Andy Lathrop alathrop
alathrop
/ ml_for_marketing__trees_python_pt2
Last active
May 23, 2020 01:35
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # DataCamp ML for Marketing in Python | |
| ''' | |
| Fit decision tree model | |
| Now you will fit a decision tree on the training set of the telecom dataset, and then predict labels on the unseen testing data, and calculate the accuracy of your model predictions. You will see the difference in the performance compared to the logistic regression. | |
| The accuracy_score function has been imported, also the training and testing datasets that you've built previously have been loaded as train_X and test_X for features, and train_Y and test_Y for target variables. | |
| ''' | |
| # Initialize decision tree classifier |
alathrop
/ logistic_churn_python
Last active
May 23, 2020 01:29
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # DataCamp ML for Marketing in Python | |
| # Print the unique Churn values | |
| print(set(telcom['Churn'])) | |
| # Calculate the ratio size of each churn group | |
| telcom.groupby(['Churn']).size() / telcom.shape[0] * 100 | |
| # Import the function for splitting data to train and test | |
| from sklearn.model_selection import train_test_split |
alathrop
/ sklearn_centering_scaling_pipelines
Last active
May 20, 2020 17:58
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # DataCamp sklearn supervised | |
| # Import scale | |
| from sklearn.preprocessing import scale | |
| # Scale the features: X_scaled | |
| X_scaled = scale(X) | |
| # Print the mean and standard deviation of the unscaled features | |
| print("Mean of Unscaled Features: {}".format(np.mean(X))) |
alathrop
/ sklearn_missing_values_pipelines
Last active
May 20, 2020 17:01
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # DataCamp sklearn supervised | |
| # Import pandas | |
| import pandas as pd | |
| # Read 'gapminder.csv' into a DataFrame: df | |
| df = pd.read_csv('gapminder.csv') | |
| # Create a boxplot of life expectancy per region | |
| df.boxplot('life', 'Region', rot=60) |
alathrop
/ sklearn_hyperparameter_tuning
Last active
May 24, 2023 19:04
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ## Data Camp supervised learning with sklearn ## | |
| # Import necessary modules | |
| from sklearn.linear_model import LogisticRegression | |
| from sklearn.model_selection import GridSearchCV | |
| # Setup the hyperparameter grid | |
| c_space = np.logspace(-5, 8, 15) | |
| param_grid = {'C': c_space} | |
| # Instantiate a logistic regression classifier: logreg |
alathrop
/ sklearn_logistic_regression
Last active
May 19, 2020 17:09
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ## Data Camp supervised learning with sklearn ## | |
| # Import the necessary modules | |
| from sklearn.linear_model import LogisticRegression | |
| from sklearn.metrics import confusion_matrix, classification_report | |
| # Create training and test sets | |
| X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state=42) | |
| # Create the classifier: logreg | |
| logreg = LogisticRegression() |
alathrop
/ sklearn_classification_metrics
Last active
May 19, 2020 16:10
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ## Data Camp supervised learning with sklearn ## | |
| # Import necessary modules | |
| from sklearn.metrics import classification_report, confusion_matrix | |
| # Create training and test set | |
| X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state=42) | |
| # Instantiate a k-NN classifier: knn | |
| knn = KNeighborsClassifier(n_neighbors=6) |
alathrop
/ python_fn_examples3_manning
Last active
December 2, 2019 02:06
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| \!h ''' Manning Get Programming with Python | unit 6, module 4 | analyze your friends''' | |
| def read_file(file): | |
| """ | |
| file: a file object | |
| Starting from the first line, it reads every 2 lines and stores | |
| them in a tuple. Starting from the second line, it reads every | |
| 2 lines and stores them in a tuple. | |
| Returns a tuple of the two tuples. | |
| """ |
alathrop
/ python_fn_examples2_manning
Last active
December 2, 2019 01:48
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| \!h ''' Manning Get Programming with Python | unit 6, module 3 | advanced operations with functions''' | |
| def normalize_to_100(score, out_of): | |
| """ | |
| score: integer representing a score | |
| out_of: integer representing what score is out of | |
| Returns normalized score so that it is out of 100 | |
| """ | |
| return score*100/out_of | |
alathrop
/ python_fn_advanced_manning
Last active
December 2, 2019 01:48
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
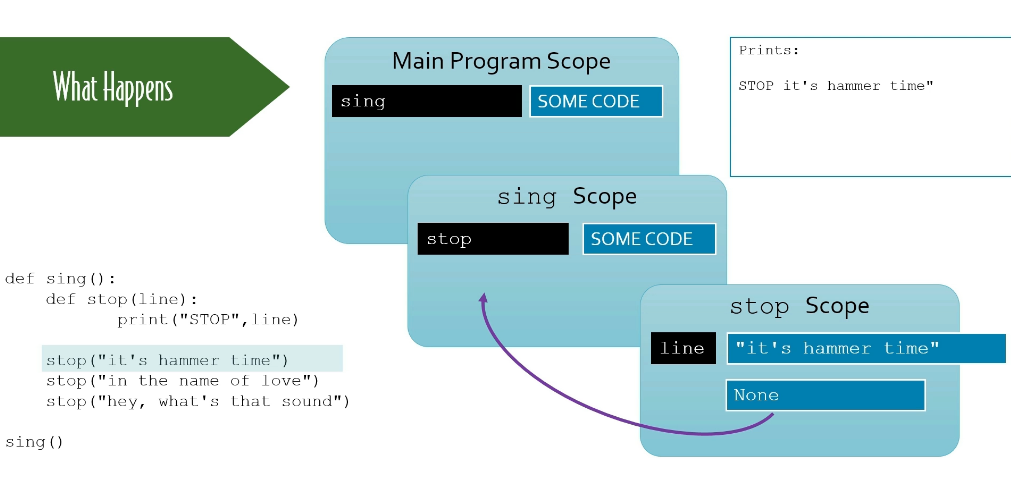
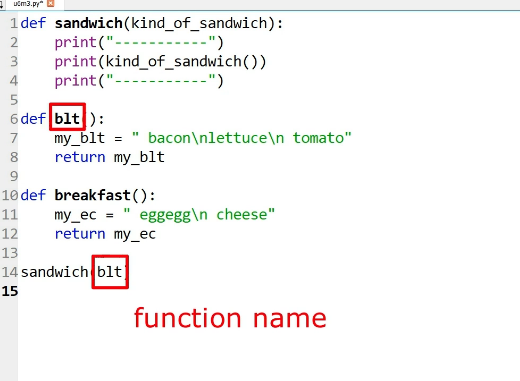
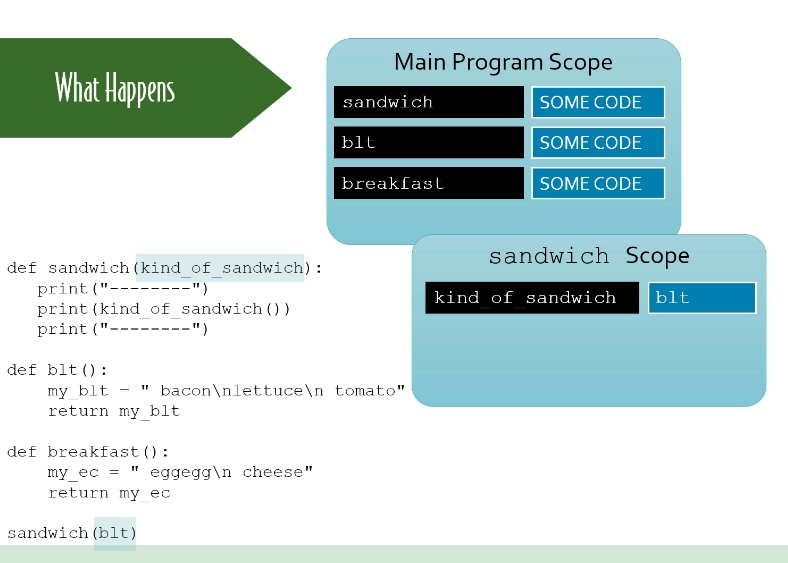
| ''' Manning Get Programming with Python | unit 6, module 3 advanced operations with functions''' | |
|  | |
|  | |
|  | |
|  |
NewerOlder