#NoSQLデータモデリング技法
原文:NoSQL Data Modeling Techniques « Highly Scalable Blog
I translated this article for study. contact matope[dot]ono[gmail] if any problem.
NoSQLデータベースはスケーラビリティ、パフォーマンス、一貫性といった様々な非機能要件から比較される。NoSQLのこの側面は実践と理論の両面からよく研究されている。ある種の非機能特性はNoSQLを利用する主な動機であり、NoSQLシステムによく適用されるCAP定理がそうであるように分散システムの基本的原則だからだ。一方で、NoSQLデータモデリングはあまり研究されておらず、リレーショナルデータベースに見られるようなシステマティックな理論に欠けている。本稿で、私はデータモデリングの視点からのNoSQLシステムファミリーの短い比較といくつかの共通するモデリングテクニックの要約を解説したい。
本稿をレビューして文法を清書してくれたDaniel Kirkdorfferに感謝したいと思う
下の図は主なNoSQLシステムファミリーの進化を表現している。すなわち、Key-Valueストア、BigTableスタイルデータベース、ドキュメントデータベース、全文検索エンジン、そしてグラフデータベースだ。
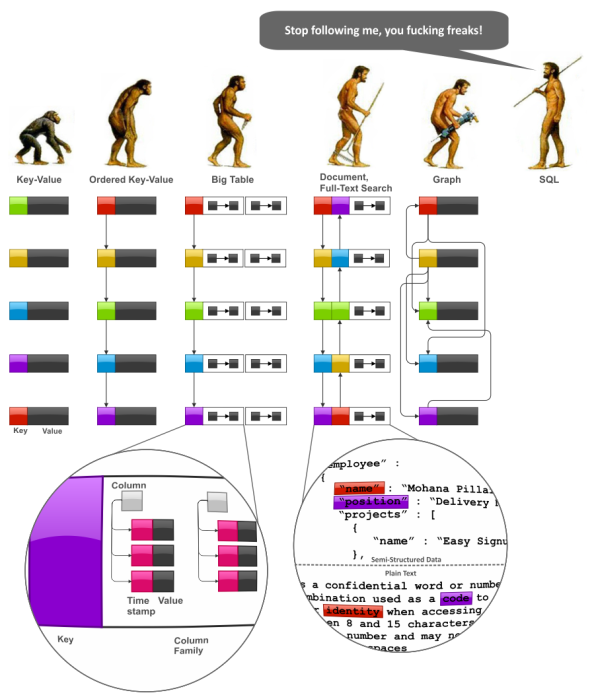
NoSQL Data Models
まず、SQLは主にエンドユーザーとのインタラクションのために遠い昔にデザインされたリレーショナルモデルであることを思い出そう。このユーザー指向の性質はとても大きな示唆を含んでいる。
- エンドユーザーはしばしばバラバラのデータアイテムではなく集計されたレポート情報に興味があり、SQLはこの側面に注意を注いできた。
- 誰も人間のユーザーが並列性、完全性、一貫性、データ型バリデーションを明示的に制御したがるとは予想していなかった。これがSQLが多大な努力をトランザクション保証、スキーマ、参照完全性に注いで来た理由だ。
その一方、ソフトウェアアプリケーションはそれほどデータベースそれ自体での集計や完全性、妥当性に興味がないこともわかってきた。さらに、これらの機能の省略はストアのスケーラビリティとパフォーマンスに非常に大きな影響をもたらした。そしてこれがデータモデルの新たなる進化の原点なのである。
- Key-Valueストレージはとてもシンプルだが強力なモデルだ。下で述べる多くの技法は完璧にこのモデルに適用可能である。
- キー範囲の処理を要求するケースへの適用性の弱さはKey-Valueモデルの大きな弱点の一つだ。順序つきKey-Value(Ordered Key-Value)モデルはこの制限を乗り越え集計能力を素晴らしく発展させた。
- Ordered Key-Valueモデルはとてもパワフルだが、これは値のモデリングに関するいかなるフレームワークも提供しない。一般的に値のモデリングはアプリケーション側で行われるが、BigTableスタイルデータベースはさらに先を行き、バリューをマップのマップのマップ、すなわちカラムファミリー、カラム、そしてタイムスタンプのついたバージョンとしてモデリングする。
- ドキュメントデータベースは二つの素晴らしい改良でBigTableモデルを上回る。ひとつめはただのマップのマップなどではなく、任意の複雑さのスキーマを持つバリューだ。二つ目は、(少なくともいくつかの実装では)データベースが管理するインデックスだ。全文検索エンジンはフレキシブルなスキーマと自動インデックスを備えることから似た種族と考えることも出来る。この二つは、ドキュメントデータベースはフィールド名でインデックスを組織するのに対して、全文検索エンジンはフィールド値でインデックスを組織する点で異なる。Oracle CoherenceのようなKey-Valueストアがインデックスとデータベース内エントリープロセッサを追加したことでドキュメントデータベースに近づいていることも覚えておいてよい。
- 最後に、グラフデータモデルはOrdered Key-Valueモデルを源流とする進化の傍流と見なすことが出来る。グラフデータベースは非常に透過的に(これに依存する)ビジネスエンティティをモデリングすることが出来るが、この領域でも階層的モデリング技法は他のデータモデルの競争力を高める。多くの実装が値をマップかドキュメントとしてモデリングすることを許していることから、グラフデータベースはドキュメントデータベースと関連している。
残りの紙面では具体的なデータモデリング技法とパターンについて言及する。前書きとして、NoSQLデータモデリングの一般的な注意をいくつか述べたい。
-
NoSQLデータモデリングはリレーショナルモデリングと異なり、しばしばアプリケーション特有のクエリからスタートする。
- リレーショナルモデリングは利用可能なデータ構造駆動だ。この設計をするにあたって重要なテーマは**"自分はどの答えを持っているか?"**
- NoSQLデータモデリングはアプリケーション特有のアクセスパターン、すなわち、サポートされるクエリの型駆動だ。メインテーマは**"自分は何を知りたいのか?"**
-
NoSQLデータモデリングは時にリレーショナルデータベースモデリングよりも深いデータ構造とアルゴリズムの理解を必要とする。
-
データ複製と非正規化は一級市民。
-
リレーショナルデータベースは階層的やグラフ状のデータのモデリングや処理にはあまり便利ではない。グラフデータベースは明らかにこの領域の完璧なソリューションであるが、実際に殆どのNoSQLソリューションは驚くほどこの問題に強い。これが本稿が階層的データ構造に対して独立した章を割いている理由である。
データモデリング技法は実装不可知論的ではあるが、本稿を執筆するにあたって私が考慮に入れたのは以下のシステムである。
- Key-Value Stores: Oracle Coherence, Redis, Kyoto Cabinet
- BigTableスタイル: Apache HBase, Apache Cassandra
- Documentデータベース: MongoDB, CouchDB
- 全文検索エンジン: Apache Lucene, Apache Solr
- グラフデータベース: neo4j, FlockDB
この章ではNoSQLデータモデリングの基本的原則について説明する
非正規化はクエリ処理をシンプル化/最適化するか、ユーザーデータを特定のデータモデルにフィットさせるために同じデータを複数のドキュメントかテーブルにコピーすることとも定義出来る。本稿で述べるほとんどの技法が何らかの形で非正規化と関係してくる。
一般的に、非正規化は次のようなトレードオフの助けになる。
- 「クエリデータボリュームまたはクエリごとのIO」 VS 「トータルのデータボリューム」。非正規化を使えば、クエリを処理するのに必要な全てのデータを一カ所にまとめることができる。?これは時に異なるクエリが異なる組み合わせでアクセスされる同じデータを流れることを意味する。ゆえに、データを複製する必要があり、それはトータルのデータボリュームを増加させる。
- 「処理の複雑性」 VS 「トータルのデータボリューム」。モデリング時の正規化と事後的なクエリ実行時結合は明らかに、特に分散システムではクエリ処理の複雑性を増加させる。非正規化はクエリ処理をシンプルにするクエリフレンドリーな構造体にデータをストアすることができます。
適用範囲: Key-Value Stores, Document Databases, BigTable-style Databases
全てのジャンルのNoSQLは何らかの方法でソフトなスキーマを提供している。
- Key-Valueストアとグラフデータベースは典型的に値に制約を設定しないので、値に任意のフォーマットを含めることが出来る。複合キーを用いてひとつのビジネスエンティティのレコード数を変動させることも出来る。例えば、ユーザーアカウントはUserId_name, UserID_email, UserID_messagesなどの複合キーをもつエントリーの集まりのようにモデル化することができる。もしユーザーがemailやメッセージを持っていなければ、対応するエントリーは記録されない。
- BigTableモデルはカラムファミリー内のカラムの変数セットとそれぞれのセルのバージョン変数によってソフトスキーマを提供している。
- Documentデータベースは本質的にスキーマレスだが、いくつかの製品はユーザー定義スキーマを使って入力データをバリデートしている。
ソフトスキーマは複雑な内部構造(ネストされたエンティティなど)を持つエンティティのクラスを形作り、特定のエンティティの構造を変化させることが出来る。この機能は二つの大きな特質を提供する。
- エンティティのネストを使い、one-to-manyリレーションを最小化し、結果的にjoinを削減する。
- ビジネスエンティティと、ひとつのドキュメントかテーブルを使う雑多なビジネスエンティティの間の"技術的な"差異の隠蔽。
これらの性質を下図に表した。この図はあるeコマースビジネスドメインでの製品エンティティのモデリングを図解している。まず、全ての製品はID,Price,Descriptionをそなえることがわかる。次に、異なるタイプの製品は、BookのAuthor,JeansのLengthのように異なる属性を持つことに気づく。これらの属性のうちいくつかは、Music AlbumのTracksのように、one-to-manyまたはmany-to-manyの性質を持っている。例えば、Jeans属性はブランドと特定の製造者の間で一貫していない。この問題をリレーショナル正規化データモデルで解決することは可能であるが、その解決方法はエレガントさからはほど遠いものになってしまう。ソフトスキーマでは全てのプロダクトの種類とそれらの属性をモデリングした単一の集計(product)を使うことが出来ます。
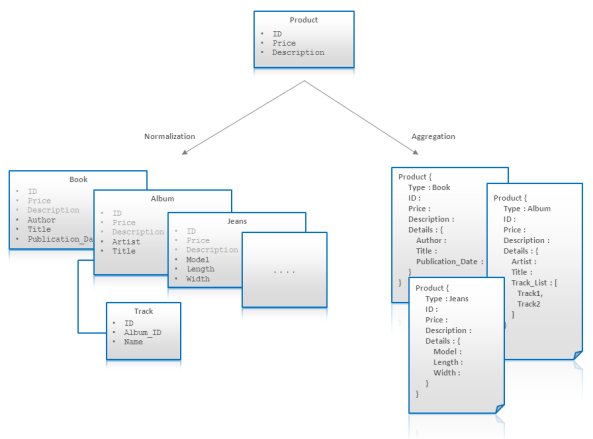
非正規化の埋め込みはパフォーマンスと一貫性に甚大な影響を与えるので、アップデートフローには特別な注意を払うこと。
適用範囲: Key-Value Stores, Document Databases, BigTable-style Databases
JoinはNoSQLソリューションではほとんどサポートされることはない。"知りたいこと指向"なNoSQLの性質の結果として、joinはしばしば、リレーショナルモデルがクエリ実行時に実行されるのに反し、設計時に行われることになる。クエリ実行時ジョインは殆ど常にパフォーマンスペナルティをもたらしますが、多くの場合非正規化と集計、すなわちネスト化されたエンティティを使ってこれを回避することが出来る。もちろん多くの場合joinは不可欠なので、アプリケーションがハンドルするべきである。主なユースケースは以下。
- many-to-manyリレーションシップはしばしばリンクでモデリングされ、joinを要求する。
- 集計はエンティティ内部が頻繁に編集されるとき適用出来ない。通常は何か起こったことを記録し続け、値が変わったときではなくクエリ実行時にジョインするのほうが良い。例えば、メッセージングシステムはMessageエンティティをネストしたUserエンティティとしてモデリング出来る。しかしメッセージが頻繁に追加されるとしたら、Messageを独立したエンティティとして扱い、それらをクエリ実行時にjoinしたほうがよい。
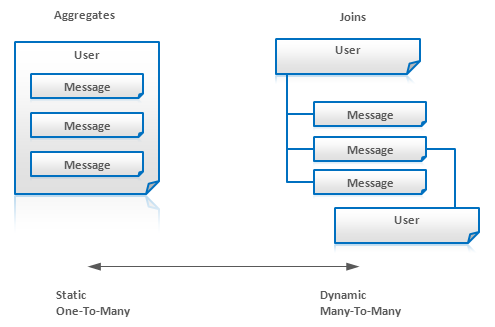
適用範囲: Key-Value Stores, Document Databases, BigTable-style Databases, Graph Databases
##一般的なモデリング技術 この章では様々なNoSQL実装に適用可能なモデリング技術を議論する。
全てではないが、多くのNoSQLソリューションは限定的なトランザクションをサポートしている。分散ロックかapplication-managed MVCCを使ってトランザクショナルな振る舞いを達成しているものもあるが、ACID特性のいくつかを保証するために集計技法を使ってデータをモデリングするのが一般的だ。
パワフルなトランザクション機構がリレーショナルデータベースの不可欠な部分である理由の一つは、正規化されたデータは典型的には複数箇所の更新が必要とされるからである。一方、集計(Aggregate)では単一のビジネスエンティティを単一のドキュメント、行、またはkey-valueペアとしてストアし、自動的に更新することが可能である。
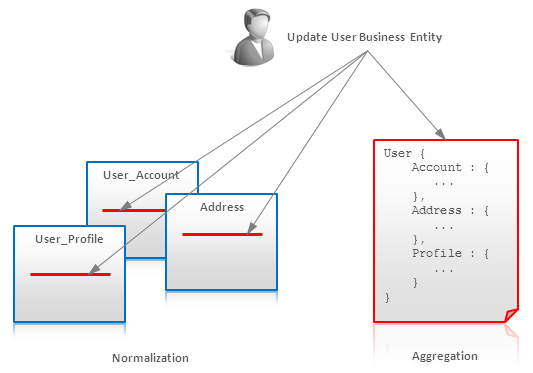
もちろんデータモデリング技法としてアトミックな集計は完全なトランザクションのソリューションではないが、もしストアがある程度の一貫性保証、ロック、test-and-set機構を提供する場合、Atomic Aggregateは適用可能だ。
適用範囲: Key-Value Stores, Document Databases, BigTable-style Databases
おそらく順序つきでないKey-Valueデータモデルの最大の利点は、単にキーをハッシュするだけでエントリーを複数のサーバーにパーティションできることだ。ソートは物事を複雑にしてしまうが、あるときとしてアプリケーションは、ストレージがそのような機能を提供していなかったとしても順序つきキーを利用することが出来る。例としてemailメッセージのモデリングを考えてみよう。
- いくつかのNoSQLストアはシーケンシャルなIDを生成することが出来るアトミックなカウンターを提供する。このケースではuserID_messageIDを複合キーとしてストアすることが出来る。もし最新のmessage IDを知っていたら、その前のメッセージをトラバースすることは可能である。また与えられたどんなmessage IDに対しても前後のメッセージをトラバースできる。
- メッセージは、例えば日時バケットのようなバケットにグループ化することができる。これでどんな与えられた日付や現在の日付からでもメールボックスを前や後ろにトラバース出来る。
適用範囲: Key-Value store
Dimensionality Reductionは多次元のデータをKey-Valueモデルかその方かの多次元モデルにマッピングすることができる技法だ。
伝統的な地形情報システムはインデックスにいくつかのQuadtreeかR-Treeのバリエーションを利用している。これらのデータ構造はin-placeに更新される必要があり、データボリュームが巨大なときには操作が高くつく。代わりのアプローチは、2D構造をトラバースしてエントリーのプレーンなリストに引き延ばすものだ。このテクニックの良く知られた例はGeohashである。GeohashはZ-likeスキャンで2D空間を満たし、それぞれのムーブは方向によって0か1にエンコードされる。軽度と緯度のビットは移動するたびに交互に移動する。このエンコーディングプロセスは以下の図のように表され、黒と赤のビットはそれぞれ軽度と緯度を表す。
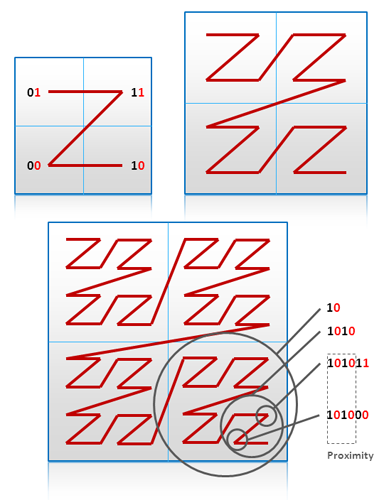
Geohash Index
Geohashの重要な機能は、図で示したようにビット幅のコード近傍を使って領域の距離を見積もれることだ。Geohashエンコーディングはプレーンなデータモデルを使い、空間的なリレーションを保持したソート済みkey valueのようにチリ情報を保存出来ることである。BigTableでの次元削減の技法は[6.1]で述べられている。Geohashや関連のテクニックについては[6.2]と[6.3]に詳しい。
適用範囲: Key-Value Stores, Document Databases, BigTable-style Databases
Index Talbeはインデックスを内部的にサポートしていないストアでインデックスを利用するためのとても素直なテクニックだ。そのような保存の最も重要なクラスはBitTableデータベースだ。このアイデアはアクセスパターンに応じたキーの特別なテーブルを作り維持するというものだ。たとえば、user IDとしてアクセスされるuser accountがストアされるマスターテーブルがあるとする。特定の都市から全てのユーザーを取得するクエリはcityがキーである追加のテーブルを使ってサポートされる。
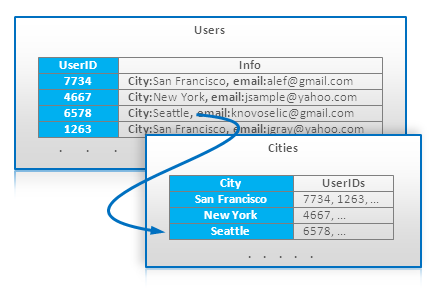
Index Table Example
インデックステーブルはマスターテーブルの更新やバッチモードごとに更新できる。どちらの方法でも、これはパフォーマンスペナルティの追加と一貫性の問題を招く。
インデックステーブルはリレーショナルデータベースにおけるマテリアライズドビューの相似形と考えることも出来る。
適用範囲: BigTable-style Databases
複合キーはとても一般的なテクニックだが、順序つきキーを使うとき大変有益である。セカンダリソートで結合した複合キーで、前述の次元削減テクニックと本質的に似た多次元インデックスを構築することが出来る。例えば、各レコードがユーザー統計であるレコードセットを考える。もしこれらの統計をユーザーの出身地で集計した場合、そのストアが(BigTable-styleシステムのように)部分キーマッチでのキーレンジのセレクトをサポートしていれば、特定の州か市のレコードをイテレーションすることができるフォーマット(State:City:UserID)のキーを使うことが出来る。
SELECT Values WHERE state="CA:*"
SELECT Values WHERE city="CA:San Francisco*"

適用範囲: BigTable-style Databases
複合キーはインデックスだけでなくグルーピングの異なる型にも使われる。例を考えよう。インターネットユーザーと彼らがどのサイトから訪問したかの情報の膨大なログレコードの配列がある。目的は各サイトのユニークユーザー数だ。これは次のSQLクエリに似ている。
SELECT count(distinct(user_id)) FROM clicks GROUP BY site
この状況はUserIDプレフィックスの複合キーを用いて以下のようにモデル化できる。
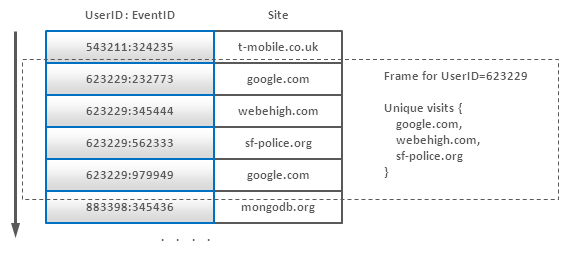
これはそれぞれのユーザーの全レコードの一カ所へのまとまりを保持するという考えなので、このようなフレームをメモリにフェッチして(それぞれのユーザーはあまりに大量のイベントを生成することはできない)、ハッシュテーブルか何かを使ってサイトをの複製を削除することが出来る。他の手法は、1ユーザーにつき1エントリーを持ち、イベント到達とともにsiteをこのエントリーに追加していくというものだ。 それでもやはり、主要な実装でのエントリー挿入より一般的にエントリ編集の効率性は低下する。
適用範囲: Ordered Key-Value Stores, BigTable-style Databases
###(10)転置検索 - 直接集計(Inverted Search - Direct Aggregation) このテクニックはデータモデリングというよりデータ処理パターンだ。そうはいっても、データモデルはこのパターンの利用によってインパクトを受ける。このテクニックの主なアイデアは基準に見合ったデータを探すのにインデックスを使うことだが、独自の表現またはフルスキャンを用いてデータを集計する。例を考えよう。インターネットユーザーと彼らがどのサイトから訪問したかの情報の膨大なログレコードがある。各レコードはuser ID, ユーザーが所属するカテゴリー(Men, Women, Bloggers, etc)、出身市、訪れたサイトの情報を持つ。目的はこのオーディエンスによって見いだされるそれぞれのカテゴリーにおけるユニークユーザーという点でいくつかの基準に達するオーディエンスを得ることである(すなわち基準を満たすユーザーのセット)。
{Category -> [user IDs]} か {Site -> [user IDs]}といった転置インデックスを用いることで基準を満たすユーザーの検索が効果的に行われることは明白である。このようなインデックスを用いることで、対応するユーザーIDを交差またはユニーク化して(これはuser IDsがソート済みリストかビットセットとしてストアされていれば効果的に実行可能だ)、オーディエンスを入手することが出来る。しかしクエリライクな集計に似ているオーディエンスの記述
SELECT count(distinct(user_id)) ... GROUP BY category
は、カテゴリ数が大きくなると転置インデックスの仕様は効率的ではなくなる。これを解決するため、{UserID -> [Categories]}という形式の直接インデックスを構築して最終レポートを構築するためにイテレーションすることが出来る。このスキーマは以下の図のようである。
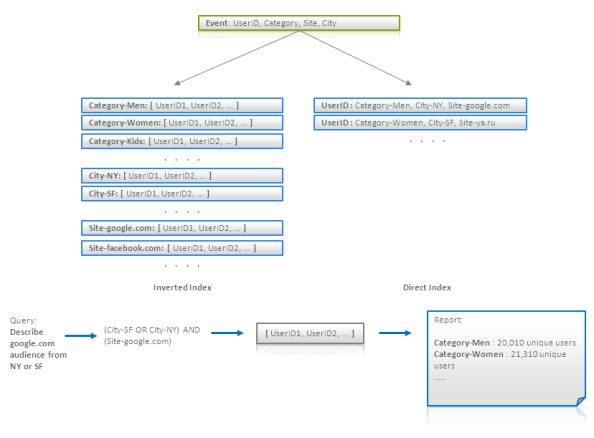
最後の注意として、オーディエンス中のユーザーIDのそれぞれのレコードのランダム取得は非効率になる可能性がある。誰かがバッチクエリ処理の影響でこの問題と取っ組み合うことになるかもしれない。これは、いくつかのユーザーセットを(ことなる基準で)事前計算できることを意味し、そのときこのオーディエンスのバッチの全てのレポートは直接または転置インデックスのフルスキャンで計算可能であるということだ。
適用範囲: Key-Value Stores, BigTable-style Databases, Document Databases
##階層モデリング技術(Hierarchy Modeling Techniques)
ツリーや(非正規化の力を借りた)任意のグラフは単一のレコードやドキュメントとしてモデリングできる。
- このテクニックはツリーが一回でアクセスされる(例えば、ブログコメントのツリー全体をフェッチして投稿とともに表示する場合)場合に効果的だ。
- エントリーへの検索と任意のアクセスは問題になるかもしれない。
- 更新は殆どのNoSQL実装で(独立ノードよりも)非効率である。
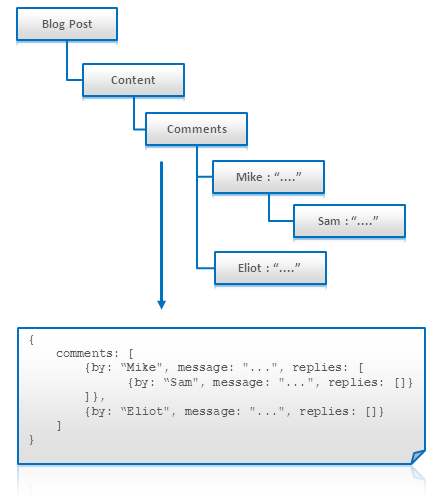
適用範囲: Key-Value Stores, Document Databases
近接リスト?はグラフモデリングの素直な手法であるー各ノードは子孫か先祖を指す配列を含む独立したレコードとしてモデル化される。これはノードを親か子供の識別子で検索することも出来るし、もちろん、クエリごとに一回ずつホップしてトラバースすることもできる。このアプローチは通常与えられたノードの全てのサブツリーを深さ優先探索や幅優先探索で取得するのには非効率である。
適用範囲: Key-value Stores, Document Databases
マテリアライズドパスはツリーライクな構造の再帰的なトラバースを避けるのに役立つテクニックだ。このテクニックは非正規化の一種と考えることができる。このアイデアはそれぞれのノードにその全ての親か子供の識別子を属性づけることなので、トラバーサル無しで全ての祖先か子孫を求めることが出来る:
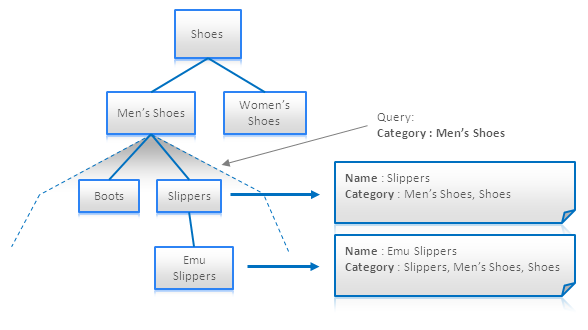
Materialized Paths for eShop Category Hierarchy
このテクニックは、階層構造をフラットなドキュメントに変換出来るので、全文検索エンジンに特に有用である。上の図では全ての製品かMen's Shoesカテゴリのサブカテゴリの全ての製品がカテゴリ名のシンプルなクエリで取得出来る様子がわかる。
マテリアライズドパスはIDのセットかIDを結合した単一の文字列として保管される。後者では正規表現を用いてパスの一部に一致するノードを検索することが出来る。この様子は下の図で示される。
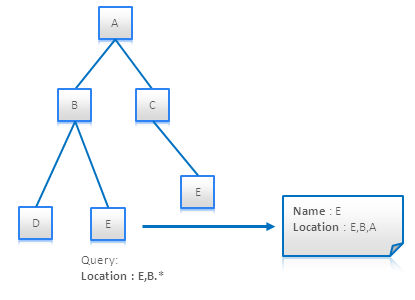
Query Materialized Paths using RegExp
適用範囲: Key-Value Stores, Document Databases, Search Engines
Nested setsはツリー状の構造体をモデリングするための標準的なテクニックだ。リレーショナルデータベースで広く利用されているが、Key-Value StoreやDocument Databaseにも完全に適用可能である。これは下図のように、ツリーの葉をひとつの配列に保管し、startとendインデックスによる葉のレンジをそれぞれの非葉ノードにマップするアイデアだ。
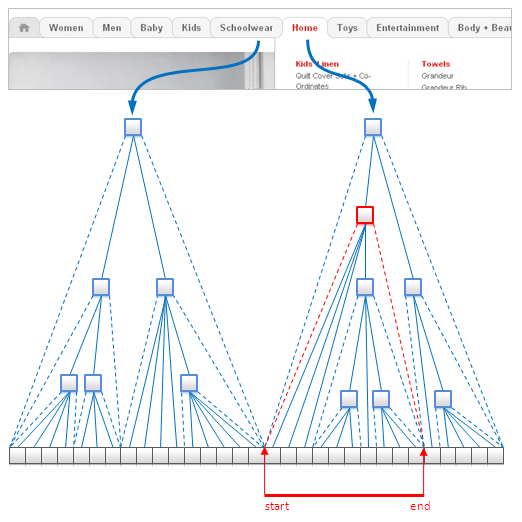
Modeling of eCommerce Catalog using Nested Sets
この構造はメモリのフットプリントが小さく、トラバーサルなしで与えられたノードの全ての葉をフェッチ出来るので、不変性のデータにとって非常に効率的である。だがしかし、葉の追加はインデックスの高価な更新を起こすので、挿入と更新はまったく高コストである。
適用範囲: Key-Value Stores, Document Databases
検索エンジンは通常フラットなドキュメントを扱う、すなわち各ドキュメントはフィールドと値のフラットなリストである。このデータモデリングの目的はビジネスエンティティをプレーンなドキュメントにマッピングすることであり、これはエンティティが複雑な内部構造を持っていた場合チャレンジングである。ひとつの典型的なチャレンジではドキュメントを階層構造でマッピングする、すなわちネストされたドキュメントが入っているドキュメントである。次のように考えよう。
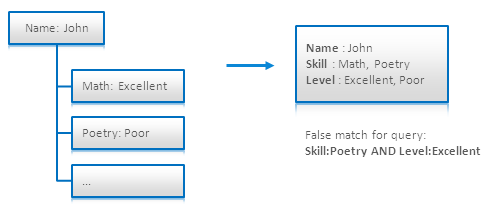
Nested Documents Problem
各ビジネスエンティティはレジュメのようなものである。これは人物の名前とスキルとスキルレベルをを含む。このようなエンティティをモデリングする明らかな方法は、SkillとLevelフィールドを持つプレーンドキュメントを作成することだ。このモデルではスキルかレベルから人物を検索できるが、両方のフィールドを含むクエリは上の図のようにfalseマッチを起こすので好ましくない。
これを乗り越える方法が[4.6]で提案されている。このテクニックの主な考え方はそれぞれのスキルと対応するレベルをSkill_iとLevel_iフィールドの専用のペアとしてインデックスしてこれらのペアを並列に検索することである(クエリ内でORされた単語の数はひとりの人物のスキルの数の最大値まで)。
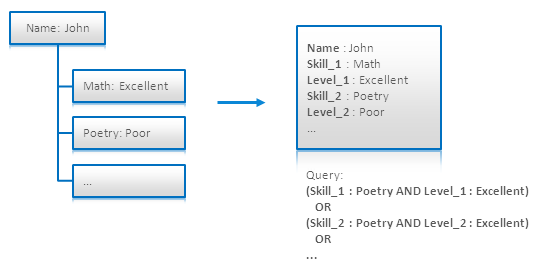
Nested Document Modeling using Numbered Field Names
このアプローチはネスト構造の数の関数として急速に複雑性が上昇するので、あまりスケーラブルではない。
適用範囲: Search Engines
ネストドキュメントの問題は[4.6]で述べられている他の方法でも解決出来るかもしれない。このアイデアはドキュメント内での単語間の距離を制限した近傍クエリを用いる。下図では、全てのスキルとレベルがひとつのSkillAndLevelフィールドにインデックスされており、クエリは"Excellent"と"Poetry"が隣接しているべきことを示している。

Nested Document Modeling using Proximity Queries
[4.3] ではSolrでの成功事例が述べられている。
適用範囲: Search Engines
neo4jのようなグラフデータベースは例外的に与えられたノードの近傍探索か二つか少数のノードのリレーションシップ探索が得意だ。しかし、巨大なグラフのグローバルな処理は、汎用目的グラフデータベースが上手くスケールしないため効率があまりよくない。分散グラフ処理は、例えば私の以前の記事で述べたMapReduceとMessage Passingパターンで実行出来る。このアプローチはKey-Value store, Document database, BigTabl-styleデータベースを巨大グラフの処理に適したものにする。
適用範囲: Key-Value Stores, Document Databases, BigTable-style Databases
最後に、NoSQLデータモデリングに関連した便利なリンクを提供する。
- Key-Vlue Stores:
- http://www.devshed.com/c/a/MySQL/Database-Design-Using-KeyValue-Tables/
- http://antirez.com/post/Sorting-in-key-value-data-model.html
- http://stackoverflow.com/questions/3554169/difference-between-document-based-and-key-value-based-databases
- http://dbmsmusings.blogspot.com/2010/03/distinguishing-two-major-types-of_29.html
- BigTable-style Databases:
- http://www.slideshare.net/ebenhewitt/cassandra-datamodel-4985524
- http://www.slideshare.net/mattdennis/cassandra-data-modeling
- http://nosql.mypopescu.com/post/17419074362/cassandra-data-modeling-examples-with-matthew-f-dennis
- http://s-expressions.com/2009/03/08/hbase-on-designing-schemas-for-column-oriented-data-stores/
- http://jimbojw.com/wiki/index.php?title=Understanding_Hbase_and_BigTable
- Document Databases:
- http://www.slideshare.net/mongodb/mongodb-schema-design-richard-kreuters-mongo-berlin-preso
- http://www.michaelhamrah.com/blog/2011/08/data-modeling-at-scale-mongodb-mongoid-callbacks-and-denormalizing-data-for-efficiency/
- http://seancribbs.com/tech/2009/09/28/modeling-a-tree-in-a-document-database/
- http://www.mongodb.org/display/DOCS/Schema+Design
- http://www.mongodb.org/display/DOCS/Trees+in+MongoDB
- http://blog.fiesta.cc/post/11319522700/walkthrough-mongodb-data-modeling
- Full Text Search Engines:
- http://www.searchworkings.org/blog/-/blogs/query-time-joining-in-lucene
- http://www.lucidimagination.com/devzone/technical-articles/solr-and-rdbms-basics-designing-your-application-best-both
- http://blog.griddynamics.com/2011/07/solr-experience-search-parent-child.html
- http://www.lucidimagination.com/blog/2009/07/18/the-spanquery/
- http://blog.mgm-tp.com/2011/03/non-standard-ways-of-using-lucene/
- http://www.slideshare.net/MarkHarwood/proposal-for-nested-document-support-in-lucene
- http://mysolr.com/tips/denormalized-data-structure/
- http://sujitpal.blogspot.com/2010/10/denormalizing-maps-with-lucene-payloads.html
- http://java.dzone.com/articles/hibernate-search-mapping-entit
- Graph Databases:
- Demensionality Reductions: