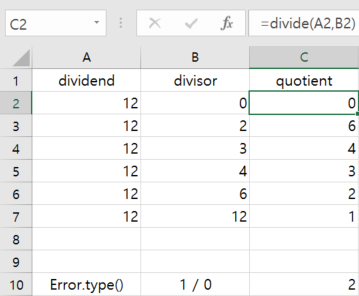
Now I'm enrolled in Applied Data Science Capstone Course offered by IBM in Coursera.
It requests me to commit my assignment through Git, so I tried it first.
Actullay, all the previous commits of mine were done through web.
It was so stupid way to use this smart site, Github.
But, this is the time to say Good-bye to my stupid era.
I'm reborn now as a man who know use the 'real' Git!
This great page provides so helpful guide to install Git, SSH setup-concerned stuff, create and clone a repository,