If you accidentally landed on this page looking for the original (Franz) Kafka, however unlikely it may seem, I have nothing to offer to you, except this wonderful quote.
By believing passionately in something that still does not exist, we create it. The nonexistent is whatever we have not sufficiently desired -- Franz Kafka
But if you came here for Apache Kafka, I assume you already know what Kafka is. But for the uninitiated, here is a fun illustrated introduction to Kafka, aptly named Gently Down The Stream. But don't stop there, read a more serious introduction here.
With that out of the way, lets get straight to the point of this this post. We recently had the opportunity of deploying self managed Kafka clusters at scale for our multiple customers as part of migrating them from On-premise / AWS environments to Google Cloud Platform. This post is a how to guide on deploying a highly available Kafka (version 3.0.0) cluster with Zookeeper ensemble on Compute Engine.
We are going to deploy this Kafka cluster along with a Zookeeper ensemble. I am sure some of you are wondering why Kafka still needs a keeper. Zookeeper has been used to store Kafka cluster's metadata. To avoid external metadata management and simplify Kafka clusters, the future versions of Kafka are not going to need an external Zookeeper for metadata management, instead - Kafka will internally manage metadata quorum using KRaft(Kafka Raft Metadata Mode). Unfortunately, KRaft is not production ready yet, so for this post - we will go with Zookeeper.
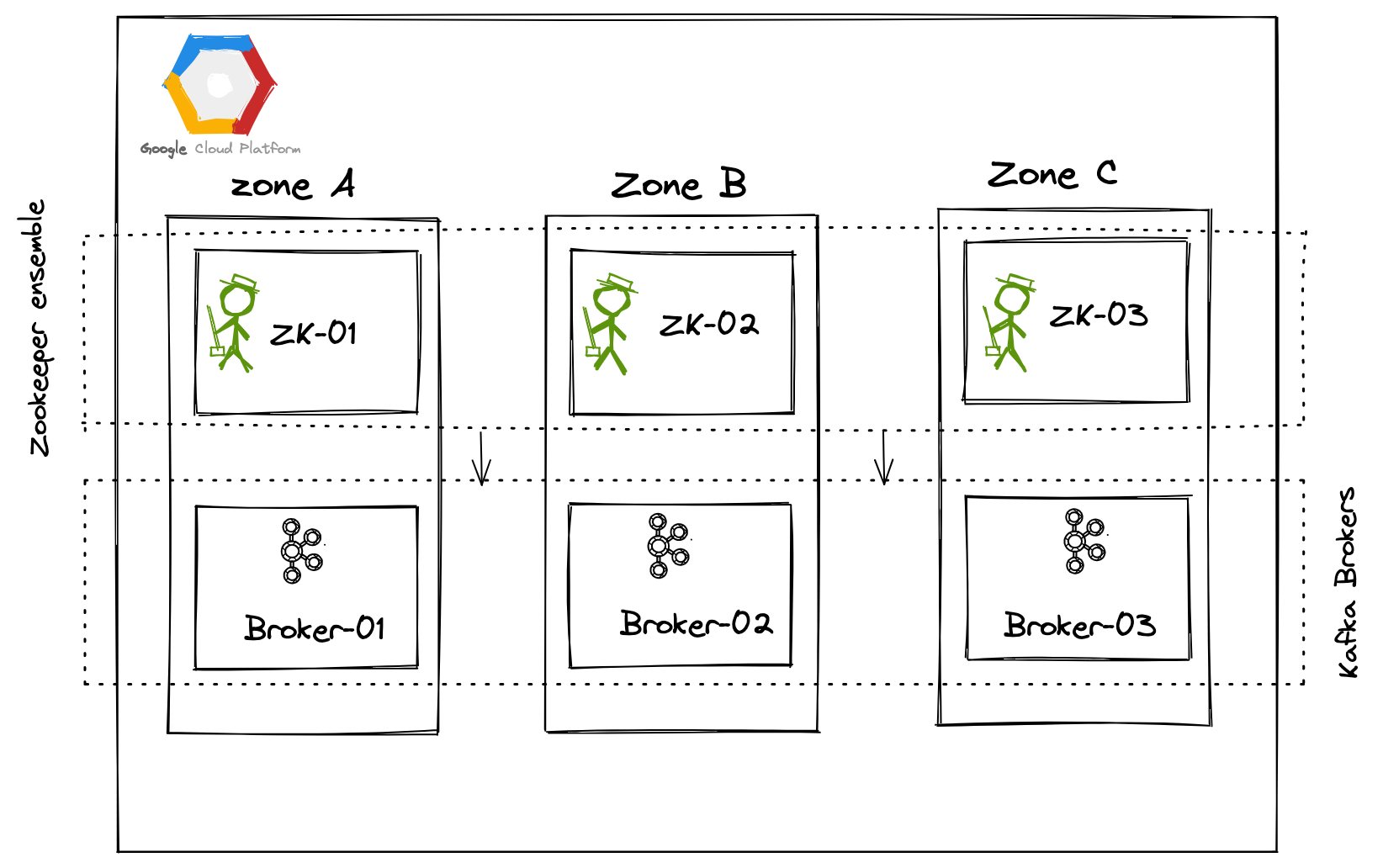
We will deploy a highly available Kafka cluster in Mumbai region on GCP. We will configure a 3 node Zookeeper ensemble (or cluster) spread across 3 availability zones and configure 3 Kafka brokers (you can configure more, depending on your throughput requirements)
| Node | Zone | IP |
|---|---|---|
| zk-01 | asia-south1-a | 10.10.0.10 |
| zk-02 | asia-south1-b | 10.10.0.11 |
| zk-03 | asia-south1-b | 10.10.0.12 |
| kafka-broker-01 | asia-south1-a | 10.10.0.20 |
| kafka-broker-02 | asia-south1-b | 10.10.0.21 |
| kafka-broker-03 | asia-south1-c | 10.10.0.22 |
Let's get started!
If you already have a VPC and subnets, feel free to skip this section. If you don't have one already, follow along.
Configure your project and region in gcloud
gcloud auth login
gcloud config set project YOUR-PROJECT-NAME
gcloud config set compute/region asia-south1
If you already have a VPC, you can skip this part. For the sake of this guide, let's create a simple VPC and one subnet. In production, you would ideally provision these in a private subnet dedicated for database layer.
gcloud compute networks create kafka-cluster-vpc --subnet-mode custom
gcloud compute networks subnets create db-sn \
--network kafka-cluster-vpc \
--range 10.10.0.0/24
We will use the network tag kafka to enable access between kafka and zookeeper nodes. Let's create a firewall rule. This is rather permissive, you might want to open only necessary ports in production.
gcloud compute firewall-rules create kafka-cluster-vpc-allow-kafka-zookeeper \
--description="Allow traffic between Kafka brokers and Zookeeper nodes" \
--direction=INGRESS --priority=1000 --network=kafka-cluster-vpc --action=ALLOW \
--rules=all --source-tags=kafka \
--target-tags=kafka
# If you want to SSH to your VMs via Identity Aware Proxy (which is a good practice), whitelist IaP
gcloud compute firewall-rules create allow-ssh-ingress-from-iap \
--direction=INGRESS \
--action=allow \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--network=kafka-cluster-vpc
Let's provision a VM and configure Zookeeper on it. While launching these VMs, we will assign the network tag kafka so that the firewall rule we created above comes into effect and allows traffic between these VMs.
gcloud compute instances create zk-01 \
--async \
--boot-disk-size 50GB \
--can-ip-forward \
--image-family ubuntu-2004-lts \
--image-project ubuntu-os-cloud \
--machine-type e2-small \
--private-network-ip 10.10.0.10 \
--scopes compute-rw,storage-ro,service-management,service-control,logging-write,monitoring \
--subnet db-sn \
--tags kafka \
--labels=application=zookeeper \
--zone=asia-south1-aVerify if the VM is up and running
gcloud compute instances list --filter="tags.items=kafka"
SSH to this VM. Install and configure Zookeeper.
gcloud beta compute ssh zk-01 --tunnel-through-iap --zone=asia-south1-a
Install JDK. After installing JDK, it's important to set the Java heap size in production environments. This will help avoid swapping, which will degrade Zookeeper's performance. Refer the Zookeeper administration guide here
sudo apt update
sudo apt install default-jdk -yAdd a user to run Zookeeper services and grant relevant permissions, we will go with zkadmin
sudo useradd zkadmin -m && sudo usermod --shell /bin/bash zkadmin
#set a password for zkadmin
sudo passwd zkadmin
# Add zkadmin user to sudoers
sudo usermod -aG sudo zkadmin
#switch to zkadmin user for the rest of the setup
su -l zkadmin
sudo mkdir -p /data/zookeeper
sudo chown -R zkadmin:zkadmin /data/zookeeper
cd /opt
sudo wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
sudo tar -xvf apache-zookeeper-3.6.3-bin.tar.gz
sudo chown zkadmin:zkadmin -R apache-zookeeper-3.6.3-bin
sudo ln -s apache-zookeeper-3.6.3-bin zookeeper
sudo chown -h zkadmin:zkadmin /opt/zookeeperTime to configure Zookeeper. Let's make a config file.
vi /opt/zookeeper/conf/zoo.cfgAdd the following configuration.
tickTime=2000
dataDir=/data/zookeeper
clientPort=2181
initLimit=10
syncLimit=5We can quickly verify if everything went well so far by starting zookeeper
cd /opt/zookeeper && /opt/zookeeper/bin/zkServer.sh start 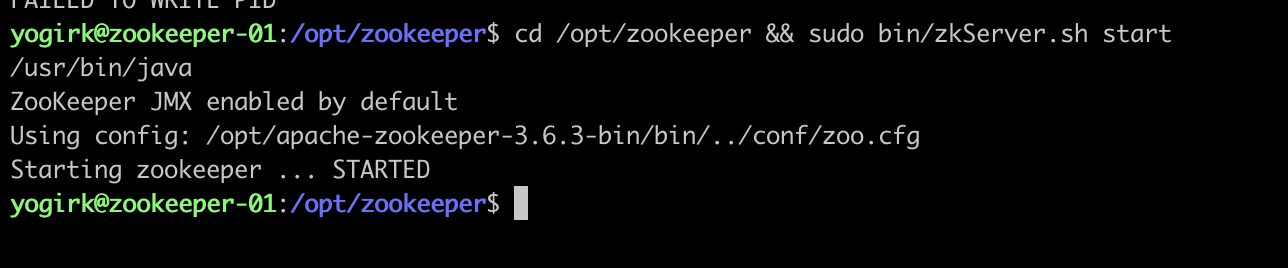
You can connect and verify
bin/zkCli.sh -server 127.0.0.1:2181You should see something like this
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: 127.0.0.1:2181(CONNECTED) 0]let's stop Zookeeper and proceed with the rest of the setup
sudo bin/zkServer.sh stopLet's create a systemd unit file so that we can manage Zookeeper as a service - sudo vi /etc/systemd/system/zookeeper.service
Add the following
[Unit]
Description=Zookeeper Daemon
Documentation=http://zookeeper.apache.org
Requires=network.target
After=network.target
[Service]
Type=forking
WorkingDirectory=/opt/zookeeper
User=zkadmin
Group=zkadmin
ExecStart=/opt/zookeeper/bin/zkServer.sh start /opt/zookeeper/conf/zoo.cfg
ExecStop=/opt/zookeeper/bin/zkServer.sh stop /opt/zookeeper/conf/zoo.cfg
ExecReload=/opt/zookeeper/bin/zkServer.sh restart /opt/zookeeper/conf/zoo.cfg
TimeoutSec=30
Restart=on-failure
[Install]
WantedBy=default.targetEnable the service << REVIEW THIS >>
sudo systemctl enable zookeeper.serviceNow that we have tested that Zookeeper on one instance, we can create an image out of it and use it to spin up 2 more nodes. Let's make an image.
gcloud beta compute machine-images create zookeeper-machine-image --source-instance zk-01 --source-instance-zone asia-south1-aWe can now use this image to create two more VMs - zk-02 and zk-03 in ap-south1-b and ap-south1-c zones respectively. Let's create these VMs
#Create Node 2
gcloud beta compute instances create zk-02 \
--source-machine-image zookeeper-machine-image \
--zone asia-south1-b \
--machine-type e2-small \
--private-network-ip 10.10.0.11 \
--subnet db-sn \
--tags kafka \
--labels=application=zookeeper
#Create Node 3
gcloud beta compute instances create zk-03 \
--source-machine-image zookeeper-machine-image \
--zone asia-south1-c \
--machine-type e2-small \
--private-network-ip 10.10.0.12 \
--subnet db-sn \
--tags kafka \
--labels=application=zookeeper Once all the zookeeper nodes are up and running, We will create a myid file in each of the zookeeper nodes. The myid file consists of a single line containing only the text of that machine's id. So myid of server 1 would contain the text "1" and nothing else. The id must be unique within the Zookeeper ensemble and should have a value between 1 and 255.
gcloud beta compute ssh zk-01 \
--tunnel-through-iap \
--zone=asia-south1-a \
--command 'echo "1" | sudo tee /data/zookeeper/myid && sudo chown -R zkadmin:zkadmin /data/zookeeper'
gcloud beta compute ssh zk-02 \
--tunnel-through-iap \
--zone=asia-south1-b \
--command 'echo "2" | sudo tee /data/zookeeper/myid && sudo chown -R zkadmin:zkadmin /data/zookeeper'
gcloud beta compute ssh zk-03 \
--tunnel-through-iap \
--zone=asia-south1-c \
--command 'echo "3" | sudo tee /data/zookeeper/myid && sudo chown -R zkadmin:zkadmin /data/zookeeper'Let's now edit the zookeeper configuration file on all nodes to form the cluster quorum. We will add the hostname and ports of each node in the configuration file. You can find the FQDN of your zookeeper nodes by running the command hostname -a, usually it will be in the following format - [SERVER-NAME].[ZONE].[PROJECT-NAME].internal. Example: zk-01.asia-south1-a.c.cloudside-academy.internal. If your zookeeper cluster is single zone deployment, you can simply resolve using the VM name - ping zk-03 etc. Since our deployment is multi zone for availability reasons, lets use a FQDN. If you want to keep things simpler, you may add the static internal IP of each node instead of the domain name.
SSH to each zookeeper node. On each node, change to zkadmin user - su -l zkadmin and open /opt/zookeeper/conf/zoo.cfg. The config file on all nodes should look like this:
tickTime=2000
dataDir=/data/zookeeper
clientPort=2181
initLimit=10
syncLimit=5
server.1=zk-01.asia-south1-a.c.cloudside-academy.internal:2888:3888
server.2=zk-02.asia-south1-b.c.cloudside-academy.internal:2888:3888
server.3=zk-03.asia-south1-c.c.cloudside-academy.internal:2888:3888
4lw.commands.whitelist=*we have added 4lw.commands.whitelist=* config option to whitelist commands like stat, ruok, conf, isro.
We are now ready to start the cluster. Let's enable zookeeper.service on all nodes and also start it.
gcloud beta compute ssh zk-01 \
--tunnel-through-iap \
--zone=asia-south1-a \
--command 'sudo systemctl enable zookeeper.service && sudo systemctl start zookeeper.service'
gcloud beta compute ssh zk-02 \
--tunnel-through-iap \
--zone=asia-south1-b \
--command 'sudo systemctl enable zookeeper.service && sudo systemctl start zookeeper.service'
gcloud beta compute ssh zk-03 \
--tunnel-through-iap \
--zone=asia-south1-c \
--command 'sudo systemctl enable zookeeper.service && sudo systemctl start zookeeper.service'You may now connect to one of the zookeeper nodes and check the cluster status.
gcloud beta compute ssh zk-01 \
--tunnel-through-iap \
--zone=asia-south1-a \
--command 'echo stat | nc localhost 2181 | grep Mode'
gcloud beta compute ssh zk-02 \
--tunnel-through-iap \
--zone=asia-south1-b \
--command 'echo stat | nc localhost 2181 | grep Mode'
gcloud beta compute ssh zk-03 \
--tunnel-through-iap \
--zone=asia-south1-c \
--command 'echo stat | nc localhost 2181 | grep Mode'You will see the status as either leader or follower for each node
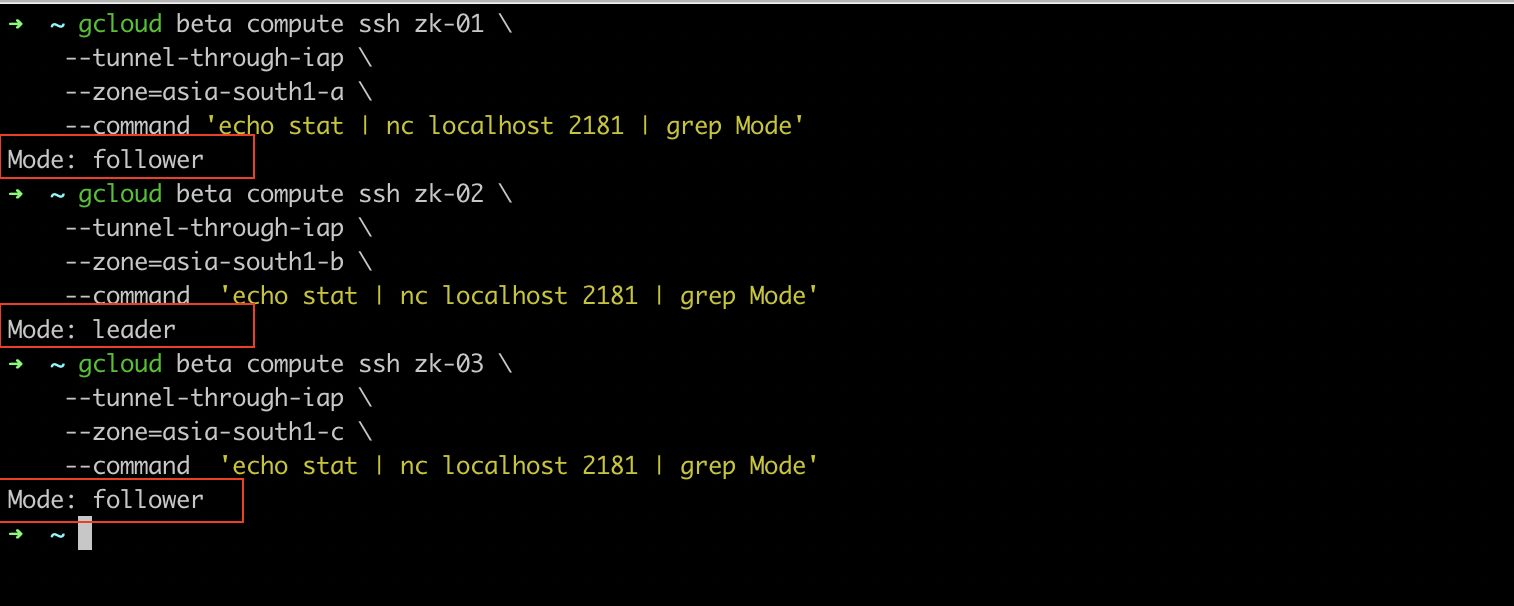
Zookeeper ensemble is up and running, so let's move on to configuring Kafka brokers. We will configure broker on one VM, and from it's image, spin up two more Kafka brokers.
You might want to choose the right instance type in production and also attach an SSD disk for storage. For this guide, we will go ahead with e2-small VM. Let's reserve three internal static IPs for our Kafka brokers
gcloud compute addresses create kafka-broker-01-ip \
--region asia-south1 --subnet db-sn --addresses 10.10.0.20
gcloud compute addresses create kafka-broker-02-ip \
--region asia-south1 --subnet db-sn --addresses 10.10.0.21
gcloud compute addresses create kafka-broker-03-ip \
--region asia-south1 --subnet db-sn --addresses 10.10.0.22
```
Create a VM
```bash
gcloud compute instances create kafka-broker-01 \
--async \
--boot-disk-size 50GB \
--can-ip-forward \
--image-family ubuntu-2004-lts \
--image-project ubuntu-os-cloud \
--machine-type e2-small \
--private-network-ip 10.10.0.20 \
--scopes compute-rw,storage-ro,service-management,service-control,logging-write,monitoring \
--subnet db-sn \
--tags kafka \
--labels=application=kafka \
--zone=asia-south1-aSSH to the VM and start setting up Kafka.
gcloud beta compute ssh kafka-broker-01 \
--tunnel-through-iap \
--zone=asia-south1-aCreate a user for running Kafka services and download binaries
## install jdk
sudo apt update && sudo apt install default-jdk -y
# Add a user
sudo useradd kafka -m && sudo usermod --shell /bin/bash kafka
#set a password for kafka
sudo passwd kafka
# Add kafka user to sudoers
sudo usermod -aG sudo kafka
# make a dir
sudo mkdir -p /data/kafka && sudo mkdir -p /data/kafka/logs
# Download binaries
sudo wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
sudo tar -xvzf kafka_2.13-3.0.0.tgz --strip 1
sudo chown -R kafka:kafka /data/kafkaYou can use the following configuration file to begin with.
[Gist Link][https://gist.github.com/rk-cloudside/6831b027bf3b83623a2606e90dc35c90]
For this first kafka broker, we will assign broker.id as 0 and you can add more brokers and increment the id. use the internal IP of the broker VM to configure advertised.listeners, and listeners. Finally, configure zookeeper.connect to include all zookeeper nodes (use either FQDNs or IP addresses)
Move the existing existing sample config file and create a new config with the contents from above gist
sudo mv /data/kafka/config/server.properties /data/kafka/config/server.properties-OLD
vi /data/kafka/config/server.properties #use above config from the gistLet's create a systemd file - sudo vi /etc/systemd/system/kafka.service
Add the following:
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/data/kafka/bin/kafka-server-start.sh /data/kafka/config/server.properties > /data/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetStart the service - systemctl start kafka
You can now connect to one of the Zookeeper nodes and verify that the kafka broker with id 0 shows up.
#SSH to any zookeeper node and cd /opt/zookeeper
bin/zkCli.sh -server 127.0.0.1:2181After connecting, run
ls /brokers/idsYou should see this
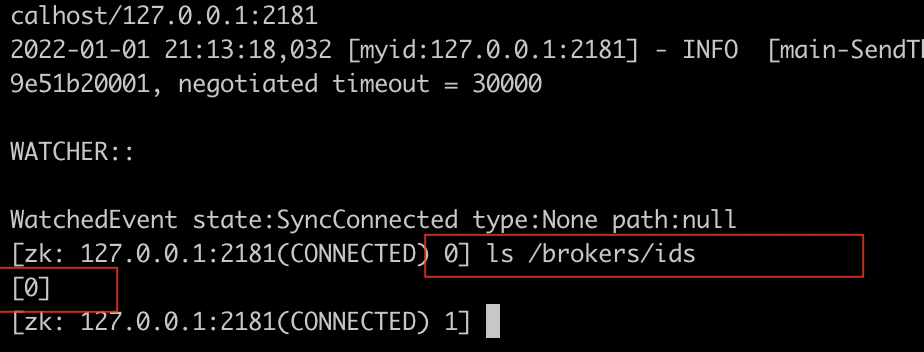
We are now ready to make an image out of this VM and use it to spin up more Kafka broker nodes. Let's make an image
gcloud beta compute machine-images create kafka-machine-image --source-instance kafka-broker-01 --source-instance-zone asia-south1-aLet's now create kafka-broker-02, kafka-broker-03 VMs in asia-south1-b, asia-south1-c zones respectively.
#Create broker 2
gcloud beta compute instances create kafka-broker-02 \
--source-machine-image kafka-machine-image \
--zone asia-south1-b \
--machine-type e2-small \
--private-network-ip 10.10.0.21 \
--subnet db-sn \
--tags kafka \
--labels=application=kafka
#Create broker 3
gcloud beta compute instances create kafka-broker-03 \
--source-machine-image kafka-machine-image \
--zone asia-south1-c \
--machine-type e2-small \
--private-network-ip 10.10.0.22 \
--subnet db-sn \
--tags kafka \
--labels=application=kafka Once these VMs are online, all you need to do is to SSH to these VMs and change the following properties in configuration file - vi /data/kafka/config/server.properties
For kafka-broker-02 VM
broker.id=1
listeners=PLAINTEXT://10.10.0.21:9092
advertised.listeners=PLAINTEXT://10.10.0.21:9092For kafka-broker-03 VM
broker.id=2
listeners=PLAINTEXT://10.10.0.22:9092
advertised.listeners=PLAINTEXT://10.10.0.22:9092Since we are launching these VMs from an image, and there might be some data left which belonged to Broker 0, we have to cleanup the data (log) directories before we start the service.
sudo rm -rf /data/kafka/logs/ && systemctl start kafkaYou can now finally verify the status of all brokers in one of the zookeeper nodes

Congratulations! you have now setup Kafka the hard way on Google Compute Engine. Let's cleanup now.
# Delete VMs
gcloud compute instances delete zk-01 kafka-broker-01 --zone=asia-south1-a
gcloud compute instances delete zk-02 kafka-broker-02 --zone=asia-south1-b
gcloud compute instances delete zk-03 kafka-broker-03 --zone=asia-south1-c
# Delete Images
gcloud beta compute machine-images delete zookeeper-machine-image kafka-machine-image
# Delete FW rules
gcloud compute firewall-rules delete kafka-cluster-vpc-allow-kafka-zookeeper
# Delete IP addresses
gcloud compute addresses delete kafka-broker-01-ip kafka-broker-02-ip kafka-broker-03-ip
# Delete subnet and VPC
gcloud compute networks subnets delete db-sn
gcloud compute networks delete kafka-cluster-vpc
Hope you found this guide useful. If you need help running self managed kafka at scale on Google Compute Engine, reach out to us! Happy stream processing :)