
Tools are the enablers of magnificent creations, be it mechanical tools or software tools.We have been striving all these years with tons of tools which are the stepping stones for our journey towards excellence.
NLP is one of the most hottest topics in the industry now and GPT-3 models have hyped it to the next level. Text data is available everywhere from public data like tweets, Reddit, blogs etc, to other private data as well. This makes NLP tools of great relevance and demand for analysing and processing large amounts of textual data.
So let's explore two relevant NLP tools in this article which has served us throughout these years:
- Semantic Reactor
- OpenRefine

Understanding context from the text for machines is considered to be a very complex, time-consuming and costly process. Yet this is where Semantic Reactor under Semantic experiences comes to make communication with digital services like chatbots, search engines, games very easy. It’s a Natural Language Understanding(NLU) tool, built with advanced Machine learning models.
Semantic Reactor is used for a lot of purposes like finding the response queries matching to a given input text, writing dialogues in games, responding to questions in various digital services and many more. It’s a tool to experiment with ML models from Google sheets.
Semantic Reactor is an easy to use tool which can be installed from G-suites business apps. Once installed we can find semantic reactor in Google sheets add on section. This makes it easy to load any text data and gain understanding based on it. Any changes in the google sheets can be reloaded and a new model is being created for you.
Semantic Reactor consists of mainly two features that are:
- Semantic Similarity
- Input/ output response
There is an additional feature to say with/without Ranking(to rank response based on certain rules)
Semantic similarity
Let’s go into details of semantic similarity. Chatbots are being used in real-world applications a lot. Majority of questions will be already anticipated and have labelled answer. Yet the problem is the same question can be framed in multiple ways by different persons interacting with a chatbot.
Given an anticipated question to ask in a chatbot like: Where is the taxi stand?
There can be a lot of queries which are similar yet need the same anticipated result?:
Is the taxi stand near a motel?
Where can I get a taxi?
So with semantic similarity, we examine which anticipated question matches our input statement with a probability. It helps us understand the responses and return a list of queries which are similar to the input query to match similar word as input. All this uses complex machine learning models techniques and can be used easily used inside google sheet for your use case.

In the given above image, we are asking - Did you see anything during dinner? as a question, and anticipated questions and answers which match our input question are being returned by Semantic Reactor.
Input/Output Response
Next mode is the use of Input/output response which be used for getting the appropriate reply for a given input text from the sheet without anticipated answers, given a sequence of conversation. You can’t always anticipate what the user will type. Given an input text query like input text like Hello, a list of queries which match similar words are given as replies. as shown below.
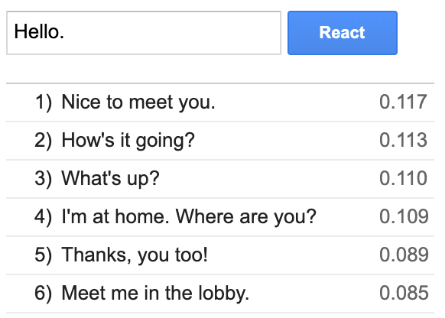
Semantic Reactor comes with three varieties of models:
- Local - basic tflite model
- Basic Online - Universal sentence encoder model in English
- Multilingual Online - Universal sentence encoder multilingual q-a model in Chinese-traditional, English, French, German, Italian, Japanese, Korean, Dutch, Polish, etc.
Based on top of Semantic Reactor, google has built various interactive chatbots to play Mystery of Three bots which can be found on github. Also, you can experiment it to find and understand valuable insights from your data very easily.

OpenRefine is an awesome open-source tool for handling messy data, transforming data, understanding data, cleaning it up and reconcile it into ready-made form. It’s open-sourced and currently being maintained by Code for Science & Society. It’s a Java-based web power tool that can be used from the comfort and privacy of your computer.
OpenRefine adds spreadsheets of data which can be in various forms like CSV, TSV, Excel, JSON, XML, RDF etc. The data can be added locally from computer, web addresses, Clipboard, database etc

OpenRefine web platform helps in exploring the added data and can analyse data automatically and gain valuable insights from it. It removes inconsistencies in various datasets, understand anomalies in data and helps us to zoom in data.
Another useful feature is how Open Refine, helps in cleaning certain datasets into some format and removing unwanted garbage data. It separates chunks of data, and can handle millions of rows of datasets, and do these tasks at this scale as long as your computer memory supports that. It can also transform data from one form to another.
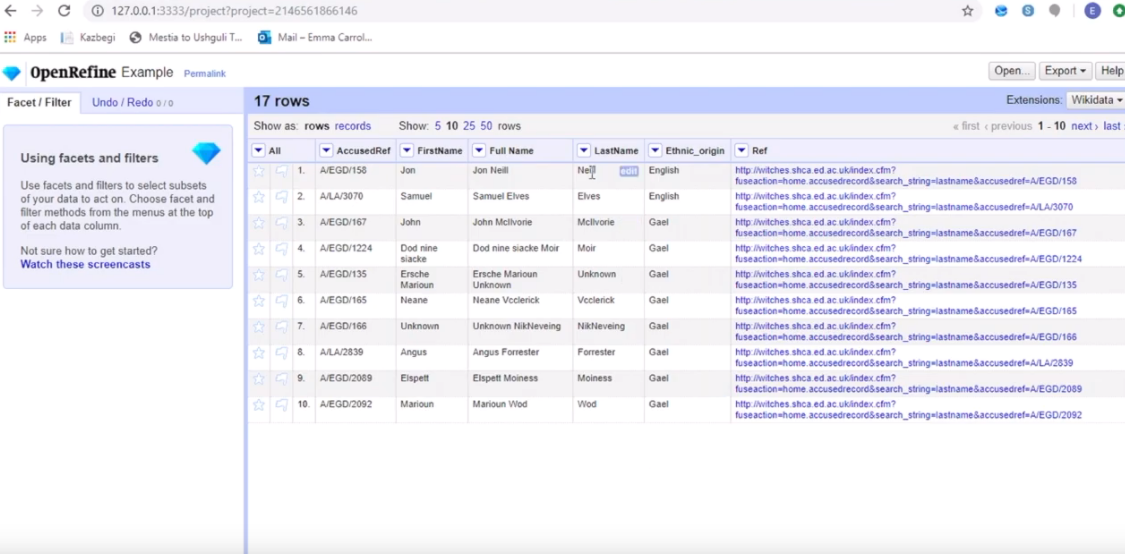
OpenRefine can be used to link and extend your dataset with various web services. This is called reconciling data as a lot of thought process needs to be done, before applying this. Consider the case of a dataset with input text being there in multiple languages. We can use google translate to detect the language which is being in the input text and identify which language each input text belongs to and map to language code.
OpenRefine is used by a lot of professional organisations and users. It’s open-sourced under BSD license and loved by the community with more than 7,500+ Github stars.
So next time when you want to work on any Natural language understanding tasks do check out Semantic Reactor. When handling large scale NLP data which needs to be cleaned, transformed and reconsiled, use OpenRefine.
Thanks everyone, hope you're staying safe and making cool things!
