Aujourd'hui, j'ai choisi de vous montrer comment mettre en place un pipeline d'intégration continue (CI) et de déploiement continu (CD) pour vos applications Angular, avec GitHub Actions et Netlify.
« GitHub Actions est une API proposée par GitHub : orchestrer n'importe quel workflow, basé sur n'importe quel événement, tandis que GitHub gère l'exécution, fournit un retour d'information riche et sécurise chaque étape du processus. Avec GitHub Actions, les flux de travail et les étapes ne sont que du code dans un référentiel, vous pouvez donc créer, partager, réutiliser et adapter vos pratiques de développement logiciel ». Source : blog github
« Netlify a pour but de simplifier la mise en production et de fournir tous les outils modernes nécessaires à des stratégies de déploiement agiles à tout un chacun, sans avoir besoin pour cela d’être un devops confirmé ». Source : jamstatic.
Ces deux outils sont faciles d'accès et fréquemment utilisés, c'est pour cela que j'ai fait le choix de les utiliser pour ce tutoriel.
Mais avant de passer à la pratique, (re)voyons ensemble ce qu'est le DevOps, l'intégration continue et le déploiement continu.
Avec le passage au numérique d’un grand nombre d’applications et l’accroissement de la demande, les entreprises du numérique ont besoin d’industrialiser leur processus de développement d’applications. Face au besoin croissant du nombre de développeurs et d’ingénieurs logiciels, les agences web, les éditeurs de logiciels et les sociétés de services sont obligées d’optimiser leurs méthodes de travail.
Il est devenu commun que l'on demande aux développeurs d'être multi-casquette et d'endosser le rôle de DevOps, en support aux Ops dans leurs équipes ou pour palier au besoin croissant d'automatisation de leur processus.
Depuis quelques années le mouvement DevOps tend à promouvoir l’automatisation et le suivi « de toutes les étapes de la création d'un logiciel, depuis le développement, l'intégration, les tests, la livraison jusqu'au déploiement, l'exploitation et la maintenance des infrastructures ». Source : Devops, Wikipédia
Le DevOps peut aussi être décrit comme une approche cherchant à unifier le développement d’application (dev) et l’administration des infrastructures informatiques (ops).
L’intégration continue et le déploiement continu sont de plus en plus présents ces dernières années car ils facilitent la mise en place du mouvement DevOps.
« L'intégration continue est un ensemble de pratiques utilisées en génie logiciel consistant à vérifier à chaque modification de code source que le résultat des modifications ne produit pas de régression dans l'application développée. L'intégration continue est de plus en plus utilisée en entreprise afin d'améliorer la qualité du code et du produit final. » Source : Intégration continue, Wikipédia
La vérification à chaque modification du code source passe généralement par un outil dédié (ici GitHub). Lors de la détection de changement sur le code source, le logiciel va exécuter un processus appelé pipeline (avec GitHub nous parlerons de workflow). On parle de pipeline d’intégration continue. Un pipeline en intégration continue est une suite de tâches à exécuter :
- l'analyse statique est l’ensemble de méthodes permettant d’obtenir des informations sur le code source. L’analyse statique permet de vérifier les erreurs de programmation ou par exemple la complexité du code.
- Les tests pré-déploiement sont tous les types de tests qui ne nécessitent pas le déploiement du code sur un serveur. Cette phase permet une grande couverture du code et est obligatoire en intégration continue. Les tests ne sont pas les seuls prérequis de l'intégration continue. L'une des règles les plus importantes est que lorsque le pipeline échoue, la résolution du problème est plus prioritaire que toute autre tâche.
- Le packaging est une étape qui n’est pas obligatoire pour toutes les applications web. Elle dépend de la technologie utilisée. Par exemple si l’application est écrite en Java, alors vous allez générer un fichier WAR ou JAR alors que pour les applications web type JavaScript ou PHP, vous allez seulement compresser les fichiers dans une archive ZIP.
- Le déploiement vers un environnement de test qualité, également appelé environnement QA (Quality Assurance), va permettre d’exécuter les tests post déploiement et de tester si les scripts de déploiements fonctionnent.
- Le déroulement des tests post-déploiement est une phase également fortement conseillée qui contient tous les tests qui ne peuvent pas être exécutés sans déployer l'application ou un service, tous les tests qui prouvent que l’intégration a réussi. Ces tests peuvent être des tests fonctionnels, d’intégration et de performance.
Une fois que toutes ces étapes sont réalisées, le pipeline d’intégration continue est terminé.
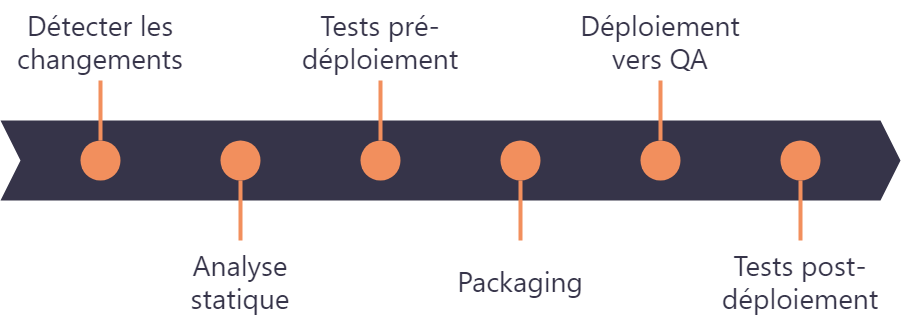
Cette liste est une liste exhaustive de tâches recommandées en intégration continue mais dépend fortement du contexte, de l’entreprise et des outils utilisés.
« La livraison continue est une approche d’ingénierie logicielle dans laquelle les équipes produisent des logiciels dans des cycles courts, ce qui permet de le mettre à disposition à n’importe quel moment. Le but est de construire, tester et diffuser un logiciel plus rapidement. » Source : Livraison continue, Wikipédia
« Le déploiement continu ou Continuous deployment (CD) en anglais est une approche d'ingénierie logicielle dans laquelle les fonctionnalités logicielles sont livrées fréquemment par le biais de déploiements automatisés. » Source : Déploiement continu, Wikipédia
La différence entre ces deux processus réside dans la présence d’une validation manuelle pour la mise en ligne de l’application. Avec la livraison continue, le code est livré et en attente d’une validation pour la mise en ligne. Avec le déploiement continu, le code est livré et déployé automatiquement.
Ces deux phases surviennent après le pipeline d’intégration continue et contiennent généralement les étapes suivantes :
- Le déploiement vers l’environnement de production va permettre de déployer le package créé pendant l’étape du packaging durant l’exécution du pipeline d’intégration continue sur le serveur de production. Le serveur de production est le serveur sur lequel le nom de domaine public va effectuer ses requêtes.
- Il est important d’effectuer une nouvelle fois les tests post-déploiement car même si l’environnement de test qualité est censé être « iso-prod » et que pour déployer l’application il faut que tous les tests passent, personne n’est à l’abri d’une erreur humaine ou d’un changement de configuration sur le serveur de production.

Le nombre d’étapes peut varier mais celles présentées ci-dessus représentent le minimum vital pour un pipeline de déploiement continu.
Les notions clés maintenant définies, nous allons maintenant voir comment répondre à la problématique.
Pour débuter, il faut comprendre le cycle de vie DevOps :
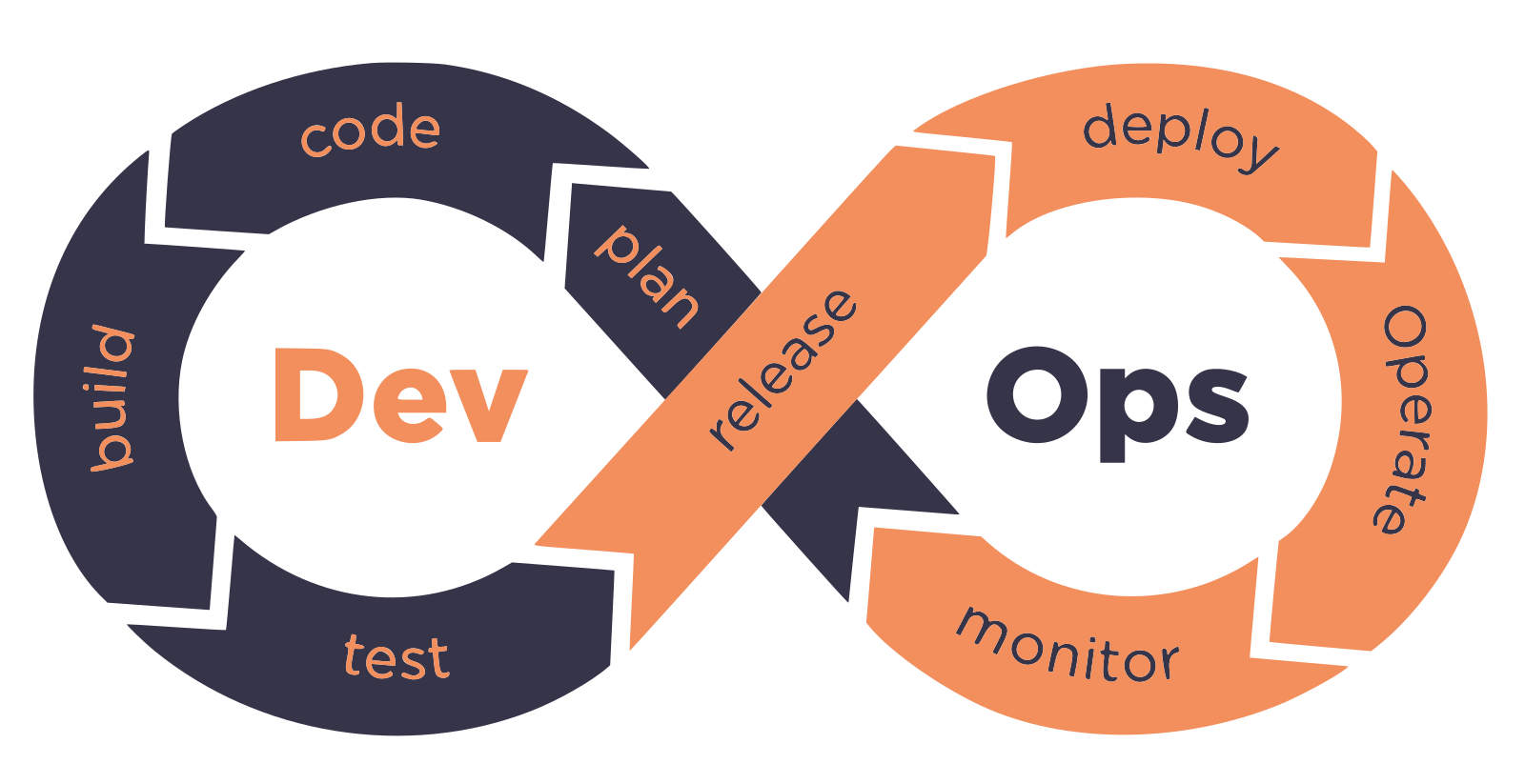
L’étape qui va permettre de déclencher l’intégration continue est l’étape de développement appelée « code ». C’est lors de cette phase que les développeurs vont programmer les fonctionnalités et envoyer le code sur un dépôt. Ce dépôt est le point de départ du pipeline.
Aujourd'hui seules les étapes « build, test, release & deploy » vont nous intéresser. Le pipeline d'intégration continue aura pour responsabilité les étapes « build, test & release » et le pipeline d'intégration continue l'étape « deploy ».
Maintenant que nous avons toutes notions nécessaires à la bonne réalisation de ce tutoriel, passons à la pratique !
- Git
- Node.JS
- Angular CLI
- Un compte GitHub avec un dépôt dédié pour ce tutoriel
Dans ce tutoriel, je vous laisserai en autonomie et le soin de commit et push votre code aux étapes que vous souhaitez.
Dans un premier temps nous allons créer le projet Angular, qui correspond à l'étape « code » du cycle de vie DevOps et qui, lors de votre push sur votre dépôt GitHub sera le point de déclenchement de notre pipeline.
Création et configuration du projet Angular
Pour créer un nouveau projet Angular, voici la commande à exécuter :
ng new project-nameUne fois cette commande exécutée, vous allez retrouver votre code source dans un dossier project-name.
Par défaut, Angular génère un projet avec au moins un test unitaire et un test de bout en bout. Ce qui va nous faciliter la tâche car nous allons pouvoir les utiliser dans notre pipeline d'intégration continue.
Angular utilise le framework de test Jasmine. Le test unitaire sont exécutés avec Karma et les tests de bout en bout avec Protractor.
Avant de créer le pipeline d'intégration continue, il va falloir préparer le code à être exécuter sur celui-ci :
- Ajouter puppeteer à notre projet permettant de contrôler une instance du navigateur Chrome Headless (Chrome sans UI) et d'exécuter les tests sur cette instance.
- Configurer notre application pour utiliser puppeteer
- Préparer des commandes NPM (scripts) utilisant cette configuration
Ajout de puppeteer
Pour ajouter puppeteer à notre projet :
npm i -D puppeteerL'option -D permet d'indiquer à NPM d'ajouter cette dépendance au devDependencies.
Pour que puppeteer fonctionne correctement il manque cependant une chose : un script permettant de mettre à jour les drivers lors de l'installation de vos dépendances NPM.
Dans votre fichier packages.json, dans la balise scripts vous allez ajouter la ligne suivante :
"postinstall": "webdriver-manager update --standalone false --gecko false"Ce script permet de dire à NPM d’exécuter la commande webdriver-manager update --standalone false --gecko false juste après npm install. Source : documentation npm.
Pour être sûr que cette commande est bien appelée lors de l'installation, vous pouvez supprimer vos node_modules et relancer npm install.
Dans un premier temps nous allons configurer Karma pour qu'il utilise Chrome Headless. Dans le fichier karma.conf.js, juste après browsers: ['Chrome'], ajouter le code suivant :
customLaunchers: {
ChromeHeadlessCI: {
base: 'ChromeHeadless',
flags: [
'--no-sandbox',
'--disable-gpu',
'--disable-dev-shm-usage',
'--ignore-certificate-errors',
'--window-size=1920,1080'
]
}
},Cette configuration permet d'ajouter un launcher personnalisé nommé ChromeHeadlessCI ayant pour base ChromeHeadless et avec différentes options :
--no-sandbox: Désactive la sandbox pour tous les types de processus qui sont normalement en sandbox.--disable-gpu: Désactive l'accélération matérielle du GPU. Si le logiciel de rendu n'est pas en place, le processus GPU ne se lancera pas.--disable-dev-shm-usage: La partition /dev/shm est trop petite dans certains environnements de machines virtuelles, ce qui entraîne une défaillance ou un plantage de Chrome. Utilisez ce drapeau pour contourner ce problème (un répertoire temporaire sera toujours utilisé pour créer des fichiers anonymes de mémoire partagée).--ignore-certificate-errors: ignorer les erreurs liées aux certificats.--window-size=1920,1080: Définit la taille initiale de la fenêtre. Fourni sous forme de chaîne au format "800,600".
Source : Chromium documentation.
Karma étant configuré, il faut donc maintenant indiquer à Angular d'utiliser ce nouveau launcher. Pour cela nous allons ajouter le code suivant dans le fichier angular.json dans la balise projects > project-name > architect > test et juste après la balise options :
"configurations": {
"ci": {
"watch": false,
"progress": false,
"browsers": "ChromeHeadlessCI"
}
}watch: indique à Karma de relancer ou non la compilation lorsqu'un changement a été effectuer dans le code sourceprogress: indique à Karma d'afficher les logs dans la console pendant la compilationbrowsers: spécifie le nom du navigateur à utiliser parmi la liste définie dans la balisecustomLaunchersdans le fichierkarma.conf.js
Cette configuration est maintenant utilisable avec la commande de test Angular : ng test -c=ci.-c est un alias pour --configuration.
Nous pouvons donc ajouter une commande NPM dans la balise scripts du fichier package.json :
"test:ci": "ng test -c=ci",De cette manière, lors de l’exécution du pipeline, nous exécuterons les tests unitaires (tests de pré-déploiements) avec la configuration dédiée à l'intégration continue avec la commande npm run test:ci.
De la même manière, nous allons configurer Protractor pour qu'il soit utilisable dans notre pipeline.
Dans un premier temps nous allons configurer Protractor pour qu'il utilise le binaire Chrome fournit par puppeteer. Dans le dossier e2e de votre projet, nous allons modifier le fichier protractor.conf.js en ajoutant le code suivant juste après la définition de browserName dans la balise capabilities :
chromeOptions: {
args: ['--no-sandbox', '--disable-dev-shm-usage', '--ignore-certificate-errors'],
binary: require('puppeteer').executablePath()
}Cette configuration indique à Protractor de lancer Chrome avec certaines options. Je vous ai présenté ces options dans la partie précédente. Pour plus d'informations : Chromium documentation.
Protractor utilise maintenant le binaire de puppeteer, cependant il n'utilise pas la version sans interface de Chrome. Pour cela nous allons créer un nouveau fichier protractor-ci.conf.js dans le dossier e2ede votre projet avec le contenu suivant :
const config = require('./protractor.conf').config;
config.capabilities = {
browserName: 'chrome',
chromeOptions: {
args: [
'--headless',
'--no-sandbox',
'--disable-gpu',
'--disable-dev-shm-usage',
'--ignore-certificate-errors',
'--window-size=1920,1080'
],
binary: require('puppeteer').executablePath()
}
};
exports.config = config;Cette configuration indique à Protractor d'utiliser le binaire de puppeteer, et, comme pour Karma, nous avons ajouté quelques options pour le lancement de Chrome. Ici, à la différence de Karma où nous avions comme base ChromeHeadless, nous utilisons Chrome avec une interface. Pour la désactiver, nous ajoutons donc l'option --headless.
Protractor étant configuré, il faut donc maintenant indiquer à Angular d'utiliser cette nouvelle configuration. Pour cela nous allons ajouter le code suivant dans le fichier angular.json dans la balise projects > project-name > architect > e2e > configurations et juste après la balise production :
"configurations": {
"production": {
"devServerTarget": "project-name:serve:production"
},
"ci": {
"devServerTarget": "project-name:serve:production",
"protractorConfig": "e2e/protractor-ci.conf.js"
}
}Cette configuration est maintenant utilisable avec la commande de test d'Angular : ng e2e -c=ci.-c est un alias pour --configuration.
Nous pouvons donc ajouter une commande NPM dans la balise scripts du fichier package.json :
"e2e:ci": "ng e2e -c=ci",De cette manière, lors de l’exécution du pipeline, nous pourrons exécuter les tests avec la configuration dédiée à l'intégration continue avec npm run e2e:ci.
Les webdriver étant mis à jour lors de l'installation de nos dépendances NPM, je désactive leur mise à jour dans le configuration Angular. Pour cela, dans le fichier angular.json dans la balise projects > project-name > architect > e2e > options, il suffit d'ajouter :
"options": {
"protractorConfig": "e2e/protractor.conf.js",
"devServerTarget": "project-name:serve",
"webdriverUpdate": false
},Notre projet Angular étant configuré et nous allons pouvoir commencer à construire notre pipeline avec GitHub actions.
Pour ce tutoriel j'ai fait le choix de grouper les pipelines de CI & CD dans un seul et de faire deux « jobs » : un pour l'intégration continue et l'autre pour le déploiement continu.
Un pipeline est appelé Workflow avec GitHub actions, pour le créer, rien de plus simple : à la racine de votre dépôt GitHub, créer un dossier .github/workflow qui contiendra vos futurs pipelines.
Dans ce dernier, créer un fichier ci-cd.yml, avec le nom de votre choix, la seule contrainte est l'extension : .yml ou .yaml. Vous devriez obtenir la même architecture que ci-dessous :
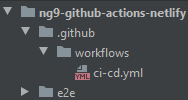
Dans un premier temps nous pouvons donner un nom à ce pipeline :
name: CI-CDLe pipeline peut être déclenché de différente manière, le paramètre on permet de définir une stratégie de déclenchement de ce pipeline :
on:
push:
branches:
- masterPour ce tutoriel, je n'ai que la branche master qui est utilisée, j'ai donc décidé de déclencher mon pipeline à chaque push sur cette branche. Cette stratégie dépendra de votre workflow Git (par exemple : GitFlow).
Pour en savoir plus sur le déclenchement de votre pipeline : workflow syntax documentation.
Dans ce fichier, nous allons définir des « jobs » qui vont correspondre à des étapes de notre pipeline. Chaque « job » s'exécutera sur une plateforme définie avec la balise runs-on et peut avoir une suite consécutive d'étapes décrites sous la balise steps.
La ou les plateforme(s) d'exécution (runs-on) peuvent être hébergées par GitHub ou par vous même (self-hosted). Pour en savoir plus, vous pouvez consulter cette documentation.
Pour ce tutoriel, j'ai choisi d'utiliser un Linux hébergé par GitHub : ubuntu-latest (Ubuntu 18.04).
Dans un premier temps nous allons créer un « job » nommé build avec les responsabilités suivantes :
- Récupérer le code source
- Installer l'environnement Node.JS sur la VM
- Installer les dépendances du projet
- Vérifier la syntaxe du code (lint)
- Exécuter les tests unitaires et de bout en bout
- Compiler l'application en mode
production - Créer un artefact réutilisable avec notre application compilée
Ce « job » remplira le rôle de pipeline d'intégration continue.
jobs:
build:
runs-on: ubuntu-latest
steps:Pour récupérer le code source nous allons utiliser une action fournie par GitHub : actions/checkout. Pour indiquer à notre pipeline de l'utiliser, rien de plus simple :
// [...]
steps:
- name: Checkout source code
uses: actions/checkout@v2Notre code source étant récupéré, il va falloir paramétrer Node.JS pour pouvoir exécuter les commandes que nous avons défini précédemment. L'action actions/setup-node répond à ce besoin :
// [...]
steps:
// [...]
- name: Use Node.js
uses: actions/setup-node@v1
with:
node-version: '12.x'Pour ce tutoriel j'ai choisi d'utiliser la version LTS (long-term support) de Node.JS, mais il est possible de configurer une matrice de versions pour que votre « job » s’exécute pour plusieurs versions à la fois. Pour en savoir plus, voici quelques exemples d'utilisation.
Pour cette étape, nous n'allons pas utiliser une action mais la commande suivante : npm install :
// [...]
steps:
// [...]
- name: Install dependencies
run: npm installPour cette étape, nous n'allons pas utiliser une action mais une commande fournie par Angular : ng lint. Une commande NPM est définie dans le fichier packages.json : lint. C'est ce que nous allons utiliser dans notre pipeline :
// [...]
steps:
// [...]
- name: Lint
run: npm run lintPour ces étapes, nous n'allons pas utiliser une action mais les scripts NPM que nous avons écrits lors de l'étape de Configuration de l'application (test:ci & e2e:ci) :
// [...]
steps:
// [...]
- name: Unit tests
run: npm run test:ci
- name: E2E
run: npm run e2e:ciPour compiler l'application en mode production, il suffit d’exécuter la commande ng build --prod. Cependant, comme pour les commandes de tests, je préfère définir un script NPM dans le fichier packages.json :
"build:prod": "ng build --prod",Cette commande est la commande par défaut pour appeler la configuration production définie dans le fichier angular.json. Dans votre cas, votre configuration de production pourrait avoir un autre nom et il faudrait alors utiliser l'option -c ou --configuration.
Notre script NPM étant prêt à l'emploi, il suffit donc de l'ajouter à notre pipeline :
// [...]
steps:
// [...]
- name: Build app
run: npm run build:prodPour créer notre artefact, nous allons utiliser une action fournie par GitHub : actions/upload-artifact. Pour indiquer à notre pipeline de l'utiliser, rien de plus simple :
// [...]
steps:
// [...]
- name: Upload artifact
uses: actions/upload-artifact@v2
with:
name: ng9-github-actions-netlify-${{ github.ref }}-${{ github.run_id }}-${{ github.run_number }}
path: ./dist/ng9-github-actions-netlifyLe name permet de définir le nom de l’artefact et le path indique le chemin vers le contenu l'on souhaite ajouter à l'artefact, ici le dossier de compilation de notre application.
Pour le nom de notre artefact, je voulais qu'il ait le format : <project-name>-<branch>-<run_id>-<run_number> pour qu'il soit unique et identifiable lorsque l'on veut déployer un artefact spécifique.
Cependant la variable github.ref ne contient pas juste le nom de la branche, ici master, mais refs/heads/master. Le slash / étant un caractère interdit dans le nom de l'artefact et n'étant pas très lisible, j'ai alors trouvé une action permettant de ne récupérer que le nom de la branche : rlespinasse/github-slug-action.
J'ai donc dû ajouter une étape avant la création de mon artefact et modifier le format de nom de mon artifact :
// [...]
steps:
// [...]
- name: Inject slug/short variables
uses: rlespinasse/github-slug-action@v2.x
- name: Upload artifact
uses: actions/upload-artifact@v2
with:
name: ng9-github-actions-netlify-${{ env.GITHUB_REF_SLUG }}-${{ github.run_id }}-${{ github.run_number }}
path: ./dist/ng9-github-actions-netlifyUne fois l'artefact créé et sauvegardé, l'étape de build de notre pipeline est terminée, nous allons pouvoir passer au déploiement.
Pour cela, nous allons créer un « job » nommé deploy avec les responsabilités suivantes :
- Récupérer l'artefact précédemment créé
- Déployer l'artefact avec Netlify
Ce « job » rempli le rôle du pipeline de déploiement continu.
// [...]
test:
runs-on: ubuntu-latest
steps:Pour récupérer et télécharger notre artefact, nous allons utiliser une action fournie par GitHub : actions/download-artifact. Pour indiquer à notre pipeline de l'utiliser, rien de plus simple :
// [...]
steps:
- name: Inject slug/short variables
uses: rlespinasse/github-slug-action@v2.x
- name: Download artifact
uses: actions/download-artifact@v2
with:
name: ng9-github-actions-netlify-${{ env.GITHUB_REF_SLUG }}-${{ github.run_id }}-${{ github.run_number }}
path: './build'L'option name correspond au nom de l'artefact donné lors de la création. J'ai donc également ajouté l'action permettant de récupérer le nom de la branche, et le path indique le chemin où décompresser cet artefact.
Dans un premier temps, il va vous falloir créer votre compte : https://app.netlify.com/signup
Une fois votre compte créé, il va falloir lié votre compte Netlify avec votre compte GitHub :
- Cliquez en haut à droite sur l'icône de votre profil, puis allez dans
User settings
- Scrollez jusqu'à la section
Connected Accounts - Si ce n'est pas déjà fait, liez votre compte GitHub en cliquant sur
Edit settingspuisConnect - Une fois GitHub lié, cliquez sur le bouton
Done
Votre compte GitHub maintenant lié, nous allons maintenant ajouter un site à partir d'un dépôt Git :
- Retournez sur le listes de vos sites
- Cliquez sur le bouton
New site from Git - Dans la section
Continuous Deployment, cliquez sur GitHub - Une pop-up va apparaître et vous demander d'autoriser Netlify à se connecter à GitHub
- Vous allez avoir le choix entre autoriser l'accès a tous vos dépôts ou seulement ceux que vous désirez. Si vous choisissez la deuxième, il faudra alors spécifier le dépôt que vous souhaitez lier.
- Netlify à maintenant accès à votre dépôt et va vous proposer d'écouter une branche de votre dépôt, d'exécuter une commande de compilation et de publier votre site à partir du chemin que vous lui aurez fourni. Cependant ce n'est pas la méthode que nous allons employer aujourd'hui : nous allons déployer votre site depuis le pipeline.
- Cliquez sur
Deploy sitesans saisir de valeur dans les différents champs du formulaire.
Pour désactiver le déploiement continue depuis Netlify, voici la marche à suivre :
- Depuis la vue d'ensemble de votre site (
overview), cliquez surSite settings - Cliquez sur le bouton
Build & deploydans le menu de gauche - Dans la section
Build settings, cliquez sur le boutonEdit settings - Au niveau du paramètre
Builds, sélectionner l'optionStop builds - Cliquez sur
Save
Nous allons maintenant ajouter une étape à notre pipeline pour déployer l'artefact que nous avons compilé à l'étape de build de notre pipeline.
L'action nwtgck/actions-netlify répond à notre besoin en nous permettant de déployer le contenu d'un dossier. Pour pouvoir l'utiliser, il faut obligatoirement indiquer :
publish-dirle répertoire contenant les fichiers à publier (par exemple : "dist", "_site")NETLIFY_AUTH_TOKEN: le token permettant de nous authentifier. Pour le créer :- Cliquez sur le lien suivant Personal access tokens
- Cliquez sur le bouton
New access token
NETLIFY_SITE_ID: correspond à l'id unique de votre site ou app sur Netlify. Pour le récupérer :team page>your site>Settings>Site details>Site information>API ID
PI: API ID = NETLIFY_SITE_ID.
Source : nwtgck/actions-netlify documentation.
NETLIFY_AUTH_TOKEN et NETLIFY_SITE_ID sont des variables que vous ne pouvez pas rendre publique pour des raisons de sécurité, nous allons donc utiliser les secrets de GitHub afin de garder ces valeurs cachées.
Pour ajouter un secret et le rendre disponible sur votre pipeline :
- Sur votre dépôt GitHub, allez dans
SettingspuisSecrets - Cliquez sur
New secret - Saisissez le nom que vous souhaitez lui donner (dans notre cas
NETLIFY_AUTH_TOKEN) et saisissez la valeur associée - Répétez l'action pour
NETLIFY_SITE_ID
Vos secrets ont bien été ajoutés et sont utilisables dans votre pipeline.
Nous avons maintenant tous les prérequis pour ajouter l'action à notre pipeline :
// [...]
steps:
// [...]
- name: Deploy to Netlify
uses: nwtgck/actions-netlify@v1.1
with:
publish-dir: './build'
production-branch: master
github-token: ${{ secrets.GITHUB_TOKEN }}
deploy-message: "Deploy from GitHub Actions"
enable-pull-request-comment: true
enable-commit-comment: true
overwrites-pull-request-comment: true
env:
NETLIFY_AUTH_TOKEN: ${{ secrets.NETLIFY_AUTH_TOKEN }}
NETLIFY_SITE_ID: ${{ secrets.NETLIFY_SITE_ID }}publish-dircorrespond au chemin où nous avons décompressé notre artefact.production-branchcorrespond à la branche de production (la branche stable vous permettant de livrer votre application)deploy-messagecorrespond au message de déploiement personnalisé visible sur Netlifyenable-pull-request-commentpermet d'activer ou non l'ajout de commentaire sur une pull request (activé par défaut)enable-commit-commentpermet d'activer ou non l'ajout de commentaire sur un commit (activé par défaut)overwrites-pull-request-commentpermet d'autoriser ou non la réécriture de commentaire sur une pull request (activé par défaut)
Les variables d'environnement (env) sont les variables permettant de nous authentifier auprès de Netlify (NETLIFY_AUTH_TOKEN) et d'identifier quel est le site à déployer (NETLIFY_SITE_ID).
Le « job » deploy de notre pipeline est maintenant terminé. Votre pipeline est complet. Il vous suffit maintenant de pousser vos modifications sur votre dépôt et vérifier que tout fonctionne correctement.
Si vous souhaitez vérifier votre code et le comparer à celui du tutoriel : smarlhens/ng9-github-actions-netlify.
Pour suivre votre déploiement, sur votre dépôt GitHub, cliquez sur Actions et cliquez sur le nom du workflow que vous avez défini précédemment. Vous êtes maintenant sur la liste des exécutions de votre pipeline :
 Cliquez sur votre dernier commit, vous devriez voir le détail de l'exécution de votre pipeline avec sur la gauche le statut des « jobs » de votre pipeline :
Cliquez sur votre dernier commit, vous devriez voir le détail de l'exécution de votre pipeline avec sur la gauche le statut des « jobs » de votre pipeline :
 Si vous cliquez dessus, vous allez pouvoir suivre le déroulement de chaque étape de votre « job » :
Si vous cliquez dessus, vous allez pouvoir suivre le déroulement de chaque étape de votre « job » :
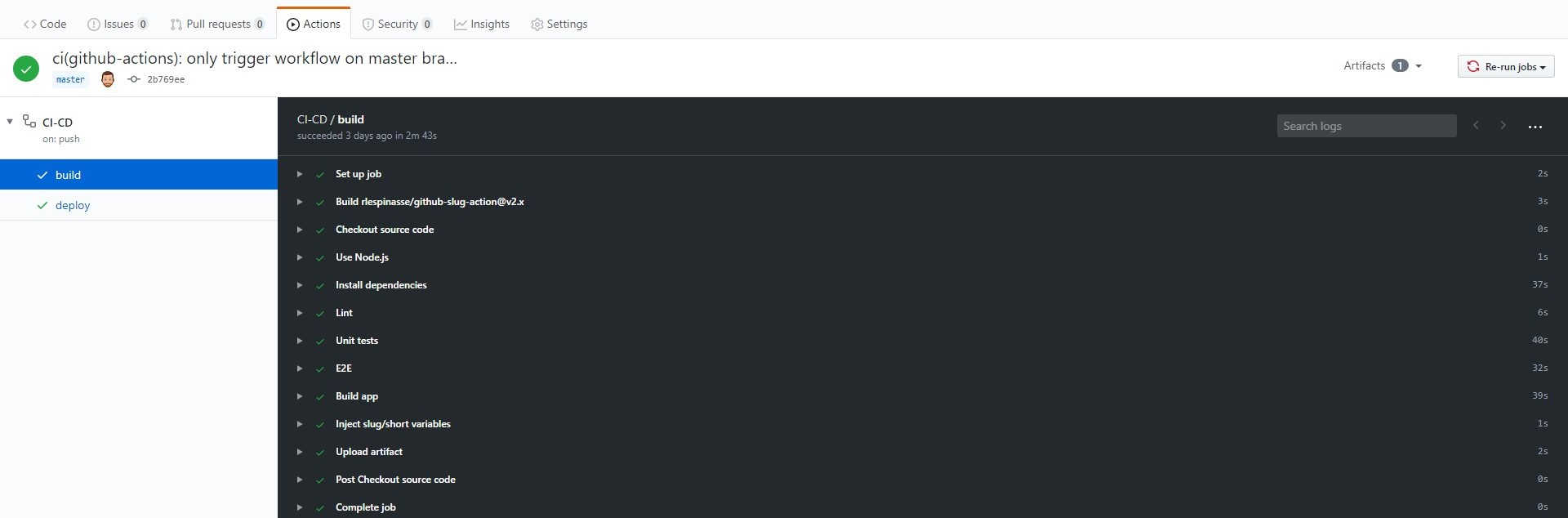
Une fois votre pipeline exécuté avec succès, vous pouvez retrouver l'artefact créé en retournant sur la page de détails de l’exécution :
 Si vous revenez sur votre commit et si vous aviez activé
Si vous revenez sur votre commit et si vous aviez activé enable-commit-comment alors vous devriez voir apparaitre un commentaire publié par le bot de GitHub Actions :
 Sur Netlify, sur la page
Sur Netlify, sur la page Overview de votre site, la date de publication mise à jour :
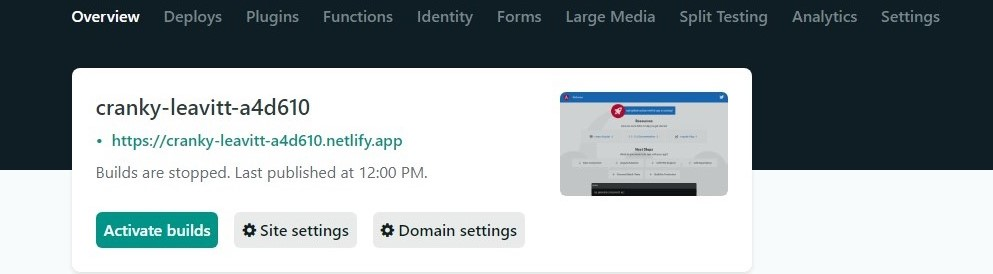
Félicitations ! Votre site a bien été déployé.
Bravo ! Vous savez maintenant comment mettre en place facilement un pipeline d'intégration continue et de déploiement continu avec GitHub Actions & Netlify pour vos applications Angular.
Vous avez également pu remarquer que le déploiement avec Netlify se fait à partir d'un dossier, vous pourriez donc réutiliser ce pipeline en l'adaptant pour vos autres applications JavaScript : React, Svelte, etc.
Nous n'avons pas exploré toutes les possibilités de GitHub Actions (stratégie de déclenchement des workflows, choix de la plateforme d'exécution, etc.) et il existe une multitude d'Actions réalisées par la communauté permettant de répondre à vos besoins. N'hésitez pas à explorer le marketplace pour trouver votre bonheur et à vous exercer en prenant le réflexe de créer des pipelines pour vos futurs projets !
- https://help.github.com/en/actions
- https://docs.netlify.com/
- https://angular.io/docs
- https://fr.wikipedia.org/
- Les autres sources sont référencées directement dans l'article