In this Google Summer of Code 2022 project, I developed the CloudStack-Terraform-Provider by expanding the list of data sources and resources supported by CloudStack. This report summarizes the work conducted from May to September 2022.
- Organization: Apache Software Foundation
- Project: CloudStack Terraform Provider - Add datasources for the existing resources
- Student: Daman Arora
- Mentors: Boris Stoyanov, Pearl Dsilva, Harikrishna
- Technologies used: Go language, Terraform, Apache Cloudstack, Cloud-Monkey
Terraform is an Infrastructure as Code technology that allows users to build immutable infrastructure. With HCL (HashiCorp Configuration Language), infrastructure can be expressed as code in a simple, human-readable manner. Using Terraform, resources are created and maintained by means of plugins known as providers. These providers add a set of resources and/or data-sources that Terraform is able to handle.
Recently, CloudStack released its own Terraform provider, called CloudStack-Terraform-Provider v0.4.0, and as of today, it supports 25 resource types and 1 data-source type. As part of my GSoC 2022 project, I worked with my mentors Pearl and Harikrishna to extend the list of data-sources and resources supported by the CloudStack Terraform Provider.
As part of the process of adding new resources and data-sources to CloudStack-terraform-provider, I was required to learn Go language and familiarize myself with the API endpoints exposed via the CloudStacks client library that was written in Go language.
Here is an example of a data-source functionality I developed from scratch in this GSoC project:
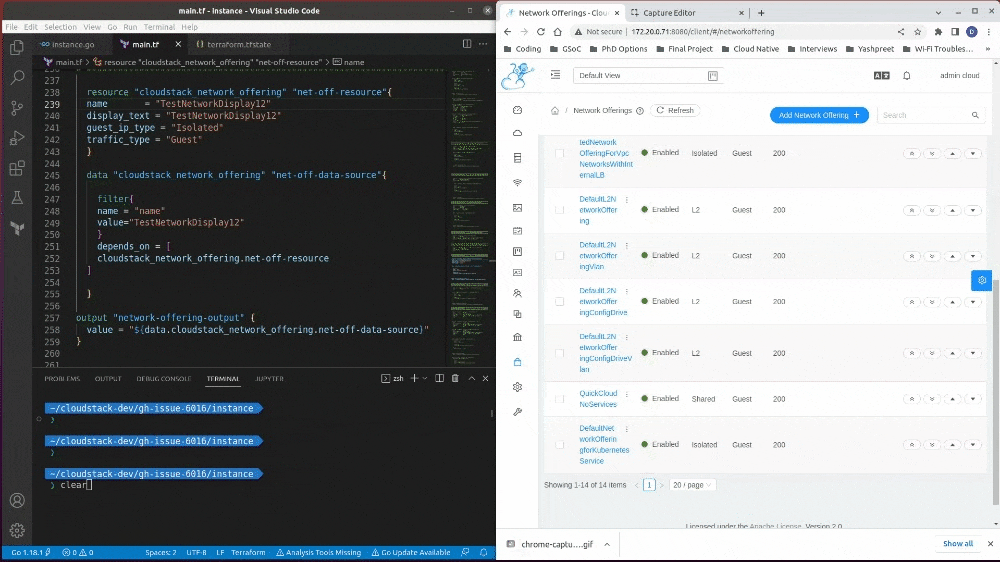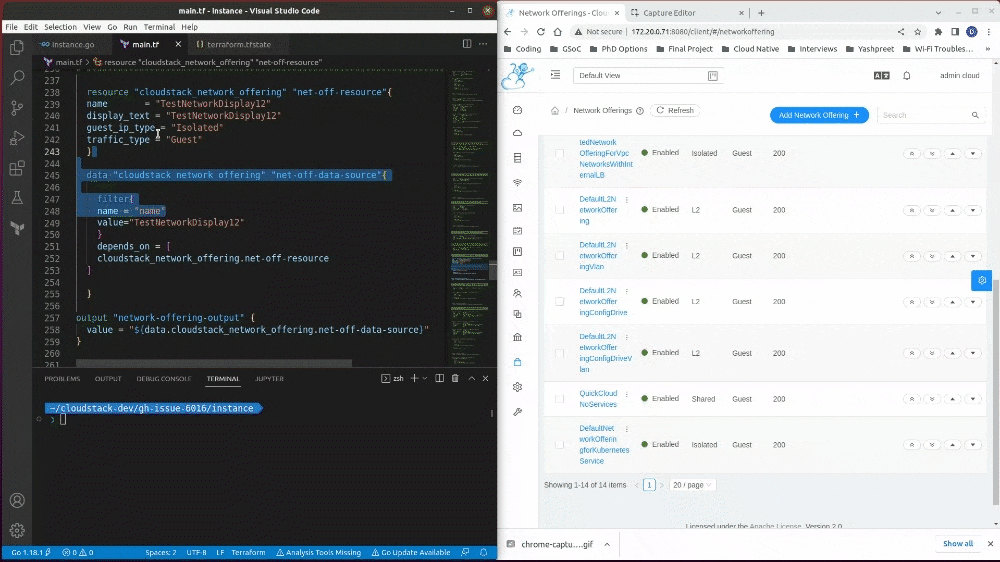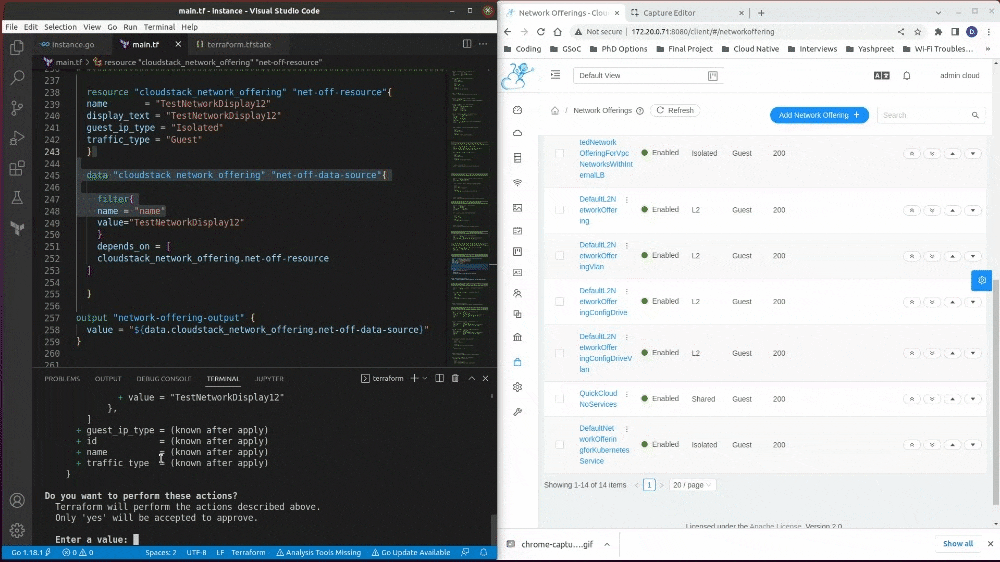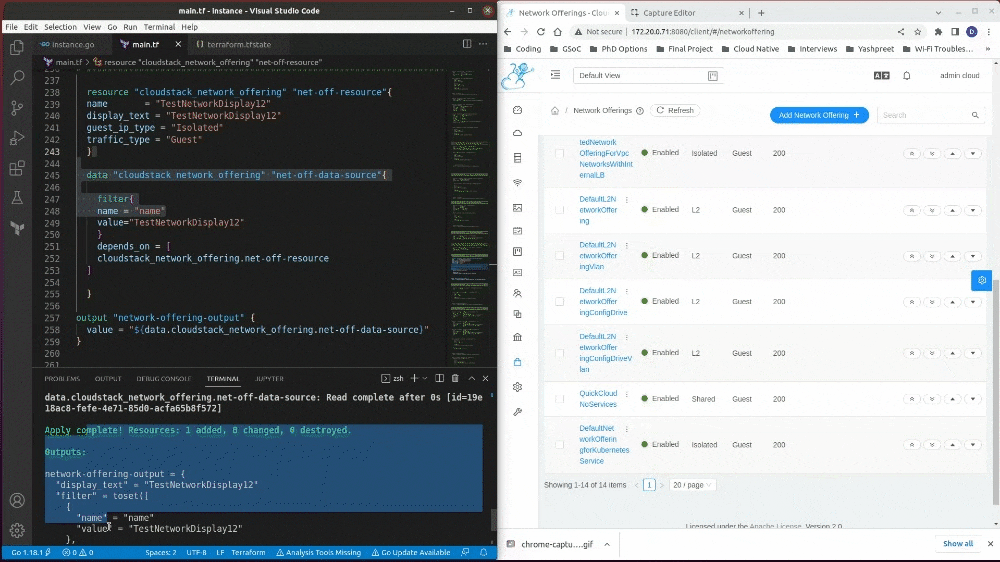
I have broken down the development in three parts:
- First phase - Data-sources development:
This phase of the project involved developing several data-sources. For some data-sources, corresponding resources existed, whereas for others, I had to develop the resources myself, the details of which will be discussed in the next section. Here is a list of data-sources that I've successfully implemented and tested:
- cloudstack_instance
- cloudstack_ipaddress
- cloudstack_network_offering
- cloudstack_service_offering
- cloudstack_ssh_keypair
- cloudstack_user
- cloudstack_volume
- cloudstack_vpc
- cloudstack_vpn_connection
- cloudstack_zone
As a first step in the development of any of the data-sources given above, I experimented with the corresponding Read method available in the cloudstack-go library. As an example, before I developed a data-source for cloudstack_instance, I queried the cloudstack API endpoint via cloudstack-go by using the following go module:
p := cs.VirtualMachine.NewListVirtualMachinesParams()
csInstances, err := cs.VirtualMachine.ListVirtualMachines(p)
fmt.Println(csInstances.Count)
fmt.Println(csInstances.VirtualMachines)
fmt.Println(err)
for _, t := range csInstances.VirtualMachines {
fmt.Println(t.Id, t.Account, t.Displayname, t.State, t.Hostid, t.Zoneid, t.Created, t.Nic)
}
After successfully listing an existing cloudstack resource using the cloudstack-go library, I created a new data-source file written in Go lang. Then in each file, I generally followed the same pattern. To begin with, I defined a structure of the data expressed by the respective data-source for defining attributes and their behaviors, using a high-level package exposed by Terraform Core called schema. Terraform Core uses schemas in Providers, Resources, and Provisioners to generate plans and execute executions based on the behaviors described.
Below is an example schema used for setting uuid_count attribute in an arbitrary data-source:
Schema: map[string]*schema.Schema{
"uuid_count": &schema.Schema{
Type: schema.TypeString,
Required: true,
},
After defining the schema, I would add a read method using the knowledge I obtained initially when I queried the respective endpoint via cloudstack-go. Following the read method, I developed a filter method to filter out the results, as well as a description method to describe the output of the read method. The read method was then tied to the schema defined in the respective data-source I wrote.
- Second phase - Resources development:
During this phase, I developed a number of resources. For some resources, I was able to complete all the required CRUD functionality, while for others, I ensured at least a Create and Delete method was included so I could use it to write acceptance tests when writing the corresponding data-source.
Here is a list of resources that I've successfully implemented and tested:
- cloudstack_account
- cloudstack_disk_offering
- cloudstack_domain
- cloudstack_network_offering
- cloudstack_service_offering
- cloudstack_user
- cloudstack_volume
- cloudstack_zone
In order to develop resources, I followed an overall process similar to that for developing data-sources, except that in addition to implementing a Read method, I also had to write Create, Update, and Delete methods. In a Terraform resource, the Create and Delete methods are the most important.
- Third phase - Documentation:
After adding new data-sources, I created documentation for each of them. Data source documentation I wrote includes a description of the data-source and an example showing how to create a new data-source in a Terraform configuration file. I have also added references to each attribute that can be used as part of a data-source.
- New data-sources: apache/cloudstack-terraform-provider#38
- Documentation for the new data-sources added: apache/cloudstack-terraform-provider#45