Last active
May 4, 2017 14:01
-
-
Save lbourbon/6df6fc84016347ee721814044eea9c5a to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "source": [ | |
| "Agora que começa a brincadeira, o primeiro passo é importar o numpy, usando o famoso:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 1, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import numpy as np" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# CRIANDO ARRAYS" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Existem várias formas de criar arrays, pode ser através do método np.array(), usando uma lista ou tupla do python:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 2, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "arr = [-2. 4.3 7. 9. ]\n", | |
| "arr2 = [ 8. -5. 0. 3.2]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "arr = np.array([-2, 4.3, 7, 9])\n", | |
| "\n", | |
| "my_tuple = (8, -5, 0, 3.2)\n", | |
| "arr2 = np.array(my_tuple)\n", | |
| "\n", | |
| "print('arr = ', arr)\n", | |
| "print('arr2 = ', arr2)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Usando o método arange (similar ao range do python)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 3, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[0 1 2 3 4 5 6 7 8 9] \n", | |
| "\n", | |
| "[[ 1 3 5 7]\n", | |
| " [ 9 11 13 15]\n", | |
| " [17 19 21 23]\n", | |
| " [25 27 29 31]]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "arr = np.arange(10)\n", | |
| "print(arr, '\\n')\n", | |
| "\n", | |
| "# Lembrando que arrays podem ter mais de uma dimensão\n", | |
| "# cria uma array começando em 2 e até 32 (sem incluí-lo), pulando cada dois números\n", | |
| "\n", | |
| "arr2 = np.arange(1, 32, 2).reshape(4, 4) # reshape muda o formato da array - nesse caso de (16) para (4x4)\n", | |
| "print(arr2)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Usando os métodos 'zeros()' e 'ones()' para criar arrays de 0 e 1, respectivamente:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 4, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[ 0. 0. 0. 0. 0. 0. 0. 0.]\n", | |
| "[[ 1. 1. 1.]\n", | |
| " [ 1. 1. 1.]\n", | |
| " [ 1. 1. 1.]\n", | |
| " [ 1. 1. 1.]]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "arr = np.zeros(8) # array contendo 8 'zeros'\n", | |
| "print (arr)\n", | |
| "\n", | |
| "arr2 = np.ones((4,3)) # array contendo 12 'uns', no formato 4 x 3\n", | |
| "print(arr2)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 5, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[ 1. 12. 23. 34. 45. 56. 67. 78. 89. 100.] \n", | |
| "\n", | |
| "[[ 6.95324061e-312 6.95304310e-312 6.95305659e-312 9.79597118e-315]\n", | |
| " [ 9.79598683e-315 9.79597260e-315 6.95280442e-312 6.95324061e-312]\n", | |
| " [ 6.95281148e-312 6.95324131e-312 6.95304310e-312 6.95286325e-312]\n", | |
| " [ 9.79597197e-315 9.79597165e-315 6.95280442e-312 6.95324131e-312]\n", | |
| " [ 6.95281148e-312 6.95314450e-312 6.95304310e-312 6.95305620e-312]\n", | |
| " [ 9.79597165e-315 0.00000000e+000 0.00000000e+000 0.00000000e+000]] \n", | |
| "\n", | |
| "[[ 1. 0. 0. 0.]\n", | |
| " [ 0. 1. 0. 0.]\n", | |
| " [ 0. 0. 1. 0.]\n", | |
| " [ 0. 0. 0. 1.]]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# Método linspace()\n", | |
| "\n", | |
| "arr = np.linspace(1, 100, 10) # de 1 a 100, contendo 10 valores\n", | |
| "print(arr, '\\n')\n", | |
| "\n", | |
| "\n", | |
| "# Array vazia com o método empty()\n", | |
| "\n", | |
| "arr2 = np.empty((6,4)) # normalmente a saída é lixo de memória ou zeros\n", | |
| "print(arr2, '\\n')\n", | |
| "\n", | |
| "\n", | |
| "# Np.Eye\n", | |
| "\n", | |
| "arr3 = np.eye(4) # eye cria uma array de duas dimensões com 1 na da diagnoal e 0 nos outros elementos\n", | |
| "print(arr3)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## ATRIBUTOS DAS ARRAYS" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Existem vários atributos, mas o três principais são .shape , .size e .dtype" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 6, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| ".shape: (10,)\n", | |
| ".size: 10\n", | |
| ".dtype: float64\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "arr = np.linspace(.5, 50, 10)\n", | |
| "\n", | |
| "print('.shape: ', arr.shape) # imprime o formato da array\n", | |
| "print('.size: ', arr.size) # imprime o tamanho da array\n", | |
| "print('.dtype: ', arr.dtype) # imprime o tipo de dado dos elementos" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Outros atributos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 7, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| ".ndim: 1\n", | |
| ".itemsize: 10\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "print('.ndim: ', arr.ndim) # número de dimensões\n", | |
| "print('.itemsize: ', arr.size) # tamanho de cada elemento em bytes" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## MÉTODOS" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Existem inúmeros métodos que nos ajudam a trabalhar com numpy arrays, vou mostrar os mais usados:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 8, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "array original: [1 2 3 4 5 6 7 8 9] \n", | |
| "\n", | |
| "formato 3x3: \n", | |
| " [[1 2 3]\n", | |
| " [4 5 6]\n", | |
| " [7 8 9]] \n", | |
| "\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "arr = np.arange(1,10)\n", | |
| "print('array original: ', arr, '\\n')\n", | |
| "\n", | |
| "# Como já vimos 'reshape()' muda o formato da array, MAS o número de elementos dos dois formatos tem que coincidir, exemplo:\n", | |
| "arr2 = arr.reshape((3,3))\n", | |
| "print ('formato 3x3: \\n' , arr2, '\\n')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 9, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "9" | |
| ] | |
| }, | |
| "execution_count": 9, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "arr.max() # retorna o valor máximo" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 10, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "8\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "True" | |
| ] | |
| }, | |
| "execution_count": 10, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "print(arr.argmax()) # retorna o índice que contém o valor máximo\n", | |
| "arr[8] == arr[arr.argmax()]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 11, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "1" | |
| ] | |
| }, | |
| "execution_count": 11, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "arr.min() # retorna o mínimo" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 12, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "0\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "True" | |
| ] | |
| }, | |
| "execution_count": 12, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "print(arr.argmin()) # retorna o índice que contém o valor máximo\n", | |
| "arr[0] == arr[arr.argmin()]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 13, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "5.0" | |
| ] | |
| }, | |
| "execution_count": 13, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "arr.mean() # retorna a média" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 14, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "2.5819888974716112" | |
| ] | |
| }, | |
| "execution_count": 14, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "arr.std() # retorna o desvio padrão" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 15, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "45" | |
| ] | |
| }, | |
| "execution_count": 15, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "arr.sum() #retorna a soma de todos os elementos da array" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 16, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 1. , 1.41421356, 1.73205081, 2. , 2.23606798,\n", | |
| " 2.44948974, 2.64575131, 2.82842712, 3. ])" | |
| ] | |
| }, | |
| "execution_count": 16, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "### FUNÇÕES UNIVERSAIS ###\n", | |
| "\n", | |
| "np.sqrt(arr) # retorna um array com a raiz quadrada de cada elemento" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 17, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427,\n", | |
| " -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])" | |
| ] | |
| }, | |
| "execution_count": 17, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "np.sin(arr) # retorna um array com o seno de cada elemento" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 18, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 0.54030231, -0.41614684, -0.9899925 , -0.65364362, 0.28366219,\n", | |
| " 0.96017029, 0.75390225, -0.14550003, -0.91113026])" | |
| ] | |
| }, | |
| "execution_count": 18, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "np.cos(arr) # retorna um array com o cosseno de cada elemento" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 19, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 2.71828183e+00, 7.38905610e+00, 2.00855369e+01,\n", | |
| " 5.45981500e+01, 1.48413159e+02, 4.03428793e+02,\n", | |
| " 1.09663316e+03, 2.98095799e+03, 8.10308393e+03])" | |
| ] | |
| }, | |
| "execution_count": 19, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "np.exp(arr) # retorna um array com o exponencial cada elemento (e^x)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## OPERAÇÕES BÁSICAS" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "É bem fácil realizar operações matemáticas com arrays " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 20, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| " A: [0 1 2 3 4 5 6 7 8 9] \n", | |
| " B: [10 13 16 19 22 25 28 31 34 37]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# vamos criar as arrays A e B para fazer operações com elas\n", | |
| "\n", | |
| "A = np.arange(10)\n", | |
| "B = np.arange(10,38,3)\n", | |
| "\n", | |
| "print (' A: ', A, '\\n', 'B: ', B)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 21, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "somar: [10 14 18 22 26 30 34 38 42 46]\n", | |
| "subtrair: [-10 -12 -14 -16 -18 -20 -22 -24 -26 -28]\n", | |
| "dividir: [ 0. 0.07692308 0.125 0.15789474 0.18181818 0.2\n", | |
| " 0.21428571 0.22580645 0.23529412 0.24324324]\n", | |
| "multiplicar: [ 0 13 32 57 88 125 168 217 272 333]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "somar = A + B\n", | |
| "subtrair = A - B\n", | |
| "dividir = A / B\n", | |
| "multiplicar = A * B\n", | |
| "\n", | |
| "print('somar: ', somar )\n", | |
| "print('subtrair: ', subtrair )\n", | |
| "print('dividir: ', dividir )\n", | |
| "print('multiplicar: ', multiplicar)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "#### Perceba que se você dividir por zero, numpy não vai dar erro (o código vai rodar), porém vai emitir uma advertência!" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 22, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stderr", | |
| "output_type": "stream", | |
| "text": [ | |
| "C:\\Users\\lbour\\Anaconda3\\envs\\k35\\lib\\site-packages\\ipykernel\\__main__.py:1: RuntimeWarning: divide by zero encountered in true_divide\n", | |
| " if __name__ == '__main__':\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ inf, 13. , 8. , 6.33333333,\n", | |
| " 5.5 , 5. , 4.66666667, 4.42857143,\n", | |
| " 4.25 , 4.11111111])" | |
| ] | |
| }, | |
| "execution_count": 22, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "B/A # a array A contém um zero como primeiro elemento" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "BROADCAST = transmissão" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 23, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 0, 100, 200, 300, 400, 500, 600, 700, 800, 900])" | |
| ] | |
| }, | |
| "execution_count": 23, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "''' Você pode fazer operações envolvendo arrays e um único elemento, dessa forma numpy itera a operação \n", | |
| "do elemento único com todos os componentes da array, exemplo: ''' \n", | |
| "\n", | |
| "A * 100 # retorna um array com a multiplicação de todos elementos da array por 100" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## INDEXAÇÃO E FATIAMENTO (SLICING)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "O acesso de elementos de uma array, funciona de forma similar ao das listas do Python:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 24, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 1, 4, 9, 16, 25, 36, 49, 64, 81])" | |
| ] | |
| }, | |
| "execution_count": 24, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "# criar uma array com o quadrado dos números de 1 a 10\n", | |
| "arr = np.arange(1, 10) **2\n", | |
| "arr" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 25, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "1º elemento: 1\n", | |
| "5º elemento: 25\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# acessando o primeiro elemento\n", | |
| "print('1º elemento: ', arr[0]) # lembrar que índice começa do 0\n", | |
| "\n", | |
| "# acessando o quinto elemento\n", | |
| "print ('5º elemento: ', arr[4]) # O quinto elemento é acessado pelo índice 4" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 26, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[[ 1 4 9]\n", | |
| " [16 25 36]\n", | |
| " [49 64 81]] \n", | |
| "\n", | |
| "Acessando o elemento 25: 25\n", | |
| "Acessando o elemento 25: 25\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "81" | |
| ] | |
| }, | |
| "execution_count": 26, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "# Em um array de duas dimensões (ou mais) existem duas formas de acessar o índice:\n", | |
| "\n", | |
| "arr = arr.reshape((3,3))\n", | |
| "print (arr, '\\n')\n", | |
| "\n", | |
| "# Usando colchetes duplos [][]\n", | |
| "print ('Acessando o elemento 25: ', arr[1][1])\n", | |
| "\n", | |
| "# Ou minha preferência pessoal - separando índices por vírgula\n", | |
| "print ('Acessando o elemento 25: ', arr[1,1])\n", | |
| "\n", | |
| "# acessando o último elemento usando o -1\n", | |
| "arr[-1, -1] " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 27, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[[ 1 4 9]\n", | |
| " [16 25 36]] \n", | |
| "\n", | |
| "[[ 1 4 9]\n", | |
| " [16 25 36]]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# Para acessar fatias de elementos, usamos o slice [i:i], exemplo\n", | |
| "\n", | |
| "# linha: acessar da linha de índice 0 a linha de índice 2 (excluindo esta) = [0:2]\n", | |
| "# coluna: acessar da coluna de índice 0 a coluna de 3 (excluindo esta) = [0:3] - no nosso caso, todas as colunas\n", | |
| "print(arr[0:2 , 0:3],'\\n')\n", | |
| "\n", | |
| "# outra forma de obter o mesmo resultado é usando [:], que pega todos os elementos\n", | |
| "print(arr[0:2 , 0:3])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 28, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([[ 4, 9],\n", | |
| " [25, 36],\n", | |
| " [64, 81]])" | |
| ] | |
| }, | |
| "execution_count": 28, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "# Podemos criar uma nova array com slice de outra\n", | |
| "\n", | |
| "arr2 = arr[ : , 1:3]\n", | |
| "arr2" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 29, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([[ 1, 4, 9],\n", | |
| " [-99, -99, -99],\n", | |
| " [ 49, 64, 81]])" | |
| ] | |
| }, | |
| "execution_count": 29, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "# Podemor atribuir novos elementos a nossa array, usando slice\n", | |
| "\n", | |
| "arr[1:2, :] = -99\n", | |
| "arr" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Uma imagem vale mais que mil palavras:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "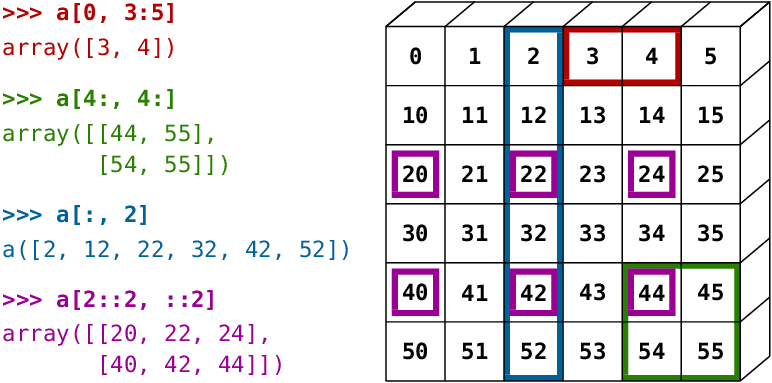" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "#### SELEÇÃO CONDICIONAL:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Uma forma interessante de selecionar elementos baseado em alguma condição" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 30, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "A: [0 1 2 3 4 5 6 7 8 9]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "A = np.arange(10)\n", | |
| "print ('A: ', A)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 31, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([False, False, False, False, False, False, True, True, True, True], dtype=bool)" | |
| ] | |
| }, | |
| "execution_count": 31, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "A > 5 # retorna uma array de variáveis booleanas de acordo com a condição" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 32, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Também odemos criar uma array a partir dessa condição\n", | |
| "B = A > 5" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 33, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[6 7 8 9]\n", | |
| "[6 7 8 9]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# Isso nos dá 2 opções para fazer seleção condicional, passando a condição ou passando o array como índice \n", | |
| "\n", | |
| "print (A [A > 5])\n", | |
| "\n", | |
| "print (A [B])\n", | |
| "\n", | |
| "# em ambos os casos só retorna os valores que admitem essa condição " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## NÚMEROS ALEATÓRIOS:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "np.random" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 34, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[ 0.57523608 0.04945749] \n", | |
| "\n", | |
| "[ 0.63409923 0.46116619 0.07086467 0.27315467]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# random ou random_sample cria floats aleatórios entre 0 e 1\n", | |
| "\n", | |
| "print (np.random.random(2), '\\n') # passar a quantidade de números desejada\n", | |
| "print(np.random.random_sample(4)) " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 35, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[ 0.21341662 -0.04578248] \n", | |
| "\n", | |
| "[-1.10114593 1.04906643 0.22603859 1.36423983 -1.02432287]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# randn cria números aleatórios entre -1 e 1 (distribuição normal)\n", | |
| "\n", | |
| "print (np.random.randn(2), '\\n') # passar a quantidade de números desejada\n", | |
| "print (np.random.randn(5)) " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 36, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[2 1 1 1] \n", | |
| "\n", | |
| "[14 13 15 16 17 16 16 15]\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "# randint cria números inteiros aleatórios\n", | |
| "\n", | |
| "print (np.random.randint(1,5,4), '\\n') # passar menor valor, maior valor e a quantidade de números desejada\n", | |
| "print (np.random.randint(10,20,8)) " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Para criar números aleatórios em outro intervalo, basta usar multiplicação e soma para atingir o objetivo" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 37, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 0.51082241, 4.31755943, 1.90554176, 2.54231171, 0.65662266,\n", | |
| " 3.36074459, 1.52641151, 3.93203519, 3.44842574, 2.43359316])" | |
| ] | |
| }, | |
| "execution_count": 37, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "# 10 números aleatórios entre 0 e 5\n", | |
| "5 * np.random.random(10)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 38, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([ 7.59145368, 9.2303235 , 8.22579528, 8.15308105, 7.74361074,\n", | |
| " 5.66208778, 7.28898889, 9.87313444, 5.27853908, 9.72449187])" | |
| ] | |
| }, | |
| "execution_count": 38, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "# 10 números aleatórios entre 5 e 10\n", | |
| "5 * np.random.random(10) + 5" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "anaconda-cloud": {}, | |
| "kernelspec": { | |
| "display_name": "Python [conda env:k35]", | |
| "language": "python", | |
| "name": "conda-env-k35-py" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.5.2" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 1 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment