Today, I released the new version of MessagePack for Ruby!
- Even faster
- New API
- API reference
I rewrote all the code and achieved significant performance improvement, especially for serialization. I compared the new version to the old version (v4) using ruby-serializers benchmark, and the new version is faster for all data sets including Twitter, Image, Integers, Geo and 3D model.
This benchmark test uses JSON objects available from Twitter API. The new version "msgpack" shows 4x faster serilization performance compared to the pervious version "msgpack(old)".
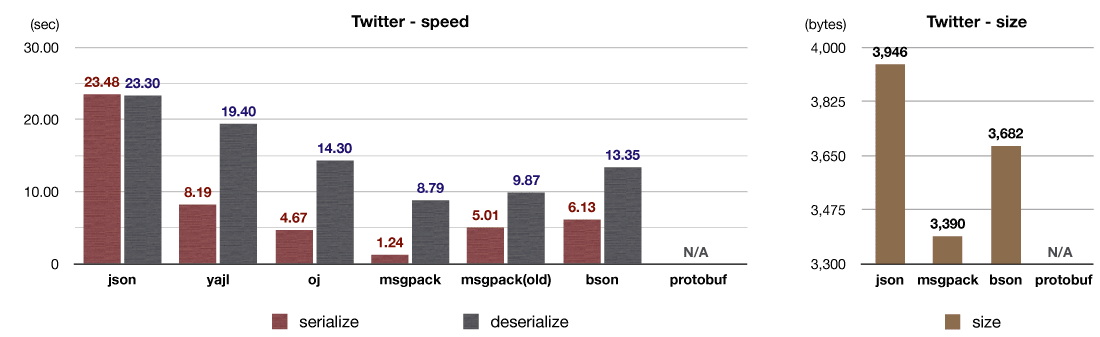
I found out that in most cases, serialized data fit into several KBs. So I implemented a 4KB fixed-length memory pool to focus on such typical cases. This optimization reduces number of expensive malloc(3) calls. Because this memory pool is shared across all instances, you don't have to write verbose code to reuse serializer instances. All serializations get faster automatically.
This memory pool also reduces memory fragmentation. Memory fragmentation is a considerable problem for server programs which need to run 24/7 because it increases memory footprint and forces you to restart the server regularly (the claimed memory cannot be released effectively in many cases).
By the way, jemalloc is another way to reduce memory fragmentation. It improves the memory usage of Ruby on Rails by 10-20%.
This test uses ~6KB image data and a few metadata.
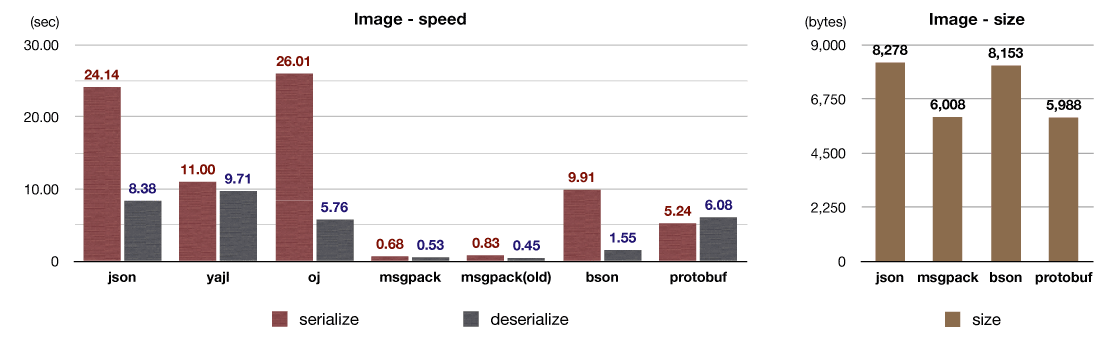
While most serialized data fits into 4KB, other data include much larger objects and may exceed 4KB in size. So, msgpack-ruby takes these binary large objects into account and can deserialize them without copying. It takes advantage of the Copy-on-Write capability of Ruby's String class (CRuby).
Copy-on-Write is, as its name suggests, a technique that copies the data when an object is (destructively) modified, not when the object is duplicated. And not copying large binary objects means drastic performance improvement. This technique is very effective to deserialize image data because typically, we don't (destructively) modify deserialized image objects or source data. Instead, we just release the used objects.
(*In this test, images are encoded in base64 format for JSON libraries because JSON can't handle binary data. But the measurement doesn't include the encoding/decoding time, should be included actually)
This uses an integer array.
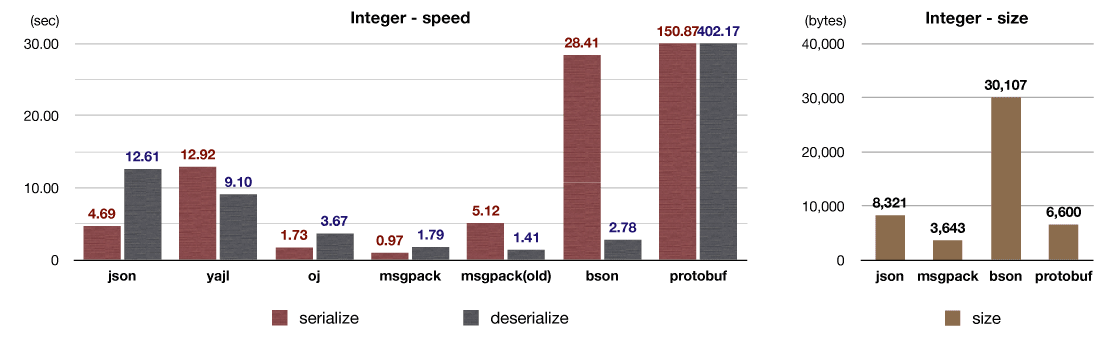
A major overhead of serialization is memory allocation, copying and function invocation (C function invocation from C functions). Function invocation overhead is actually large. The inline expansion of a function sometimes improves performance by 2 or 3 times. The old implementation of msgpack-ruby used to append data into a String instance. But it always caused function invocation once or twice for each objects. This created a serious overhead to serialize many small objects.
So, I implemented a new buffer class and tightly coupled it with the serializer (and deserializer) so that compilers can inline expand functions. This is the reason why serialization performance sharply improved in this test.
I used a geographical data set available from GeoJSON as an alternative test.
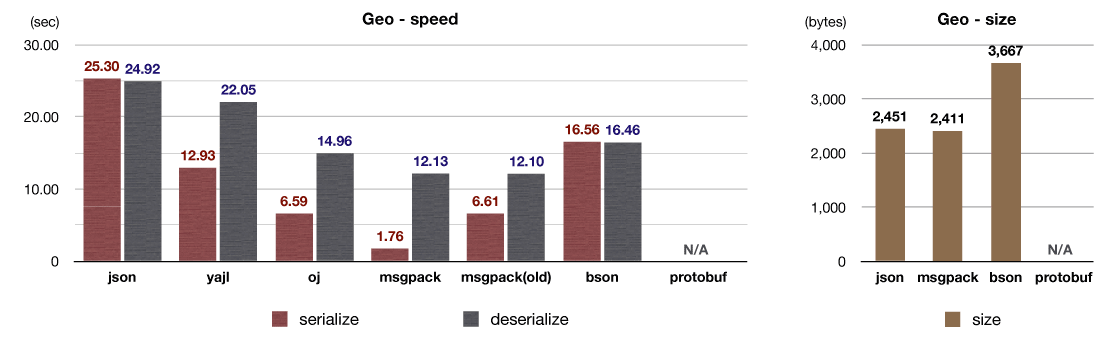
GeoJSON mainly consists of hash and string objects but also includes floating points. Memory pool and inline expansion help to improve serialization performance.
I used 3D model data as an special test case. The sample data is available from blender-webgl-exporter. This data consist of a lot of floating points.
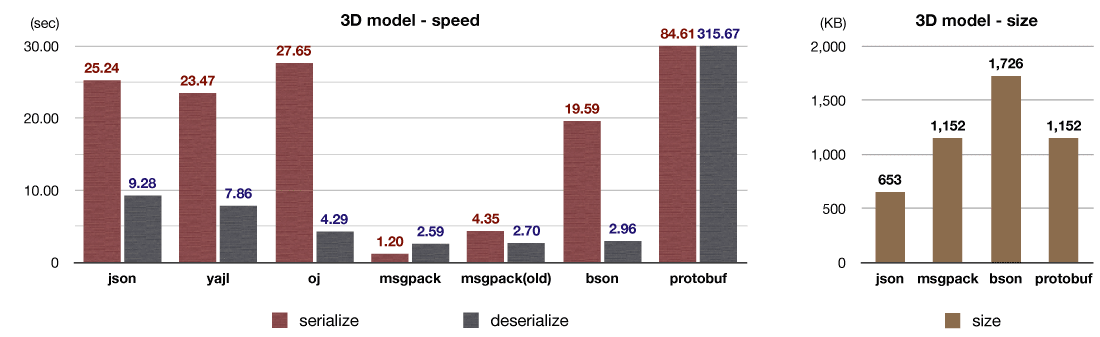
(*JSON is smaller than binary formats such as msgpack and bson in this test. This is because JSON uses decimal to represent numbers while binary formats use binary. It means these two formats represent different data to be precious)
MessagePack is "casual" like JSON, but it's a "serious" binary serializer at the same time. For example, Treasure Data adopted MessagePack as the data reporesentation format for their columnar storage system. And Fluentd, a log collector which handles logs in semi-structured style, uses MessagePack to represent collected logs internally. Pinterest uses MessagePack with memcached and Redis also includes MessagePack.
So, you can use msgpack for network protocols or file formats to bring your software up from a "casual" small tool to "serious" software without breaking the compatibility with external programs. With this new version, I added some APIs that might be useful for serious software.
Unpacker#skip method decodes data without creating a new instance. It means it skips the first object.
Instantiation is a major overhead for deserilization: its performance may get 5 times faster without instantiation.
For example, you can deserialize objects lazily (unpacker deserializes objects only when an object is accessed) so that you can skip unused objects. Unpacker#skip should improve performance significantly in this case.
MessagePack's Array format stores the number of elements first and objects follow.
In other words, an array becomes a sequence of objects if you removed the header using Unpacker#read_array_header method. This technique is useful to handle a huge array which doesn't fit in memory.
Packer#write_array_header does the opposite. You can convert a sequence of objects into an array. This is useful if you don't know the number of elements of an array before serializiong it.
You can manipulate the internal buffer directly using this MessagePack::Buffer class. This is useful to mix an original header or footer in a msgpack stream or add custom types to a msgpack stream.
The internal architecture of MessagePack::Buffer is a queue of chunks. So, you can append or prepend data efficiently. And it uses the above fixed-length memory pool as a memory allocator to handle small data efficiently.
Additionally, it uses above Copy-on-Write optimization that makes it possible to handle binary large objects very efficently.
MessagePack for Ruby version 5 improves serialization speed because of fixed-lenght memory pool and tightly-coupled buffer implementation. And it introduces new API, MessagePack::Buffer and some Packer/Unpacker methods.
I used following environment for the benchmark:
- OS: Mac OS X 10.8.2
- CPU: Intel COre i7 2.7GHz
- Memory: 16GB 1600MHz DDR3
- ruby 1.9.3p194 (2012-04-20 revision 35410) [x86_64-darwin11.4.0]
- ruby-serializers
- gem
- json 1.7.5
- yajl-ruby 1.1.0
- oj 1.4.7
- msgpack 0.5.0
- msgpack 0.4.7 (old)
- bson_ext 1.8.0
- protobuf 2.5.3
Links:
Great article