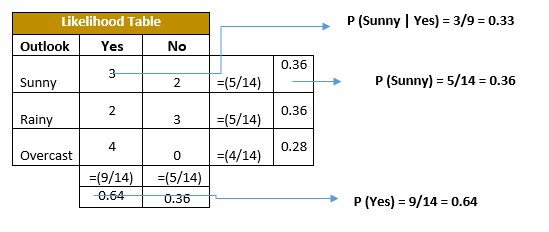
|
let all_features = ["sex_male", "passengerid", "fare", "age", "sex_female", "pclass", "parch", "sibsp", "cabin_missing", "embarked_C", "embarked_S", "cabin_E25", "cabin_C22 C26", "cabin_E24", "embarked_Q", "cabin_B96 B98", "cabin_E12", "cabin_C106", "cabin_C104", "cabin_D45", "cabin_E17", "cabin_E10", "cabin_C52", "cabin_A23", "cabin_B20", "cabin_E8", "cabin_C126", "cabin_E77", "cabin_E121", "cabin_D35", "cabin_D19", "cabin_C148", "cabin_C92", "cabin_C86", "cabin_B49", "cabin_B50", "cabin_C70", "cabin_A26", "cabin_F2", "cabin_C47", "cabin_B82 B84", "cabin_B41", "cabin_E50", "cabin_D49", "cabin_A10", "cabin_A34", "cabin_C111", "cabin_G6", "cabin_A20", "cabin_D33", "cabin_E101", "cabin_B37", "cabin_C124", "cabin_C65", "cabin_D48", "cabin_B71", "cabin_B51 B53 B55", "cabin_C68", "cabin_B101", "cabin_C82", "cabin_C118", "cabin_F33", "cabin_D", "cabin_B77", "cabin_C2", "cabin_B5", "cabin_C23 C25 C27", "cabin_C46", "cabin_B18", "cabin_B57 B59 B63 B66", "cabin_D30", "cabin_B22", "cabin_E67", "cabin_C91", "cabin_E44", |