Created
March 25, 2021 22:07
-
-
Save gngdb/9ae3393ab31224a9f1015ed7547d1869 to your computer and use it in GitHub Desktop.
https://github.com/karpathy/minGPT/blob/master/play_char.ipynb unpacked into a single notebook
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "This notebook is based on [minGPT's play_char][playchar], but avoiding any of the imports. Instead I'm going to import them into this notebook, which is going to make the notebook much longer but the whole thing is going to be self-contained. I'm doing this to learn about how GPT works more than any other reason.\n", | |
| "\n", | |
| "[playchar]: https://github.com/karpathy/minGPT/blob/master/play_char.ipynb" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Train a character-level GPT on some text data\n", | |
| "\n", | |
| "The inputs here are simple text files, which we chop up to individual characters and then train GPT on. So you could say this is a char-transformer instead of a char-rnn. Doesn't quite roll off the tongue as well. In this example we will feed it some Shakespeare, which we'll get it to predict character-level." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 1, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "env: CUDA_VISIBLE_DEVICES=0\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "%env CUDA_VISIBLE_DEVICES=0" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 2, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# set up logging\n", | |
| "import logging\n", | |
| "logging.basicConfig(\n", | |
| " format=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\n", | |
| " datefmt=\"%m/%d/%Y %H:%M:%S\",\n", | |
| " level=logging.INFO,\n", | |
| ")" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 3, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s set_seed https://github.com/karpathy/minGPT/raw/master/mingpt/utils.py\n", | |
| "def set_seed(seed):\n", | |
| " random.seed(seed)\n", | |
| " np.random.seed(seed)\n", | |
| " torch.manual_seed(seed)\n", | |
| " torch.cuda.manual_seed_all(seed)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 4, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import numpy as np\n", | |
| "import torch\n", | |
| "import torch.nn as nn\n", | |
| "from torch.nn import functional as F" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 5, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import math\n", | |
| "from torch.utils.data import Dataset\n", | |
| "\n", | |
| "class CharDataset(Dataset):\n", | |
| "\n", | |
| " def __init__(self, data, block_size):\n", | |
| " chars = sorted(list(set(data)))\n", | |
| " data_size, vocab_size = len(data), len(chars)\n", | |
| " print('data has %d characters, %d unique.' % (data_size, vocab_size))\n", | |
| " \n", | |
| " self.stoi = { ch:i for i,ch in enumerate(chars) }\n", | |
| " self.itos = { i:ch for i,ch in enumerate(chars) }\n", | |
| " self.block_size = block_size\n", | |
| " self.vocab_size = vocab_size\n", | |
| " self.data = data\n", | |
| " \n", | |
| " def __len__(self):\n", | |
| " return len(self.data) - self.block_size\n", | |
| "\n", | |
| " def __getitem__(self, idx):\n", | |
| " # grab a chunk of (block_size + 1) characters from the data\n", | |
| " chunk = self.data[idx:idx + self.block_size + 1]\n", | |
| " # encode every character to an integer\n", | |
| " dix = [self.stoi[s] for s in chunk]\n", | |
| " \"\"\"\n", | |
| " arrange data and targets so that the first i elements of x\n", | |
| " will be asked to predict the i-th element of y. Notice that\n", | |
| " the eventual language model will actually make block_size\n", | |
| " individual predictions at the same time based on this data,\n", | |
| " so we are being clever and amortizing the cost of the forward\n", | |
| " pass of the network. So for example if block_size is 4, then\n", | |
| " we could e.g. sample a chunk of text \"hello\", the integers in\n", | |
| " x will correspond to \"hell\" and in y will be \"ello\". This will\n", | |
| " then actually \"multitask\" 4 separate examples at the same time\n", | |
| " in the language model:\n", | |
| " - given just \"h\", please predict \"e\" as next\n", | |
| " - given \"he\" please predict \"l\" next\n", | |
| " - given \"hel\" predict \"l\" next\n", | |
| " - given \"hell\" predict \"o\" next\n", | |
| " \n", | |
| " In addition, because the DataLoader will create batches of examples,\n", | |
| " every forward/backward pass during traning will simultaneously train\n", | |
| " a LOT of predictions, amortizing a lot of computation. In particular,\n", | |
| " for a batched input of integers X (B, T) where B is batch size and\n", | |
| " T is block_size and Y (B, T), the network will during training be\n", | |
| " simultaneously training to make B*T predictions, all at once! Of course,\n", | |
| " at test time we can paralellize across batch B, but unlike during training\n", | |
| " we cannot parallelize across the time dimension T - we have to run\n", | |
| " a forward pass of the network to recover the next single character of the \n", | |
| " sequence along each batch dimension, and repeatedly always feed in a next\n", | |
| " character to get the next one.\n", | |
| " \n", | |
| " So yes there is a big asymmetry between train/test time of autoregressive\n", | |
| " models. During training we can go B*T at a time with every forward pass,\n", | |
| " but during test time we can only go B at a time, T times, with T forward \n", | |
| " passes.\n", | |
| " \"\"\"\n", | |
| " x = torch.tensor(dix[:-1], dtype=torch.long)\n", | |
| " y = torch.tensor(dix[1:], dtype=torch.long)\n", | |
| " return x, y\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 6, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "block_size = 128 # spatial extent of the model for its context" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 11, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "!wget -q -nc https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 12, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "data has 1115394 characters, 65 unique.\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# you can download this file at https://github.com/karpathy/char-rnn/blob/master/data/tinyshakespeare/input.txt\n", | |
| "# text = open('input.txt', 'r').read() # don't worry we won't run out of file handles\n", | |
| "# SORYY ANDREJ I AM WORRIED\n", | |
| "with open('input.txt', 'r') as f:\n", | |
| " text = f.read()\n", | |
| "train_dataset = CharDataset(text, block_size) # one line of poem is roughly 50 characters" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 13, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "x: torch.Size([128]) torch.int64\n", | |
| "y: torch.Size([128]) torch.int64\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "x,y = train_dataset[0]\n", | |
| "print('x: ', x.shape, x.dtype)\n", | |
| "print('y: ', y.shape, y.dtype)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "The Model\n", | |
| "=========\n", | |
| "\n", | |
| "It's probably a good idea to delineate this Section, I'll Put a title before Training too.\n", | |
| "\n", | |
| "I'm adding a debug break so I can call it later to inspect different variables while this thing is running." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 14, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "class Debugger():\n", | |
| " def __init__(self, break_at):\n", | |
| " self.break_idx = 0\n", | |
| " self.break_at = break_at\n", | |
| " def __call__(self, **kwargs):\n", | |
| " if self.break_idx == self.break_at:\n", | |
| " for kwarg in kwargs:\n", | |
| " x = kwargs[kwarg]\n", | |
| " if isinstance(x, torch.Tensor):\n", | |
| " print(f\"{kwarg}: {x.size()} {x.dtype}, min={x.min():.3f} max={x.max():.3f}\")\n", | |
| " else:\n", | |
| " print(f\"{kwarg}: {x}\")\n", | |
| " assert False\n", | |
| " else:\n", | |
| " self.break_idx += 1 if self.break_at > 0 else 0" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "I also need a `logger` because this is going to try and use one." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 15, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -r 17 https://github.com/karpathy/minGPT/raw/master/mingpt/model.py\n", | |
| "logger = logging.getLogger(__name__)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 16, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s GPT https://github.com/karpathy/minGPT/raw/master/mingpt/model.py\n", | |
| "class GPT(nn.Module):\n", | |
| " \"\"\" the full GPT language model, with a context size of block_size \"\"\"\n", | |
| "\n", | |
| " def __init__(self, config, debugger):\n", | |
| " super().__init__()\n", | |
| "\n", | |
| " # input embedding stem\n", | |
| " self.tok_emb = nn.Embedding(config.vocab_size, config.n_embd)\n", | |
| " self.pos_emb = nn.Parameter(torch.zeros(1, config.block_size, config.n_embd))\n", | |
| " self.drop = nn.Dropout(config.embd_pdrop)\n", | |
| " # transformer\n", | |
| " self.blocks = nn.Sequential(*[Block(config, debugger) for _ in range(config.n_layer)])\n", | |
| " # decoder head\n", | |
| " self.ln_f = nn.LayerNorm(config.n_embd)\n", | |
| " self.head = nn.Linear(config.n_embd, config.vocab_size, bias=False)\n", | |
| "\n", | |
| " self.block_size = config.block_size\n", | |
| " self.apply(self._init_weights)\n", | |
| "\n", | |
| " logger.info(\"number of parameters: %e\", sum(p.numel() for p in self.parameters()))\n", | |
| " \n", | |
| " self.debugger = debugger\n", | |
| "\n", | |
| " def get_block_size(self):\n", | |
| " return self.block_size\n", | |
| "\n", | |
| " def _init_weights(self, module):\n", | |
| " if isinstance(module, (nn.Linear, nn.Embedding)):\n", | |
| " module.weight.data.normal_(mean=0.0, std=0.02)\n", | |
| " if isinstance(module, nn.Linear) and module.bias is not None:\n", | |
| " module.bias.data.zero_()\n", | |
| " elif isinstance(module, nn.LayerNorm):\n", | |
| " module.bias.data.zero_()\n", | |
| " module.weight.data.fill_(1.0)\n", | |
| "\n", | |
| " def configure_optimizers(self, train_config):\n", | |
| " \"\"\"\n", | |
| " This long function is unfortunately doing something very simple and is being very defensive:\n", | |
| " We are separating out all parameters of the model into two buckets: those that will experience\n", | |
| " weight decay for regularization and those that won't (biases, and layernorm/embedding weights).\n", | |
| " We are then returning the PyTorch optimizer object.\n", | |
| " \"\"\"\n", | |
| "\n", | |
| " # separate out all parameters to those that will and won't experience regularizing weight decay\n", | |
| " decay = set()\n", | |
| " no_decay = set()\n", | |
| " whitelist_weight_modules = (torch.nn.Linear, )\n", | |
| " blacklist_weight_modules = (torch.nn.LayerNorm, torch.nn.Embedding)\n", | |
| " for mn, m in self.named_modules():\n", | |
| " for pn, p in m.named_parameters():\n", | |
| " fpn = '%s.%s' % (mn, pn) if mn else pn # full param name\n", | |
| "\n", | |
| " if pn.endswith('bias'):\n", | |
| " # all biases will not be decayed\n", | |
| " no_decay.add(fpn)\n", | |
| " elif pn.endswith('weight') and isinstance(m, whitelist_weight_modules):\n", | |
| " # weights of whitelist modules will be weight decayed\n", | |
| " decay.add(fpn)\n", | |
| " elif pn.endswith('weight') and isinstance(m, blacklist_weight_modules):\n", | |
| " # weights of blacklist modules will NOT be weight decayed\n", | |
| " no_decay.add(fpn)\n", | |
| "\n", | |
| " # special case the position embedding parameter in the root GPT module as not decayed\n", | |
| " no_decay.add('pos_emb')\n", | |
| "\n", | |
| " # validate that we considered every parameter\n", | |
| " param_dict = {pn: p for pn, p in self.named_parameters()}\n", | |
| " inter_params = decay & no_decay\n", | |
| " union_params = decay | no_decay\n", | |
| " assert len(inter_params) == 0, \"parameters %s made it into both decay/no_decay sets!\" % (str(inter_params), )\n", | |
| " assert len(param_dict.keys() - union_params) == 0, \"parameters %s were not separated into either decay/no_decay set!\" \\\n", | |
| " % (str(param_dict.keys() - union_params), )\n", | |
| "\n", | |
| " # create the pytorch optimizer object\n", | |
| " optim_groups = [\n", | |
| " {\"params\": [param_dict[pn] for pn in sorted(list(decay))], \"weight_decay\": train_config.weight_decay},\n", | |
| " {\"params\": [param_dict[pn] for pn in sorted(list(no_decay))], \"weight_decay\": 0.0},\n", | |
| " ]\n", | |
| " optimizer = torch.optim.AdamW(optim_groups, lr=train_config.learning_rate, betas=train_config.betas)\n", | |
| " return optimizer\n", | |
| "\n", | |
| " def forward(self, idx, targets=None):\n", | |
| " b, t = idx.size()\n", | |
| " assert t <= self.block_size, \"Cannot forward, model block size is exhausted.\"\n", | |
| "\n", | |
| " # forward the GPT model\n", | |
| " token_embeddings = self.tok_emb(idx) # each index maps to a (learnable) vector\n", | |
| " position_embeddings = self.pos_emb[:, :t, :] # each position maps to a (learnable) vector\n", | |
| " self.debugger(token_embeddings=token_embeddings, position_embeddings=position_embeddings)\n", | |
| " x = self.drop(token_embeddings + position_embeddings)\n", | |
| " self.debugger(before_blocks=x)\n", | |
| " x = self.blocks(x)\n", | |
| " self.debugger(after_blocks=x)\n", | |
| " x = self.ln_f(x)\n", | |
| " logits = self.head(x)\n", | |
| "\n", | |
| " # if we are given some desired targets also calculate the loss\n", | |
| " loss = None\n", | |
| " if targets is not None:\n", | |
| " loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))\n", | |
| "\n", | |
| " return logits, loss" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "This module uses the internally defined `Block` modules. The choice of a Gaussian Error Linear Unit is surprising to me, I haven't seen that before. As far as I can tell, it's chosen just because [it performs better in some empirical evaluation?][gelu]\n", | |
| "\n", | |
| "Also, it looks like this block has roughly the same structure as the Encoder block from the [illustrated transformer][illustrated] article.\n", | |
| "\n", | |
| "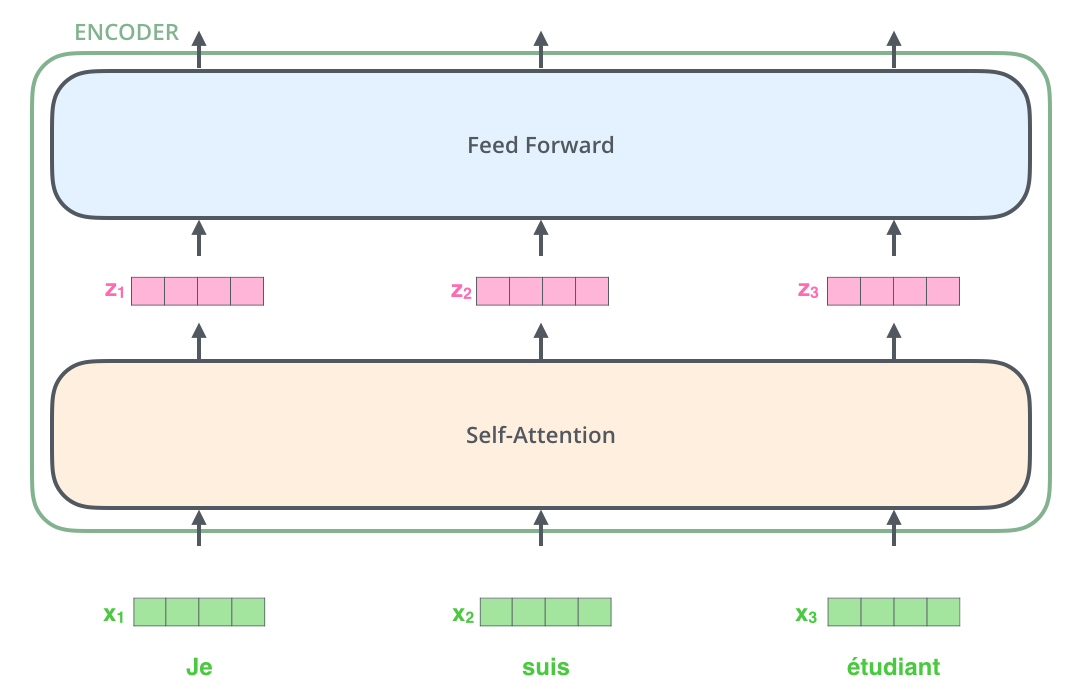\n", | |
| "\n", | |
| "[illustrated]: http://jalammar.github.io/illustrated-transformer/\n", | |
| "[gelu]: https://arxiv.org/abs/1606.08415v4" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 17, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s Block https://github.com/karpathy/minGPT/raw/master/mingpt/model.py\n", | |
| "class Block(nn.Module):\n", | |
| " \"\"\" an unassuming Transformer block \"\"\"\n", | |
| "\n", | |
| " def __init__(self, config, debugger):\n", | |
| " super().__init__()\n", | |
| " self.debugger = debugger\n", | |
| " self.ln1 = nn.LayerNorm(config.n_embd)\n", | |
| " self.ln2 = nn.LayerNorm(config.n_embd)\n", | |
| " self.attn = CausalSelfAttention(config, debugger)\n", | |
| " self.mlp = nn.Sequential(\n", | |
| " nn.Linear(config.n_embd, 4 * config.n_embd),\n", | |
| " nn.GELU(), # why this nonlinearity? https://pytorch.org/docs/stable/generated/torch.nn.GELU.html\n", | |
| " nn.Linear(4 * config.n_embd, config.n_embd),\n", | |
| " nn.Dropout(config.resid_pdrop),\n", | |
| " )\n", | |
| "\n", | |
| " def forward(self, x):\n", | |
| " self.debugger(in_block=x)\n", | |
| " x = x + self.attn(self.ln1(x))\n", | |
| " x = x + self.mlp(self.ln2(x))\n", | |
| " return x" | |
| ] | |
| }, | |
| { | |
| "attachments": {}, | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "And those use `CausalSelfAttention` modules.\n", | |
| "\n", | |
| "The Queries `q`, Keys `k` and Values `v` are also illustrated:\n", | |
| "\n", | |
| "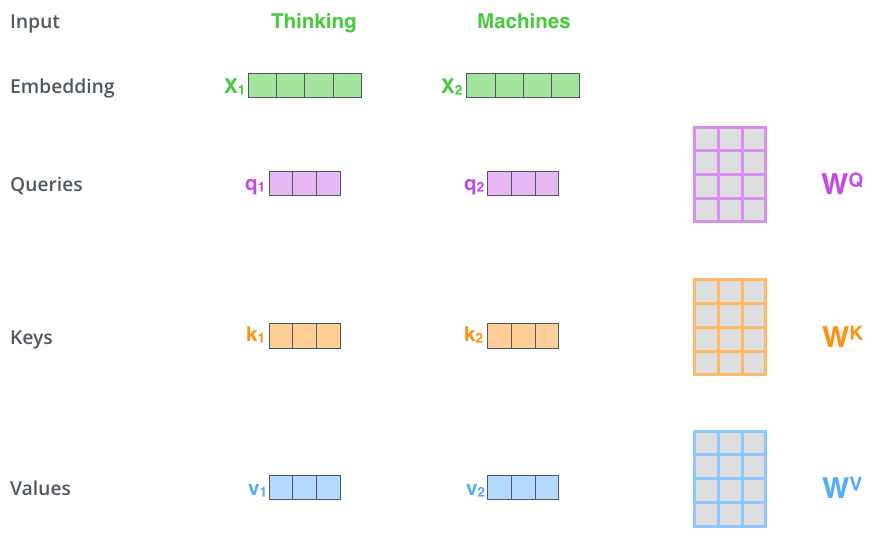\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 18, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s CausalSelfAttention https://github.com/karpathy/minGPT/raw/master/mingpt/model.py\n", | |
| "class CausalSelfAttention(nn.Module):\n", | |
| " \"\"\"\n", | |
| " A vanilla multi-head masked self-attention layer with a projection at the end.\n", | |
| " It is possible to use torch.nn.MultiheadAttention here but I am including an\n", | |
| " explicit implementation here to show that there is nothing too scary here.\n", | |
| " \"\"\"\n", | |
| "\n", | |
| " def __init__(self, config, debugger):\n", | |
| " super().__init__()\n", | |
| " self.debugger = debugger\n", | |
| " assert config.n_embd % config.n_head == 0\n", | |
| " # key, query, value projections for all heads\n", | |
| " self.key = nn.Linear(config.n_embd, config.n_embd)\n", | |
| " self.query = nn.Linear(config.n_embd, config.n_embd)\n", | |
| " self.value = nn.Linear(config.n_embd, config.n_embd)\n", | |
| " # regularization\n", | |
| " self.attn_drop = nn.Dropout(config.attn_pdrop)\n", | |
| " self.resid_drop = nn.Dropout(config.resid_pdrop)\n", | |
| " # output projection\n", | |
| " self.proj = nn.Linear(config.n_embd, config.n_embd)\n", | |
| " # causal mask to ensure that attention is only applied to the left in the input sequence\n", | |
| " self.register_buffer(\"mask\", torch.tril(torch.ones(config.block_size, config.block_size))\n", | |
| " .view(1, 1, config.block_size, config.block_size))\n", | |
| " self.n_head = config.n_head\n", | |
| "\n", | |
| " def forward(self, x, layer_past=None):\n", | |
| " B, T, C = x.size()\n", | |
| "\n", | |
| " # calculate query, key, values for all heads in batch and move head forward to be the batch dim\n", | |
| " self.debugger(self_attention_input=x)\n", | |
| " k = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)\n", | |
| " q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)\n", | |
| " v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)\n", | |
| " self.debugger(k=k, q=q, v=v)\n", | |
| "\n", | |
| " # causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)\n", | |
| " att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))\n", | |
| " att = att.masked_fill(self.mask[:,:,:T,:T] == 0, float('-inf'))\n", | |
| " att = F.softmax(att, dim=-1)\n", | |
| " att = self.attn_drop(att)\n", | |
| " y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)\n", | |
| " y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side\n", | |
| "\n", | |
| " # output projection\n", | |
| " y = self.resid_drop(self.proj(y))\n", | |
| " return y" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "I can't use this `GPT` class without a `GPTConfig` class:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 19, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s GPTConfig https://github.com/karpathy/minGPT/raw/master/mingpt/model.py\n", | |
| "class GPTConfig:\n", | |
| " \"\"\" base GPT config, params common to all GPT versions \"\"\"\n", | |
| " embd_pdrop = 0.1\n", | |
| " resid_pdrop = 0.1\n", | |
| " attn_pdrop = 0.1\n", | |
| "\n", | |
| " def __init__(self, vocab_size, block_size, **kwargs):\n", | |
| " self.vocab_size = vocab_size\n", | |
| " self.block_size = block_size\n", | |
| " for k,v in kwargs.items():\n", | |
| " setattr(self, k, v)\n", | |
| " \n", | |
| " # adding this to explain to myself what these mean\n", | |
| " def __repr__(self):\n", | |
| " r = []\n", | |
| " r.append(f\"Embedding Dropout Probability: {self.embd_pdrop:.2f}\")\n", | |
| " r.append(f\"Residual Dropout Probability: {self.resid_pdrop:.2f}\")\n", | |
| " r.append(f\"Attention Dropout Probability: {self.attn_pdrop:.2f}\")\n", | |
| " r.append(f\"Vocabulary Size: {self.vocab_size}\")\n", | |
| " r.append(f\"Block Size: {self.block_size}\")\n", | |
| " r = [\" \"+s for s in r]\n", | |
| " return \"GPT Configuration:\\n\"+\"\\n\".join(r)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 20, | |
| "metadata": { | |
| "scrolled": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "GPT Configuration:\n", | |
| " Embedding Dropout Probability: 0.10\n", | |
| " Residual Dropout Probability: 0.10\n", | |
| " Attention Dropout Probability: 0.10\n", | |
| " Vocabulary Size: 65\n", | |
| " Block Size: 128\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:33 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "token_embeddings: torch.Size([1, 128, 512]) torch.float32, min=-0.083 max=0.080\n", | |
| "position_embeddings: torch.Size([1, 128, 512]) torch.float32, min=0.000 max=0.000\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:33 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "before_blocks: torch.Size([1, 128, 512]) torch.float32, min=-0.089 max=0.079\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:33 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-0.077 max=0.089\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:34 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-4.353 max=4.081\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:34 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.705 max=2.054\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.769 max=1.614\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.808 max=1.775\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:34 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-1.096 max=1.114\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:35 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-4.146 max=4.548\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:35 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.987 max=1.678\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.799 max=1.662\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.724 max=2.060\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:35 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-1.709 max=1.611\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:36 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-4.412 max=4.998\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:36 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-2.209 max=1.774\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.797 max=1.774\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.947 max=1.764\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:36 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-2.042 max=2.418\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:37 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-4.399 max=3.912\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:37 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.722 max=1.871\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.971 max=1.672\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.834 max=1.958\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:37 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-2.272 max=2.245\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:38 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-4.023 max=4.299\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:38 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-2.038 max=2.019\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.965 max=1.936\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.918 max=2.084\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:38 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-2.587 max=2.281\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:39 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-3.707 max=4.044\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:39 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.879 max=1.961\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.738 max=2.021\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.675 max=1.893\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:39 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-2.826 max=3.172\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:40 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-3.973 max=4.384\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:40 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.678 max=1.751\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-2.042 max=1.941\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.875 max=1.762\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:40 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "in_block: torch.Size([1, 128, 512]) torch.float32, min=-3.299 max=3.185\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:41 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "self_attention_input: torch.Size([1, 128, 512]) torch.float32, min=-4.132 max=3.991\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:41 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "k: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.843 max=1.961\n", | |
| "q: torch.Size([1, 8, 128, 64]) torch.float32, min=-1.672 max=1.791\n", | |
| "v: torch.Size([1, 8, 128, 64]) torch.float32, min=-2.085 max=1.610\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:41 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| }, | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "after_blocks: torch.Size([1, 128, 512]) torch.float32, min=-3.535 max=3.357\n" | |
| ] | |
| }, | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:42 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# test this with a dummy input\n", | |
| "mconf = GPTConfig(train_dataset.vocab_size, train_dataset.block_size,\n", | |
| " n_layer=8, n_head=8, n_embd=512)\n", | |
| "print(mconf)\n", | |
| "for i in range(28):\n", | |
| " debugger = Debugger(i)\n", | |
| " model = GPT(mconf, debugger)\n", | |
| " x, y = train_dataset[0]\n", | |
| " try:\n", | |
| " model(x.view(1,-1))\n", | |
| " except:\n", | |
| " pass" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 21, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "03/25/2021 15:57:42 - INFO - __main__ - number of parameters: 2.535219e+07\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# after that disable the debugger\n", | |
| "debugger = Debugger(-1)\n", | |
| "model = GPT(mconf, debugger)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Training\n", | |
| "=======\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 22, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "from tqdm.notebook import tqdm\n", | |
| "import torch.optim as optim\n", | |
| "from torch.optim.lr_scheduler import LambdaLR\n", | |
| "from torch.utils.data.dataloader import DataLoader" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 23, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s TrainerConfig https://github.com/karpathy/minGPT/raw/master/mingpt/trainer.py\n", | |
| "class TrainerConfig:\n", | |
| " # optimization parameters\n", | |
| " max_epochs = 10\n", | |
| " batch_size = 64\n", | |
| " learning_rate = 3e-4\n", | |
| " betas = (0.9, 0.95)\n", | |
| " grad_norm_clip = 1.0\n", | |
| " weight_decay = 0.1 # only applied on matmul weights\n", | |
| " # learning rate decay params: linear warmup followed by cosine decay to 10% of original\n", | |
| " lr_decay = False\n", | |
| " warmup_tokens = 375e6 # these two numbers come from the GPT-3 paper, but may not be good defaults elsewhere\n", | |
| " final_tokens = 260e9 # (at what point we reach 10% of original LR)\n", | |
| " # checkpoint settings\n", | |
| " ckpt_path = None\n", | |
| " num_workers = 0 # for DataLoader\n", | |
| "\n", | |
| " def __init__(self, **kwargs):\n", | |
| " for k,v in kwargs.items():\n", | |
| " setattr(self, k, v)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 24, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s Trainer https://github.com/karpathy/minGPT/raw/master/mingpt/trainer.py\n", | |
| "class Trainer:\n", | |
| "\n", | |
| " def __init__(self, model, train_dataset, test_dataset, config):\n", | |
| " self.model = model\n", | |
| " self.train_dataset = train_dataset\n", | |
| " self.test_dataset = test_dataset\n", | |
| " self.config = config\n", | |
| "\n", | |
| " # take over whatever gpus are on the system\n", | |
| " self.device = 'cpu'\n", | |
| " if torch.cuda.is_available():\n", | |
| " self.device = torch.cuda.current_device()\n", | |
| " self.model = torch.nn.DataParallel(self.model).to(self.device)\n", | |
| "\n", | |
| " def save_checkpoint(self):\n", | |
| " # DataParallel wrappers keep raw model object in .module attribute\n", | |
| " raw_model = self.model.module if hasattr(self.model, \"module\") else self.model\n", | |
| " logger.info(\"saving %s\", self.config.ckpt_path)\n", | |
| " torch.save(raw_model.state_dict(), self.config.ckpt_path)\n", | |
| "\n", | |
| " def train(self):\n", | |
| " model, config = self.model, self.config\n", | |
| " raw_model = model.module if hasattr(self.model, \"module\") else model\n", | |
| " optimizer = raw_model.configure_optimizers(config)\n", | |
| "\n", | |
| " def run_epoch(split):\n", | |
| " is_train = split == 'train'\n", | |
| " model.train(is_train)\n", | |
| " data = self.train_dataset if is_train else self.test_dataset\n", | |
| " loader = DataLoader(data, shuffle=True, pin_memory=True,\n", | |
| " batch_size=config.batch_size,\n", | |
| " num_workers=config.num_workers)\n", | |
| "\n", | |
| " losses = []\n", | |
| " pbar = tqdm(enumerate(loader), total=len(loader)) if is_train else enumerate(loader)\n", | |
| " for it, (x, y) in pbar:\n", | |
| "\n", | |
| " # place data on the correct device\n", | |
| " x = x.to(self.device)\n", | |
| " y = y.to(self.device)\n", | |
| "\n", | |
| " # forward the model\n", | |
| " with torch.set_grad_enabled(is_train):\n", | |
| " logits, loss = model(x, y)\n", | |
| " loss = loss.mean() # collapse all losses if they are scattered on multiple gpus\n", | |
| " losses.append(loss.item())\n", | |
| "\n", | |
| " if is_train:\n", | |
| "\n", | |
| " # backprop and update the parameters\n", | |
| " model.zero_grad()\n", | |
| " loss.backward()\n", | |
| " torch.nn.utils.clip_grad_norm_(model.parameters(), config.grad_norm_clip)\n", | |
| " optimizer.step()\n", | |
| "\n", | |
| " # decay the learning rate based on our progress\n", | |
| " if config.lr_decay:\n", | |
| " self.tokens += (y >= 0).sum() # number of tokens processed this step (i.e. label is not -100)\n", | |
| " if self.tokens < config.warmup_tokens:\n", | |
| " # linear warmup\n", | |
| " lr_mult = float(self.tokens) / float(max(1, config.warmup_tokens))\n", | |
| " else:\n", | |
| " # cosine learning rate decay\n", | |
| " progress = float(self.tokens - config.warmup_tokens) / float(max(1, config.final_tokens - config.warmup_tokens))\n", | |
| " lr_mult = max(0.1, 0.5 * (1.0 + math.cos(math.pi * progress)))\n", | |
| " lr = config.learning_rate * lr_mult\n", | |
| " for param_group in optimizer.param_groups:\n", | |
| " param_group['lr'] = lr\n", | |
| " else:\n", | |
| " lr = config.learning_rate\n", | |
| "\n", | |
| " # report progress\n", | |
| " pbar.set_description(f\"epoch {epoch+1} iter {it}: train loss {loss.item():.5f}. lr {lr:e}\")\n", | |
| "\n", | |
| " if not is_train:\n", | |
| " test_loss = float(np.mean(losses))\n", | |
| " logger.info(\"test loss: %f\", test_loss)\n", | |
| " return test_loss\n", | |
| "\n", | |
| " best_loss = float('inf')\n", | |
| " self.tokens = 0 # counter used for learning rate decay\n", | |
| " for epoch in range(config.max_epochs):\n", | |
| "\n", | |
| " run_epoch('train')\n", | |
| " if self.test_dataset is not None:\n", | |
| " test_loss = run_epoch('test')\n", | |
| "\n", | |
| " # supports early stopping based on the test loss, or just save always if no test set is provided\n", | |
| " good_model = self.test_dataset is None or test_loss < best_loss\n", | |
| " if self.config.ckpt_path is not None and good_model:\n", | |
| " best_loss = test_loss\n", | |
| " self.save_checkpoint()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "I had to reduce the batch size to get this to run on my single Titan X GPU." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 25, | |
| "metadata": { | |
| "scrolled": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "application/vnd.jupyter.widget-view+json": { | |
| "model_id": "a42a8109e8af4a86a531edec8b618f87", | |
| "version_major": 2, | |
| "version_minor": 0 | |
| }, | |
| "text/plain": [ | |
| " 0%| | 0/8714 [00:00<?, ?it/s]" | |
| ] | |
| }, | |
| "metadata": {}, | |
| "output_type": "display_data" | |
| }, | |
| { | |
| "data": { | |
| "application/vnd.jupyter.widget-view+json": { | |
| "model_id": "5c87e790c5a747a09b56668f6c57876c", | |
| "version_major": 2, | |
| "version_minor": 0 | |
| }, | |
| "text/plain": [ | |
| " 0%| | 0/8714 [00:00<?, ?it/s]" | |
| ] | |
| }, | |
| "metadata": {}, | |
| "output_type": "display_data" | |
| } | |
| ], | |
| "source": [ | |
| "# initialize a trainer instance and kick off training\n", | |
| "tconf = TrainerConfig(max_epochs=2, batch_size=128, learning_rate=6e-4,\n", | |
| " lr_decay=True, warmup_tokens=512*20, final_tokens=2*len(train_dataset)*block_size,\n", | |
| " num_workers=4)\n", | |
| "trainer = Trainer(model, train_dataset, None, tconf)\n", | |
| "trainer.train()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "When loading this function, it lost it's decorator and I had to put it back on." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 26, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s sample https://github.com/karpathy/minGPT/raw/master/mingpt/utils.py\n", | |
| "@torch.no_grad()\n", | |
| "def sample(model, x, steps, temperature=1.0, sample=False, top_k=None):\n", | |
| " \"\"\"\n", | |
| " take a conditioning sequence of indices in x (of shape (b,t)) and predict the next token in\n", | |
| " the sequence, feeding the predictions back into the model each time. Clearly the sampling\n", | |
| " has quadratic complexity unlike an RNN that is only linear, and has a finite context window\n", | |
| " of block_size, unlike an RNN that has an infinite context window.\n", | |
| " \"\"\"\n", | |
| " block_size = model.get_block_size()\n", | |
| " model.eval()\n", | |
| " for k in range(steps):\n", | |
| " x_cond = x if x.size(1) <= block_size else x[:, -block_size:] # crop context if needed\n", | |
| " logits, _ = model(x_cond)\n", | |
| " # pluck the logits at the final step and scale by temperature\n", | |
| " logits = logits[:, -1, :] / temperature\n", | |
| " # optionally crop probabilities to only the top k options\n", | |
| " if top_k is not None:\n", | |
| " logits = top_k_logits(logits, top_k)\n", | |
| " # apply softmax to convert to probabilities\n", | |
| " probs = F.softmax(logits, dim=-1)\n", | |
| " # sample from the distribution or take the most likely\n", | |
| " if sample:\n", | |
| " ix = torch.multinomial(probs, num_samples=1)\n", | |
| " else:\n", | |
| " _, ix = torch.topk(probs, k=1, dim=-1)\n", | |
| " # append to the sequence and continue\n", | |
| " x = torch.cat((x, ix), dim=1)\n", | |
| "\n", | |
| " return x" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 27, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# %load -s top_k_logits https://github.com/karpathy/minGPT/raw/master/mingpt/utils.py\n", | |
| "def top_k_logits(logits, k):\n", | |
| " v, ix = torch.topk(logits, k)\n", | |
| " out = logits.clone()\n", | |
| " out[out < v[:, [-1]]] = -float('Inf')\n", | |
| " return out" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 28, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "O God, O God! that e'er this tongue of mine,\n", | |
| "That laid the sentence of dread banishment\n", | |
| "On yon proud man, should take it off again\n", | |
| "With words of sooth! O that I were as great\n", | |
| "As is my grief, or lesser than my name!\n", | |
| "Or that I could forget what I have been,\n", | |
| "Or not remember what I must be now!\n", | |
| "Swell'st thou, proud heart? I'll give thee scope to beat,\n", | |
| "Since foes have scope to beat both thee and me.\n", | |
| "\n", | |
| "DUKE OF AUMERLE:\n", | |
| "Northumberland comes back from Bolingbroke.\n", | |
| "\n", | |
| "KING RICHARD II:\n", | |
| "What must the king do now? must he submit?\n", | |
| "The king shall do it: must he be deposed?\n", | |
| "The king shall be contented: must he lose\n", | |
| "The name of king? o' God's name, let it go:\n", | |
| "I'll give my jewels for a set of beads,\n", | |
| "My gorgeous palace for a hermitage,\n", | |
| "My gay apparel for an almsman's gown,\n", | |
| "My figured goblets for a dish of wood,\n", | |
| "My sceptre for a palmer's walking staff,\n", | |
| "My subjects for a pair of carved saints\n", | |
| "And my large kingdom for a little grave,\n", | |
| "A little little grave, an obscure grave;\n", | |
| "Or I'll be buried in the king's highway,\n", | |
| "Some way of common trade, where subjects' feet\n", | |
| "May hourly trample on their sovereign's head;\n", | |
| "For on my heart they tread now whilst I live;\n", | |
| "And buried once, why not upon my head?\n", | |
| "Aumerle, thou weep'st, my tender-hearted cousin!\n", | |
| "We'll make foul weather with despised tears;\n", | |
| "Our sighs and they shall lodge the summer corn,\n", | |
| "And make a dearth in this revolting land.\n", | |
| "Or shall we play the wantons with our woes,\n", | |
| "And make some pretty match with shedding tears?\n", | |
| "As thus, to drop them still upon one place,\n", | |
| "Till they have fretted us a pair of graves\n", | |
| "Within the earth; and, therein laid,--there lies\n", | |
| "Two kinsmen digg'd their graves with weeping eyes.\n", | |
| "Would not this ill do well? Well, well, I see\n", | |
| "I talk but idly, and you laugh at me.\n", | |
| "Most mighty prince, my Lord Northumberland,\n", | |
| "What says King Bolingbroke? will his majesty\n", | |
| "Give Richard leave to live till Richard die?\n", | |
| "You make a leg, and Bolingbroke says ay.\n", | |
| "\n", | |
| "NORTHUMBERLAND:\n", | |
| "My lord, in the base court he doth attend\n", | |
| "To speak with you; may it please you to come dow\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "context = \"O God, O God!\"\n", | |
| "x = torch.tensor([train_dataset.stoi[s] for s in context], dtype=torch.long)[None,...].to(trainer.device)\n", | |
| "y = sample(model, x, 2000, temperature=1.0, sample=True, top_k=10)[0]\n", | |
| "completion = ''.join([train_dataset.itos[int(i)] for i in y])\n", | |
| "print(completion)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [] | |
| } | |
| ], | |
| "metadata": { | |
| "kernelspec": { | |
| "display_name": "Python [conda env:gngdb-movement]", | |
| "language": "python", | |
| "name": "conda-env-gngdb-movement-py" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.8.5" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 4 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment