Designed and implemented a topic modeling module (PR #269) (Personal repo link).
-
Learning and implementing all existing Maryam's modules. (Jupyter Notebooks).
-
The first prototype.
-
Designed and implemented the first prototype for the core/util/iris/topicmodeling.py: K-Means algorithm and Wordcloud. (notebook),
output = tm.perform_kmeans()
-
-
The second prototype.
-
Designed and implemented topic modeling using Mr. Kaushik's dataset, with NMF and LDA algorithm (notebook),
tm = topicmodeling(jsonfile)tm.perform_nmf1()
tm.perform_nmf2() )
)tm.perform_lda()
-
-
The third prototype.
-
Implemented BERT algorithm using BERTopic and SentenceTransformer. (notebook), users will be able to choose their preferred word embedding model, from repositories, as for a particular dataset user may need to select the best word embedding model which has the most superior performance.

tm.run_topic_modeling("paraphrase-distilroberta-base-v1")
-
-
The fourth prototype.
-
Adding CVF file support and stopwords removal. (notebook),
tm = topicmodeling(inputfile="testdataset.csv", filetype="csv", verbose=True)
-
-
The initial creation of the PR for topicmodeling module (PR).
-
Fix bug and add new feature (commit).
-
Renaming the plotly.py to solve the dependencies problem. In addition, I also added the --output and --api functionality. Tested by using =
topicmodeling -i mixed.json -t json -m all-distilroberta-v1 --outputreport json testreport iris/topicmodelingtopicmodeling -i mixed.json -t json -m all-distilroberta-v1 --api
-
-
Added a new feature:
-
Search Topics Using a Keyword (Top2Vec). (notebook),
topic_words, word_scores, topic_scores, topic_nums = model.search_topics(keywords=["music"], num_topics=2) for topic in topic_nums: model.generate_topic_wordcloud(topic)
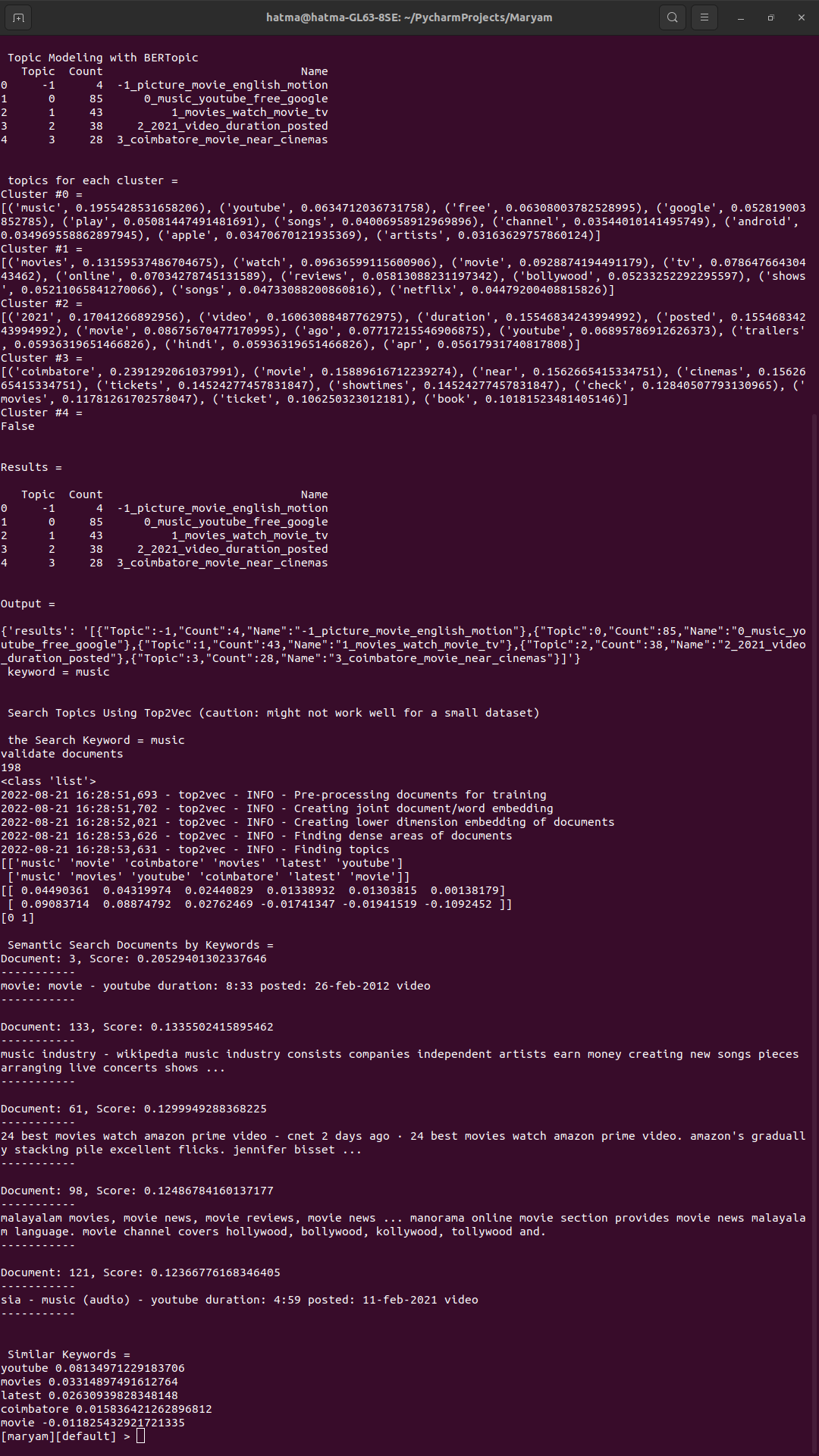
-
-
Top2Vec has a limitation: that it might not work well for a small dataset. Therefore, when using a small dataset (such as Mr. Kaushik's mixed.json) sometimes it will not work. See the demonstration on jupyter notebook.
-
The same notebook as the previous notebook, but when we re-run the notebook sometimes it will fail.
-
Top2Vec algorithm has a good performance, but still has this problem when using a small dataset. To continue my work, we need to find an alternative algorithm or improving the current Top2Vec implementation.
-