Created
October 21, 2019 04:00
-
-
Save dg1223/1417a7e810a1e78a474177e5544e4ff8 to your computer and use it in GitHub Desktop.
Our coding workspace
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # -*- coding: utf-8 -*- | |
| """DEDOMENA.ipynb | |
| Automatically generated by Colaboratory. | |
| Original file is located at | |
| https://colab.research.google.com/drive/1UGwNluyb9CBl48FRQ9ioV2O6FbvSYGnc | |
| # **FINAL_SUBMISSION** | |
| **THE CHALLANGE** | |
| Help find ways to improve the performance of machine learning and predictive models by filling in gaps in the datasets prior to model training. | |
| ANATOMY OF THE CHALLANGE: | |
| DO WHAT? | |
| Improve performance of Machine Learning (ML) models by collecting a complete and continuous sensor data stream. | |
| WHY DID IT HAPPEN? | |
| * Sensor issues or signal noise due to experimental environment/setup | |
| * Corrupted of data | |
| * Loss of data during transmission (also due to limited bandwidth of transmission) | |
| * Interference | |
| * Limited amount of power for data collection and transmission | |
| WHAT IT DOES? | |
| * Limits the ability to train accurate ML models to predict features/characteristics in data, which in turn renders the data "useless" | |
| * Hinders the collection of good-quality data silos | |
| HOW TO SOLVE/OBJECTIVE? | |
| * By "filling in" the missing datapoints in the datasets | |
| * By "generating" the missing datapoints in the datasets | |
| * By eliminating/removing the noisy/corrupted information that is embedded in individual datapoints | |
| DO IT WHEN? | |
| * Prior to training, i.e. during data cleaning and preprocessing. | |
| We started by investigating the reasons behind data loss when the data is acquired through a sensor or sensor array. In addition, we also started doing research finding the reasons behind the loss. | |
| Our research concluded that data loss in any dataset does not only occur due to missing data (be it discreet or continuous/timeseries) but also due to incomplete or corrupted or noisy collection of these data that are acquired by the sensors due to the reasons mentioned above. | |
| --- | |
| HYPOTHESIS: | |
| We propose an end-to-end Machine learning pipeline to -fill in the missing data using Generative modeling which involves using a model to generate new examples that plausibly come from an existing distribution of samples. | |
| Stacked Denoising Autoencoder for when the sensor data is corrupted or there is a bit of noise in it, we call this type of data noisy data. | |
| To obtain proper information about the data, we want Denoising. | |
| We define our autoencoder to remove (if not all)most of the noise our data. | |
| Transforms the input into a lower dimensional representation, and a decoder, which tries to reconstruct the original input from the lower dimensional representation. Therefore, these models present some some sort of “bottle neck” in the middle that forces the network to learn how to compress the data in a lower dimensional space. When training these algorithms, the objective is to be able to reconstruct the original input with the minimum amount of information loss. Once the model is trained, we can compress data at will by only using the encoder component of the autoencoder. | |
| --- | |
| **(A)** | |
| DETAILS: | |
| One model is called the “generator” or “generative network” model that learns to generate new plausible samples. The other model is called the “discriminator” or “discriminative network” and learns to differentiate generated examples from real examples. | |
| The two models are set up in a contest or a game (in a game theory sense) where the generator model seeks to fool the discriminator model, and the discriminator is provided with both examples of real and generated samples. | |
| After training, the generative model can then be used to create new plausible samples on demand. | |
| ---- | |
| **(B)** | |
| An autoencoder is a neural network used for dimensionality reduction; that is, for feature selection and extraction. Autoencoders with more hidden layers than inputs run the risk of learning the identity function – where the output simply equals the input – thereby becoming useless. | |
| Denoising autoencoders are an extension of the basic autoencoder, and represent a stochastic version of it. Denoising autoencoders attempt to address identity-function risk by randomly corrupting input (i.e. introducing noise) that the autoencoder must then reconstruct, or denoise. | |
| Stacked Denoising Autoencoder | |
| A stacked denoising autoencoder is simply many denoising autoencoders strung together. | |
| A key function of SDAs, and deep learning more generally, is unsupervised pre-training, layer by layer, as input is fed through. Once each layer is pre-trained to conduct feature selection and extraction on the input from the preceding layer, a second stage of supervised fine-tuning can follow. | |
| A word on stochastic corruption in SDAs: Denoising autoencoders shuffle data around and learn about that data by attempting to reconstruct it. The act of shuffling is the noise, and the job of the network is to recognize the features within the noise that will allow it to classify the input. When a network is being trained, it generates a model, and measures the distance between that model and the benchmark through a loss function. Its attempts to minimize the loss function involve resampling the shuffled inputs and re-reconstructing the data, until it finds those inputs which bring its model closest to what it has been told is true. | |
| --- | |
| **(C)** | |
| Encoder network: It translates the original high-dimension input into the latent low-dimensional code. The input size is larger than the output size. | |
| Decoder network: The decoder network recovers the data from the code, likely with larger and larger output layers. | |
| The encoder network essentially accomplishes the dimensionality reduction, just like how we would use Principal Component Analysis (PCA) or Matrix Factorization (MF) for. In addition, the autoencoder is explicitly optimized for the data reconstruction from the code. | |
| --- | |
| **(D)** | |
| Disentangled Variational autoencoders | |
| The idea of Variational Autoencoder is actually less similar to all the autoencoder models above, but deeply rooted in the methods of variational bayesian and graphical model. | |
| Instead of mapping the input into a fixed vector, we want to map it into a distribution. | |
| If each variable in the inferred latent representation is only sensitive to one single generative factor and relatively invariant to other factors, we will say this representation is disentangled or factorized. One benefit that often comes with disentangled representation is good interpretability and easy generalization to a variety of tasks. | |
| For example, a model trained on photos of human faces might capture the gentle, skin color, hair color, hair length, emotion, whether wearing a pair of glasses and many other relatively independent factors in separate dimensions. Such a disentangled representation is very beneficial to facial image generation. | |
| https://lilianweng.github.io/lil-log/2018/08/12/from-autoencoder-to-beta-vae.html#beta-vae | |
| # **Download NASA Satellite Images of the Earth (NASA MODIS)** | |
| This function can download an entire history of any NASA image dataset that follow the GIBS RESTful API pattern of calls | |
| **Sample call**: https://gibs.earthdata.nasa.gov/wmts/epsg4326/best/MODIS_Terra_CorrectedReflectance_TrueColor/default/2012-07-09/250m/6/13/36.jpg | |
| **Pattern**: https://gibs.earthdata.nasa.gov/wmts/epsg{EPSG:Code}/best/{ProductName}/default/{Time}/{TileMatrixSet}/{ZoomLevel}/{TileRow}/{TileCol}.png | |
| **GIBS API webpage**: https://wiki.earthdata.nasa.gov/display/GIBS/GIBS+API+for+Developers | |
| """ | |
| import requests | |
| import shutil | |
| import os | |
| """ | |
| This function can download an entire history of any NASA image dataset that follow the GIBS RESTful API pattern of calls | |
| Sample call: https://gibs.earthdata.nasa.gov/wmts/epsg4326/best/MODIS_Terra_CorrectedReflectance_TrueColor/default/2012-07-09/250m/6/13/36.jpg | |
| Pattern: https://gibs.earthdata.nasa.gov/wmts/epsg{EPSG:Code}/best/{ProductName}/default/{Time}/{TileMatrixSet}/{ZoomLevel}/{TileRow}/{TileCol}.png | |
| """ | |
| def download_MODIS_image(num_images, year, month, day, max_day, max_month, end_date): | |
| # input parameters | |
| # num_images: number of images to download (for this URL, don't go over 80) | |
| # year: year when image was taken; e.g. 2019 | |
| # month: month when image was taken; e.g. 7 | |
| # day: day when image was taken; e.g. 12 | |
| # max_day: day of each month on which you want to stop and move on to the next month; e.g. 30 | |
| # max_month: month of each year on which you want to stop and move on to the next year; e.g. 12 | |
| # end_date: a data (string) on which you want to break the loop; e.g. ''2019-10-20 | |
| if month < 10 and day < 10: | |
| date = str(year) + '-0' + str(month) + '-0' + str(day) | |
| elif month < 10 and day >= 10: | |
| date = str(year) + '-0' + str(month) + '-' + str(day) | |
| elif month >= 10 and day < 10: | |
| date = str(year) + '-' + str(month) + '-0' + str(day) | |
| else: | |
| date = str(year) + '-' + str(month) + '-' + str(day) | |
| #max_day = 30 # not going to take the data from 31st day of any month (future imoprovement) | |
| #max_month = 12 | |
| image_num = 0 | |
| for m in range(month, max_month+1): | |
| for d in range(day, max_day+1): | |
| for i in range(num_images): | |
| if date == end_date: | |
| print('end date','end_date', ' reached') | |
| break | |
| image_id = i | |
| #image_num = str(img_counter) | |
| url = 'https://gibs.earthdata.nasa.gov/wmts/epsg4326/best/MODIS_Terra_CorrectedReflectance_TrueColor/default/' + date + '/250m/6/13/' + str(image_id) + '.jpg' | |
| #Save file in local hard drive | |
| filepath = 'D:\SpaceApps2019\Chasers_of_lost_data\downloads\images_modis_nasa\\' | |
| filename = 'nasa_modis_image_' + date + '_' + str(image_num) + '.jpg' | |
| full_filepath = filepath + filename | |
| # Open the url image, set stream to True, this will return the stream content. | |
| response = requests.get(url, stream=True) | |
| # Open a local file with wb ( write binary ) permission. | |
| local_file = open(full_filepath, 'wb') | |
| # Set decode_content value to True, otherwise the downloaded image file's size will be zero. | |
| response.raw.decode_content = True | |
| # Copy the response stream raw data to local image file. | |
| shutil.copyfileobj(response.raw, local_file) | |
| # Remove the image url response object. | |
| local_file.close() | |
| del response | |
| filesize = os.path.getsize(full_filepath) | |
| if filesize > 428: | |
| print('image #', 'image_num', 'downloaded') | |
| else: | |
| print('image #','image_num', 'is a zero sized file --> invalid image') | |
| image_num += 1 | |
| #### MAIN #### | |
| # Loop over dates in a month to download in larger batches | |
| #num_images = 80 | |
| #day = 1 | |
| #month = 7 | |
| #year = 2019 | |
| #max_day = 30 | |
| #max_month = 9 | |
| #end_date = '2019-09-15' | |
| #download_MODIS_image(num_images, year, month, day, max_day, max_month, end_date) | |
| """# **Image Completion with Deep Learning in TensorFlow** | |
| Content-aware fill is a powerful tool designers and photographers use to fill in unwanted or missing parts of images. Image completion and inpainting are closely related technologies used to fill in missing or corrupted parts of images. There are many ways to do content-aware fill, image completion, and inpainting. | |
| We use Semantic Image Inpainting with Deep Generative Models | |
| "Semantic image inpainting is a challenging task where large missing regions have to be filled based on the available visual data. Existing methods which extract information from only a single image generally produce unsatisfactory results due to the lack of high level context. In this paper, we propose a novel method for semantic image inpainting, which generates the missing content by conditioning on the available data. Given a trained generative model, we search for the closest encoding of the corrupted image in the latent image manifold using our context and prior losses. This encoding is then passed through the generative model to infer the missing content. In our method, inference is possible irrespective of how the missing content is structured, while the state-of-the-art learning based method requires specific information about the holes in the training phase. Experiments show that the method successfully predicts information in large missing regions and achieves pixel-level photorealism, significantly outperforming the state-of-the-art methods." | |
| --- | |
| --- | |
| --- | |
| --- | |
| --- | |
| --- | |
| --- | |
| --- | |
| --- | |
| --- | |
| # **Proof of Concept #1** | |
| # **Filling up missing portions of NASA earth images with ** | |
| # **# Algorithm: Deep Convolutional Generative Adversarial Network (DCGAN)** | |
| This is a modified version of a DCGAN tutorial that was originally developed to generate fake MNIST images. **We have modified the code to take a single, corrupted NASA earth image as input and repair it.** | |
| The code is written using the [Keras Sequential API](https://www.tensorflow.org/guide/keras) with a `tf.GradientTape` training loop. | |
| ## What are GANs? | |
| [Generative Adversarial Networks](https://arxiv.org/abs/1406.2661) (GANs) are one of the most interesting ideas in computer science today. Two models are trained simultaneously by an adversarial process. A *generator* ("the artist") learns to create images that look real, while a *discriminator* ("the art critic") learns to tell real images apart from fakes. | |
| 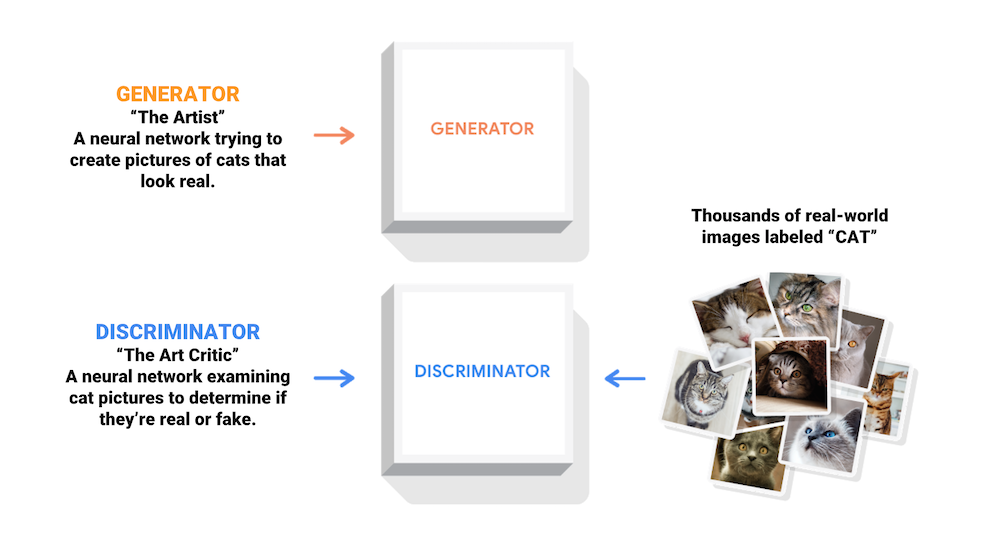 | |
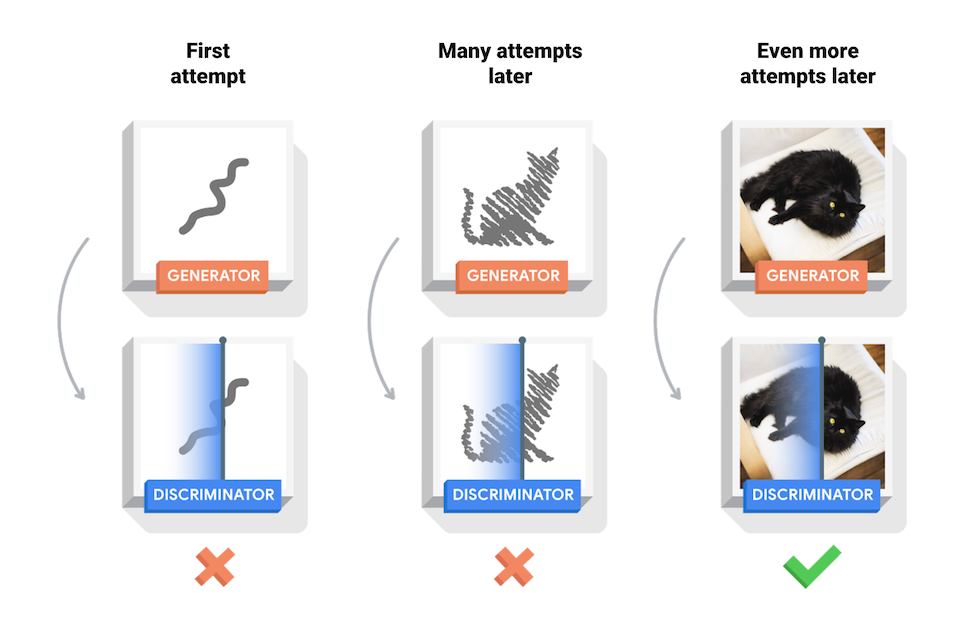
| During training, the *generator* progressively becomes better at creating images that look real, while the *discriminator* becomes better at telling them apart. The process reaches equilibrium when the *discriminator* can no longer distinguish real images from fakes. | |
|  | |
| ### Import TensorFlow and other libraries | |
| """ | |
| from __future__ import absolute_import, division, print_function, unicode_literals | |
| # Commented out IPython magic to ensure Python compatibility. | |
| try: | |
| # %tensorflow_version only exists in Colab. | |
| # %tensorflow_version 2.x | |
| except Exception: | |
| pass | |
| import tensorflow as tf | |
| tf.__version__ | |
| # To generate GIFs | |
| !pip install imageio | |
| import glob | |
| import imageio | |
| import matplotlib.pyplot as plt | |
| import numpy as np | |
| import os | |
| import PIL | |
| from tensorflow.keras import layers | |
| import time | |
| from IPython import display | |
| """### Load and prepare the dataset | |
| You will use the MNIST dataset to train the generator and the discriminator. The generator will generate handwritten digits resembling the MNIST data. | |
| """ | |
| (train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data() | |
| train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32') | |
| train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1] | |
| BUFFER_SIZE = 60000 | |
| BATCH_SIZE = 256 | |
| # Batch and shuffle the data | |
| train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE) | |
| """## Create the models | |
| Both the generator and discriminator are defined using the [Keras Sequential API](https://www.tensorflow.org/guide/keras#sequential_model). | |
| ### The Generator | |
| The generator uses `tf.keras.layers.Conv2DTranspose` (upsampling) layers to produce an image from a seed (random noise). Start with a `Dense` layer that takes this seed as input, then upsample several times until you reach the desired image size of 28x28x1. Notice the `tf.keras.layers.LeakyReLU` activation for each layer, except the output layer which uses tanh. | |
| """ | |
| def make_generator_model(): | |
| model = tf.keras.Sequential() | |
| model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,))) | |
| model.add(layers.BatchNormalization()) | |
| model.add(layers.LeakyReLU()) | |
| model.add(layers.Reshape((7, 7, 256))) | |
| assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size | |
| model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)) | |
| assert model.output_shape == (None, 7, 7, 128) | |
| model.add(layers.BatchNormalization()) | |
| model.add(layers.LeakyReLU()) | |
| model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)) | |
| assert model.output_shape == (None, 14, 14, 64) | |
| model.add(layers.BatchNormalization()) | |
| model.add(layers.LeakyReLU()) | |
| model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')) | |
| assert model.output_shape == (None, 28, 28, 1) | |
| return model | |
| """Use the (as yet untrained) generator to create an image.""" | |
| generator = make_generator_model() | |
| noise = tf.random.normal([1, 100]) | |
| generated_image = generator(noise, training=False) | |
| plt.imshow(generated_image[0, :, :, 0], cmap='gray') | |
| """### The Discriminator | |
| The discriminator is a CNN-based image classifier. | |
| """ | |
| def make_discriminator_model(): | |
| model = tf.keras.Sequential() | |
| model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', | |
| input_shape=[28, 28, 1])) | |
| model.add(layers.LeakyReLU()) | |
| model.add(layers.Dropout(0.3)) | |
| model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same')) | |
| model.add(layers.LeakyReLU()) | |
| model.add(layers.Dropout(0.3)) | |
| model.add(layers.Flatten()) | |
| model.add(layers.Dense(1)) | |
| return model | |
| """Use the (as yet untrained) discriminator to classify the generated images as real or fake. The model will be trained to output positive values for real images, and negative values for fake images.""" | |
| discriminator = make_discriminator_model() | |
| decision = discriminator(generated_image) | |
| print (decision) | |
| """## Define the loss and optimizers | |
| Define loss functions and optimizers for both models. | |
| """ | |
| # This method returns a helper function to compute cross entropy loss | |
| cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True) | |
| """### Discriminator loss | |
| This method quantifies how well the discriminator is able to distinguish real images from fakes. It compares the discriminator's predictions on real images to an array of 1s, and the discriminator's predictions on fake (generated) images to an array of 0s. | |
| """ | |
| def discriminator_loss(real_output, fake_output): | |
| real_loss = cross_entropy(tf.ones_like(real_output), real_output) | |
| fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output) | |
| total_loss = real_loss + fake_loss | |
| return total_loss | |
| """### Generator loss | |
| The generator's loss quantifies how well it was able to trick the discriminator. Intuitively, if the generator is performing well, the discriminator will classify the fake images as real (or 1). Here, we will compare the discriminators decisions on the generated images to an array of 1s. | |
| """ | |
| def generator_loss(fake_output): | |
| return cross_entropy(tf.ones_like(fake_output), fake_output) | |
| """The discriminator and the generator optimizers are different since we will train two networks separately.""" | |
| generator_optimizer = tf.keras.optimizers.Adam(1e-4) | |
| discriminator_optimizer = tf.keras.optimizers.Adam(1e-4) | |
| """### Save checkpoints | |
| This notebook also demonstrates how to save and restore models, which can be helpful in case a long running training task is interrupted. | |
| """ | |
| checkpoint_dir = './training_checkpoints' | |
| checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt") | |
| checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer, | |
| discriminator_optimizer=discriminator_optimizer, | |
| generator=generator, | |
| discriminator=discriminator) | |
| """## Define the training loop""" | |
| EPOCHS = 50 | |
| noise_dim = 100 | |
| num_examples_to_generate = 16 | |
| # We will reuse this seed overtime (so it's easier) | |
| # to visualize progress in the animated GIF) | |
| seed = tf.random.normal([num_examples_to_generate, noise_dim]) | |
| """The training loop begins with generator receiving a random seed as input. That seed is used to produce an image. The discriminator is then used to classify real images (drawn from the training set) and fakes images (produced by the generator). The loss is calculated for each of these models, and the gradients are used to update the generator and discriminator.""" | |
| # Notice the use of `tf.function` | |
| # This annotation causes the function to be "compiled". | |
| @tf.function | |
| def train_step(images): | |
| noise = tf.random.normal([BATCH_SIZE, noise_dim]) | |
| with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: | |
| generated_images = generator(noise, training=True) | |
| real_output = discriminator(images, training=True) | |
| fake_output = discriminator(generated_images, training=True) | |
| gen_loss = generator_loss(fake_output) | |
| disc_loss = discriminator_loss(real_output, fake_output) | |
| gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables) | |
| gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables) | |
| generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables)) | |
| discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables)) | |
| def train(dataset, epochs): | |
| for epoch in range(epochs): | |
| start = time.time() | |
| for image_batch in dataset: | |
| train_step(image_batch) | |
| # Produce images for the GIF as we go | |
| display.clear_output(wait=True) | |
| generate_and_save_images(generator, | |
| epoch + 1, | |
| seed) | |
| # Save the model every 15 epochs | |
| if (epoch + 1) % 15 == 0: | |
| checkpoint.save(file_prefix = checkpoint_prefix) | |
| print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start)) | |
| # Generate after the final epoch | |
| display.clear_output(wait=True) | |
| generate_and_save_images(generator, | |
| epochs, | |
| seed) | |
| """**Generate and save images**""" | |
| def generate_and_save_images(model, epoch, test_input): | |
| # Notice `training` is set to False. | |
| # This is so all layers run in inference mode (batchnorm). | |
| predictions = model(test_input, training=False) | |
| fig = plt.figure(figsize=(4,4)) | |
| for i in range(predictions.shape[0]): | |
| plt.subplot(4, 4, i+1) | |
| plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray') | |
| plt.axis('off') | |
| plt.savefig('image_at_epoch_{:04d}.png'.format(epoch)) | |
| plt.show() | |
| """## Train the model | |
| Call the `train()` method defined above to train the generator and discriminator simultaneously. Note, training GANs can be tricky. It's important that the generator and discriminator do not overpower each other (e.g., that they train at a similar rate). | |
| At the beginning of the training, the generated images look like random noise. As training progresses, the generated digits will look increasingly real. After about 50 epochs, they resemble MNIST digits. This may take about one minute / epoch with the default settings on Colab. | |
| """ | |
| # Commented out IPython magic to ensure Python compatibility. | |
| # %%time | |
| # train(train_dataset, EPOCHS) | |
| """Restore the latest checkpoint.""" | |
| checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir)) | |
| """## Create a GIF""" | |
| # Display a single image using the epoch number | |
| def display_image(epoch_no): | |
| return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no)) | |
| display_image(EPOCHS) | |
| """# **Proof of Concept #2** | |
| # **Cleaning up noisy/missing data from NASA datasets** | |
| # **# Algorithm: Denoising Autoencoder** | |
| **Denoising_autoencoders_NASA_earth_data** | |
| https://colab.research.google.com/drive/1Sj_J9yKrNXkFQCBMcZAqF03MOJqUIt_N#forceEdit=true&sandboxMode=true | |
| https://colab.research.google.com/drive/1Sj_J9yKrNXkFQCBMcZAqF03MOJqUIt_N | |
| https://github.com/pilillo/img-notebooks | |
| https://github.com/pilillo/img-notebooks/blob/master/Denoising_autoencoders.ipynb | |
| """ | |
| !pwd | |
| cd Colab\ Notebooks | |
| !ls | |
| # mount google drive location where you saved a .zip archive of your folder that contains images; then unzip the file | |
| from google.colab import drive | |
| drive.mount('/content/drive') | |
| # get RGB images from Google drive and store them as numpy array | |
| from PIL import Image | |
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| import glob | |
| import math | |
| import cv2 | |
| #filelist = glob.glob('Bulk/*.jpg') | |
| #good_im = np.array([np.array(Image.open(fname).convert('LA')) for fname in filelist]) # Already converts to grayscale but has an extra dummy layer | |
| filelist = glob.glob('Bulk/*.jpg') | |
| data = [] | |
| for file in filelist: | |
| img = cv2.imread(file) | |
| img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) | |
| data.append(img_gray) | |
| np.shape(data) | |
| data_array = np.array(data) | |
| data_array.shape, type(data_array) | |
| plt.imshow(data_array[56,:,:]) | |
| # split the batch into training and test set: 80-20 partition | |
| batch_size = len(data_array[:,0,0]) | |
| train_size = int(math.ceil(batch_size*0.8)) | |
| test_size = batch_size - train_size | |
| x_train = data_array[0:train_size,:,:] | |
| x_test = data_array[train_size:,:,:] | |
| train_size, test_size | |
| x_train.shape, x_test.shape | |
| # Commented out IPython magic to ensure Python compatibility. | |
| # %matplotlib inline | |
| import keras | |
| #from keras.datasets import cifar10 | |
| #from keras.datasets import mnist | |
| from matplotlib import pyplot | |
| from matplotlib.pyplot import imshow | |
| import numpy as np | |
| # https://keras.io/datasets/#mnist-database-of-handwritten-digits | |
| # load mnist in a grayscale format bunch of images | |
| #(x_train, y_train), (x_test, y_test) = mnist.load_data() | |
| print('x_train shape:', x_train.shape) | |
| print(x_train.shape[0], 'train samples') | |
| print(x_test.shape[0], 'test samples') | |
| for i in range(0, 9): | |
| pyplot.subplot(330 + 1 + i) | |
| imshow(x_train[i]) | |
| imgplot = pyplot.imshow(x_train[i]) | |
| print "training set shape is", x_train.shape | |
| #print y_train.shape | |
| # since we deal with square images | |
| image_size = x_train.shape[1] | |
| # inspect the format of x and y | |
| print "First image in the training set" | |
| pyplot.imshow(x_train[0]) | |
| initial_seed = 1234 | |
| np.random.seed(initial_seed) | |
| print np.amax(x_train) | |
| # normalize the pixel values to have everything between 0 and 1 | |
| x_train = x_train.astype('float32') / 255 | |
| x_test = x_test.astype('float32') / 255 | |
| # https://github.com/keras-team/keras/blob/master/examples/mnist_denoising_autoencoder.py | |
| # https://blog.keras.io/building-autoencoders-in-keras.html | |
| # x_train_ = np.reshape(x_train, [-1, image_size, image_size, 1]) | |
| x_train_ = np.reshape(x_train, (len(x_train), image_size, image_size, 1)) | |
| print "Reshaped train from", x_train.shape, "to", x_train_.shape | |
| #x_test_ = np.reshape(x_test, [-1, image_size, image_size, 1]) | |
| x_test_ = np.reshape(x_test, (len(x_test), image_size, image_size, 1)) | |
| print "Reshaped test from", x_test.shape, "to", x_test_.shape | |
| # Generate corrupted MNIST images by adding noise with normal dist | |
| # centered at 0.5 and std=0.5 | |
| noise = np.random.normal(loc=0.5, | |
| scale=0.5, | |
| size=x_train_.shape) | |
| print "x_train noise.shape", noise.shape | |
| x_train_noisy = x_train_ + noise | |
| noise = np.random.normal(loc=0.5, | |
| scale=0.5, | |
| size=x_test_.shape) | |
| x_test_noisy = x_test_ + noise | |
| print "x_test noise.shape", noise.shape | |
| # make sure the data are in the [0,1] range by clipping lower and higher ones | |
| # https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.clip.html | |
| x_train_noisy = np.clip(x_train_noisy, 0., 1.) | |
| x_test_noisy = np.clip(x_test_noisy, 0., 1.) | |
| """Let's see how noisy became the first training entry after adding the noise:""" | |
| pyplot.imshow( | |
| np.reshape(x_train_noisy[0], (1, image_size, image_size))[0] | |
| ) | |
| from keras.models import Sequential | |
| from keras.layers import Dense, Dropout, Activation, Flatten | |
| from keras.constraints import maxnorm | |
| from keras.optimizers import SGD, rmsprop | |
| from keras.layers.convolutional import Conv2D, MaxPooling2D, UpSampling2D | |
| model = Sequential() | |
| model.add(Conv2D(16, (3, 3), | |
| input_shape=x_train_.shape[1:], # (28, 28) | |
| activation='relu', | |
| padding='same')) | |
| model.add(MaxPooling2D((2, 2), padding="same")) | |
| model.add(Conv2D(8, (3, 3), activation='relu', padding='same')) | |
| model.add(MaxPooling2D((2, 2), padding="same")) | |
| model.add(Conv2D(8, (3, 3), activation='relu', padding='same')) | |
| model.add(MaxPooling2D((2, 2), padding="same")) | |
| # ** encoded representation ** | |
| # at this point the representation is (4, 4, 8) i.e. 128-dimensional | |
| model.add(Conv2D(8, (3, 3), activation='relu', padding='same')) | |
| model.add(UpSampling2D((2, 2))) | |
| model.add(Conv2D(8, (3, 3), activation='relu', padding='same')) | |
| model.add(UpSampling2D((2, 2))) | |
| model.add(Conv2D(16, (3, 3), activation='relu')) | |
| model.add(UpSampling2D((2, 2))) | |
| model.add(Conv2D(1, (3, 3), activation='sigmoid', padding='same')) | |
| model.compile(optimizer='adadelta', loss='binary_crossentropy') | |
| model.fit(x_train_noisy, | |
| x_train_, | |
| epochs=250, | |
| batch_size=128, | |
| shuffle=True, | |
| validation_data=(x_test_noisy, x_test_)) | |
| # example prediction on the corrupted test images | |
| decoded = model.predict( | |
| # only predict the first element as example | |
| np.reshape(x_test_noisy[0], (1, image_size, image_size, 1)) | |
| ) | |
| pyplot.imshow( | |
| np.reshape(x_test_noisy[0], (1, image_size, image_size))[0] | |
| ) | |
| pyplot.imshow( | |
| np.reshape(decoded, (1, image_size, image_size))[0] | |
| ) | |
| from __future__ import absolute_import | |
| from __future__ import division | |
| from __future__ import print_function | |
| import keras | |
| from keras.layers import Activation, Dense, Input | |
| from keras.layers import Conv2D, Flatten | |
| from keras.layers import Reshape, Conv2DTranspose | |
| from keras.models import Model | |
| from keras import backend as K | |
| from keras.datasets import mnist | |
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| from PIL import Image | |
| np.random.seed(1337) | |
| # MNIST dataset | |
| (x_train, _), (x_test, _) = mnist.load_data() | |
| image_size = x_train.shape[1] | |
| x_train = np.reshape(x_train, [-1, image_size, image_size, 1]) | |
| x_test = np.reshape(x_test, [-1, image_size, image_size, 1]) | |
| x_train = x_train.astype('float32') / 255 | |
| x_test = x_test.astype('float32') / 255 | |
| # Generate corrupted MNIST images by adding noise with normal dist | |
| # centered at 0.5 and std=0.5 | |
| noise = np.random.normal(loc=0.5, scale=0.5, size=x_train.shape) | |
| x_train_noisy = x_train + noise | |
| noise = np.random.normal(loc=0.5, scale=0.5, size=x_test.shape) | |
| x_test_noisy = x_test + noise | |
| x_train_noisy = np.clip(x_train_noisy, 0., 1.) | |
| x_test_noisy = np.clip(x_test_noisy, 0., 1.) | |
| # Network parameters | |
| input_shape = (image_size, image_size, 1) | |
| batch_size = 128 | |
| kernel_size = 3 | |
| latent_dim = 16 | |
| # Encoder/Decoder number of CNN layers and filters per layer | |
| layer_filters = [32, 64] | |
| # Build the Autoencoder Model | |
| # First build the Encoder Model | |
| inputs = Input(shape=input_shape, name='encoder_input') | |
| x = inputs | |
| # Stack of Conv2D blocks | |
| # Notes: | |
| # 1) Use Batch Normalization before ReLU on deep networks | |
| # 2) Use MaxPooling2D as alternative to strides>1 | |
| # - faster but not as good as strides>1 | |
| for filters in layer_filters: | |
| x = Conv2D(filters=filters, | |
| kernel_size=kernel_size, | |
| strides=2, | |
| activation='relu', | |
| padding='same')(x) | |
| # Shape info needed to build Decoder Model | |
| shape = K.int_shape(x) | |
| # Generate the latent vector | |
| x = Flatten()(x) | |
| latent = Dense(latent_dim, name='latent_vector')(x) | |
| # Instantiate Encoder Model | |
| encoder = Model(inputs, latent, name='encoder') | |
| encoder.summary() | |
| # Build the Decoder Model | |
| latent_inputs = Input(shape=(latent_dim,), name='decoder_input') | |
| x = Dense(shape[1] * shape[2] * shape[3])(latent_inputs) | |
| x = Reshape((shape[1], shape[2], shape[3]))(x) | |
| # Stack of Transposed Conv2D blocks | |
| # Notes: | |
| # 1) Use Batch Normalization before ReLU on deep networks | |
| # 2) Use UpSampling2D as alternative to strides>1 | |
| # - faster but not as good as strides>1 | |
| for filters in layer_filters[::-1]: | |
| x = Conv2DTranspose(filters=filters, | |
| kernel_size=kernel_size, | |
| strides=2, | |
| activation='relu', | |
| padding='same')(x) | |
| x = Conv2DTranspose(filters=1, | |
| kernel_size=kernel_size, | |
| padding='same')(x) | |
| outputs = Activation('sigmoid', name='decoder_output')(x) | |
| # Instantiate Decoder Model | |
| decoder = Model(latent_inputs, outputs, name='decoder') | |
| decoder.summary() | |
| # Autoencoder = Encoder + Decoder | |
| # Instantiate Autoencoder Model | |
| autoencoder = Model(inputs, decoder(encoder(inputs)), name='autoencoder') | |
| autoencoder.summary() | |
| autoencoder.compile(loss='mse', optimizer='adam') | |
| # Train the autoencoder | |
| autoencoder.fit(x_train_noisy, | |
| x_train, | |
| validation_data=(x_test_noisy, x_test), | |
| epochs=30, | |
| batch_size=batch_size) | |
| # Predict the Autoencoder output from corrupted test images | |
| x_decoded = autoencoder.predict(x_test_noisy) | |
| # Display the 1st 8 corrupted and denoised images | |
| rows, cols = 10, 30 | |
| num = rows * cols | |
| imgs = np.concatenate([x_test[:num], x_test_noisy[:num], x_decoded[:num]]) | |
| imgs = imgs.reshape((rows * 3, cols, image_size, image_size)) | |
| imgs = np.vstack(np.split(imgs, rows, axis=1)) | |
| imgs = imgs.reshape((rows * 3, -1, image_size, image_size)) | |
| imgs = np.vstack([np.hstack(i) for i in imgs]) | |
| imgs = (imgs * 255).astype(np.uint8) | |
| plt.figure() | |
| plt.axis('off') | |
| plt.title('Original images: top rows, ' | |
| 'Corrupted Input: middle rows, ' | |
| 'Denoised Input: third rows') | |
| plt.imshow(imgs, interpolation='none', cmap='gray') | |
| Image.fromarray(imgs).save('corrupted_and_denoised.png') | |
| plt.show() | |
| """All the other demos are examples of Supervised Learning, so in this demo is an example of Unsupervised Learning we train an autoencoder on MNIST digits. | |
| An autoencoder is a regression task where the network is asked to predict its input (in other words, model the identity function). Sounds simple enough, except the network has a tight bottleneck of a few neurons in the middle (in the default example only two!), forcing it to create effective representations that compress the input into a low-dimensional code that can be used by the decoder to reproduce the original input | |
| https://cs.stanford.edu/people/karpathy/convnetjs/demo/autoencoder.html | |
| CITATIONS: | |
| https://github.com/pilillo/img-notebooks/blob/master/Denoising_autoencoders.ipynb | |
| https://paperswithcode.com/paper/high-throughput-onboard-hyperspectral-image | |
| https://arxiv.org/abs/1607.07539 | |
| http://bamos.github.io/2016/08/09/deep-completion/#ml-heavy-tensorflow-implementation-of-image-completion-with-dcgans | |
| # **Other similar algorithms as solutions to the missing data challenge** | |
| # **RDCGAN: Unsupervised Representation Learning With Regularized Deep Convolutional Generative Adversarial Networks** | |
| https://colab.research.google.com/drive/1xMdzSoZJXEvIKRxuzSCvDMjAkrweGPky | |
| http://bamos.github.io/2016/08/09/deep-completion/#ml-heavy-tensorflow-implementation-of-image-completion-with-dcgans | |
| --- | |
| --- | |
| --- | |
| # **ISR: Image Super Resolution** | |
| # **# Demo of training** | |
| """ | |
| !pip install ISR | |
| """# Train | |
| ## Get the training data | |
| Get your data to train the model. The div2k dataset linked here is for a scaling factor of 2. Beware of this later when training the model. | |
| (for more options on how to get you data on Colab notebooks visit https://colab.research.google.com/notebooks/io.ipynb) | |
| """ | |
| !wget http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_LR_bicubic_X2.zip | |
| !wget http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_valid_LR_bicubic_X2.zip | |
| !wget http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_HR.zip | |
| !wget http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_valid_HR.zip | |
| !mkdir div2k | |
| !unzip -q DIV2K_valid_LR_bicubic_X2.zip -d div2k | |
| !unzip -q DIV2K_train_LR_bicubic_X2.zip -d div2k | |
| !unzip -q DIV2K_train_HR.zip -d div2k | |
| !unzip -q DIV2K_valid_HR.zip -d div2k | |
| """## Create the models | |
| Import the models from the ISR package and create | |
| - a RRDN super scaling network | |
| - a discriminator network for GANs training | |
| - a VGG19 feature extractor to train with a perceptual loss function | |
| Carefully select | |
| - 'x': this is the upscaling factor (2 by default) | |
| - 'layers_to_extract': these are the layers from the VGG19 that will be used in the perceptual loss (leave the default if you're not familiar with it) | |
| - 'lr_patch_size': this is the size of the patches that will be extracted from the LR images and fed to the ISR network during training time | |
| Play around with the other architecture parameters | |
| """ | |
| from ISR.models import RRDN | |
| from ISR.models import Discriminator | |
| from ISR.models import Cut_VGG19 | |
| lr_train_patch_size = 40 | |
| layers_to_extract = [5, 9] | |
| scale = 2 | |
| hr_train_patch_size = lr_train_patch_size * scale | |
| rrdn = RRDN(arch_params={'C':4, 'D':3, 'G':64, 'G0':64, 'T':10, 'x':scale}, patch_size=lr_train_patch_size) | |
| f_ext = Cut_VGG19(patch_size=hr_train_patch_size, layers_to_extract=layers_to_extract) | |
| discr = Discriminator(patch_size=hr_train_patch_size, kernel_size=3) | |
| """## Give the models to the Trainer | |
| The Trainer object will combine the networks, manage your training data and keep you up-to-date with the training progress through Tensorboard and the command line. | |
| Here we do not use the pixel-wise MSE but only the perceptual loss by specifying the respective weights in `loss_weights` | |
| """ | |
| from ISR.train import Trainer | |
| loss_weights = { | |
| 'generator': 0.0, | |
| 'feature_extractor': 0.0833, | |
| 'discriminator': 0.01 | |
| } | |
| losses = { | |
| 'generator': 'mae', | |
| 'feature_extractor': 'mse', | |
| 'discriminator': 'binary_crossentropy' | |
| } | |
| log_dirs = {'logs': './logs', 'weights': './weights'} | |
| learning_rate = {'initial_value': 0.0004, 'decay_factor': 0.5, 'decay_frequency': 30} | |
| flatness = {'min': 0.0, 'max': 0.15, 'increase': 0.01, 'increase_frequency': 5} | |
| trainer = Trainer( | |
| generator=rrdn, | |
| discriminator=discr, | |
| feature_extractor=f_ext, | |
| lr_train_dir='div2k/DIV2K_train_LR_bicubic/X2/', | |
| hr_train_dir='div2k/DIV2K_train_HR/', | |
| lr_valid_dir='div2k/DIV2K_train_LR_bicubic/X2/', | |
| hr_valid_dir='div2k/DIV2K_train_HR/', | |
| loss_weights=loss_weights, | |
| learning_rate=learning_rate, | |
| flatness=flatness, | |
| dataname='div2k', | |
| log_dirs=log_dirs, | |
| weights_generator=None, | |
| weights_discriminator=None, | |
| n_validation=40, | |
| ) | |
| """Choose epoch number, steps and batch size and start training""" | |
| trainer.train( | |
| epochs=1, | |
| steps_per_epoch=20, | |
| batch_size=4, | |
| monitored_metrics={'val_PSNR_Y': 'max'} | |
| ) |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment