Last active
August 21, 2021 23:41
-
-
Save thistleknot/85a95f8db6b47b947cd06f5e7bbdf8ec to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #https://towardsdatascience.com/pipelines-custom-transformers-in-scikit-learn-the-step-by-step-guide-with-python-code-4a7d9b068156 | |
| #https://github.com/HCGrit/MachineLearning-iamJustAStudent/blob/master/PipelineFoundation/Pipeline_Experiment.ipynb | |
| import pandas as pd | |
| from sklearn.compose import TransformedTargetRegressor | |
| from sklearn.pipeline import FeatureUnion, Pipeline, make_pipeline | |
| from sklearn.base import BaseEstimator, TransformerMixin | |
| from sklearn.model_selection import GridSearchCV, KFold, cross_val_score, RepeatedKFold, train_test_split | |
| from sklearn.preprocessing import StandardScaler, PowerTransformer | |
| class ss_yj_Transformer(BaseEstimator, TransformerMixin): | |
| # add another additional parameter, just for fun, while we are at it | |
| def __init__(self, feature_names=[], additional_param = ""): | |
| self.ss_X = StandardScaler() | |
| self.pt_X = PowerTransformer(standardize=True) | |
| self.ss_y = StandardScaler() | |
| self.pt_y = PowerTransformer(standardize=True) | |
| self.feature_names = feature_names | |
| self.additional_param = additional_param | |
| def fit(self, X, y = None): | |
| self.ss_X.fit(X) | |
| self.pt_X.fit(self.ss_X.transform(X)) | |
| if (y is not None): | |
| self.ss_y.fit(y) | |
| self.pt_y.fit(self.ss_y.transform(y)) | |
| return self | |
| def transform(self, X, y = None): | |
| pt_X_ = pd.DataFrame(self.pt_X.fit(pd.DataFrame(self.ss_X.fit(X).transform(X),index=X.index,columns=X.columns)).transform(pd.DataFrame(self.ss_X.fit(X).transform(X),index=X.index,columns=X.columns)),index=X.index,columns=X.columns) | |
| if (y is None): | |
| return pt_X_ | |
| else: | |
| pt_y_ = pd.DataFrame(self.pt_y.fit(pd.DataFrame(self.ss_y.fit(y).transform(y),index=y.index,columns=y.columns)).transform(pd.DataFrame(self.ss_y.fit(y).transform(y),index=y.index,columns=y.columns)),index=y.index,columns=y.columns) | |
| return pt_X_, pt_y_ | |
| def inverse_transform(self, X, y = None): | |
| target_X = pd.DataFrame(self.ss_X.inverse_transform(self.pt_X.inverse_transform(X)),index=X.index,columns=X.columns) | |
| if (y is None): | |
| return target_X | |
| else: | |
| target_y = pd.DataFrame(self.ss_y.inverse_transform(self.pt_y.inverse_transform(y)),index=y.index,columns=y.columns) | |
| return target_X, target_y | |
| target = 'Poverty' | |
| exclude = 'States' | |
| all_data = pd.read_csv('https://raw.githubusercontent.com/thistleknot/python-ml/master/data/raw/states.csv') | |
| train, valid = train_test_split(all_data.index, test_size=0.3, shuffle=True) | |
| valid, test = train_test_split(valid, test_size=0.5, shuffle=True) | |
| X = all_data[set(all_data.columns).difference([target,exclude])].copy() | |
| y = pd.DataFrame(all_data[target].copy()) | |
| X_train = X.loc[train].copy() | |
| X_valid = X.loc[valid].copy() | |
| X_test = X.loc[test].copy() | |
| y_train = y.loc[X_train.index][[target]].copy() | |
| y_valid = y.loc[X_valid.index][[target]].copy() | |
| y_test = y.loc[X_test.index][[target]].copy() | |
| X_train_ss_yj_t = ss_yj_Transformer() | |
| X_train_ss_yj_t.fit(X_train) | |
| X_train_ss_yj = X_train_ss_yj_t.transform(X_train) | |
| y_train_ss_yj_t = ss_yj_Transformer() | |
| y_train_ss_yj_t.fit(y_train) | |
| y_train_ss_yj = y_train_ss_yj_t.transform(y_train) | |
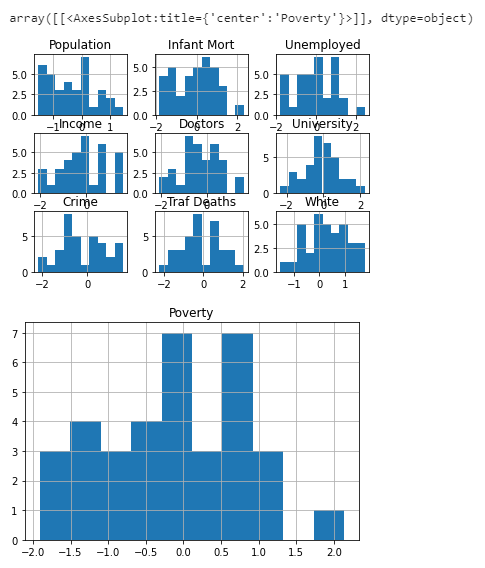
| X_train_ss_yj.hist() | |
| y_train_ss_yj.hist() | |
| y_train_ss_yj_t.inverse_transform(y_train_ss_yj)-y_train |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I've found setting standardize to False results in better results (using sequentialfeatureselector)