
Go is an ancient board game that has been played for more than 2,500 years, and is considered the be the oldest game continuously played to the present day. It is an abstract strategy game that most scholars contend was adapted from tribal Chinese warloards and generals placing stones on the ground to plan and prepare for attacks.
The game is played on a board with numerous points. The professional Go board being 19x19 points but learning boards going down to as small as 9x9, and the original Go board was 17x17 points but was later was standardized to the 19x19 moden board sometime around the 5th century CE. The game is played by placing pieces on these points and attempting to gain territory by chaining pieces together and capturing your opponents pieces. The game is played until both players can find no beneficial moves and both pass. Yet, despite these simple rules Go is considered one of the most complex board games available. It is more complex than chess by having a larger board, a grander scope and longer games, as well as generally having significanly more alternative moves. The approximate number of Go moves has been calculated at 2.1 × 10^170.
Games like Go and chess have a benefit that make them perfect candidates for machine learning. These games are perfect information games in which a player knows all game states and information that can be known in the current game states, therefore all positions may be analyzed and scored. The issue with solving large games is that you must search breadth and depth of the game for move optimization, which in a smaller game is simple, but in a game such as go that has more moves than there are atoms in the currently observable universe it provides an interesting challenge. These searches implement recursive functions, and a recursive function is a complex idea that boils down to the concept of running an action that references itself until you end up at a predetermined base state. Unfortunately, these kinds of exhaustive searches are impossible in Go as the universe would die of heat death before the first move was processed.
However, within the last 20 years computer scientists have begun to develop and expand upon techniques that can provide superhuman levels of play in games like backgammon or checkers, but only weak amateur-like performances in Go - once again showing the complexity of the game. These advances have come about through the utilization of a Monte Carlo search tree. A MCST is an isea tha tuses search trees based on random sampling to provide results for problems. The idea behind the Monte Carlo Method has been around since the 1940's for use in solving difficult or near impossible deterministic problems. In essence the Monte Carlo search tree works simply by analyzing the current state of the game, playing both sides through random moves to the end of the game, and then weighting moves based on the outcomes of these simulations known as playouts or rollouts. These moves are placed in the node of a search tree, which is a directed acyclic graph, and the results are backpropogated through the search tree to produce node weights for move scores.
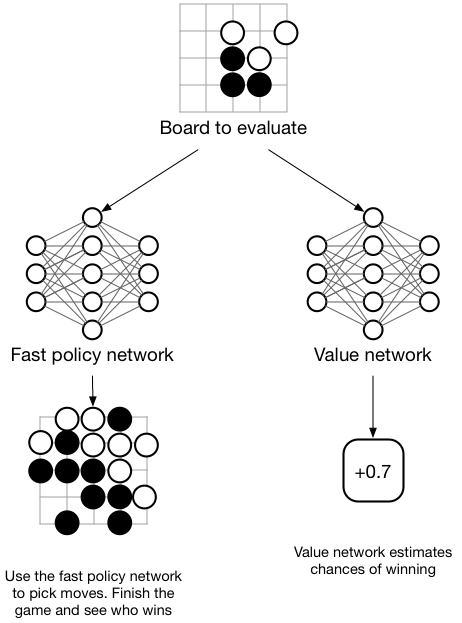
AlphaGo utilized a machine learning pipeline that made use of both supervised learning and reinforcement learning. The supervised learning layers trained a network on moves and board positions that were compiled from an online Go platform to form the basis of the policy network, The value network was trained by successive games of self-play that were based on the policy gradient generated by the supervised learning policy network. Policy gradients were created by sampling action pairs from a MCST and moves from experts on which stochastic gradient ascent are applied to maximize the liklihood that a human move would be selected. This policy gradient is used by the reinforcement learning value network to determine the optimal move based on current game state.
Finally, we evaluated the distributed version of AlphaGo against Fan Hui, a professional 2 dan, and the winner of the 2013, 2014 and 2015 European Go championships. Over 5–9 October 2015 AlphaGo and Fan Hui competed in a formal five-game match. AlphaGo won the match 5 games to 0 (Fig. 6 and Extended Data Table 1). This is the first time that a computer Go program has defeated a human professional player, without handicap, in the full game of Go—a feat that was previously believed to be at least a decade away
Mastering the game of Go with deep neural networks and tree search
The paper outlines some other very interestin g results however. Such as the fact that a distributed version of the AlphaGo network would win 77% of all games played against a single machine version of AlphaGo, showing that distributed computing provides a significantlu better ability to process and therefore utilize the search trees. The match AlphaGo played against Hui evaluated thousands of moves less than what Deep Blue evaluated in it famous game against Kasparov. It did this by selecting moves in a more intelligent way by using the Policy and Value networks. Deep Blue also used a custom evaluation function while AlphaGo used standard, general purpose supervised and reinforcement machine learning. These factors and the consideration of Go as a significantly more complex game provides proof that AlphaGo is the superior deep learning intelligence in the game playing field.