OpenAddresses is a free and open global address collection. This gist is a record of an attempt to compare OA data density with worldwide population estimates. Read an explanatory blog post with more information about the code and data here.
Last active
February 15, 2016 22:23
-
-
Save migurski/f5eead5bd512a8f0debe to your computer and use it in GitHub Desktop.
Testing Compare G-Econ.ipynb
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Start with all our imports. `osgeo` can be found in the package `python-gdal` on Ubuntu. More information from [osgeo.org](https://trac.osgeo.org/gdal/wiki/GdalOgrInPython)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 1, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from __future__ import division\n", | |
| "\n", | |
| "from zipfile import ZipFile\n", | |
| "from collections import defaultdict\n", | |
| "from csv import DictReader\n", | |
| "from re import compile\n", | |
| "from math import floor\n", | |
| "from osgeo import ogr\n", | |
| "import json" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Prepare Population Data" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "We’re using two datasets of countries, which have slightly mis-matched names. `NE-missing.csv` is a supplemental file of country name / ISO code mappings that will make it possible to fully map Natural Earth and G-Econ data. Store a mapping from name to ISO code in `gecon_iso_a2s`." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 2, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "with open('NE-missing.csv') as file:\n", | |
| " gecon_iso_a2s = {r['Name']: r['ISO A2'] for r in DictReader(file)}" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Now we load Natural Earth data, included as [part of OpenAddresses under `openaddr/geodata`](https://github.com/openaddresses/machine/tree/master/openaddr/geodata)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 3, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "ogr.UseExceptions()\n", | |
| "\n", | |
| "ds = ogr.Open('openaddr/geodata/ne_50m_admin_0_countries-54029.shp')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Make two dictionaries of Natural Earth features, keyed on country names and ISO codes." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 4, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def load_ne_feature_dicts(ds):\n", | |
| " ''' Return two dictionaries: features by name, and by ISO code.\n", | |
| " '''\n", | |
| " features = list(ds.GetLayer(0))\n", | |
| "\n", | |
| " name_features = {f.GetField('name').decode('utf8'): f for f in features}\n", | |
| " iso_a2_features = {f.GetField('iso_a2').decode('utf8'): f for f in features}\n", | |
| " \n", | |
| " return name_features, iso_a2_features\n", | |
| "\n", | |
| "ne_country_name_features, ne_country_iso_a2_features = load_ne_feature_dicts(ds)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Make a dictionary of G-Econ data, keyed on tuple of ISO code, latitude, and longitude. G-Econ data [comes from `gecon.yale.edu`](http://gecon.yale.edu/data-and-documentation-g-econ-project), in the form of an Excel spreadsheet with rows for square degrees per country. G-Econ includes other data such as economic output, soil type, availability of water, and climate, but we will be using only the 2005 population counts from column `POPGPW_2005_40`." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 5, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def load_gecon_dict(ne_country_name_features, ne_country_iso_a2_features, gecon_iso_a2s):\n", | |
| " ''' Return a dictionary of G-Econ squares by (ISO code, lat, lon).\n", | |
| " '''\n", | |
| " iso_a2_squares = dict()\n", | |
| "\n", | |
| " with open('GEcon40-cut.csv') as file:\n", | |
| " for row in DictReader(file):\n", | |
| " south, west = int(row['LAT']), int(row['LONGITUDE'])\n", | |
| " \n", | |
| " feature = None\n", | |
| " \n", | |
| " if row['COUNTRY'] in ne_country_name_features:\n", | |
| " feature = ne_country_name_features[row['COUNTRY']]\n", | |
| " elif row['COUNTRY'] in gecon_iso_a2s:\n", | |
| " if gecon_iso_a2s[row['COUNTRY']] in ne_country_iso_a2_features:\n", | |
| " feature = ne_country_iso_a2_features[gecon_iso_a2s[row['COUNTRY']]]\n", | |
| " \n", | |
| " iso_a2 = feature and feature.GetField('iso_a2')\n", | |
| " \n", | |
| " if not iso_a2:\n", | |
| " continue\n", | |
| " \n", | |
| " iso_a2_squares[iso_a2, south, west] = row\n", | |
| " row.update(population=float(row['POPGPW_2005_40'] or '0'), area=float(row['AREA']))\n", | |
| " \n", | |
| " return iso_a2_squares\n", | |
| "\n", | |
| "gecon_iso_a2_squares = load_gecon_dict(ne_country_name_features, ne_country_iso_a2_features, gecon_iso_a2s)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Count Addresses" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Make another dictionary of OpenAddresses data, with identical (ISO, lat, lon) keys to G-Econ data. Zip files are available at http://results.openaddresses.io. Here we are using just the US West states to get a quick result. Iterate over each zipped CSV file and note the location of the address point in a grid square.\n", | |
| "\n", | |
| "This is the slow part." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 6, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "Populated 454 squares\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "def load_openaddr_squares():\n", | |
| " ''' Return a dictionary of OpenAddresses squares by (ISO code, lat, lon).\n", | |
| " '''\n", | |
| " iso_a2_squares = defaultdict(lambda: 0)\n", | |
| "\n", | |
| " zip = ZipFile('/tmp/openaddr-collected-us_west.zip')\n", | |
| " pat = compile(r'^(?P<iso_a2>\\w\\w)[/\\-].+\\.csv$')\n", | |
| "\n", | |
| " for name in sorted(zip.namelist()):\n", | |
| " match = pat.match(name)\n", | |
| " \n", | |
| " if not match:\n", | |
| " continue\n", | |
| " \n", | |
| " iso_a2 = match.group('iso_a2').upper()\n", | |
| " file = zip.open(name)\n", | |
| " \n", | |
| " for row in DictReader(file):\n", | |
| " try:\n", | |
| " lat, lon = float(row['LAT']), float(row['LON'])\n", | |
| " except ValueError:\n", | |
| " # possible empty lat/lon in openaddresses collection\n", | |
| " continue\n", | |
| " else:\n", | |
| " key = iso_a2, int(floor(lat)), int(floor(lon))\n", | |
| " iso_a2_squares[key] += 1\n", | |
| " \n", | |
| " print 'Populated', len(iso_a2_squares), 'squares'\n", | |
| " return iso_a2_squares\n", | |
| "\n", | |
| "openaddr_iso_a2_squares = load_openaddr_squares()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Output" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Now build a GeoJSON dictionary from the OpenAddresses grid squares.\n", | |
| "\n", | |
| "Each feature includes these properties:\n", | |
| "- `iso_a2`: ISO 2-letter country code.\n", | |
| "- `addr`: Number of address points in this country square.\n", | |
| "- `pop`: 2005 population count for this country square.\n", | |
| "- `app`: Addresses-per-person in this country square.\n", | |
| "- `ppa`: People-per-address in this country square." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 13, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "features = list()\n", | |
| "\n", | |
| "for (key, count) in openaddr_iso_a2_squares.items():\n", | |
| " if key not in gecon_iso_a2_squares:\n", | |
| " # likely null island\n", | |
| " continue\n", | |
| " \n", | |
| " gecon = gecon_iso_a2_squares[key]\n", | |
| " \n", | |
| " iso_a2, S, W = key\n", | |
| " N, E = S + 1, W + 1\n", | |
| " geom = dict(type='Polygon', coordinates=[[[W, S], [E, S], [E, N], [W, N], [W, S]]])\n", | |
| " prop = dict(iso_a2=iso_a2, addr=count, pop=gecon['population'], area=gecon['area'])\n", | |
| " prop.update(ppa=None if (prop['addr'] == 0) else prop['pop'] / prop['addr'])\n", | |
| " prop.update(app=None if (prop['pop'] == 0) else prop['addr'] / prop['pop'])\n", | |
| " feat = dict(type='Feature', geometry=geom, properties=prop)\n", | |
| " features.append(feat)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Finally, dump everything to GeoJSON." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 14, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "with open('compare-gecon.geojson', 'w') as file:\n", | |
| " json.dump(dict(type='FeatureCollection', features=features), file)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Results\n", | |
| "\n", | |
| "Renderings show addresses per person for U.S. western states and Europe:\n", | |
| "\n", | |
| "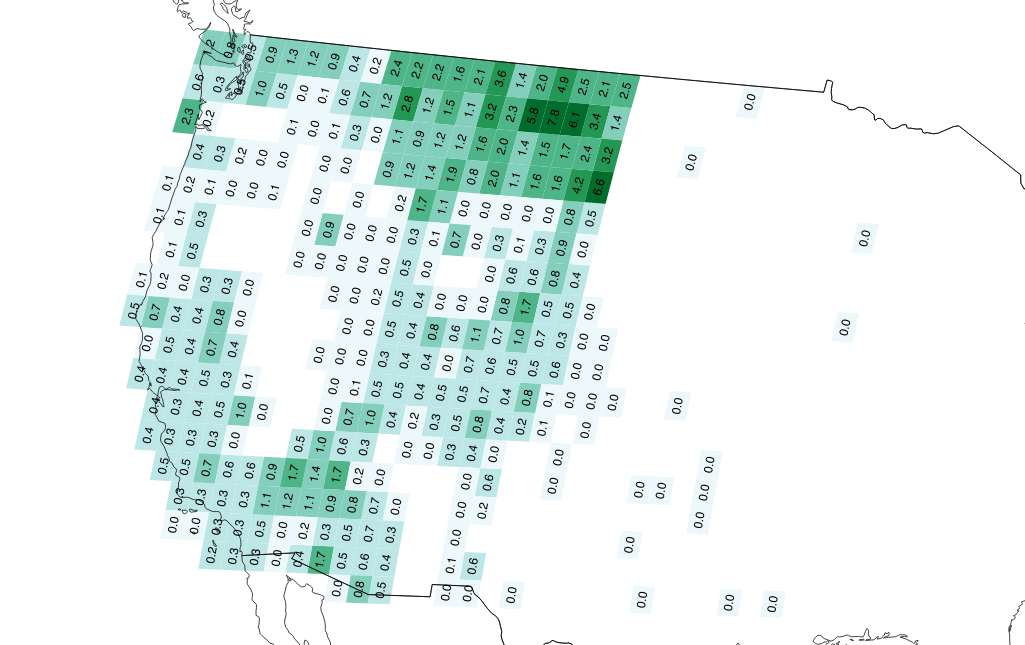\n", | |
| "\n", | |
| "\n", | |
| "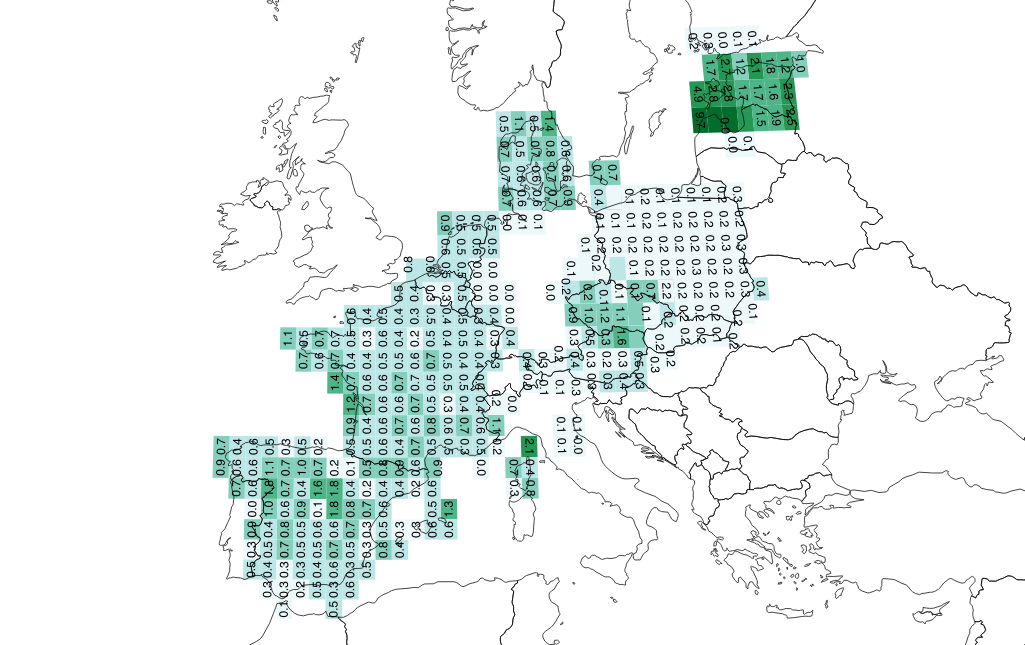" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "kernelspec": { | |
| "display_name": "Python 2", | |
| "language": "python", | |
| "name": "python2" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 2 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython2", | |
| "version": "2.7.10" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 0 | |
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Name | ISO A2 | |
|---|---|---|
| Sao Tome and Principe | ST | |
| Bouvet I. | BV | |
| Serbia and Montenegro | RS | |
| French Polynesia | PF | |
| Bosnia&Herzegovina | BA | |
| Midway Is. | MI | |
| Gibraltar | GI | |
| South Georgia & the South Sandwich Is. | GS | |
| Laos | LA | |
| Northern Mariana Is. | MP | |
| Cote d'Ivoire | CI | |
| Czech Republic | CZ | |
| Guadeloupe | GP | |
| Kyrgyztan | KG | |
| Virgin Is. | ||
| Tuvalu | TV | |
| Antarctica | AQ | |
| St. Vincent and the Grenadines | VC | |
| Solomon Islands | SB | |
| Marshall Islands | MH | |
| Christmas I. | CX | |
| Tokelau | TK | |
| Martinique | MQ | |
| Netherlands Antilles | AN | |
| Dominican Republic | DO | |
| St. Pierre & Miquelon | PM | |
| Baker and Howland Island | ||
| Johnston Atoll | ||
| Mayotte | YT | |
| Guinea Bissau | GW | |
| Central African Republic | CF | |
| Bailiwick of Jersey | JE | |
| British Indian Ocean Territory | IO | |
| Heard I. & McDonald Is. | HM | |
| Federated State of Micronesia | FM | |
| Wallis and Futuna | WF | |
| Timor Leste | TP | |
| French Guiana | GF | |
| St. Lucia | LC | |
| Bailiwick of Guernsey | GG | |
| North Korea | KP | |
| Wake I. | WK | |
| West Bank and Gaza | PS | |
| Macau | MO | |
| Equatorial Guinea | GQ | |
| Jan Mayen | ||
| Jarvis I. | ||
| Vatican City | VA | |
| Faroe Is. | FO | |
| French Southern & Antarctic Lands | TF | |
| Svalbard | ||
| Norfolk I. | NF | |
| Antigua and Barbuda | AG | |
| Turks & Caicos Is. | TC | |
| Reunion | RE | |
| Cocos Is. | CC | |
| South Korea | KR | |
| Democratic Republic of Congo | CD |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment