The code is located at https://github.com/NickRoz1/cBAM
CBAM file format intended to eliminate unnecessary disk overhead when processing of BAM data requires only few fields of each BAM records. Initial implementation was simple tool for parsing full columns and rowgroups, and wasn't suitable for big files and lack of features. Current implementation provides convenient API which is convenient to use.
Since the time of July blog, the CBAM reader implementation was completely refactored. It lacked two, major features - iteration over column in foreach and iteration over few columns simultaneously.
These features implemented on a base of a new Column primitive. Now, to acquire a column of CBAM file one may use:
auto file = File("file.cbam", "r");
auto cbamReader = new FileReader(file);
auto column = cbamReader.getColumn(bamFields.pos);This column object can be used to acquire every field of CBAM column or to iterate through its fields consistently. When iterated, column uses buffering to avoid performance drop.
// Choose desired field using bamFields enum
auto bamField = bamFields.flag;
// Get corresponding column
auto flagColumn = FileReader.getColumn(bamField);
auto dupFlag = 0x400;
bool noDups = true;
// Iterate through column
foreach(flag; flagColumn){
if(flag & dupFlag){
noDups = false;
break;
}
}
short[] flagStorage;
flagStorage.length = flagColumn.size;
// Iterate through column with index
foreach(i, flag; flagColumn){
flagStorage[i++] = flag;
}
// Get whole column
auto checkStorage = flagColumn.fullColumn();
assert(equal(flagStorage, checkStorage));
// Choose desired row group number
auto groupNumber = 1;
RawReadBlob[] rowGroup;
// Get rowgroup
rowGroup = fileReader.readRowGroup(groupNumber);Another handy functionality is new Variadic Reader, it allows simultaneous iteration over multiple columns. Essentially, it's a columns wrapper based on variadic templates. Variadic Reader can be used in foreach loops:
auto columns = getVarReader!(bamFields.pos,
bamFields.refID,
bamFields.flag,
bamFields.mapq);
foreach(pos, refID, flag, mapq; columns){
writefln("pos:%s\n
refID:%s\n
flag:%s\n
mapq:%s", pos, refID, flag, mapq);
}All core functionalities covered with tests. Testing performed via comparing reads fields from experimental BAM reader with reads fields from CBAM reader.
All tests where performed on six core 3.4 Hz machine in single threaded mode. Data (original BAM file and it's respective CBAM file) was stored on a 5400 RPM hard drive. To avoid influence of system disk precaching, cache was flushed before each measurement with:
echo 3 | sudo tee /proc/sys/vm/drop_cachesElapsed time of processing or reading data was measured in milliseconds.
CBAM file size: 1.43 GB
BAM file size: 0.88 GB
BAM records count: 34303751
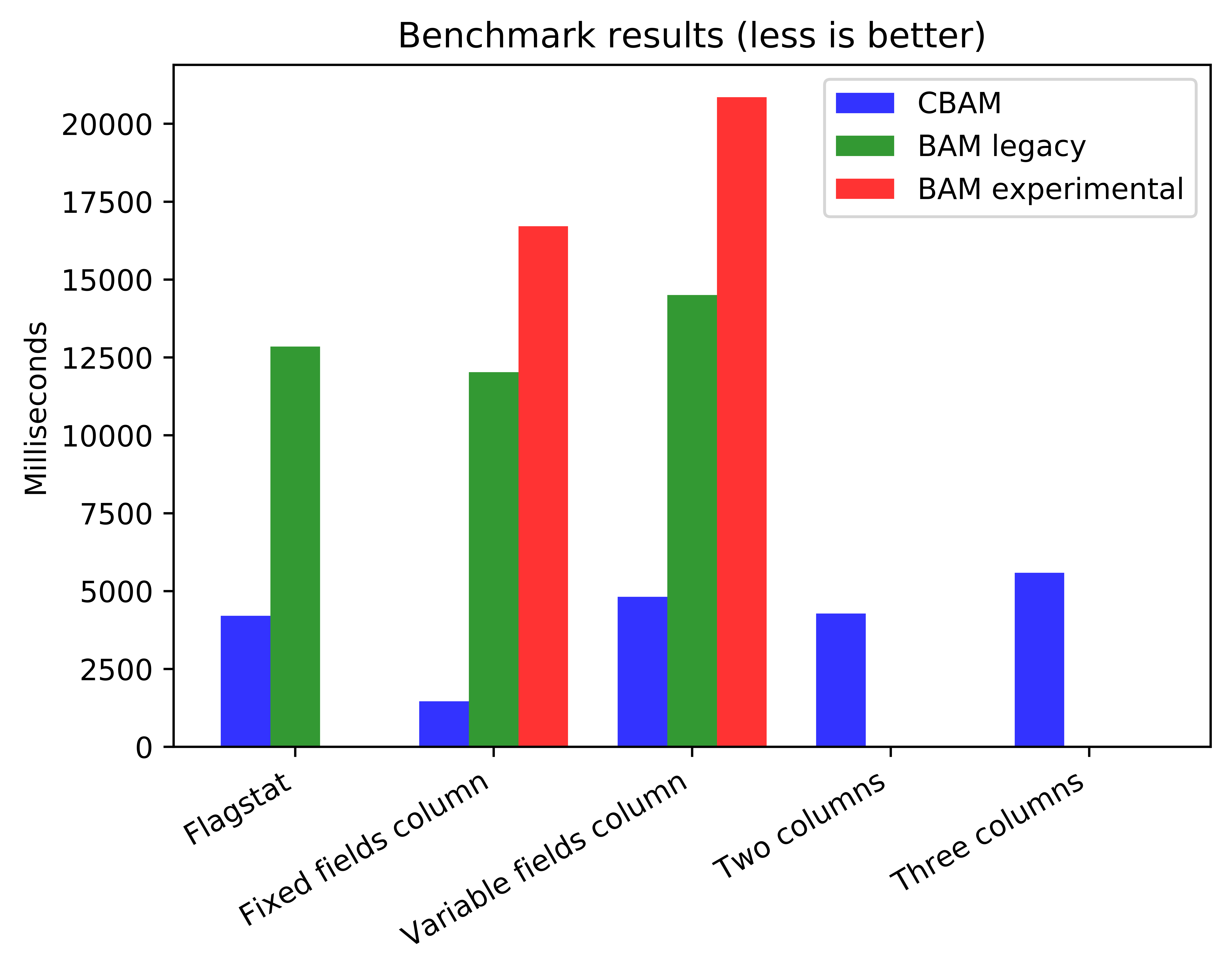
| Reader/Test | Flagstat* | Fixed Col** | Var Col** | Two Cols*** | Three Cols*** |
|---|---|---|---|---|---|
| CBAM | 4204 | 1462 | 4815 | 4280 | 5585 |
| BAM experimental | N/A | 16709 | 20851 | N/A | N/A |
| BAM legacy | 12849 | 12025 | 14504 | N/A | N/A |
*Flagstat - duration of process of collection flag statistics from file, reads several fields of all records in file
**Fixed/Var Col - duration of reading column (particular field of every record in the file) holding fixed/variable size fields
***Two/Three Cols - duration of reading fixed field size columns bounded via Variadic Reader
Concurrent capabilities of Dlang can be used to significantly speed up parsing of raw bytes and even double the speed of BAM to CBAM conversion. That is, parsing readblobs from BAM file and writing resulting rowgroups to the CBAM file could be done in parallel.
During experiments, process of parsing of raw bytes have been accelerated more than by three times via mapping byte range parse process on a multiple threads. Due to locality of this multithread processing such modification can be safely implemented.
While abstractions like Columns and Variadic Readers definitely add up to convenience of usage, they also slowing up the implementation. Utilizing CBAM without these abstractions leads to significant speed up (more than twice). One way to save the speed not sacrificing the convenience is multithreading - one thread does the low level manipulations, while second manages the API.
Format can be modified to be used on network file systems which can significantly enhance data manipulating performance.
During development process of CBAM few Dlang bugs were caught. Due to unusual usage of some standart library functions undefined behavior was caught:
Initially lockstep1 function was used to implement Variadic Reader simultaneous iteration behavior. It should have been accept several input ranges in the form of Column objects, parse the front elements for foreach usage and advance the ranges.
Launches of this implementation always lead to crashes, because file descriptor (along with FILE struct) were destroyed right after first iteration. After long debugging session it was concluded that this2 particular line of the standart library code lead to premature destruction of FILE object which belonged to the Column object.
Adam D. Ruppe, who agreed to help to resolve this problem, reduced the bug case, and suggested that this behavior may be induced by tuple assignment implementation. Bug is caused by sudden destructor call after value struct copying was performed. The Dlang issue can be found here: http://issues.dlang.org/show_bug.cgi?id=20135
Lockstep behavior was emulated via custom parsing function which ultimately lead to a more robust and elegant solution than it might been using mentioned standart library function.
The second bug was discovered by accident passing wrong input to other, rather important standart library feature - TaskPool. When constructed with value 0 (number of working threads) destruction of TaskPool leads to program segfault. Debug session with GDB pointed on a mutex lock operation.
Many thanks to my mentor Pjotr Prins for all the support and help he has given to me. I truly appreciate it.
Thanks to Artem Tarasov for motivating me to participate in GSoC.
Thanks to Kai Blin for midterm evaluation.
Thanks to OBF for organization of this awesome event and great community.
And of course thanks to Google for hosting this program. It's very important for Open Source community.