The following are appendices from Optics By Example, a comprehensive guide to optics from beginner to advanced! If you like the content below, there's plenty more where that came from; pick up the book!
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Today we'll be looking into Kmett's | |
| [adjunctions](http://hackage.haskell.org/package/adjunctions) library, | |
| particularly the meat of the library in Data.Functor.Adjunction. | |
| This post is a literate haskell file, which means you can load it right up in | |
| ghci and play around with it! Like any good haskell file we need half a dozen | |
| language pragmas and imports before we get started. | |
| > {-# language DeriveFunctor #-} | |
| > {-# language TypeFamilies #-} |
ChrisPenner
/ tail_recursive_functions.py
Last active
June 8, 2023 23:55
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def factorial(n): | |
| if n == 0: return 1 | |
| else: return factorial(n-1) * n | |
| def tail_factorial(n, accumulator=1): | |
| if n == 0: return accumulator | |
| else: return tail_factorial(n-1, accumulator * n) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| {-# LANGUAGE LambdaCase #-} | |
| {-# LANGUAGE RankNTypes #-} | |
| {-# LANGUAGE ScopedTypeVariables #-} | |
| {-# LANGUAGE TypeApplications #-} | |
| module BFS where | |
| import Control.Applicative | |
| import Control.Monad.Logic | |
| import Control.Monad.Reader |
ChrisPenner
/ Tape.lhs
Last active
January 1, 2023 13:09
Building up Zippers from Distributive, Representable, and Cofree
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| We're going to take a look at an alternative way to define a Zipper Comonad | |
| over a data type. Typically one would define a Zipper Comonad by defining a new | |
| datatype which represents the Zipper; then implementing `duplicate` and | |
| `extract` for it. `extract` is typically straightforward to write, but I've had | |
| some serious trouble writing `duplicate` for some more complex data-types like | |
| trees. | |
| We're looking at a different way of building a zipper, The advantages of this | |
| method are that we can build it up out of smaller instances piece by piece. | |
| Each piece is a easier to write, and we also gain several utility functions |
ChrisPenner
/ Folds.Filtering.hs
Created
January 19, 2020 16:48
Deck of cards example for Optics By Example
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| module Folds.Filtering where | |
| import Control.Lens | |
| data Card = | |
| Card { _name :: String | |
| , _aura :: Aura | |
| , _holo :: Bool -- Is the card holographic | |
| , _moves :: [Move] | |
| } deriving (Show, Eq) |
ChrisPenner
/ OpticsForTreeTraversals.hs
Last active
February 9, 2022 19:52
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| {-# LANGUAGE LambdaCase #-} | |
| {-# LANGUAGE DeriveFunctor #-} | |
| {-# LANGUAGE DeriveTraversable #-} | |
| {-# LANGUAGE RankNTypes #-} | |
| module Recurser where | |
| import Control.Lens | |
| import Data.Monoid | |
| import Data.Foldable | |
| import Data.Functor.Contravariant |
Generating BQ schema from google sheet header row
To generate a new schema:
-
Copy the ID header row from your google sheet
-
pbpaste | python make_schema.py -
There's your BQ schema!
-
Add a new dataset to bigquery
-
Use your spreadsheet link as the file location
ChrisPenner
/ README.md
Last active
December 8, 2021 22:15
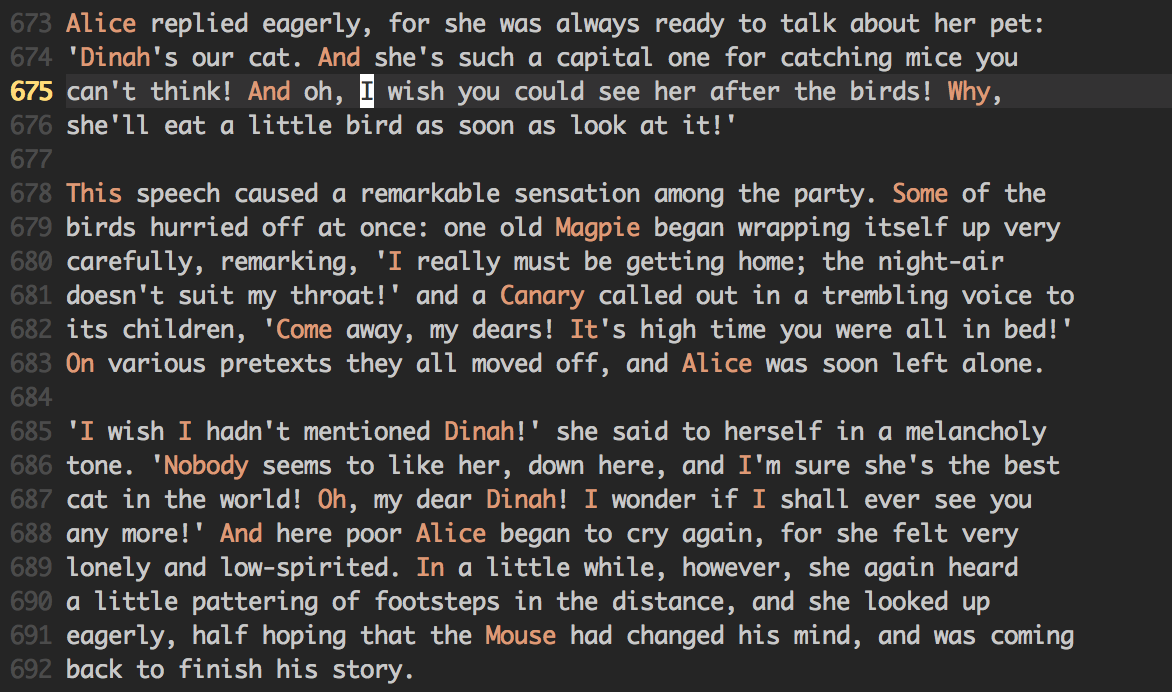
Syntax highlighting for text files, breaks up walls of white text.
Over the years I've gotten used to reading code with syntax highlighting. The colouring of the highlighting provides anchoring points for my eyes as I scroll, helping me to keep my place. However, when I'd be editing plain-text, I have no anchoring points, just a huge wall of text; so I wrote a simple syntax file for it.
All it does is highlights capitalized words, very simple. This typically ends up highlighting things of importance: headings, names, and most importantly the beginning of sentences. I've found this to be a good amount of highlighting without being overwhelming, providing context without being overly flashy.
Here's my current version:
NewerOlder