An interesting regex — Parsing out template constructor strings for Mad Libs
/\[.*?\]|[a-z0-9']+|[^a-z0-9'\[\]\s]+|\s+/igIn September 2022, I was part of a small team that built Mad Libs, an application that reimagines the popular word game in a browser-based forum/blog context. Among other features, the app includes:
- A template maker, in which a user inputs a constructor string that is converted to a Mad Libs template that other users can then fill in
- After a template is created, while another user is in the midst of filling it in, redaction of the template's unchanging ("static") words, which can be progressively unredacted using an on-screen slider
Making these two features work together requires careful parsing of a template's constructor string before the template officially enters the database, which involves the regular expression shown above. I'll break down how it works here.
- Summary / context
- Regex components:
- The results of the regex parse
- The rest of the process
- Screenshots
- About me
I highly recommend checking out the application itself for context. You can see user-created templates here, try your hand at creating a template yourself here (requires creating an account), or just check out screenshots here. The redaction feature is most visible for templates that contain a lot of "static" words.
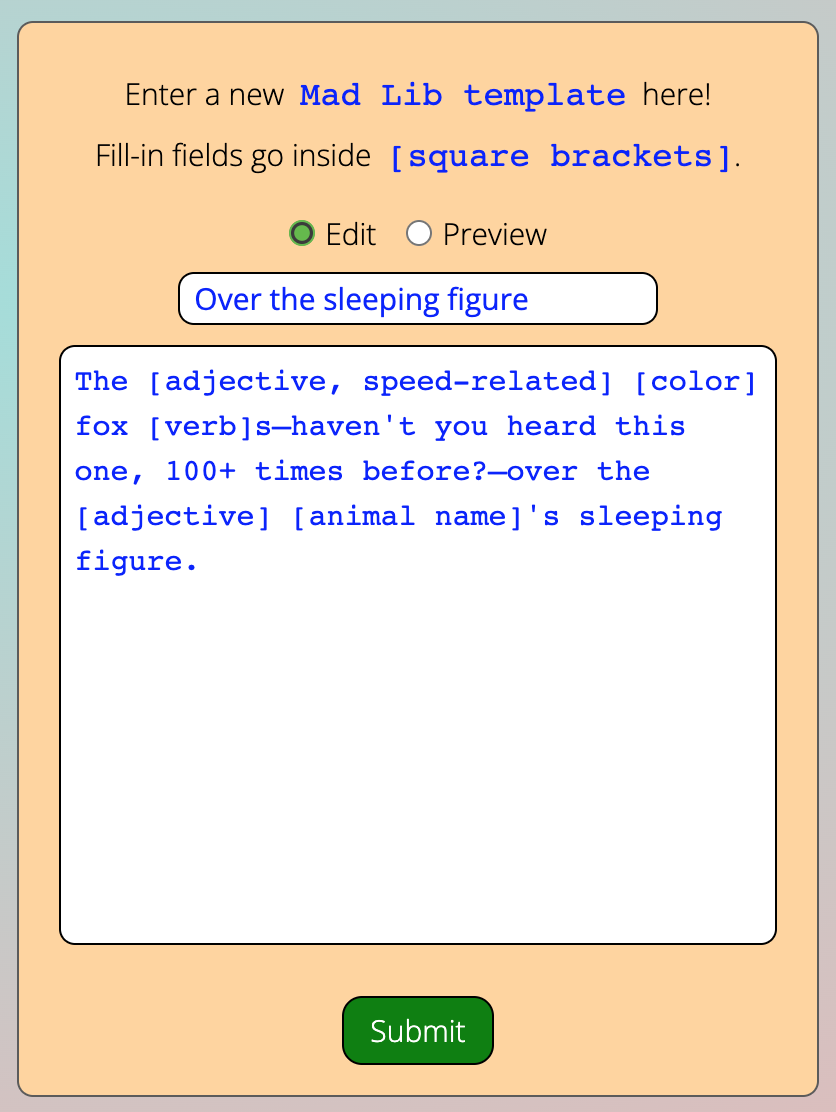
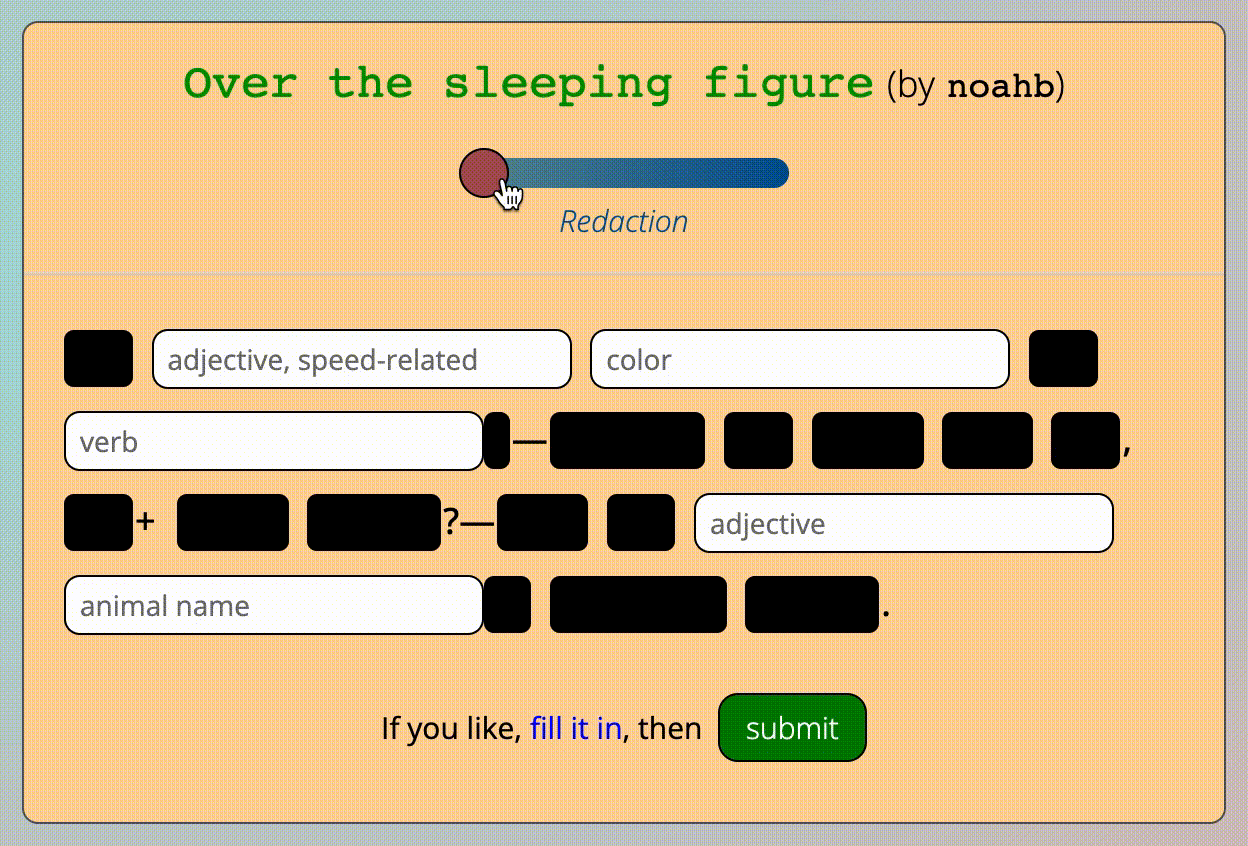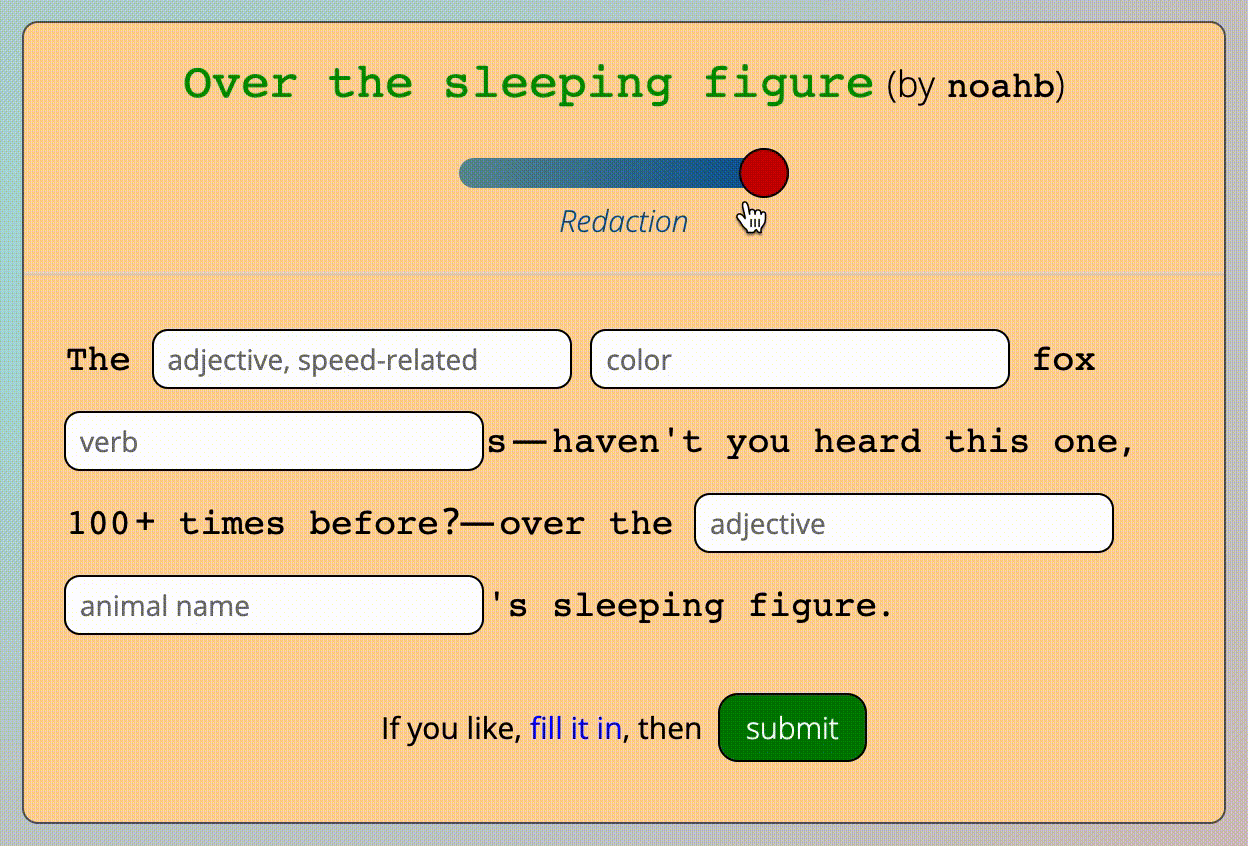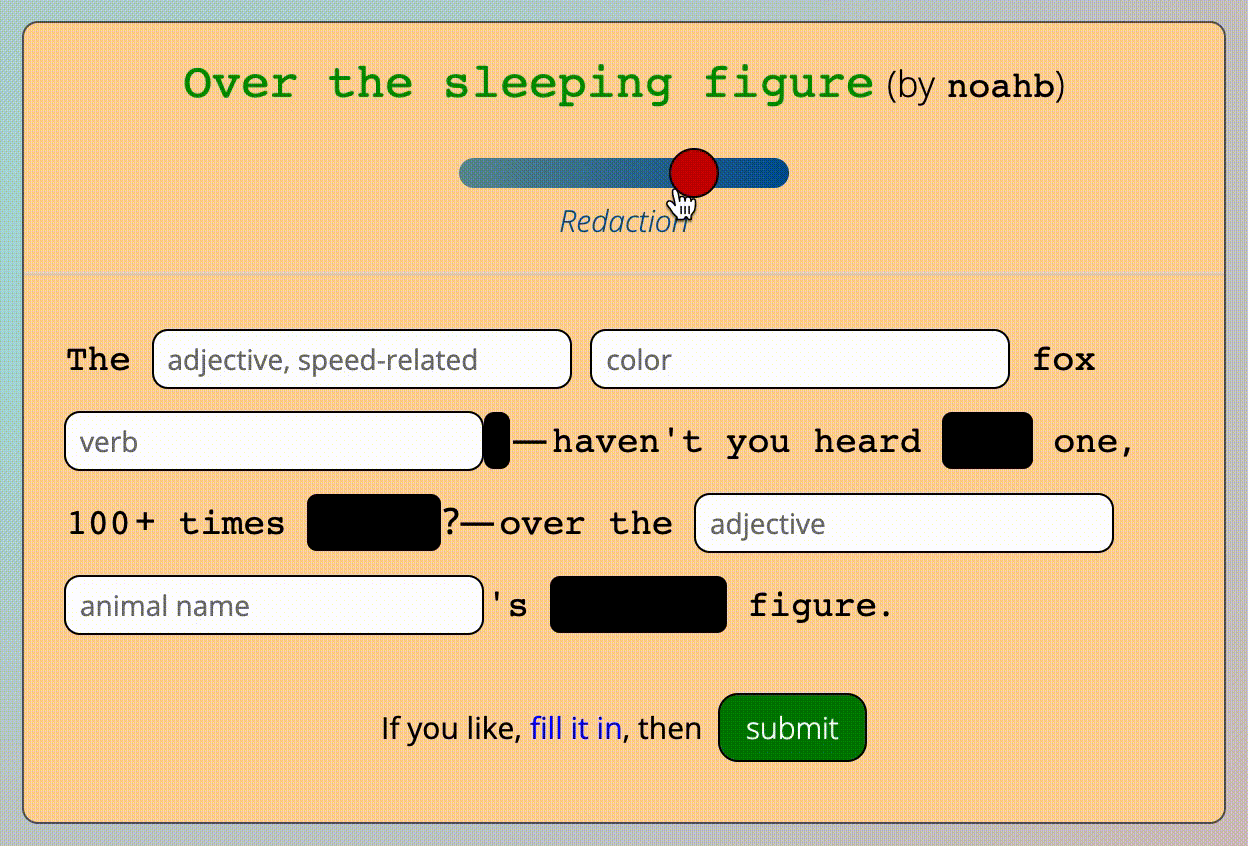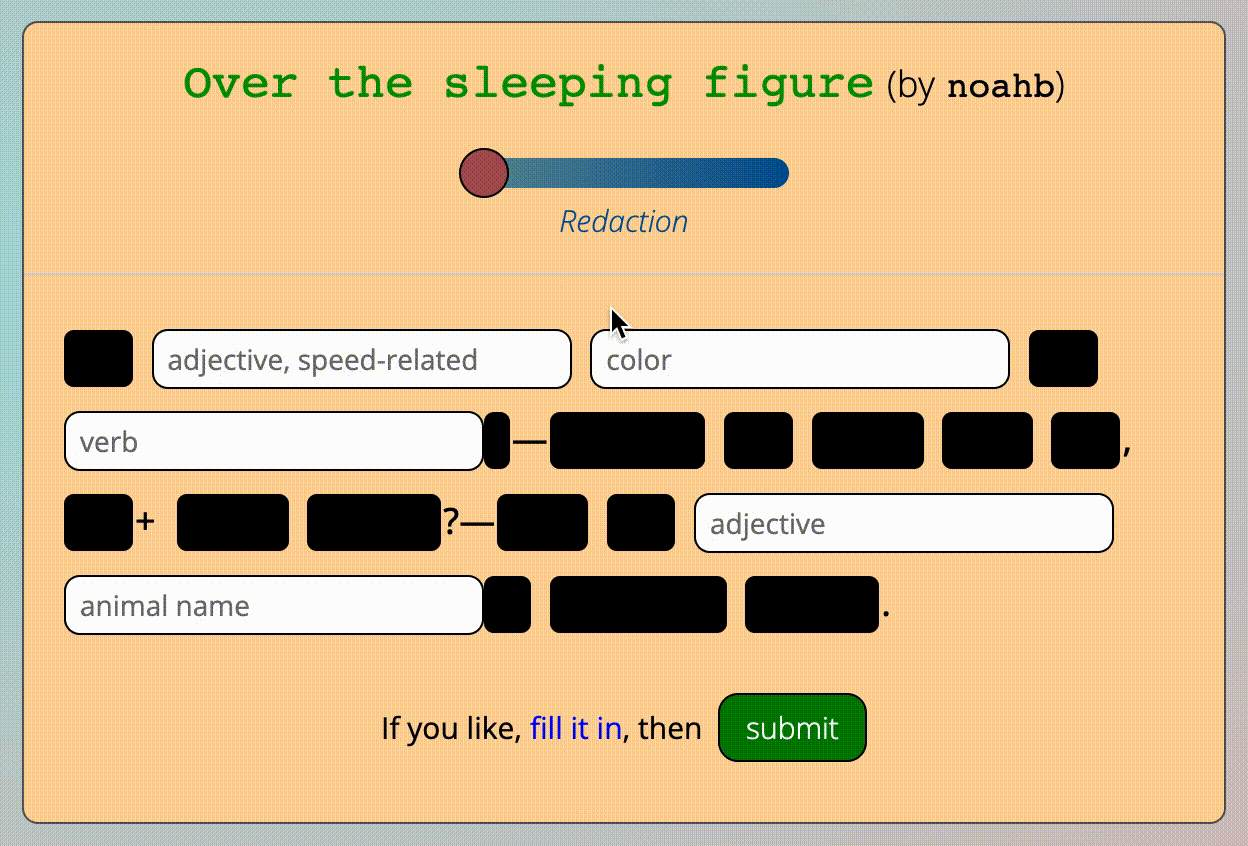
A template constructor string that a user types in and submits might look something like this:
The [adjective, speed-related] [color] fox [verb]s——haven't you heard this one, 100+ times before?——over the [adjective] [animal name]'s sleeping figure.
This example constructor string will be used throughout this explanation.
A constructor is parsed into three separate types of substrings:
- Mutables — After the template is submitted, when other users are filling it in, "mutables" are the fields in which they insert their input. In the constructor string, mutables are the values enclosed by square brackets:
[adjective, speed-related],[color],[verb], etc. They are eventually rendered as HTMLinputelements on the page, with the text inside their square brackets used for theplaceholderattribute. - Static words — These are exactly what they sound like: words that are a hard-and-fast part of the template, the unchanging framework of the Mad Lib. In the constructor string, static words are all the words not enclosed by square brackets:
The,fox,s(following the[verb]mutable),haven't, etc. They are eventually redacted on the page, with gradated unredaction controlled by a slider. - Static punctuations — Like static words, these are part of the unchanging framework of the Mad Lib. However, these are never redacted, are always completely visible at any level of redaction. In the constructor string, static punctuations are all of the non-alphanumeric sequences of punctuation that lie outside square brackets:
——, betweensandhaven't;,, afterone;+, after100;?——, betweenbeforeandover; etc.
Parsing a constructor string into these three types of substrings is achieved by this regex:
/\[.*?\]|[a-z0-9']+|[^a-z0-9'\[\]\s]+|\s+/igI'll give a step-by-step walkthrough of this regex below. In the final section, The rest of the process, I'll give some more context about how this regex fits into the multi-step processing of newly submitted templates.
The logic of the regex is framed by two forwards slashes: /.../.
Following this logic are two flags, ig, which have to do with the overall behavior of the regex:
i— This tells the regex to ignore case.ABCandabcare treated equivalently.g— This tells the regex to match all occurences, rather than just the first occurence.
The logic of the regex is broken into four different match conditions, which parse the string into the three types of substrings described above. These conditions are separated by the OR | operator, which ensures that a string matching any of these OR statements is considered a match and is included in the array of final results.
(Note that OR statements "short-circuit". If a sequence of characters, call it x, is matched to condition #1, then the regex search will move forward to the remaining unmatched characters in the string, evaluating them beginning again with condition #1, then #2, and so on; it will not match or re-match any of the characters in x using match conditions #2, #3 or #4. Generally speaking, this means that the order of OR statements matters. Given the logic of these specific OR statements, their order happens to be of no consequence, but this is nevertheless good to keep in mind.)
The four match conditions are:
\[.*?\]— Matches mutable substrings[a-z0-9']+— Matches static word substrings[^a-z0-9'\[\]\s]+— Matches static punctuation substrings, except for space characters\s+— Matches space character substrings, which fall under the category of static punctuation but are useful to parse out separately
I'll walk through each of these match conditions below, building cumulatively on an understanding of regex syntax along the way.
\[.*?\]This piece of the regex matches mutables, which are any text enclosed by square brackets.
First, the given match must begin with [ and end with ]. Square brackets are used for other purposes in regex syntax, so to actually match a square bracket character requires escaping it with a backslash \. Thus, we have the beginning and end of this piece of the regex: \[...\].
Inside of the square brackets, we want the match to include all types of characters (letters, numbers, punctuations, spaces). . represents "any single character", and * is a quantifier meaning "zero or more characters of such characters".
Lastly, when ? follows a quantifier, it activates something called "lazy mode", which means "match the shortest possible string that satisfies the conditions of the whole regex" (in this case, just this piece of the whole regex). For example, if this were our constructor string…
[Foo] goes for a walk on [Bar] Lane.
…triggering lazy mode ensures that [Foo] and [Bar] are matched. Otherwise, in "greedy mode" (which is the default), the longest possible string is matched, which in this case would be [Foo] goes for a walk on [Bar], the longest string that lies between [ and ] (no matter that there are other square brackets within).
So then, this piece of the regex in total, \[.*?\], translates to: "\[: begin the match with a left square bracket; .*?: then, include zero or more of any character, keeping this as short as possible until the close of this particular match; \]: then, close the match with a right square bracket."
From our example constructor string, the mutables matched would be: [adjective, speed-related], [color], [verb], [adjective], and [animal name].
[a-z0-9']+This piece of the regex matches static words, which are any alphanumeric character sequences that lie outside of square brackets.
The [ and ] in this piece of the regex are not backslash-escaped, which means they represent not square bracket characters but a different type of regex functionality. So-called "bracket notation" means, "Match any of the characters listed between these brackets". For example, [abc] means "Match a or b or c".
There are three match-options sandwiched together inside the brackets: a-z, 0-9, and '.
a-z means, "Match any letter between a and z (i.e. all the letters in the English alphabet)". Recall that the i flag at the end of the whole regex establishes case insensitivity for letters.0-9 means "Match any digit between 0 and 9".
(a-z0-9 could have been represented summarily as \w, but I prefer the readability of the former here.)
' also includes the apostrophe character in static-word matches. The idea here is that, for example, haven't would be treated as a single match / a single static word, rather than haven (static word, redactable) + ' (static punctuation, never redacted) + t (static word, redactable).
(Beyond apostrophes, a case could be made for including other punctuations as part of static words, e.g. hyphens, but I opted against it.)
Lastly, the + after the bracket notation is the regex quantifier for "one or more characters".
So then, this piece of the regex in total, [a-z0-9']+, translates to: "Match one or more characters that are either letters, numbers, or an apostrophe."
From our example constructor string, the static words matched would be: The, fox, s, haven't, you, heard, this, one, 100, times, before, over, the, 's, sleeping, and figure.
[^a-z0-9'\[\]\s]+This piece of the regex matches static punctuations (except space characters), which are any sequences of punctuation that lie outside of square brackets. (\W may appear more compact, but it fails to exclude apostrophes, square brackets, and space characters from this punctuation search.)
Again, we see bracket notation. However, the material between the brackets begins with ^, which triggers what's called an "inverse match". [^abc] means "match any character except a or b or c".
There are six options not-to-match inside the brackets: a-z, 0-9, ', \[, \], and \s. We have seen the first five already: all letters, all digits, an apostrophe, a left square bracket, and a right square bracket.
The sixth option, \s, is what's called a "character class", the lowercase s here describing a whitespace character. (There are several different types of whitespace characters on modern computers, which makes an all-encompassing character class necessary here.)
To close, again we see the + quantifier, meaning "one or more characters".
So then, this piece of the regex in total, [^a-z0-9'\[\]\s]+, translates to: "Match one or more characters that are not one of the following: letters, numbers, an apostrophe, a left square bracket, a right square bracket, or a space character."
From our example constructor string, the non-space static punctuations matched would be: ——, ,, +, ?——, and ..
\s+This final piece of the regex matches sequences of space characters (that lie outside of square brackets), which are static punctuations that are useful to parse out separately from other non-space static punctuations (for reasons given here).
Using the \s character class and + quantifier that we have seen before, this piece of the regex translates to: "Match one or more space characters."
const sample = "The [adjective, speed-related] [color] fox [verb]s——haven't you heard this one, 100+ times before?——over the [adjective] [animal name]'s sleeping figure.";
console.log(sample.match(/\[.*?\]|[a-z0-9']+|[^a-z0-9'\[\]\s]+|\s+/ig));Working with our sample constructor string, the results of this regex match would be this array:
[
'The',
// static word
' ',
// static punctuation (space)
'[adjective, speed-related]',
// mutable
' ',
// static punctuation (space)
'[color]',
// mutable
' ',
// static punctuation (space)
'fox',
// static word
' ',
// static punctuation (space)
'[verb]',
// mutable
's',
// static word
'——',
// static punctuation (non-space)
"haven't",
// static word
' ',
// static punctuation (space)
'you',
// static word
' ',
// static punctuation (space)
'heard',
// static word
' ',
// static punctuation (space)
'this',
// static word
' ',
// static punctuation (space)
'one',
// static word
',',
// static punctuation (non-space)
' ',
// static punctuation (space)
'100',
// static word
'+',
// static punctuation (non-space)
' ',
// static punctuation (space)
'times',
// static word
' ',
// static punctuation (space)
'before',
// static word
'?——',
// static punctuation (non-space)
'over',
// static word
' ',
// static punctuation (space)
'the',
// static word
' ',
// static punctuation (space)
'[adjective]',
// mutable
' ',
// static punctuation (space)
'[animal name]',
// mutable
"'s",
// static word
' ',
// static punctuation (space)
'sleeping',
// static word
' ',
// static punctuation (space)
'figure',
// static word
'.'
// static punctuation (non-space)
]This array is later reassembled on the front-end as a viewable template, its elements fitting together like puzzle pieces.
Processing newly submitted template constructor strings as a whole follows this procedure (loosely outlined here; see template-model.js, or the whole Mad Libs repo, for more detail):
- Check to ensure that square brackets are properly formatted. A left square bracket
[must always be followed by a right square bracket], and no nesting is allowed. - Parse the string using the regex described here.
- Loop through the array of results, making each parsed element an object with properties set according to its type:
- Mutables:
{ isStatic: false, label: 'The text of the mutable, with beginning and ending square brackets removed and the inner material trimmed', // (if no inner material is supplied, defaults to 'word') mutableIndex: (integer) // an index specifically for counting mutable words in the template }
- Static words:
{ isStatic: true, word: 'staticWordText', staticIndex: (integer) // an index specifically for counting static words in the template }
- Static punctuations:
{ isStatic: true, word: 'sequence of punctuations, or a single space', // User validation: If space-sequences are more than one space long, they are reduced down to a single space——THIS is why spaces are parsed out separately from other punctuation marks staticIndex: null // Punctuations are omitted from static indexing, which is useful for making them always visible / never redacted }
- Mutables:
- Generate a
redaction_orderarray with the numbers0,1,2, and3in a random order. For example, let's use[2, 0, 1, 3].
Templates begin with static words fully redacted, and there are four levels of progressive unredaction (controlled by an on-screen slider). Using the elements of ourredaction_orderarray, theelementValue + 1th out of every four static words becomes visible.
At Level 1: The first element is[2]→ 2 + 1 = 3 → the 3rd out of every four static words becomes visible.
At Level 2:[2, 0]→ the 3rd and 1st out of every four static words become visible.
At Level 3:[2, 0, 1]→ the 3rd, 1st, and 2nd out of every four static words become visible.
At Level 4, we have no more redaction / complete visibility:[2, 0, 1, 3]→ the 3rd, 1st, 2nd, and 4th out of every four static words—that is, all static words—become visible. - Store all this data in the database, making it available for future API calls and front-end rendering (via Handlebars / HTML / CSS / JS). The Template class includes a
redactContentmethod that returns a given Template object with its content redacted to the selected level (0–4), in which theredaction_orderarray works in tandem with each word's type (mutable / static word / static punctuation) to redact the appropriate words.
The template maker
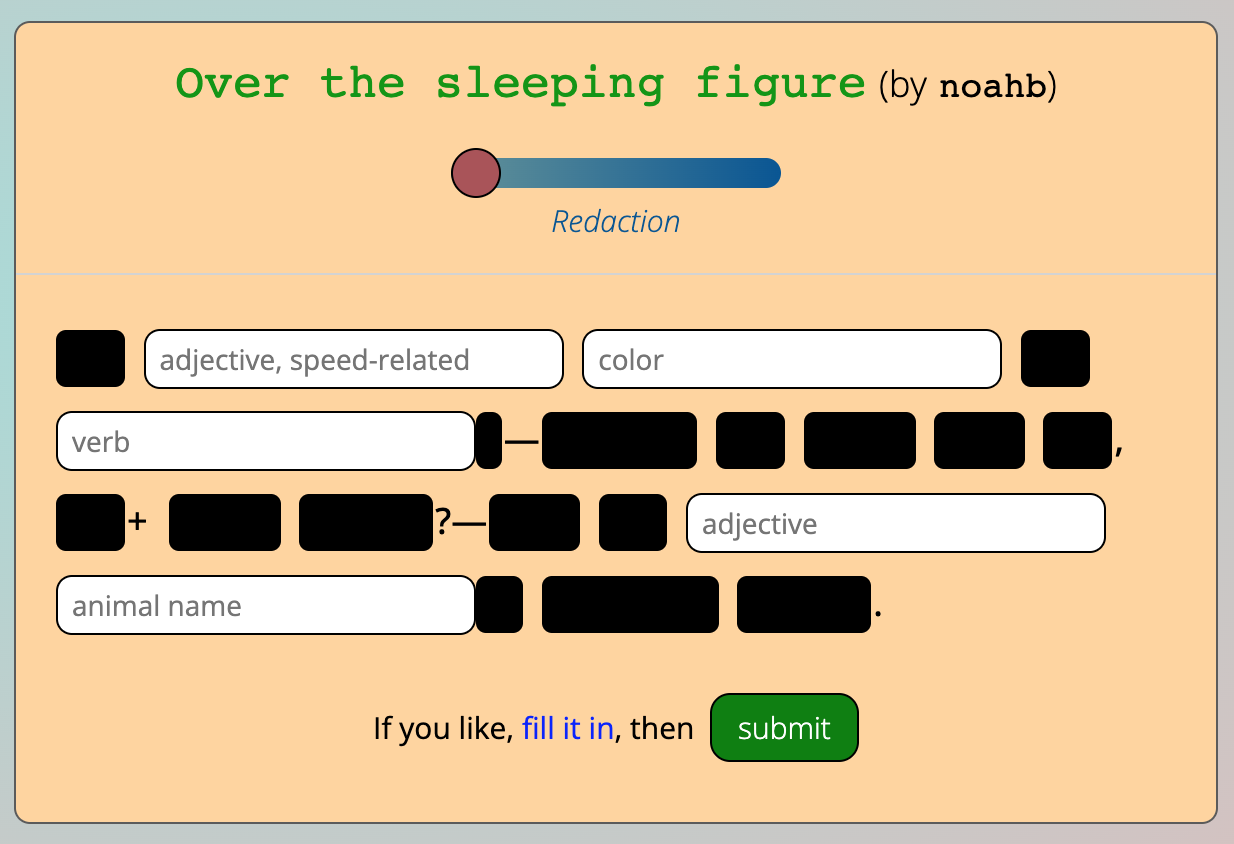
The submitted template, fully redacted
Manipulating the redaction slider
I'm a professional musician and coder living in Brooklyn, NY. You can find me at noah35becker on GitHub, or contact me at noahbeckercoding@gmail.com.