Last active
April 20, 2022 08:20
-
-
Save staticfloat/7f30b09f070444ae02ae16aab2c0047e to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| using Flux, Printf, Statistics | |
| # Simple model | |
| function gen_model() | |
| return Chain( | |
| Dense(8, 8, σ), | |
| Dense(8, 8, σ), | |
| Dense(8, 8, σ), | |
| Dense(8, 1, σ), | |
| ) | |
| end | |
| # Static dataset | |
| function gen_dataset(batch_size = 128, num_minibatches = 256) | |
| # Return an array of (x, y) tuples | |
| return [( | |
| randn(8, batch_size), | |
| randn(1, batch_size), | |
| ) for _ in 1:num_minibatches] | |
| end | |
| # Helper function to print some `@timed` stats | |
| function info_stats(msg, stats, num_epochs) | |
| @info( | |
| msg, | |
| time=stats.time, | |
| time_per_epoch=stats.time/num_epochs, | |
| gc=@sprintf("%.1f%%", stats.gctime*100.0/stats.time), | |
| allocated=Base.format_bytes(stats.bytes), | |
| ) | |
| end | |
| # Warm up codegen | |
| @info("Warming up Flux.train!()") | |
| begin | |
| model = gen_model() | |
| dataset = gen_dataset() | |
| opt = Flux.Optimise.ADAM(1e-4) | |
| num_epochs = 20 | |
| stats = @timed begin | |
| for idx in 1:num_epochs | |
| Flux.train!( | |
| (x, y) -> Flux.Losses.mse(model(x), y), | |
| Flux.params(model), | |
| dataset, | |
| opt, | |
| ) | |
| end | |
| end | |
| info_stats("First warm-up completed", stats, num_epochs) | |
| stats = @timed begin | |
| for idx in 1:4 | |
| Flux.train!( | |
| (x, y) -> Flux.Losses.mse(model(x), y), | |
| Flux.params(model), | |
| dataset, | |
| opt, | |
| ) | |
| end | |
| end | |
| info_stats("Second warm-up completed", stats, num_epochs) | |
| end | |
| # Train `num_models` in parallel, each on its own thread | |
| num_models = 32 | |
| datasets = [gen_dataset() for _ in 1:num_models] | |
| models = [gen_model() for _ in 1:num_models] | |
| training_stats = [Any[] for _ in 1:num_models] | |
| @warn("Beginning training with $(Threads.nthreads()) threads") | |
| Threads.@threads for model_idx in 1:num_models | |
| model = models[model_idx] | |
| dataset = datasets[model_idx] | |
| opt = Flux.Optimise.ADAM(1e-4) | |
| # Threads will die off one by one, so we can see how reducing the number of threads | |
| # eases off GC pressure over the whole cohort | |
| for idx in 1:(model_idx*num_epochs) | |
| push!(training_stats[model_idx], @timed begin | |
| Flux.train!( | |
| (x, y) -> Flux.Losses.mse(model(x), y), | |
| Flux.params(model), | |
| dataset, | |
| opt, | |
| ) | |
| end) | |
| end | |
| # Calculate mean statistics over the tail end of this thread's lifetime | |
| tail_stats = training_stats[model_idx][end-num_epochs+1:end] | |
| mean_stats = (; | |
| time = mean(s.time for s in tail_stats), | |
| gctime = mean(s.gctime for s in tail_stats), | |
| bytes = mean(s.bytes for s in tail_stats), | |
| ) | |
| info_stats("Finished model $(model_idx)", mean_stats, model_idx*num_epochs) | |
| end | |
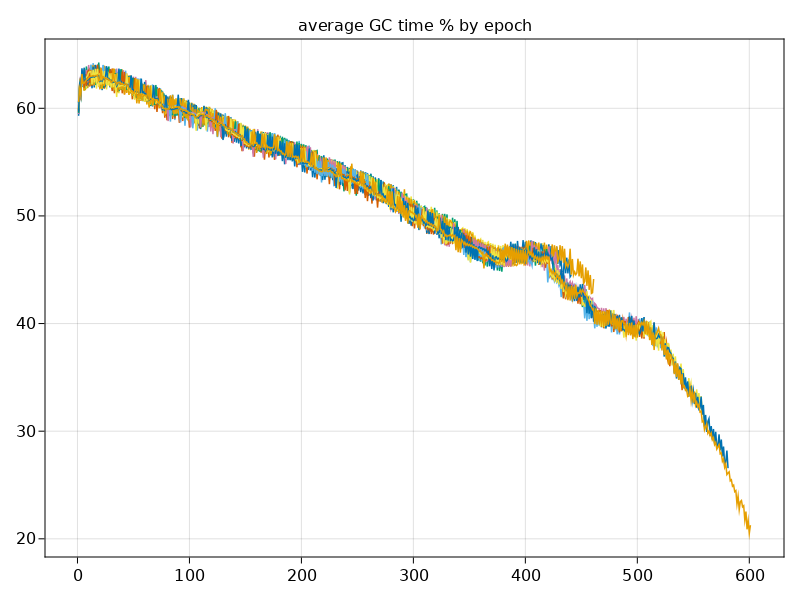
| # Create nice graph at the end of moving-average GC time % | |
| @info("Finished training") | |
| using CairoMakie | |
| fig = Figure() | |
| ax = Axis(fig[1,1]) | |
| for model_idx in 10:num_models | |
| filt_len = 2*num_epochs | |
| gctimes = [s.gctime for s in training_stats[model_idx]] | |
| gctimes_filt = conv(gctimes[:,:,:], ones(filt_len,1,1)./filt_len)[:] | |
| times = [s.time for s in training_stats[model_idx]] | |
| times_filt = conv(times[:,:,:], ones(filt_len,1,1)./filt_len)[:] | |
| lines!(ax, gctimes_filt.*100.0./times_filt) | |
| #lines!(ax, times_filt .- gctimes_filt) | |
| end | |
| ax.title = "average GC time % by epoch" | |
| save("training_stats.png", fig) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| $ julia --project --threads=auto -i flux_multithreaded_training.jl | |
| [ Info: Warming up Flux.train!() | |
| ┌ Info: First warm-up completed | |
| │ time = 24.151648601 | |
| │ time_per_epoch = 1.20758243005 | |
| │ gc = "6.6%" | |
| └ allocated = "4.288 GiB" | |
| ┌ Info: Second warm-up completed | |
| │ time = 0.292563925 | |
| │ time_per_epoch = 0.01462819625 | |
| │ gc = "12.1%" | |
| └ allocated = "188.549 MiB" | |
| ┌ Warning: Beginning training with 64 threads | |
| └ @ Main ~/src/surrogate_testing/flux_multithreaded_training.jl:67 | |
| ┌ Info: Finished model 1 | |
| │ time = 0.96046645575 | |
| │ time_per_epoch = 0.0480233227875 | |
| │ gc = "62.2%" | |
| └ allocated = "1.397 GiB" | |
| ┌ Info: Finished model 2 | |
| │ time = 0.6822931502 | |
| │ time_per_epoch = 0.017057328755 | |
| │ gc = "72.6%" | |
| └ allocated = "1.361 GiB" | |
| ┌ Info: Finished model 3 | |
| │ time = 0.63013394675 | |
| │ time_per_epoch = 0.010502232445833334 | |
| │ gc = "71.2%" | |
| └ allocated = "1.303 GiB" | |
| ┌ Info: Finished model 4 | |
| │ time = 0.6284951171 | |
| │ time_per_epoch = 0.00785618896375 | |
| │ gc = "69.2%" | |
| └ allocated = "1.258 GiB" | |
| ┌ Info: Finished model 5 | |
| │ time = 0.5810092911 | |
| │ time_per_epoch = 0.005810092911 | |
| │ gc = "71.5%" | |
| └ allocated = "1.288 GiB" | |
| ┌ Info: Finished model 6 | |
| │ time = 0.5578616940000001 | |
| │ time_per_epoch = 0.004648847450000001 | |
| │ gc = "68.6%" | |
| └ allocated = "1.197 GiB" | |
| ┌ Info: Finished model 7 | |
| │ time = 0.5249345326 | |
| │ time_per_epoch = 0.003749532375714286 | |
| │ gc = "67.2%" | |
| └ allocated = "1.146 GiB" | |
| ┌ Info: Finished model 8 | |
| │ time = 0.4802209392000001 | |
| │ time_per_epoch = 0.0030013808700000005 | |
| │ gc = "70.2%" | |
| └ allocated = "1.100 GiB" | |
| ┌ Info: Finished model 9 | |
| │ time = 0.4712065032 | |
| │ time_per_epoch = 0.0026178139066666667 | |
| │ gc = "66.0%" | |
| └ allocated = "1.059 GiB" | |
| ┌ Info: Finished model 10 | |
| │ time = 0.46222509810000006 | |
| │ time_per_epoch = 0.0023111254905000002 | |
| │ gc = "67.5%" | |
| └ allocated = "1.037 GiB" | |
| ┌ Info: Finished model 11 | |
| │ time = 0.41497993315 | |
| │ time_per_epoch = 0.0018862724234090908 | |
| │ gc = "65.9%" | |
| └ allocated = "996.651 MiB" | |
| ┌ Info: Finished model 12 | |
| │ time = 0.39126343464999996 | |
| │ time_per_epoch = 0.0016302643110416666 | |
| │ gc = "64.4%" | |
| └ allocated = "950.995 MiB" | |
| ┌ Info: Finished model 13 | |
| │ time = 0.382742247 | |
| │ time_per_epoch = 0.0014720855653846154 | |
| │ gc = "64.0%" | |
| └ allocated = "916.340 MiB" | |
| ┌ Info: Finished model 14 | |
| │ time = 0.34288418504999996 | |
| │ time_per_epoch = 0.0012245863751785713 | |
| │ gc = "64.1%" | |
| └ allocated = "852.925 MiB" | |
| ┌ Info: Finished model 15 | |
| │ time = 0.29296357749999996 | |
| │ time_per_epoch = 0.0009765452583333332 | |
| │ gc = "62.7%" | |
| └ allocated = "791.917 MiB" | |
| ┌ Info: Finished model 16 | |
| │ time = 0.27802489244999995 | |
| │ time_per_epoch = 0.0008688277889062499 | |
| │ gc = "63.1%" | |
| └ allocated = "747.786 MiB" | |
| ┌ Info: Finished model 17 | |
| │ time = 0.27814960005 | |
| │ time_per_epoch = 0.0008180870589705883 | |
| │ gc = "62.4%" | |
| └ allocated = "774.939 MiB" | |
| ┌ Info: Finished model 18 | |
| │ time = 0.22394830665 | |
| │ time_per_epoch = 0.0006220786295833334 | |
| │ gc = "60.7%" | |
| └ allocated = "663.826 MiB" | |
| ┌ Info: Finished model 19 | |
| │ time = 0.23692811540000003 | |
| │ time_per_epoch = 0.0006234950405263159 | |
| │ gc = "60.3%" | |
| └ allocated = "657.192 MiB" | |
| ┌ Info: Finished model 20 | |
| │ time = 0.1871665368 | |
| │ time_per_epoch = 0.000467916342 | |
| │ gc = "58.2%" | |
| └ allocated = "583.980 MiB" | |
| ┌ Info: Finished model 21 | |
| │ time = 0.16696599799999998 | |
| │ time_per_epoch = 0.0003975380904761904 | |
| │ gc = "60.0%" | |
| └ allocated = "573.366 MiB" | |
| ┌ Info: Finished model 22 | |
| │ time = 0.1810929687 | |
| │ time_per_epoch = 0.00041157492886363634 | |
| │ gc = "57.9%" | |
| └ allocated = "555.059 MiB" | |
| ┌ Info: Finished model 24 | |
| │ time = 0.134708169 | |
| │ time_per_epoch = 0.00028064201875 | |
| │ gc = "55.2%" | |
| └ allocated = "438.462 MiB" | |
| ┌ Info: Finished model 23 | |
| │ time = 0.14440032309999998 | |
| │ time_per_epoch = 0.0003139137458695652 | |
| │ gc = "53.9%" | |
| └ allocated = "469.888 MiB" | |
| ┌ Info: Finished model 25 | |
| │ time = 0.11250617895 | |
| │ time_per_epoch = 0.0002250123579 | |
| │ gc = "53.4%" | |
| └ allocated = "350.242 MiB" | |
| ┌ Info: Finished model 26 | |
| │ time = 0.09209255605 | |
| │ time_per_epoch = 0.00017710106932692307 | |
| │ gc = "46.9%" | |
| └ allocated = "283.863 MiB" | |
| ┌ Info: Finished model 28 | |
| │ time = 0.08827645390000001 | |
| │ time_per_epoch = 0.0001576365248214286 | |
| │ gc = "43.5%" | |
| └ allocated = "250.151 MiB" | |
| ┌ Info: Finished model 29 | |
| │ time = 0.07947673274999997 | |
| │ time_per_epoch = 0.00013702884956896547 | |
| │ gc = "38.1%" | |
| └ allocated = "220.892 MiB" | |
| ┌ Info: Finished model 27 | |
| │ time = 0.09358652614999999 | |
| │ time_per_epoch = 0.00017330838175925924 | |
| │ gc = "38.2%" | |
| └ allocated = "248.892 MiB" | |
| ┌ Info: Finished model 31 | |
| │ time = 0.06465937009999999 | |
| │ time_per_epoch = 0.0001042893066129032 | |
| │ gc = "28.0%" | |
| └ allocated = "126.471 MiB" | |
| ┌ Info: Finished model 30 | |
| │ time = 0.07568235385 | |
| │ time_per_epoch = 0.00012613725641666667 | |
| │ gc = "21.4%" | |
| └ allocated = "106.260 MiB" | |
| ┌ Info: Finished model 32 | |
| │ time = 0.041342464450000005 | |
| │ time_per_epoch = 6.459760070312501e-5 | |
| │ gc = "17.9%" | |
| └ allocated = "45.388 MiB" | |
| [ Info: Finished training |
Running on master, it looks mostly the same, maybe a little more consistent:
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Generated graph looks like: