| 階段 | 審稿人代號 | 投票 | 評論 |
|---|---|---|---|
| 1 | #23A9 | +1(高度肯定地接受) | 命題合理,研究結構完整,有完整的方法描述。我會建議「目前的解法」部分可以處理得更簡單,因為對於會眾而言,並不需要特別示範這些東西怎麼用,只要讓大家知道它們的存在即可。我覺得大概一分鐘帶過就夠了。把多一點時間花在論文介紹應該比較合適。是說論文介紹比 word2vec 還短好像不太對? |
| 1 | #5680 | +1(高度肯定地接受) | an interesting and comprehensive proposal |
| 1 | #AA7F | +1(高度肯定地接受) | 很有趣與實用的議題,能帶領大家入門自然語言處理 |
| 1 | #0A3C | +1(高度肯定地接受) | 看起來很有趣而且介紹也寫得很完整 |
| 1 | #BE2E | +1(高度肯定地接受) | 很有條理與組織性,相信能為對 text-mining 有興趣的聽眾帶來很多收穫。由 CNN 帶來的啟發: 知識可能是以階層樹狀來組織的,而 知識圖譜 似乎並不屬於此種結構,是否真能代表或者 encode 知識,關係到此研究路線的前景,學界是否有相關的討論與看法,希望也能略為介紹。 |
| 1 | #5DF5 | +1(高度肯定地接受) | very in-depth text-mining talk |
| 1 | #31D8 | +1(高度肯定地接受) | 我相信講者有能力把這場演講講好 |
| 1 | #4521 | +1(高度肯定地接受) | 題目設定有趣,內容充分且包含示範程式碼。 |
| 1 | #D25D | +1(高度肯定地接受) | (Comment redacted by the reviewer or organizers.)1 #C7F2 |
| 1 | #1D23 | +0(輕微贊成) | 非常棒的大綱跟介紹 這麼豐富的內容或許 30 分鐘會太趕。建議可以延長演講時間 |
| 1 | #9969 | +0(輕微贊成) | 從動機出發的概念很好,動機才是激起聽眾學習最重要的部分!建議最後可以比較一下您的論文與目前解法的差異。 |
| 1 | #38FE | −0(輕微反對) | 沒有太多異議,如果單純動機有一部分是希望吸引與讓會眾理解 text mining 覺得是不錯。但目前投反對原因如下建議:因為是以中階分類,要考量到來聽得會眾某些事已經具備基礎,所以建議第四部分之後要確保在有限五分鐘能說明清楚,或是能調整其他部分讓第四部分的完整度高一些 例如:背後原理與目前解法是否可以做一些濃縮與合併。 |
題目:維基教我做的金頭腦:知識圖譜製作初體驗
分類:資料分析
時間長度:30
【百萬小學堂】、【金頭腦】這類的益智節目,在台灣也風靡一時。
而電腦是否能在節目上超越人腦,也一直是人們茶餘飯後討論的話題。
在 2011 年的益智問答節目 Jeopardy中,IBM 的華生電腦(Watson)擊敗兩位世界紀錄保持人並贏得 100 萬美元,造成不小轟動。本次talk,將介紹如何自製一個答題機器人。
目前,電腦對於自然語言的理解依然有限,舉例來說:要讓電腦知道『蘋果』是什麼?就是個困難的問題。
因為蘋果在一句話中可能是指水果、手機或是喜歡的人(流行音樂中的小蘋果)。為了克服這個難題,文字探勘(text mining)中有個子領域叫做知識圖譜(Ontoloty),目的就是希望將人類所有的知識以及規則儲存成結構化的資料。
如此,在解析文字時,就會知道蘋果是水果or電腦、知道周杰倫是歌手。對益智節目、聊天機器人等應用都會產生莫大的助益。
本talk將會介紹知識圖譜的應用、目前的做法與瓶頸、如何使用Wikipedia自動建立支援各國語言的知識圖譜,最後Demo一下答題機器人的智商到底行不行。
我將我的talk分成四個部分:
- 開場
- Introduction:Text mining的應用有哪些 + 面臨哪些共同的痛點呢(e.g. 斷詞、歧異字、還有我今天要講的知識圖譜的問題)
- 知識圖譜目前的效果
- word2vec背後原理,以及對於知識圖譜的幫助
- 論文分享:如何使用Wikipedia自動建立各種語言的知識圖譜
-
1 2 3 4部分的內容:目標聽眾是給『有Python基礎和對text mining有興趣的人』,不需要有machine learning或deep learning的經驗沒關係。
我希望能讓其他領域的人知道 text mining這個領域在做什麼、知識圖譜的用途等等,所以會盡量用淺顯的例子舉例,遇到數學公式的部分,會注重在它的物理意義是什麼,並且舉例說明這時後的input和output是什麼,套完公式後能達成怎麼樣的效果。
-
第
5部分:目標聽眾需要『有點text mining背景』,這個階段會分享我論文的內容,介紹如何自動建立知識圖譜,我做法的優缺點。
也會demo使用該知識圖譜做出來的機器人和提供該專案github。
過去大家最熟悉的,是像臉書那樣 蒐集使用者平常看得、點擊的文字等資訊
去推論使用者意圖 (User Intension)
用於推薦廣告或其他服務來增加黏著度去獲利
而近年來因為deep learning的突破,智能助理變成當紅的議題
機器人能當秘書、看病、答題等等
都是當今熱門的應用
什麼是知識圖譜呢?
就是用結構化的資料
來儲存下面的關係圖
- 例子1:
- 例子2:


一個知識圖譜應該要包含:
- relation 例如:周杰倫
IS-A歌手 - axiom 例如:
魚住在水裡,這類的規則
目前最成熟的應用為IS-A的關係
例如:
- 周杰倫
IS-A歌手 - PyCon
IS-A研討會
而要從文本中提取出魚住在水裡這類的規則(axiom)
就困難重重
目前都需要人工的輔助
我土炮的知識圖譜也只能做到IS-A關係
背後的原理是下面介紹的Word2Vec
以前沒辦法用向量表示文字的時候
很多就只能用字串比對去進行
造成很大的限制
google研究員Tomas Mikolov 的演算法Word2Vec
能把文字轉成向量後 (他不是第一個,但是目前最好之一,以前的向量都很爛...)
很多基於向量的演算法有都能套用的文字上了
讓Text Mining這個領域有大幅度的進展
-
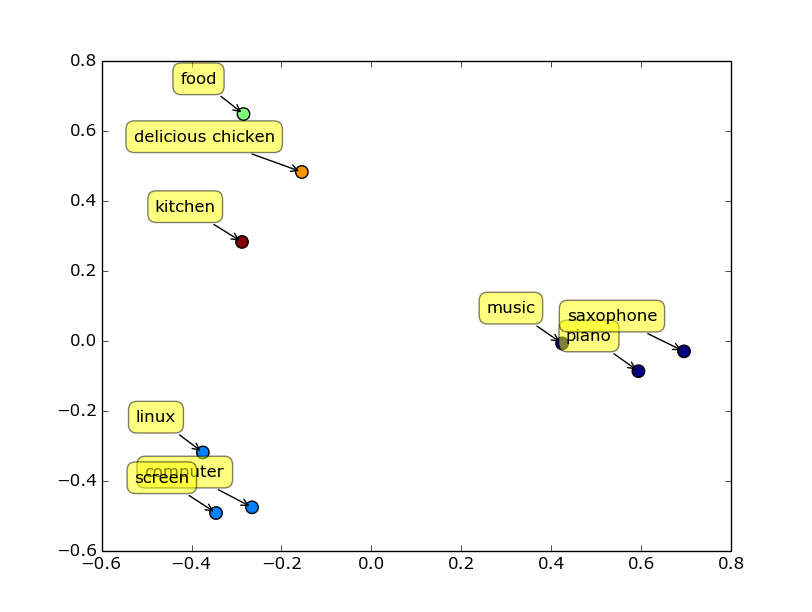 這是透過Word2Vec把文字轉成向量後
可以看到他把
這是透過Word2Vec把文字轉成向量後
可以看到他把電腦、linux、screen放在向量空間的附近 效果非常準確 -
而這張圖透過向量減法 可以推論出
man - woman的向量 近似於king - queen的向量 都是男生到女生的向量

跟其他講者相比,我安排了較多時間去講Introduction和目前的解法
因為聽眾來自各種領域,也不是都了解Text mining在做什麼
所以希望能花多一點時間讓非該領域的聽眾知道
Text mining在解決什麼問題、有哪些應用就夠了
至於我對這個題目有什麼創新的演算法,則只會簡單介紹、帶過
重點還是希望讓聽眾聽完會很清楚這樣做的動機以及了解Text mining的應用
至於實作的方法? 可能得請有興趣的會眾自行學習
能激起聽眾對於Text mining的興趣才是我的主要目的
- 開場
1分鐘- 自介
- 介紹這場talk的流程
- Introduction
4分鐘- Text mining的應用有哪些?
1分鐘 - Text mining有沒有一些共同的痛點呢(e.g. 斷詞、歧異字、還有我今天要講的知識圖譜的問題)
3分鐘
- Text mining的應用有哪些?
- 知識圖譜目前的效果 (以微軟的probase為例,稍微描述paper中的做法)
1分鐘 - word2vec背後原理,以及對於知識圖譜的幫助:
10分鐘- 現在做text mining的人都在用的word2vec,到底好在哪裡? + 傳統的文字向量One-hot encoding的缺點?
3分鐘 - word2vec的精神以及原理介紹
7分鐘
- 現在做text mining的人都在用的word2vec,到底好在哪裡? + 傳統的文字向量One-hot encoding的缺點?
- 論文分享:如何使用Wikipedia自動建立各種語言的知識圖譜:
9分鐘- 簡單介紹我如何訓練model去學會Wikipedia的知識。等該論文發表後會把連結補上,下面附上論文的source code
- 套用到答題機器人上面,效果如何?
- 我透過知識圖譜,還做了那些應用? (用來偵測使用者滑手機的意圖,在keyword extraction上比傳統tf-idf更合適)
- github source code
- API DEMO
- QA
5分鐘
- Taichung.py 擔任過一次講者
- 參加Taichung.py一年多
- 參加過1次PyCon
- 參加過4次Coscup 使用
開源貢獻票參加 - 參加過4次Sitcon 使用
開源貢獻票參加