Why we use Clojure at Unfold
My experience with Machine Learning
And why it's the ideal language for web-apps
Anshul Amar | aamar@unfold.com
To view as a slideshow, please use the cool GistDeck.
- Improving CRUD
- A case study: Document Classification
- Why Clojure helps
CRUD is a (somewhat pejorative) description for a "standard" or vanilla web-app.
Create
Read
Update
Delete
I spent years doing a lot of standard CRUD functionality on the web.
Specifically, how can we allow humans to get the same benefits, but perform less CRUD?
-
Create/Update:
- Guess data for you
- Validate data -> Probabilistic Validation
-
Read:
- Complex query interface -> Context- aware search
- Automated Suggestions & filtering
-
Delete:
- Reject counterproductive data (e.g. Spam, Gaming)

- Get each one into the system (upload it, or it arrives via fax)
- Categorize it
- Add a lot of metadata
- System will route it to correct recipient and provide them with correct options
- Reroute client's fax machines to us
- User dumps faxes to us everything arrives via mail/handoff
- Classify as many of them as possible automatically
- Route the "tricky ones" to a human
- N.B: This only happened after:
- A minimal side project
- A lot of conversation wrapping our heads around it
- It became clear that if it worked, it would save the company $$

We want to classify them into a ~40 different categories: e.g. Lab Result, Rx Renewal, Insurance Form.
Docs are form-based, lots of shorthand, very little prose => "bag of words" approach fits.
- Native Perl libraries
- These turned out to be slow/incomplete
- Reimplement some components by hand
- Still very slow
- Lots more numerical optimizations possible, but this would take a lot of coding
- Perl layer queries DB, business logic, dumps to file-system
- Feed into Rainbow/Mallet (open-source tools, optimized version of TF-IDF (discussed later))
- Back to DB
- Bad scans (upside-down, etc.)
- Page-splits
- Pages out of order
- Special rule-based classifiers
- Conditional sub-categorization (refill vs. renewal)
- Single fax = multiple "documents"
- As before, train based on what humans have done before
- What is page-to-page similarity? Similarity over a split?
- Classifier assigns to one of these cases:
- 1/1: singleton page
- 1/n: first page (e.g. "cover sheet")
- n/n: last page
- m/n: interim page
- Combining above yielded decent results
- Go through all of this, then do the classification


- Represent the core business logic
- Deal with web and database
- Be able to run basic, tweakable algorithms
- Be able to implement your own
- Avoid disk, avoid streams
- Run as much as possible in memory
- Some ML problems don't require a lot of exploration, but require scale
- Ultimately a mixed-stack may be useful
- Separate technologies can sometimes help isolate concerns
But: I've persistently found great value in being able to conveniently access ML constructs from within my primary "business-logic" language.
- Can handle the web/db stuff perfectly well
- Can implement domain logic perfectly well
- Be able to run basic, tweakable algorithms
- Philosophy of "small composable bits"
- Focus on processing lists
- Almost everything's a seq
- (entities & protocols can interfere a bit)
- e.g. Incanter uses a different internal format
- but it's trivial to port data back and forth
- Easy to implement algorithms
TF-IDF has come in handy both in doc classification and Unfold document clustering.
- TF-IDF is often associated with search, but it is a generic weighting scheme that can be useful in classification, clustering, etc.
- Basic formulas:

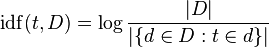

-
Thanks to Ignacio Thayer
-
Implement these formulas
-
Add stopwords
-
My changes:
- Disentangle file-access from algorithm
- Allow domain-specific tokenization
- Add Classification API
(ns tf-idf
(:use clojure.test)
(:require [clojure.string :as string]))
(def default-stopwords (set (string/split #"\n" (slurp "./stopwords.txt"))))
(defn default-tokenize
"Default tokenizer. Can be overridden by"
[text]
(remove default-stopwords (string/split (.toLowerCase text) #"[^a-zA-Z0-9]+")))
(def tokenize default-tokenize)
(defn sq [x] (Math/pow x 2))(defn idf [total-doc-count match]
(sq (Math/log (/ total-doc-count (+ 0 (count (keys match)))))))
(defn tf-map [doc-id raw & {:keys [tokenize]}]
(let [word-counts (frequencies ((or tokenize default-tokenize) raw))]
(zipmap (keys word-counts) (map (fn [c] {doc-id c}) (vals word-counts)))))
(defn accum-tfidf [total-doc-count match]
(map (fn [doc w-count] {doc (* w-count (sq (idf total-doc-count match)))})
(keys match) (vals match)))
(defn score-all [index total-doc-count search-terms]
(let [results (keep index search-terms)]
(apply merge-with +
(mapcat (partial accum-tfidf total-doc-count) results))))(defn take-top-by-val [n m]
(take n (reverse (sort-by second m))))
(defn map-hash [f m]
(reduce merge (map (fn [[k v]] {k (f [k v])}) m)))
;; pass klass for classification rather than search
(defn learn [db doc-id raw-text & [tokenize klass]]
(let [db (or db {:count 0 :index {} :norms {}})
tf (tf-map (or klass doc-id) raw-text :tokenize tokenize)
new-count (inc (:count db))
new-index (merge-with merge (:index db) tf)
;; NOTE: this part is recomputed in full each time; this can be optimized further
norms-raw (apply merge-with + (mapcat (partial accum-tfidf new-count) (vals new-index)))]
{:count new-count
:index new-index
:norms (zipmap (keys norms-raw) (map #(Math/sqrt %) (vals norms-raw)))}))
(defn learn-all [docs]
(reduce #(apply learn % %2) nil docs))(defn search [db raw-text & {:keys [tokenize]}]
(let [results (score-all (:index db) (:count db) ((or tokenize default-tokenize) raw-text))]
(take-top-by-val 3 (map-hash (fn [[k v]] (/ (results k) ((:norms db) k))) results))))
(def classify search)
(deftest search-test
(let [db (learn-all [[:a "all's well that ends well"]
[:b "some other thing that ends well"]
[:c "another thing"]])]
(is (= (map first (search db "well")) [:a :b]))
(is (= (map first (search db "thing")) [:c :b])))
(let [db-klass (learn-all [[:a "all's well that ends well" nil "play"]
[:b "all quiet on the western front" nil "movie"]
[:c "all about eve" nil "movie"]
[:d "measure for measure" nil "play"]])]
(is (= (ffirst (search db-klass "all")) "movie"))
(is (= (ffirst (search db-klass "measure")) "play"))))- ML is often taught using great tools like Matlab and R
- But it's often very valuable in the early days to call ML directly from your main language
- It's no fun to do this if your main language (due to power or idioms) make ML algorithms slow or awkward
- Clojure offers a great mix of practicality for business logic and practicality for ML
Anshul Amar aamar@unfold.com