Last active
June 25, 2022 02:54
-
-
Save hunterhector/5edab0c4ef4dc4405cb0a34b4c8413bc to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "# Building a Machine Translation System with Forte \n", | |
| "https://github.com/asyml/forte\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "## Overview\n", | |
| "\n", | |
| "This tutorial will walk you through the steps to build a machine translation system with Forte. Forte allows users to breaks down complex problems into composable pipelines and enables inter-operations across tasks through a unified data format. With Forte, it's easy to compose a customized machine translation management system that is able to handle practical problems like new feature requests.\n", | |
| "\n", | |
| "We demonstrate how our composable solutions brings us the following values\n", | |
| "* Easy to debug\n", | |
| "* Easy to adapt to changes\n", | |
| "* Low friction across environments\n", | |
| "* Easy to collaborate\n", | |
| "\n", | |
| "In this tutorial, you will learn:\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| " * How to create a simple NLP pipeline\n", | |
| " * How to maintain and store the input data\n", | |
| "* How to process data in pipeline\n", | |
| " * How to perform sentence segmentation\n", | |
| " * How to annotate and query the data\n", | |
| " * How to translate the input text with a pre-trained model\n", | |
| " * How to manage multiple data objects\n", | |
| "* How to handle new practical requests\n", | |
| " * How to handle structures like HTML data\n", | |
| " * How to select a single data object for processing\n", | |
| " * How to replace the translation model with remote translation services\n", | |
| " * How to save and load the pipeline\n", | |
| "\n", | |
| "Run the following command to install all the required dependencies for this tutorial:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "pip_install" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "# It is recommended to install these in command line\n", | |
| "!pip install forte==0.2.0 forte.nltk requests\n", | |
| "# for certain environments, you may run into troubles installing transformers, such as requiring Rust\n", | |
| "# some workaround here: https://github.com/huggingface/transformers/issues/2831#issuecomment-600141935 might help\n", | |
| "!pip install transformers==4.16.2\n", | |
| "# you may want to try different pytorch version depending on your platform\n", | |
| "# if you cannot install pytorch, try locate your problem at https://github.com/pytorch/pytorch/issues\n", | |
| "!pip install torch==1.11.0\n", | |
| "# for certain environments, the installation may fail \n", | |
| "# some workaround here: https://github.com/google/sentencepiece/issues/378#issuecomment-1145399969 might help\n", | |
| "!pip install sentencepiece" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "## Start with the Reader \n", | |
| "### Overview\n", | |
| "\n", | |
| "* **How to read data from source**\n", | |
| " * **How to create a simple pipeline**\n", | |
| " * How to maintain and store the input data\n", | |
| "* How to process data in pipeline\n", | |
| "* How to handle new practical requests\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* What is a reader and why we need it\n", | |
| "* How to compose a simple pipeline with a pre-built reader\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "def_pipeline" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from forte import Pipeline\n", | |
| "from forte.data.readers import TerminalReader\n", | |
| "pipeline: Pipeline = Pipeline()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "All pipelines need a reader to read and parse input data. To make our pipeline read queries from the user’s command-line terminal, use the `TerminalReader` class provided by Forte. `TerminalReader` transforms the user’s query into a DataPack object, which is a unified data format for NLP that makes it easy to connect different NLP tools together as Forte Processors." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "terminal_reader" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "pipeline.set_reader(TerminalReader())" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "To run the pipeline consisting of the single `TerminalReader`, call `process_dataset` which will return an iterator of DataPack objects. The second line in the following code snippet retrieves the first user query from the TerminalReader. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "pipeline.initialize()\n", | |
| "datapack = next(pipeline.process_dataset())\n", | |
| "print(datapack.text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "### DataPack\n", | |
| "#### Overview\n", | |
| "\n", | |
| "* **How to read data from source**\n", | |
| " * How to create a simple pipeline\n", | |
| " * **How to maintain and store the input data**\n", | |
| "* How to process data in pipeline\n", | |
| "* How to handle new practical requests\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* What is a DataPack object and why we need it\n", | |
| "\n", | |
| "Forte helps demystify data lineage and increase the traceability of how data flows along the pipeline and how features are generated to interface data to model. Similar to a cargo ship that loads and transports goods from one port to another, a data pack carries information when passing each module and updates the ontology states along the way.\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "#### DataPack and Multi-Modality\n", | |
| "DataPack not only supports text data but also audio and image data.\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "## Add a pre-built Forte processor to the pipeline \n", | |
| "### Overview\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| "* **How to process data in pipeline**\n", | |
| " * **How to perform sentence segmentation**\n", | |
| " * How to annotate and query the data\n", | |
| " * How to translate the input text with a pre-trained model\n", | |
| " * How to manage multiple data objects\n", | |
| "* How to handle new practical requests\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* What is a processor and why we need it\n", | |
| "* How to add a pre-built processor to the pipeline\n", | |
| "\n", | |
| "A Forte Processor takes DataPacks as inputs, processes them, and stores its outputs in DataPacks. The processors we are going to use in this section are all PackProcessors, which expect exactly one DataPack as input and store its outputs back into the same DataPack. The following two lines of code shows how a pre-built processor `NLTKSentenceSegmenter` is added to our pipeline." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "add_sent_segmenter" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from fortex.nltk.nltk_processors import NLTKSentenceSegmenter\n", | |
| "pipeline.add(NLTKSentenceSegmenter())" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "When we run the pipeline, the `NLTKSentenceSegmenter` processor will split the user query into sentences and store them back to the DataPack created by TerminalReader. The code snippet below shows how to get all the sentences from the first query.\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "import_sent" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from ft.onto.base_ontology import Sentence" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "pipeline.initialize()\n", | |
| "for sent in next(pipeline.process_dataset()).get(Sentence):\n", | |
| " print(sent.text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "### Ontology\n", | |
| "#### Overview\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| "* **How to process data in pipeline**\n", | |
| " * How to perform sentence segmentation\n", | |
| " * **How to annotate and query the data**\n", | |
| " * How to translate the input text with a pre-trained model\n", | |
| " * How to manage multiple data objects\n", | |
| "* How to handle new practical requests\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* What is the ontology system and why we need it\n", | |
| "* How to write a customized ontology and how to use it\n", | |
| "\n", | |
| "`Sentence` is a pre-defined ontology provided by Forte and it is used by `NLTKSentenceSegmenter` to annotate each sentence in text. Forte is built on top of an Ontology system, which defines the relations between NLP annotations, for example, the relation between words and documents, or between two words. This is the core for Forte. The ontology can be specified via a JSON format. And tools are provided to convert the ontology into production code (Python).\n", | |
| "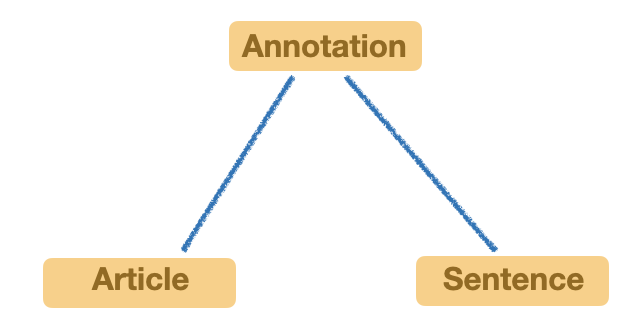\n", | |
| "\n", | |
| "We can also define customized ontologies:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "def_article" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from dataclasses import dataclass\n", | |
| "from forte.data.ontology.top import Annotation\n", | |
| "from typing import Optional\n", | |
| "\n", | |
| "@dataclass\n", | |
| "class Article(Annotation):\n", | |
| "\n", | |
| " language: Optional[str]\n", | |
| "\n", | |
| " def __init__(self, pack, begin: int, end: int):\n", | |
| " super().__init__(pack, begin, end)\n", | |
| " self.language: Optional[str] = None" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "Below is a simple example showing how we can query sentences through the new ontology we just create:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_article" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from forte.data import DataPack\n", | |
| "\n", | |
| "sentences = [\n", | |
| " \"Do you want to get better at making delicious BBQ?\",\n", | |
| " \"You will have the opportunity, put this on your calendar now.\",\n", | |
| " \"Thursday, September 22nd join World Class BBQ Champion, Tony Balay from Lonestar Smoke Rangers.\"\n", | |
| "]\n", | |
| "datapack: DataPack = DataPack()\n", | |
| "\n", | |
| "# Add sentences to the DataPack and annotate them\n", | |
| "for sentence in sentences:\n", | |
| " datapack.set_text(datapack.text + sentence)\n", | |
| " datapack.add_entry(\n", | |
| " Sentence(datapack, len(datapack.text) - len(sentence), len(datapack.text))\n", | |
| " )\n", | |
| " \n", | |
| "# Annotate the whole text with Article\n", | |
| "article: Article = Article(datapack, 0, len(datapack.text))\n", | |
| "article.language = \"en\"\n", | |
| "datapack.add_entry(article)\n", | |
| "\n", | |
| "for article in datapack.get(Article):\n", | |
| " print(f\"Article (language - {article.language}):\")\n", | |
| " for sentence in article.get(Sentence):\n", | |
| " print(sentence.text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "In our previous example, we have the following ontologies inheritance. Sentence and Article both inherit from Annotation which is used to represent text data. In Article, we have `langauge` field to represent the text language.\n", | |
| "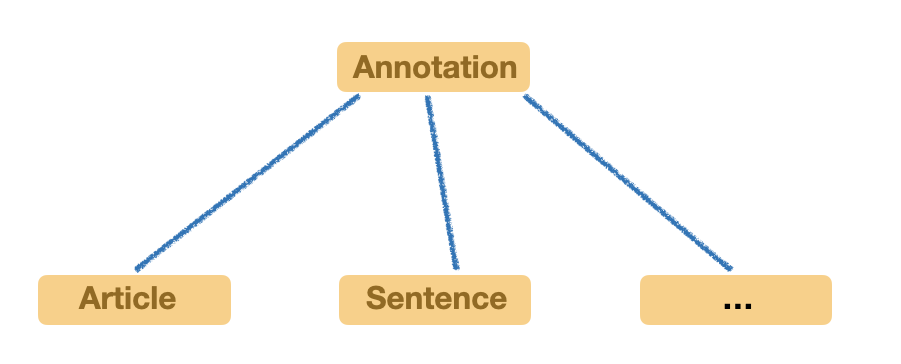" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
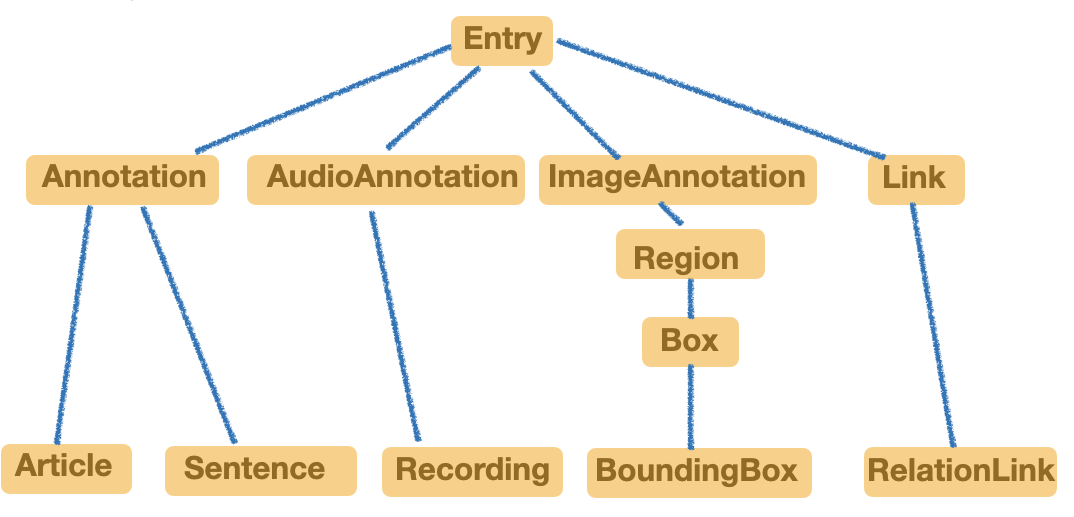
| "Actually, we not only supports text ontology but also audio, image and link which represent relationships between two entries.\n", | |
| "\n", | |
| "* `Annotation` is inherited by all text entries which usually has a span to retrieve partial text from the full text.\n", | |
| " * `Article`, as shown in our previous example, inherits annotation and contains `language` field to differentiate English and Germany. In the single DataPack example, English article has a span of English text in the DataPack. Likewise, Germany article has a span of Germany text in the DataPack. \n", | |
| " * `Sentence` in our example is used to break down article, and we pass sentences into MT pipeline.\n", | |
| "* `AudioAnnotation` is inherited by all audio entries which usually has an audio span to retrieve partial audio from the full audio.\n", | |
| " * `Recording` is an example subclass of `AudioAnnotation`, and it has extra `recording_class` field denoting the classes the audio belongs to.\n", | |
| "* `ImageAnnotation` is inherited by all image entries which usually has payload index pointing to a loaded image array.\n", | |
| " * `BoundingBox` is an example subclass of `ImageAnnotation`. As the picture shows, it has more inheritance relationships than other ontology classes due to the nature of CV objects. The advantage of forte ontology is that it supports complex inheritance, and users can inherit from existing ontology and add new ontology features for their needs.\n", | |
| "* `Link` is inherited by all link-like entries which has parent and child.\n", | |
| " * `RelationLink` is an example subclass of `Link`, and it has a class attribute specifying the relation type. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "## Create a Machine Translation Processor \n", | |
| "### Overview\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| "* **How to process data in pipeline**\n", | |
| " * How to perform sentence segmentation\n", | |
| " * How to annotate and query the data\n", | |
| " * **How to translate the input text with a pre-trained model**\n", | |
| " * How to manage multiple data objects\n", | |
| "* How to handle new practical requests\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* The basics of machine translation process\n", | |
| "* How to wrap a pre-trained machine translation model into a Forte processor\n", | |
| "\n", | |
| "Translation converts a sequence of text from one language to another. In this tutorial we will use `Huggingface` Transformer model to translate input data, which consists of several steps including subword tokenization, input embedding, model inference, decoding, etc." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "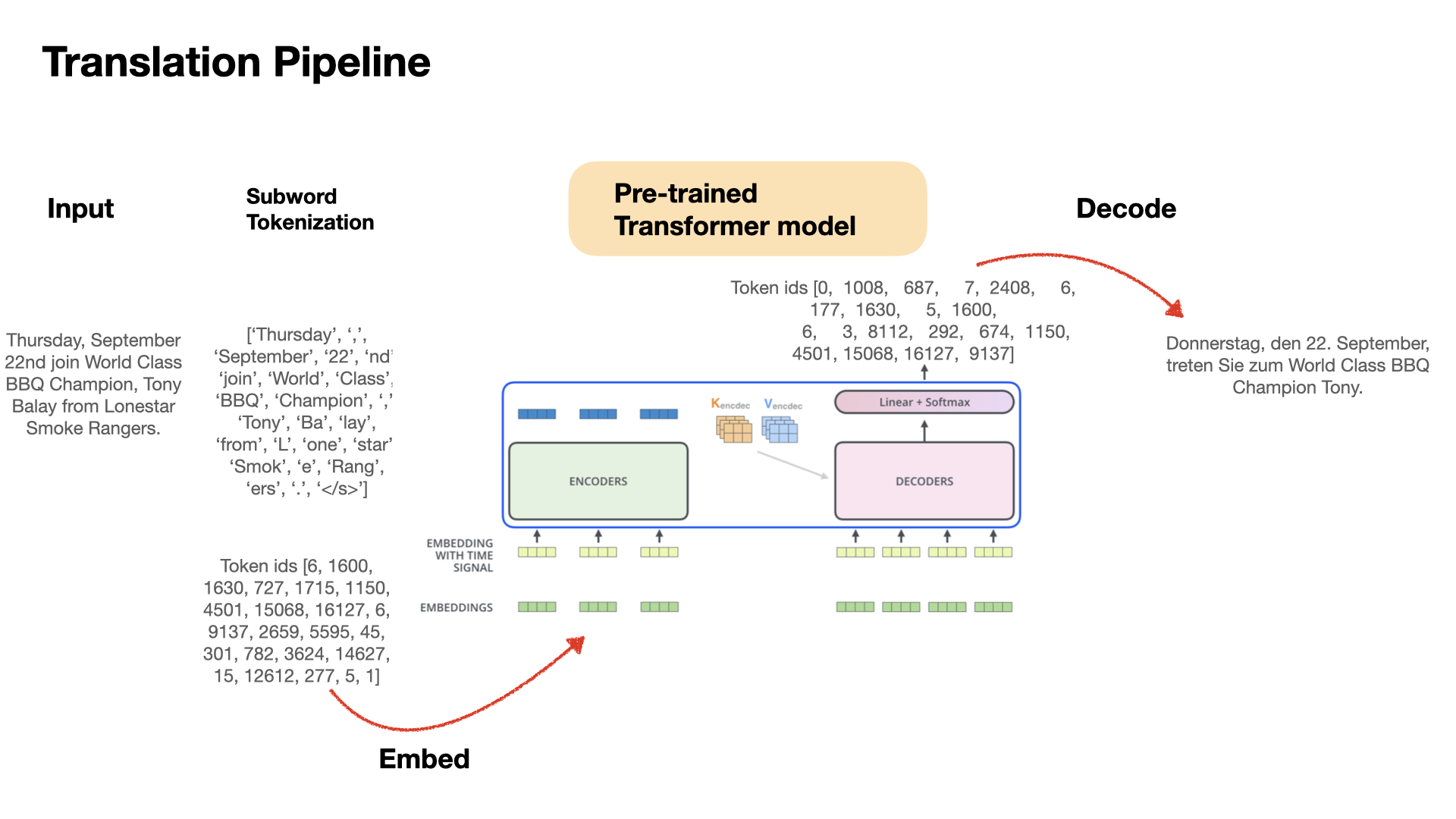" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "In Forte, we have a generic class `PackProcessor` that wraps model and inference-related components and behaviors to process `DataPack`. Therefore, we need to create a class that inherits the generic method from `PackProcessor`. Then we have a class definition \n", | |
| "`class MachineTranslationProcessor(PackProcessor)`." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "def_mt_processor" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from forte.data import DataPack\n", | |
| "from forte.data.readers import StringReader\n", | |
| "from forte.processors.base import PackProcessor\n", | |
| "from transformers import T5Tokenizer, T5ForConditionalGeneration\n", | |
| "\n", | |
| "class MachineTranslationProcessor(PackProcessor):\n", | |
| " \"\"\"\n", | |
| " Translate the input text and output to a file.\n", | |
| " \"\"\"\n", | |
| " def initialize(self, resources, configs):\n", | |
| " super().initialize(resources, configs)\n", | |
| "\n", | |
| " # Initialize the tokenizer and model\n", | |
| " model_name: str = self.configs.pretrained_model\n", | |
| " self.tokenizer = T5Tokenizer.from_pretrained(model_name)\n", | |
| " self.model = T5ForConditionalGeneration.from_pretrained(model_name)\n", | |
| " self.task_prefix = \"translate English to German: \"\n", | |
| " self.tokenizer.padding_side = \"left\"\n", | |
| " self.tokenizer.pad_token = self.tokenizer.eos_token\n", | |
| "\n", | |
| " def _process(self, input_pack: DataPack):\n", | |
| " # en2de machine translation \n", | |
| " inputs = self.tokenizer([\n", | |
| " self.task_prefix + sentence.text\n", | |
| " for sentence in input_pack.get(Sentence)\n", | |
| " ], return_tensors=\"pt\", padding=True)\n", | |
| "\n", | |
| " output_sequences = self.model.generate(\n", | |
| " input_ids=inputs[\"input_ids\"],\n", | |
| " attention_mask=inputs[\"attention_mask\"],\n", | |
| " do_sample=False,\n", | |
| " )\n", | |
| "\n", | |
| " output = ''.join(self.tokenizer.batch_decode(\n", | |
| " output_sequences, skip_special_tokens=True\n", | |
| " ))\n", | |
| " src_article: Article = Article(input_pack, 0, len(input_pack.text))\n", | |
| " src_article.language = \"en\"\n", | |
| "\n", | |
| " input_pack.set_text(input_pack.text + '\\n\\n' + output)\n", | |
| " tgt_article: Article = Article(input_pack, len(input_pack.text) - len(output), len(input_pack.text))\n", | |
| " tgt_article.language = \"de\"\n", | |
| "\n", | |
| " @classmethod\n", | |
| " def default_configs(cls):\n", | |
| " return {\n", | |
| " \"pretrained_model\": \"t5-small\"\n", | |
| " }" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "* Initialization of needed components:\n", | |
| " * Users need to consider initializing all needed NLP components for the inference task such as tokenizer and model.\n", | |
| " * Users also need to specify all configuration in `configs`, a dictionary-like object that specifies configurations of all components such as model name. \n", | |
| "\n", | |
| "* MT operations on datapack\n", | |
| " * After the initialization, we already have the needed NLP components. We need to consider several MT behaviors based on Forte DataPack.\n", | |
| "\n", | |
| " * Pre-process text data\n", | |
| " * retrieve text data from datapack (given that it already reads data from the data source).\n", | |
| " * since T5 has a better performance given a task prompt, we also want to include the prompt in our data.\n", | |
| "\n", | |
| " * Tokenization that transforms input text into sequences of tokens and token ids.\n", | |
| " * Generate output sequences from model.\n", | |
| " * Decode output token ids into sentences using the tokenizer.\n", | |
| "\n", | |
| "The generic method to process `DataPack` is `_process(self, input_pack: DataPack)`. It should tokenize the input text, use the model class to make an inference, decode the output token ids, and finally writes the output to a target file.\n", | |
| "\n", | |
| "Now we can add it into the pipeline and run the machine translation task." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_mt" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "input_string: str = ' '.join(sentences)\n", | |
| "pipeline: Pipeline = Pipeline[DataPack]()\n", | |
| "pipeline.set_reader(StringReader())\n", | |
| "pipeline.add(NLTKSentenceSegmenter())\n", | |
| "pipeline.add(MachineTranslationProcessor())\n", | |
| "pipeline.initialize()\n", | |
| "for datapack in pipeline.process_dataset([input_string]):\n", | |
| " for article in datapack.get(Article):\n", | |
| " print([f\"\\nArticle (language - {article.language}): {article.text}\"])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "#### Ontology in DataPack\n", | |
| "\n", | |
| "Here we provide an illustration so that users can better understand the internal storage of DataPack. As we can see, text data, sentence and articles, are stored as span in `Annotations`. Their text data can be easily and efficiently retrieved by their spans.\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "## A better way to store source and target text: MultiPack \n", | |
| "### Overview\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| "* **How to process data in pipeline**\n", | |
| " * How to perform sentence segmentation\n", | |
| " * How to annotate and query the data\n", | |
| " * How to translate the input text with a pre-trained model\n", | |
| " * **How to manage multiple data objects**\n", | |
| "* How to handle new practical requests\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* What is a MultiPack and why we need it\n", | |
| "* How to use a Multipack\n", | |
| "\n", | |
| "The above step outputs a DataPack which is good for holding data about one specific piece of text. A complicated pipeline like the one we are building now may need multiple DataPacks to be passed along the pipeline and this is where MultiPack can help. MultiPack manages a set of DataPacks that can be indexed by their names.\n", | |
| "\n", | |
| "`MultiPackBoxer` is a simple Forte processor that converts a DataPack into a MultiPack by making it the only DataPack in there. A name can be specified via the config. We use it to wrap DataPack that contains source sentence." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "def_mt_mpprocessor" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from forte.data import MultiPack\n", | |
| "from forte.processors.base import MultiPackProcessor\n", | |
| "from forte.data.caster import MultiPackBoxer\n", | |
| "\n", | |
| "class MachineTranslationMPProcessor(MultiPackProcessor):\n", | |
| " \"\"\"\n", | |
| " Translate the input text and output to a file.\n", | |
| " \"\"\"\n", | |
| " def initialize(self, resources, configs):\n", | |
| " super().initialize(resources, configs)\n", | |
| "\n", | |
| " # Initialize the tokenizer and model\n", | |
| " model_name: str = self.configs.pretrained_model\n", | |
| " self.tokenizer = T5Tokenizer.from_pretrained(model_name)\n", | |
| " self.model = T5ForConditionalGeneration.from_pretrained(model_name)\n", | |
| " self.task_prefix = \"translate English to German: \"\n", | |
| " self.tokenizer.padding_side = \"left\"\n", | |
| " self.tokenizer.pad_token = self.tokenizer.eos_token\n", | |
| "\n", | |
| " def _process(self, input_pack: MultiPack):\n", | |
| " source_pack: DataPack = input_pack.get_pack(\"source\")\n", | |
| " target_pack: DataPack = input_pack.add_pack(\"target\")\n", | |
| "\n", | |
| " # en2de machine translation \n", | |
| " inputs = self.tokenizer([\n", | |
| " self.task_prefix + sentence.text\n", | |
| " for sentence in source_pack.get(Sentence)\n", | |
| " ], return_tensors=\"pt\", padding=True)\n", | |
| "\n", | |
| " output_sequences = self.model.generate(\n", | |
| " input_ids=inputs[\"input_ids\"],\n", | |
| " attention_mask=inputs[\"attention_mask\"],\n", | |
| " do_sample=False,\n", | |
| " )\n", | |
| " \n", | |
| " # Annotate the source article\n", | |
| " src_article: Article = Article(source_pack, 0, len(source_pack.text))\n", | |
| " src_article.language = \"en\"\n", | |
| " \n", | |
| " # Annotate each sentence\n", | |
| " for output in self.tokenizer.batch_decode(\n", | |
| " output_sequences, skip_special_tokens=True\n", | |
| " ):\n", | |
| " target_pack.set_text(target_pack.text + output)\n", | |
| " text_length: int = len(target_pack.text)\n", | |
| " Sentence(target_pack, text_length - len(output), text_length)\n", | |
| " \n", | |
| " # Annotate the target article\n", | |
| " tgt_article: Article = Article(target_pack, 0, len(target_pack.text))\n", | |
| " tgt_article.language = \"de\"\n", | |
| "\n", | |
| " @classmethod\n", | |
| " def default_configs(cls):\n", | |
| " return {\n", | |
| " \"pretrained_model\": \"t5-small\",\n", | |
| " }" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
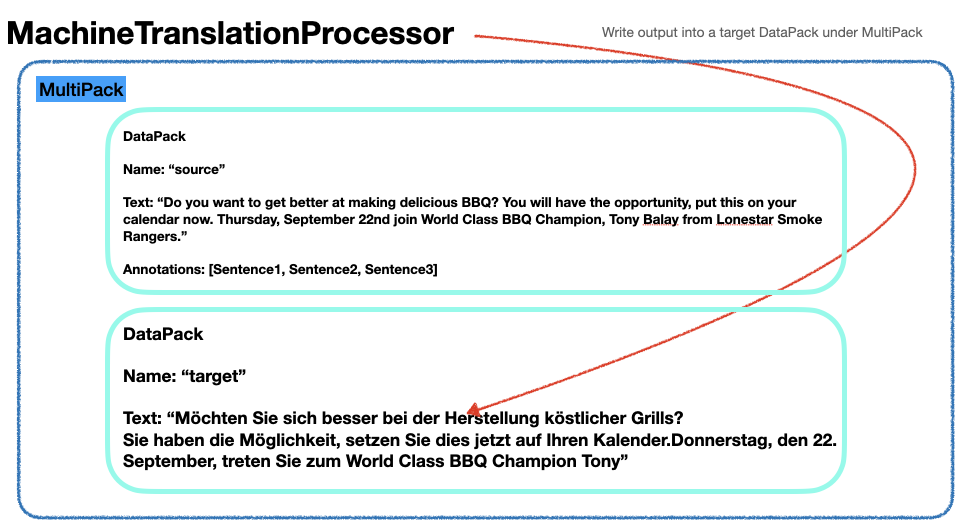
| "Then `MachineTranslationMPProcessor` writes the output sentence into a target DataPack." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "Now let's try to create a new pipeline that utilizes `MultiPack` to manage text in different languages." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_mpmt" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "nlp: Pipeline = Pipeline[DataPack]()\n", | |
| "nlp.set_reader(StringReader())\n", | |
| "nlp.add(NLTKSentenceSegmenter())\n", | |
| "nlp.add(MultiPackBoxer(), config={\"pack_name\": \"source\"})\n", | |
| "nlp.add(MachineTranslationMPProcessor(), config={\n", | |
| " \"pretrained_model\": \"t5-small\"\n", | |
| "})\n", | |
| "nlp.initialize()\n", | |
| "for multipack in nlp.process_dataset([input_string]):\n", | |
| " for pack_name in (\"source\", \"target\"):\n", | |
| " for article in multipack.get_pack(pack_name).get(Article):\n", | |
| " print(f\"\\nArticle (language - {article.language}): \")\n", | |
| " for sentence in article.get(Sentence):\n", | |
| " print(sentence.text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "#### Ontology in MultiPack\n", | |
| "\n", | |
| "For comparison, here is an illustration of the internal storage of MultiPack. We can see that MultiPack wraps one source DataPack and one target DataPack. Article spans are based on two separate DataPack text.\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "## New Requirement: Handle HTML data \n", | |
| "### Overview\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| "* How to process data in pipeline\n", | |
| "* **How to handle new practical requests**\n", | |
| " * **How to handle structures like HTML data**\n", | |
| " * **How to select a single data object for processing**\n", | |
| " * How to replace the translation model with remote translation services\n", | |
| " * How to save and load the pipeline\n", | |
| "\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* How to build a translation management system\n", | |
| "* How to preserve the structure like HTML in machine translation\n", | |
| "* How to select a specific DataPack from MultiPack for processing\n", | |
| "\n", | |
| "In the previous step, the input string is just a simple paragraph made up of several sentences. However, in many cases, we might need to handle data with structural information, such HTML or XML. When the input is a string of raw HTML data, the machine translation pipeline above may not work as expected:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_html_mtmp" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "html_input: str = \"\"\"\n", | |
| "<!DOCTYPE html>\n", | |
| "<html>\n", | |
| " <head><title>Beginners BBQ Class.</title></head>\n", | |
| " <body>\n", | |
| " <p>Do you want to get better at making delicious BBQ? You will have the opportunity, put this on your calendar now. Thursday, September 22nd join World Class BBQ Champion, Tony Balay from Lonestar Smoke Rangers.</p>\n", | |
| " </body>\n", | |
| "</html>\n", | |
| "\"\"\"\n", | |
| "nlp.initialize()\n", | |
| "for multipack in nlp.process_dataset([html_input]):\n", | |
| " print(\"Source Text: \" + multipack.get_pack(\"source\").text)\n", | |
| " print(\"\\nTarget Text: \" + multipack.get_pack(\"target\").text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "We can see that the original HTML structure is broken in the translated output.\n", | |
| "\n", | |
| "## How to preserve HTML tags/structures\n", | |
| "\n", | |
| "In order to handle structured data like HTML, we will need to update our current design of pipeline. Luckily, Forte pipelines are highly modular, we can simply insert two new processors without updating the previous pipeline.\n", | |
| "\n", | |
| "We first need a HTML cleaner to parse all the HTML tags from input string. Picture below shows the effect of tag remover.\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "After the translation is finished, we will also need to recover the HTML structure from the unstructured translation output. Picture below shows replace one source sentence with one target sentence given the target sentence is ready.\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "def_html_tag_processor" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "from forte.data import NameMatchSelector\n", | |
| "from forte.data.readers.html_reader import ForteHTMLParser\n", | |
| "\n", | |
| "class HTMLTagCleaner(MultiPackProcessor):\n", | |
| " \n", | |
| " def initialize(self, resources, configs):\n", | |
| " super().initialize(resources, configs)\n", | |
| " self._parser = ForteHTMLParser()\n", | |
| "\n", | |
| " def _process(self, input_pack: MultiPack):\n", | |
| " raw_pack: DataPack = input_pack.get_pack(\"raw\")\n", | |
| " source_pack: DataPack = input_pack.add_pack(\"source\")\n", | |
| " \n", | |
| " self._parser.feed(raw_pack.text)\n", | |
| " cleaned_text: str = raw_pack.text\n", | |
| " for span, _ in self._parser.spans:\n", | |
| " cleaned_text = cleaned_text.replace(\n", | |
| " raw_pack.text[span.begin:span.end], ''\n", | |
| " )\n", | |
| " source_pack.set_text(cleaned_text)\n", | |
| " \n", | |
| "class HTMLTagRecovery(MultiPackProcessor):\n", | |
| "\n", | |
| " def _process(self, input_pack: MultiPack):\n", | |
| " raw_pack: DataPack = input_pack.get_pack(\"raw\")\n", | |
| " source_pack: DataPack = input_pack.get_pack(\"source\")\n", | |
| " target_pack: DataPack = input_pack.get_pack(\"target\")\n", | |
| " result_pack: DataPack = input_pack.add_pack(\"result\")\n", | |
| " result_text: str = raw_pack.text\n", | |
| " for sent_src, sent_tgt in zip(source_pack.get(Sentence), target_pack.get(Sentence)):\n", | |
| " result_text = result_text.replace(sent_src.text, sent_tgt.text)\n", | |
| " result_pack.set_text(result_text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "Now we are able to create a translation management system by inserting the two processors introduced above into our previous machine translation pipeline." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_html_tag" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "# Pipeline with HTML handling\n", | |
| "pipeline: Pipeline = Pipeline[DataPack]()\n", | |
| "pipeline.set_reader(StringReader())\n", | |
| "pipeline.add(MultiPackBoxer(), config={\"pack_name\": \"raw\"})\n", | |
| "pipeline.add(HTMLTagCleaner())\n", | |
| "pipeline.add(\n", | |
| " NLTKSentenceSegmenter(),\n", | |
| " selector=NameMatchSelector(),\n", | |
| " selector_config={\"select_name\": \"source\"}\n", | |
| ")\n", | |
| "pipeline.add(MachineTranslationMPProcessor(), config={\n", | |
| " \"pretrained_model\": \"t5-small\"\n", | |
| "})\n", | |
| "pipeline.add(HTMLTagRecovery())\n", | |
| "\n", | |
| "pipeline.initialize()\n", | |
| "for multipack in pipeline.process_dataset([html_input]):\n", | |
| " print(multipack.get_pack(\"raw\").text)\n", | |
| " print(multipack.get_pack(\"result\").text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "### Selector\n", | |
| "In the code snippet above, we utilize a `NameMatchSelector` to select one specific DataPack from the MultiPack based on its reference name `select_name`. This allows `NLTKSentenceSegmenter` to process only the specified DataPack.\n", | |
| "\n", | |
| "## Replace our MT model with online translation API\n", | |
| "### Overview\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| "* How to process data in pipeline\n", | |
| "* **How to handle new practical requests**\n", | |
| " * How to handle structures like HTML data\n", | |
| " * **How to replace the translation model with remote translation services**\n", | |
| " * How to save and load the pipeline\n", | |
| "\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* How to use a different translation service\n", | |
| "\n", | |
| "Forte also allows us to update the translation model and integrate it seamlessly to the original pipeline. For example, if we want to offload the translation task to an online service, all we need to do is to update the translation processor. There is no need to change other components in the pipeline." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "# You can get your own API key by following the instructions in https://docs.microsoft.com/en-us/azure/cognitive-services/translator/\n", | |
| "api_key = input(\"Enter your API key here:\")" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "def_online_mt_processor" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "import requests\n", | |
| "import uuid\n", | |
| "\n", | |
| "class OnlineMachineTranslationMPProcessor(MultiPackProcessor):\n", | |
| " \"\"\"\n", | |
| " Translate the input text and output to a file use online translator api.\n", | |
| " \"\"\"\n", | |
| " def initialize(self, resources, configs):\n", | |
| " super().initialize(resources, configs)\n", | |
| " self.url = configs.endpoint + configs.path\n", | |
| " self.from_lang = configs.from_lang\n", | |
| " self.to_lang = configs.to_lang\n", | |
| " self.subscription_key = configs.subscription_key\n", | |
| " self.subscription_region = configs.subscription_region\n", | |
| "\n", | |
| " def _process(self, input_pack: MultiPack):\n", | |
| " source_pack: DataPack = input_pack.get_pack(\"source\")\n", | |
| " target_pack: DataPack = input_pack.add_pack(\"target\")\n", | |
| " \n", | |
| " params = {\n", | |
| " 'api-version': '3.0',\n", | |
| " 'from': 'en',\n", | |
| " 'to': ['de']\n", | |
| " }\n", | |
| " # Build request\n", | |
| " headers = {\n", | |
| " 'Ocp-Apim-Subscription-Key': self.subscription_key,\n", | |
| " 'Ocp-Apim-Subscription-Region': self.subscription_region,\n", | |
| " 'Content-type': 'application/json',\n", | |
| " 'X-ClientTraceId': str(uuid.uuid4())\n", | |
| " }\n", | |
| " # You can pass more than one object in body.\n", | |
| " body = [{\n", | |
| " 'text': source_pack.text\n", | |
| " }]\n", | |
| "\n", | |
| " request = requests.post(self.url, params=params, headers=headers, json=body)\n", | |
| " \n", | |
| " result = request.json()\n", | |
| " target_pack.set_text(\"\".join(\n", | |
| " [trans['text'] for trans in result[0][\"translations\"]]\n", | |
| " )\n", | |
| " )\n", | |
| "\n", | |
| " @classmethod\n", | |
| " def default_configs(cls):\n", | |
| " return {\n", | |
| " \"from_lang\" : 'en',\n", | |
| " \"to_lang\": 'de',\n", | |
| " \"endpoint\" : 'https://api.cognitive.microsofttranslator.com/',\n", | |
| " \"path\" : '/translate',\n", | |
| " \"subscription_key\": None,\n", | |
| " \"subscription_region\" : \"westus2\",\n", | |
| " 'X-ClientTraceId': str(uuid.uuid4())\n", | |
| " }" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_online_mt" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "nlp: Pipeline = Pipeline[DataPack]()\n", | |
| "nlp.set_reader(StringReader())\n", | |
| "nlp.add(NLTKSentenceSegmenter())\n", | |
| "nlp.add(MultiPackBoxer(), config={\"pack_name\": \"source\"})\n", | |
| "nlp.add(OnlineMachineTranslationMPProcessor(), config={\n", | |
| " \"from_lang\" : 'en',\n", | |
| " \"to_lang\": 'de',\n", | |
| " \"endpoint\" : 'https://api.cognitive.microsofttranslator.com/',\n", | |
| " \"path\" : '/translate',\n", | |
| " \"subscription_key\": api_key,\n", | |
| " \"subscription_region\" : \"westus2\",\n", | |
| " 'X-ClientTraceId': str(uuid.uuid4())\n", | |
| "})\n", | |
| "nlp.initialize()\n", | |
| "for multipack in nlp.process_dataset([input_string]):\n", | |
| " print(\"Source Text: \" + multipack.get_pack(\"source\").text)\n", | |
| " print(\"\\nTarget Text: \" + multipack.get_pack(\"target\").text)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "## Save the whole pipeline with save() \n", | |
| "### Overview\n", | |
| "\n", | |
| "* How to read data from source\n", | |
| "* How to process data in pipeline\n", | |
| "* **How to handle new practical requests**\n", | |
| " * How to handle structures like HTML data\n", | |
| " * How to replace the translation model with remote translation services\n", | |
| " * **How to save and load the pipeline**\n", | |
| "\n", | |
| "\n", | |
| "In this section, you will learn\n", | |
| "* How to export and import a Forte pipeline\n", | |
| "\n", | |
| "Forte also allow us to save the pipeline into disk. It serializes the whole pipeline and generates an intermediate representation, which can be loaded later maybe on a different machine." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_pipeline_save" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "import os\n", | |
| "save_path: str = os.path.join(os.path.dirname(os.path.abspath('')), \"pipeline.yml\")\n", | |
| "nlp.save(save_path)\n", | |
| "\n", | |
| "with open(save_path, 'r') as f:\n", | |
| " print(f.read())" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| }, | |
| "source": [ | |
| "Now that the pipeline is saved, we can try to re-load the pipeline to see if it still functions as expect." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "tags": [ | |
| "example_pipeline_load" | |
| ] | |
| }, | |
| "outputs": [ | |
| ], | |
| "source": [ | |
| "new_nlp: Pipeline = Pipeline()\n", | |
| "new_nlp.init_from_config_path(save_path)\n", | |
| "new_nlp.initialize()\n", | |
| "for multipack in new_nlp.process_dataset([input_string]):\n", | |
| " print(\"Source Text: \" + multipack.get_pack(\"source\").text)\n", | |
| " print(\"\\nTarget Text: \" + multipack.get_pack(\"target\").text)" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "celltoolbar": "Tags", | |
| "interpreter": { | |
| "hash": "ee55265381053916df67dbe70c8ab208ce4688dabc900b19af91d526111b9fa4" | |
| }, | |
| "kernelspec": { | |
| "display_name": "Python 3 (ipykernel)", | |
| "language": "python", | |
| "name": "python3" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.7.11" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 2 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment