Last active
December 9, 2017 19:22
-
-
Save markddesimone/3501f9811f00562eb1ba831ced2c90f5 to your computer and use it in GitHub Desktop.
Simple-Train-of-New-Dense-Layers.ipynb not training!
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "code", | |
| "execution_count": 44, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import utils; reload(utils)\n", | |
| "from utils import *\n", | |
| "%matplotlib inline" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Simply Load vgg" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 45, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from vgg16 import Vgg16\n", | |
| "vgg = Vgg16()\n", | |
| "model = vgg.model\n", | |
| "layers = model.layers\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 46, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "path = \"data/redux/sample/\"\n", | |
| "models_path = \"data/redux/models/\"\n", | |
| "train_path = path + \"train/\"\n", | |
| "valid_path = path + \"valid/\"\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Get our batch data" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 48, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "Found 200 images belonging to 2 classes.\n", | |
| "Found 50 images belonging to 2 classes.\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "#get the batches\n", | |
| "batch_size = 64\n", | |
| "train_batches = image.ImageDataGenerator().flow_from_directory(train_path, target_size=(224,224),\n", | |
| " class_mode='categorical', shuffle=True, batch_size=batch_size)\n", | |
| "\n", | |
| "valid_batches = image.ImageDataGenerator().flow_from_directory(valid_path, target_size=(224,224),\n", | |
| " class_mode='categorical', shuffle=True, batch_size=batch_size)\n", | |
| "\n", | |
| "\n", | |
| "num_target_classes = train_batches.nb_class" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Find first Dense layer and remove it and all subsequent layers" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Get the index of the first dense layer...\n", | |
| "first_dense_idx = [index for index,layer in enumerate(layers) if type(layer) is Dense][0]\n", | |
| "\n", | |
| "# Drop this and all subsequent layers\n", | |
| "num_del = len(layers) - first_dense_idx\n", | |
| "for i in range (0, num_del): model.pop()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Make all layers non-trainable" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 47, | |
| "metadata": { | |
| "code_folding": [], | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Set all layers to non-trainable (these are the conv layers)\n", | |
| "for layer in model.layers: layer.trainable=False" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Re-Add new dense layers" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 49, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# add new dense layers... in this example i'm just adding the same architecture of layers as the original vgg\n", | |
| "model.add(Dense(4096, activation='relu'))\n", | |
| "#model.add(Dropout(0.5))\n", | |
| "model.add(Dense(4096, activation='relu'))\n", | |
| "#model.add(Dropout(0.5))\n", | |
| "model.add(Dense(num_target_classes, activation='sigmoid'))\n", | |
| "\n", | |
| "# as i understand it i should now have a model where the convolutional layers are the same as vgg \n", | |
| "# with the same weights. these layers should be non trainable\n", | |
| "# also the dense layers have the same architecture as vgg but with fresh random weights ready to be trained\n", | |
| "\n", | |
| "#I use SGD with a fairly large learning rate as the weights are completely random\n", | |
| "model.compile(optimizer=SGD(lr=0.1), loss='binary_crossentropy', metrics=['accuracy'])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 50, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "____________________________________________________________________________________________________\n", | |
| "Layer (type) Output Shape Param # Connected to \n", | |
| "====================================================================================================\n", | |
| "lambda_4 (Lambda) (None, 3, 224, 224) 0 lambda_input_8[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_40 (ZeroPadding2D) (None, 3, 226, 226) 0 lambda_4[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_40 (Convolution2D) (None, 64, 224, 224) 0 zeropadding2d_40[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_41 (ZeroPadding2D) (None, 64, 226, 226) 0 convolution2d_40[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_41 (Convolution2D) (None, 64, 224, 224) 0 zeropadding2d_41[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "maxpooling2d_16 (MaxPooling2D) (None, 64, 112, 112) 0 convolution2d_41[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_42 (ZeroPadding2D) (None, 64, 114, 114) 0 maxpooling2d_16[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_42 (Convolution2D) (None, 128, 112, 112) 0 zeropadding2d_42[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_43 (ZeroPadding2D) (None, 128, 114, 114) 0 convolution2d_42[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_43 (Convolution2D) (None, 128, 112, 112) 0 zeropadding2d_43[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "maxpooling2d_17 (MaxPooling2D) (None, 128, 56, 56) 0 convolution2d_43[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_44 (ZeroPadding2D) (None, 128, 58, 58) 0 maxpooling2d_17[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_44 (Convolution2D) (None, 256, 56, 56) 0 zeropadding2d_44[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_45 (ZeroPadding2D) (None, 256, 58, 58) 0 convolution2d_44[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_45 (Convolution2D) (None, 256, 56, 56) 0 zeropadding2d_45[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_46 (ZeroPadding2D) (None, 256, 58, 58) 0 convolution2d_45[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_46 (Convolution2D) (None, 256, 56, 56) 0 zeropadding2d_46[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "maxpooling2d_18 (MaxPooling2D) (None, 256, 28, 28) 0 convolution2d_46[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_47 (ZeroPadding2D) (None, 256, 30, 30) 0 maxpooling2d_18[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_47 (Convolution2D) (None, 512, 28, 28) 0 zeropadding2d_47[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_48 (ZeroPadding2D) (None, 512, 30, 30) 0 convolution2d_47[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_48 (Convolution2D) (None, 512, 28, 28) 0 zeropadding2d_48[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_49 (ZeroPadding2D) (None, 512, 30, 30) 0 convolution2d_48[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_49 (Convolution2D) (None, 512, 28, 28) 0 zeropadding2d_49[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "maxpooling2d_19 (MaxPooling2D) (None, 512, 14, 14) 0 convolution2d_49[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_50 (ZeroPadding2D) (None, 512, 16, 16) 0 maxpooling2d_19[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_50 (Convolution2D) (None, 512, 14, 14) 0 zeropadding2d_50[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_51 (ZeroPadding2D) (None, 512, 16, 16) 0 convolution2d_50[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_51 (Convolution2D) (None, 512, 14, 14) 0 zeropadding2d_51[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "zeropadding2d_52 (ZeroPadding2D) (None, 512, 16, 16) 0 convolution2d_51[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "convolution2d_52 (Convolution2D) (None, 512, 14, 14) 0 zeropadding2d_52[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "maxpooling2d_20 (MaxPooling2D) (None, 512, 7, 7) 0 convolution2d_52[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "flatten_4 (Flatten) (None, 25088) 0 maxpooling2d_20[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "dense_46 (Dense) (None, 4096) 102764544 flatten_4[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "dense_47 (Dense) (None, 4096) 16781312 dense_46[0][0] \n", | |
| "____________________________________________________________________________________________________\n", | |
| "dense_48 (Dense) (None, 2) 8194 dense_47[0][0] \n", | |
| "====================================================================================================\n", | |
| "Total params: 119554050\n", | |
| "____________________________________________________________________________________________________\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "model.summary()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Now retrain the model:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 51, | |
| "metadata": { | |
| "collapsed": false, | |
| "scrolled": true | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "Epoch 1/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.5601 - acc: 0.4975 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 2/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 3/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 4/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 5/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 6/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 7/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 8/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 9/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 10/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 11/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 12/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 13/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 14/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 15/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 16/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 17/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 18/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 19/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 20/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 21/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 22/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 23/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 24/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 25/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 26/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 27/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 28/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 29/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 30/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 31/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 32/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 33/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 34/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 35/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 36/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 37/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 38/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 39/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 40/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 41/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 42/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 43/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 44/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 45/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 46/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 47/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 48/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 49/50\n", | |
| "200/200 [==============================] - 6s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n", | |
| "Epoch 50/50\n", | |
| "200/200 [==============================] - 7s - loss: 7.9712 - acc: 0.5000 - val_loss: 7.9712 - val_acc: 0.5000\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "<keras.callbacks.History at 0x7f68d21834d0>" | |
| ] | |
| }, | |
| "execution_count": 51, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "model.fit_generator(train_batches, samples_per_epoch=train_batches.nb_sample, nb_epoch=50,\n", | |
| " validation_data=valid_batches, nb_val_samples=valid_batches.nb_sample)\n", | |
| "\n", | |
| "# i get the following output...!" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Note accuracy is 0.5! what is going on?!" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [] | |
| } | |
| ], | |
| "metadata": { | |
| "kernelspec": { | |
| "display_name": "Python [conda root]", | |
| "language": "python", | |
| "name": "conda-root-py" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 2 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython2", | |
| "version": "2.7.12" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 1 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Solved
So the problem was the learning rate. It was too high. I had to reduce the learning rate to 0.001 or better still 0.0001 to get good results
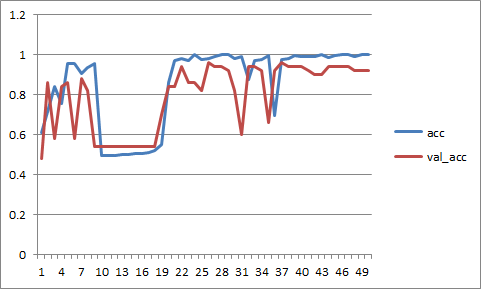
Here are the 50 iterations with lr=0.001
note the convergence is jumping around

0.0001 give a better result and is overfitting the sample data set as expected: