Unstructured information such as video, text, and audio represents the largest and fastest-growing source of information nowadays. The goal of AI is to approach the human abilities to process efficiently the vast amount of Unstructured Data in this complex real world. This project focuses on Object Hypotheses and Segmentation tasks using Symmetry Constraints in cluttered and occluded scenarios, which is developed as Rotational and Bilateral Symmetry Segmentation Analysis Engines on Robosherlock framework. This project enables RoboSherlock to operate in a knowledge-intensive real world. The project was done to fulfill the requirements of Google Summer of Code 2017.
The project is merged with the branch master. It was designed to not use any other library dependencies than the main repo. The system is now able to robustly detect rotational, bilateral symmetries and segment objects of any kind in cluttered scenes, provided the set of parameters is tuned.
Pull request: [Link]
- Implement state-of-the-art object segmentation algorithms to successfully segment distinct objects in increasing cluttered scenarios.
- Integrate these working implementations as Analysis Engines to UIM structure of RoboSherlock framework
- Parallel over-segmenting segments from a cloud with different parameters to generate a resource for symmetry detection
- Robustly detecting rotational and bilateral symmetries over a scene
- Robustly segmenting round objects from rotational and bilateral symmetries in the cluttered scene as indices of object clouds.
- Graph data structures and graph algorithms
- Similar cloud segment merger
- PCA solver
- Levenberg-Marquardt algorithm (damped least-square fitting)
- Boykov min-cut segmentation based on boost library
- Rotational Symmetry Detector, Filter and Merger
- Rotational Symmetry scoring system
- Bilateral Symmetry Detector, Filter and Merger
- Bilateral Symmetry scoring system
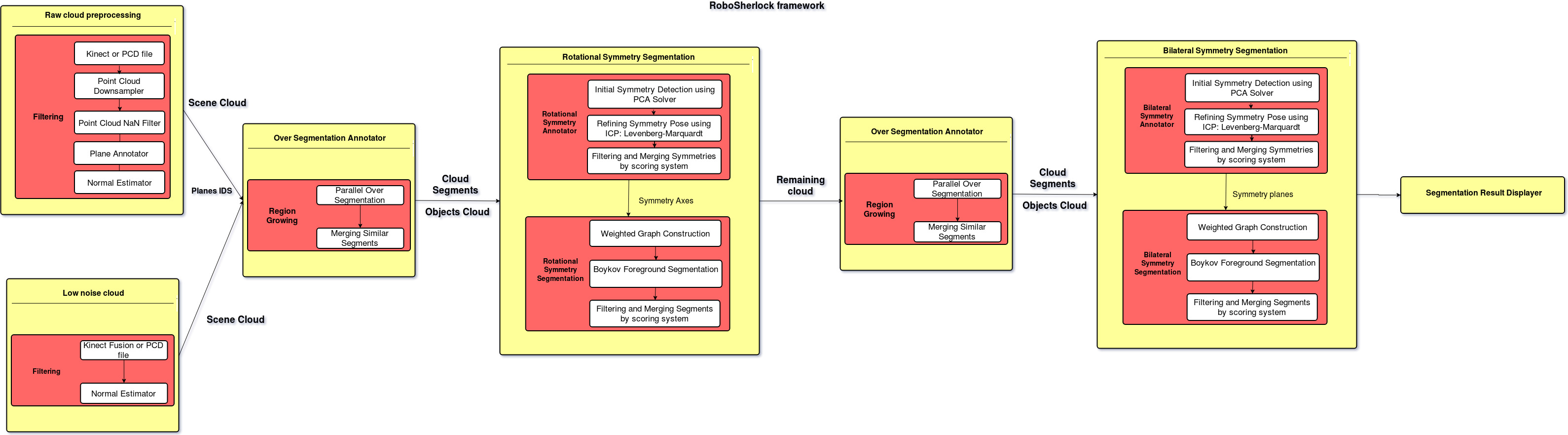
In summary, the system first will over segment the whole scene cloud using pcl::RegionGrowing, every point belong to one of these segments have similar point normal that implies these points are in the same planes.
These segments will be passed to Rotational or Bilateral Symmetry Detector. At this stage, initial symmetries are first computed by PCA solver, these symmetric axes are eigenvectors of each segment. The initial symmetry's poses are then refined by the ICP algorithm: Levenberg-Marquardt with a defined optimization model (detail in code). The refined symmetries have the best normal fit with these segments. After refining, the symmetry scoring system will score each symmetry that belongs to each segment and then filter out false symmetries. The final step is merging symmetries that have closed position and angle difference.
These symmetries are then passed to Rotational or Bilateral Symmetry Segmentation modules. Graph adjacency weights, foreground, and background weights are constructed for each symmetry with the scene cloud. The graph is input to Boykov foreground segmentation function by Boost library to segment points that belong to an object. The scoring system will score each object segment to filter inappropriate object segments and merge object segments that have a threshold of point intersection.
The rotational symmetry segments round object better than bilateral symmetry. Therefore, I construct the RoboSherlock pipeline that segments round objects first and feeds remaining cloud indices to bilateral symmetry segmentation. This pipeline has been experimentally proven to have the best accuracy and performance. The high-level system architecture of the pipeline is shown in the picture above.
PointCloudFiltering
minX, maxX, minY, maxY=> parameters for scene cloud window that covers all objects but not redundant background points.
PointCloudDownsampler
leaf_size: downsample resolution => if leaf_size is low, better normal estimator, better segmentation but worse performance.
Normal Estimator
radiusSearch: radius to find neighbors => if radiusSearch is low, point normal is vulnerable to noise. If it's high, point normal is distorted at edges. Best known value: 0.005
OverSegmentationAnnotator
-
minNormalThreshold, maxNormalThreshold, numSegmentation: parameters to parallel OverSegmentation process with total of((maxNormalThreshold - minNormalThreshold) / numSegmentation * i)instances => if normal threshold is low, more segments are found (a face of cube, cap of bottle, etc) but more noise segments due to non-perfect normal estimator. If the normal threshold is high, fewer noise segments but points on segments are less likely to be on the same plane. -
neighborNumber: the number of neighbors for region growing expansion => if neighborNumber is high (>10), hence better OverSegmentation process but slower performance.
RotationalSymmetryAnnotator
-
rotSymAnn_min_fit_angle, rotSymAnn_max_fit_angle: range for scaling symmetric scoring => if range is large, more symmetries are detected with symmetric property but more false symmetries. -
rotSymAnn_min_occlusion_angle, rotSymAnn_max_occlusion_angle: range for scaling symmetric scoring => if range is large, more symmetries are detected with less densed segments but more false symmetries. -
rotSymAnn_max_sym_score, rotSymAnn_max_occlusion_score, rotSymAnn_max_perpendicular_score, rotSymAnn_min_coverage_score: parameters to filter false symmetries => relaxing max sym score, then more symmetries with symmetric property passed; relaxing max occlusion score, then more symmetries with less densed segments passed; relaxing max perpendicular score, then more symmetries with large difference between point normal and symmetry axis range passed; relaxing min coverage score, then more symmetries with low angle coverage segment passed.
RotationalSymmetrySegmentation
-
rotSymSeg_isDownsampled, downsample_voxel_size: Turn downsample scene cloud for segmentation on or off => if turned on, considerably faster performance but need tuning other parameters well. -
rotSymSeg_adjacency_radius, rotSymSeg_num_adjacency_neighbors: parameters to construct adjacency graph => if these params are high, more dense adjacency graph, hence more accuracy and lower performance. However, there is a saturation level of accuracy if params are set higher. -
rotSymSeg_adjacency_weight_factor: weight scaling of adjacency graph => if this weight factor is high, segmentation behaves more like Region Growing. -
rotSymSeg_fg_weight_factor, rotSymSeg_bg_weight_factor: foreground and background weight scaling => if foreground weight factor is high and background weight factor is low, more points in object are segmented, but false points are also high. Otherwise objects are not fully segmented. -
rotSymSeg_min_fit_angle, rotSymSeg_max_fit_angle: range to scoring for foreground and background weight => if range is large, hence more objects with symmetric property are segmented. -
rotSymSeg_min_occlusion_angle, rotSymSeg_max_occlusion_angle: range to scoring for foreground and background weight => if range is large, hence more objects with less dense cloud are segmented. -
rotSymSeg_max_sym_score, rotSymSeg_max_occlusion_score, rotSymSeg_max_cut_score: parameters to filter false segments => relaxing max sym score, more objects with symmetric property passed; relaxing max occlusion score, more objects with less densed segments passed; relaxing max cut score, more objects with more cut points passed.
BilateralSymmetryAnnotator
-
naive_detection, angle_division: parameter to turn naive symmetry detection on or off => ifnaive_detectionis True, there are three symmetries planes detected with normals are eigenvectors. Otherwise, redundant symmetries planes are detected by generating hemisphere points defined by angle_division. -
correspondence_search_radius, correspondence_max_normal_fit_error: parameters to find symmetric correspondences of each segment => higher search radius, more likely correspondences are found for each point in segment, provided correspondences' normal angle difference is not exceededmax_normal_fit_error. -
min_segment_inlier_score, min_corres_inlier_score, bilSymAnn_max_occlusion_score: parameters to filter false symmetries => relaxing min segment inlier score, hence more symmetries with symmetric property over whole segment passed; relaxing min correspondences inlier score, hence more symmetries with symmetric property over correspondences size passed;
Other parameters have the same meaning with parameters in RotationalSymmetryAnnotator.
BilateralSymmetrySegmentation
Parameters in these modules have the same meanings with parameters in RotationaSymmetrySegmentation.
Some parts of the system can be improved in terms of accuracy and performance.
STRATEGY TO IMPROVE PERFORMANCE
- reducing false symmetry by tweaking score => this option reduces total segmented objects sometimes (in Section Parameters Tuning Guide)
- naive detection in symmetry detection => this option enhances performance considerably, but need tuning other parameters well.
- decreasing radius search and neighbors of adjacency graph in Symmetry Segmentation => this option is a trade-off, better performance but worse accuracy
- increasing downsample resolution => this option is a trade-off, better performance but worse accuracy
STRATEGY TO IMPROVE ACCURACY
- better normal estimator
- low noise input scene cloud
- more redundant symmetries => relaxing filtering, more symmetries passed, hence lower performance
- more redundant Region Growing segments => more resource to detect symmetries, lower performance
- because of needing accurate normal estimator => iteratively using Kinect fusion to scan the scene (clean cloud) or other registering method and then triggering the segmentation system to de object.
cd ~\<your_workspace>\src
git clone https://github.com/anindex/robosherlock.git
cd ..
catkin_make
Please click this image for demo

- Running segmentation demo on low noise cloud
roscore&
rosrun robosherlock run full_segmentation
- Running segmentation demo on raw cloud
roscore&
rosrun robosherlock run object_segmentation
- Running unit tests:
roscore&
cd ~\<your_workspace>
catkin_make run_tests_robosherlock
In full_segmentation or object_segmentation pipeline, one can switch to SegmentationResultDisplayer cloud viewer by pressing arrow keys to view the segmentation results.
The efficiency of the system in terms of accuracy and performance depends heavily on the set of parameters. To establish an evaluation metric for this system, unit test results are considered as a standard evaluation. The method of unit test in this system is as follows:
- Import sample cloud and ground truth table
- Run segmentation pipeline once
- Calculate similarity of indices between cloud segments and ground truth segments by the ratio: index intersection unique set size over index union unique set size, if the ratio is over 0.7f (70% similarity) => The object is segmented successfully
- If the system segments at least 75% of total objects in ground truth table => Unit test is passed.
The unit tests are imported low noise cloud with ground truth tables. The processing time for each test is 2-3 seconds average on CPU i7 2.8 GHz, RAM 16 GB. All tests are passed with the tuned parameter set.