A layer is an irmin-pack store that can be opened as a normal store, or that can be combine with other layers, to form a layered store. As in Overlayfs, the lower layer is readonly, whereas the upper layer is used for adding the latest values. add is always performed on upper. find first tries to retrieve data from upper, and then defaults to lower.
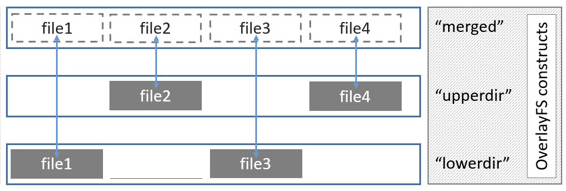
Unlike Overlayfs, data from lower is never copied back in upper: every time a data from lower is needed it is accessed on lower.
A freeze function can be called whenever we want to move data from upper to lower.
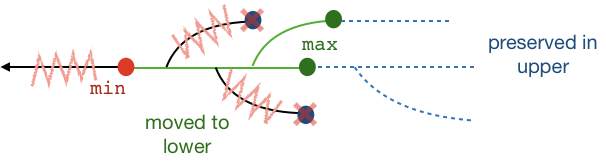
freeze ?min ?max ?squash ?copy_in_upper ?min_upper t takes as argument a range of commits [min, max] and moves all the objects in their closure graph to lower.
If max is empty then we replace it with all the current heads. If min is empty then we replace it with all ancestors of max.
If squash = true then only the max commits are moved.
By default, a freeze will clear everything from upper. To keep some data in upper, we can use the arguments copy_in_upper and min_upper:
-
If
copy_in_upper = falsethen upper is cleared after the freeze: everything contained in[min, max]is in lower, and everything else is lost. -
If
copy_in_upper = truethen the commits between[min_upper,max]are copied back in upper. Ifmin_upperis empty, then only the max commits are copied.
A freeze is non-blocking, but all data you add to the store once you call freeze is indeed preserved in upper.
A note on that the constraint that we cannot move data from lower back into upper still holds: you should check that all objects you want to have in upper after the freeze are indeed in upper before the freeze.
Use Make_layered to create a layered store:
module S =
Irmin_pack.Make_layered (Conf) (Irmin.Metadata.None) (Irmin.Contents.String)
(Irmin.Path.String_list)
(Irmin.Branch.String)
(Hash)and then create a repo and use it to build the stores in the figures below
let test repo =
S.Tree.add (S.Tree.empty) [ "a"; "b"; "c" ] "Hello" ~info:(info "commit c1")
>>= fun tree ->
S.Commit.v repo ~info ~parents:[] tree
>>= fun h ->
S.freeze repo ~max:[ h ] ~copy_in_upper:false >>= fun () ->
S.Tree.add tree [ "a"; "d" ] "Hello2" ~info:(info "commit c2") >>= fun () ->
S.Commit.v repo ~info ~parents:[h ] tree >>= fun h2 ->
S.Tree.add tree [ "a"; "b"; "c" ] "Hello3" ~info:(info "commit c3")
S.Commit.v repo ~info ~parents:[h2 ] tree
For more examples check the test in irmin-test/layered_store.ml.
Both uppers and lower are separate irmin-pack stores. The directory for these stores can be set by calling config:
let config ?(readonly = false) ?(fresh = true) ?(keep_max = true)
?(lower_root = "lower") ?(upper_root1 = "upper1")
?(upper_root0 = "upper0") root =
let conf = Irmin_pack.config ~readonly ?index_log_size ~fresh root in
Irmin.layered_config ~conf ~keep_max ~lower_root ~upper_root0
~upper_root1 rootThe stores can be opened separately while using the layered store but only in readonly mode. If you want to open them in readwrite you have first to close the layered store.
freeze ~min ~max () computes the closure graph of the commits between min and max. For each commit, all nodes and blobs contained in its tree are visited and copied to lower. If some commits, nodes or blob is already in lower (determined based on their hash), then they and their children are not visited and copied.
An lwt thread, created using Lwt.async, is running the freeze.
To ensure a nonblocking freeze we need two upper stores. One upper, the current one, is used to add objects. The next upper is only used during a freeze, to copy all the objects that we will preserve in upper after a freeze. At the end of a freeze the two are flipped: the next upper because the current one, while the previous upper is cleared and is ready for the next freeze.
Adds and finds are always performed on the current upper, the main thread does not need to use the next upper at all. This ensures that there are no concurrent writes on the same layer: the main thread writes only to current, whereas the freeze thread writes to lower and next, but only reads from the current.

During freezes, find can return false positives: it can find an object while a freeze is ongoing, which will be deleted by the end of freeze.
In order to allow for a layered store to be closed and reopen, or to recover after a failure, a flip file is used to keep track of which upper is the current one. The two uppers, called upper0 and upper1 take turns as the current_upper. The flip file contain either 0 (if current_upper is upper0), or 1(if current_upper is upper1).
The references store is also split into two uppers and one lower.
After a freeze, branches that referenced commits in upper are copied in lower and will reference the same commits in lower. References to deleted commits are removed, including master.
set only sets values in upper. test_and_set copies the reference back in upper if it is only in lower, and it uses the value in upper for all future tests.
remove deletes the reference from all stores simultaneously, i.e. it does not wait for freeze to propagate values form upper to lower.
The benchmark setting consists of a running a tezos node on a bootstrapped store, that is a node that only validates blocks baked in real time. This is to ensure that the workload of the main thread is not too intensive, and that the freeze thread can finish its work in time.
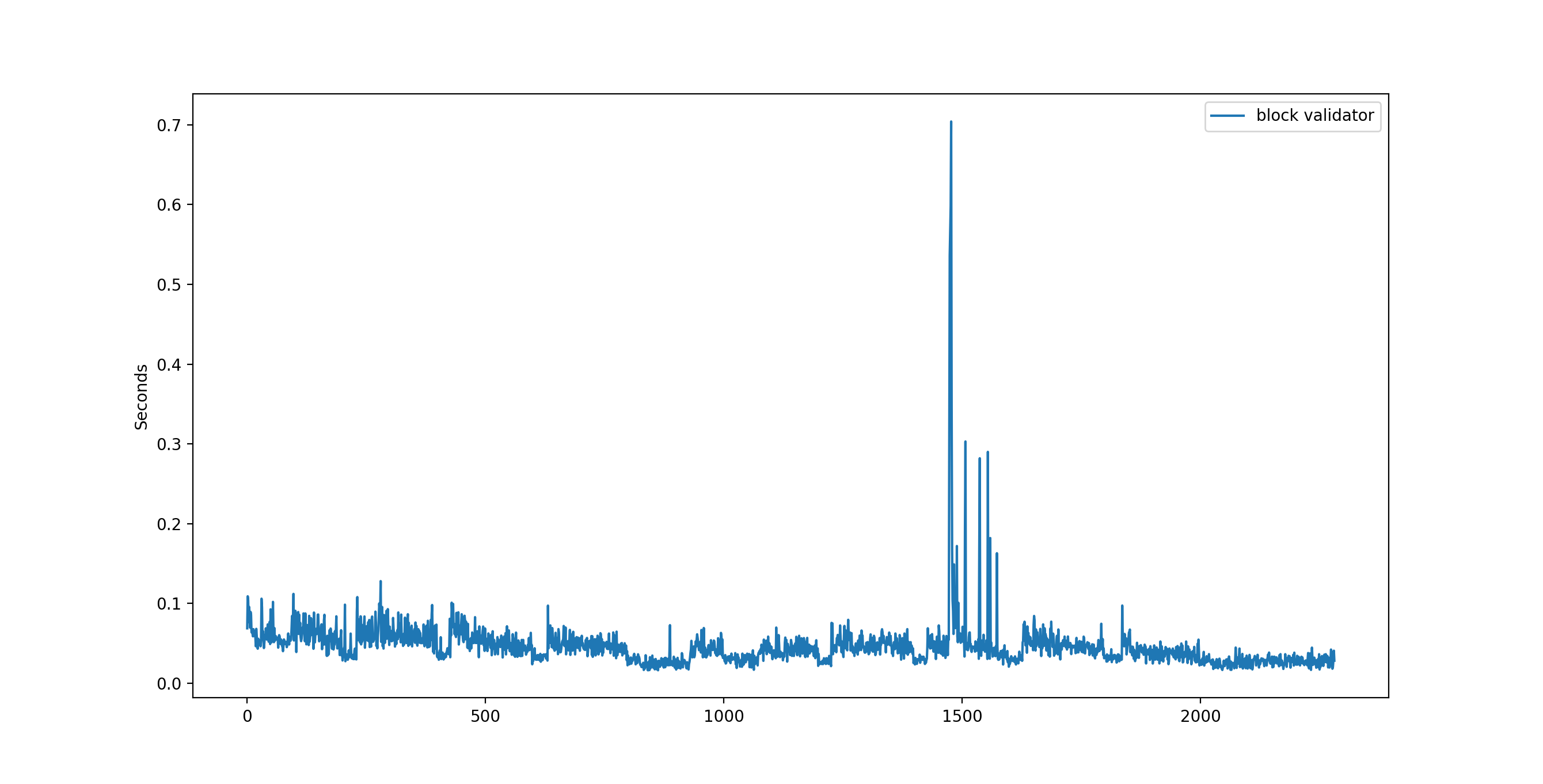
The following graphs shows for each block validated, the time it took (i.e. the completed in ... from the node logs). We can see that the freeze thread has enough time to finish its work before the next freeze is called.
 If the freeze thread does not have enough time to finish, it will block the main thread when a second freeze is called, resulting in a spike. In this case, you can see in the logs, that the freeze waiting time is large, and it is an indication that you should call freeze less often, or that your node had to bootstrap some blocks from the past.
If the freeze thread does not have enough time to finish, it will block the main thread when a second freeze is called, resulting in a spike. In this case, you can see in the logs, that the freeze waiting time is large, and it is an indication that you should call freeze less often, or that your node had to bootstrap some blocks from the past.
For the RO instance, spikes can occur at the end of freeze, when the instance has to sync with several files on disks. These spikes are less than 1s in our benchmarks.
We can plot the number of objects added by each commit to compare them with the number of objects copied by the freeze thread. This gives an idea of how much work the freeze thread has to do.
 The black lines are where the freezes occur, and the lines are annotated with the number of objects copied by the freeze. What happens with the commit that adds more than
The black lines are where the freezes occur, and the lines are annotated with the number of objects copied by the freeze. What happens with the commit that adds more than 1000 objects? It is occuring right after a freeze ended (we can see this in the logs). So what it means is that the freeze has deleted objects that were needed by the commit.
The lower layers are named "lower0" (the oldest), "lower1", etc. An index is used to store the pair (hash, layer) where layer contains the object corresponding to hash. layer_id hash retrieves the name of the lower layer that stores the object.
We can either:
- create the store with a given number of layers: then
freezecan choose a destination layer (its the current implementation); - create a new layer at each
freeze. Also the semantics ofminandmaxneeds to be revisited: ifminormaxincludes commits from a different layer than the source or destination layer.