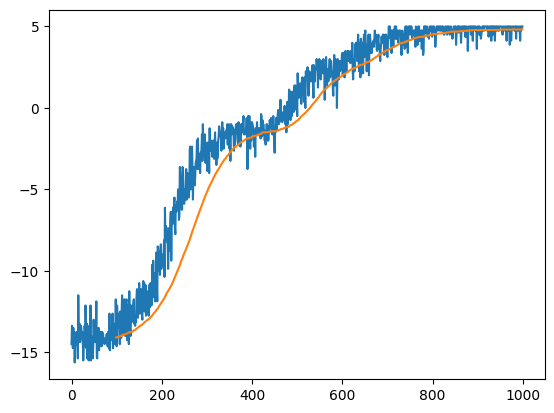
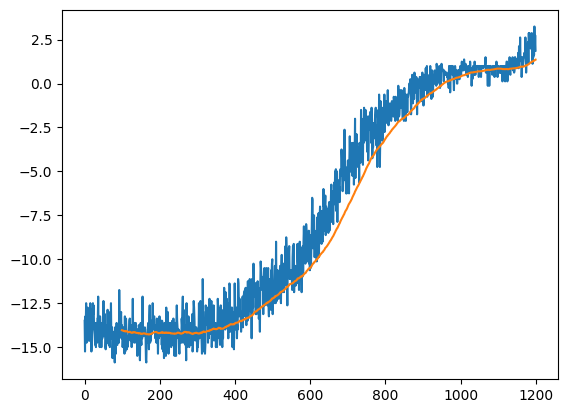
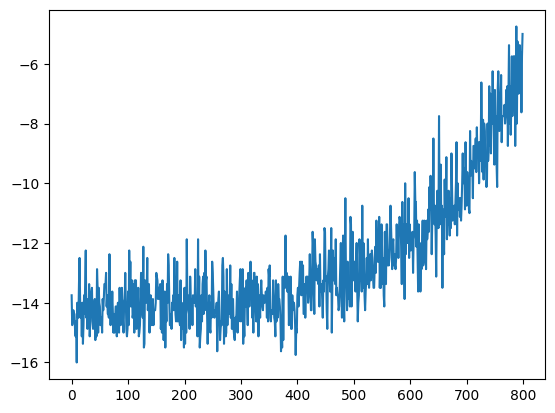
- trg = trg*(1-τ) + src*τ
- τ is stored in self.config.target_network_mix
def soft_update(self, target, source):
## trg = trg*(1-τ) + src*τ
## τ is stored in self.config.target_network_mix
for target_param, source_param in zip(target.parameters(), source.parameters()):
target_param.detach_()