Created
July 2, 2023 03:04
-
-
Save maazghani/0770ef273eab5b6042c8c9012c2ec20c to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "source": [], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| } | |
| }, | |
| "id": "f6c6bde9" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "# KafkaStreams, KSQL, and KDB on Kubernetes\n", | |
| "This notebook will provide a comprehensive analysis of how KafkaStreams, specifically KSQL and KDB, running on Kubernetes, can be used to create a data pipeline for analyzing filesystem events for anomalous behavior. I will provide examples, diagrams, and code snippets to illustrate this process. \n", | |
| "\n", | |
| "**Goal**: _Convince Pavan that this architecture can replace the Flink -> Clickhouse for real-time alerting functionality. Long-term still in clickhouse._" | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| } | |
| }, | |
| "id": "3efec9c6-de0a-4f28-bd55-8208cd9e0b8a" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "## Introduction to KafkaStreams, KSQL, and KDB\n", | |
| "Before I dive into the specifics of our data pipeline, let's first understand the key components involved:\n", | |
| "\n", | |
| "- **KafkaStreams**: A client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology.\n", | |
| "\n", | |
| "- **KSQL**: An open-source, Apache 2.0 licensed streaming SQL engine for Apache Kafka. KSQL provides a simple and completely interactive SQL interface for processing data in Kafka. You no longer need to write code in a programming language such as Java or Python. KSQL is scalable, elastic, fault-tolerant, and it supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.\n", | |
| "\n", | |
| "- **KDB**: A high-performance column-store database from Kx Systems that is widely used in financial services for time-series analytics. KDB+ is known for its performance and stability, making it suitable for large-scale data analytics.\n", | |
| "\n", | |
| "- **Kubernetes**: An open-source platform designed to automate deploying, scaling, and operating application containers. With Kubernetes, you can quickly and efficiently respond to customer demand:\n", | |
| " - Deploy your applications quickly and predictably.\n", | |
| " - Scale your applications on the fly.\n", | |
| " - Roll out new features seamlessly.\n", | |
| " - Limit hardware usage to required resources only." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "51d3f2b6-dee8-46d0-944f-3c60a9fc1dad" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "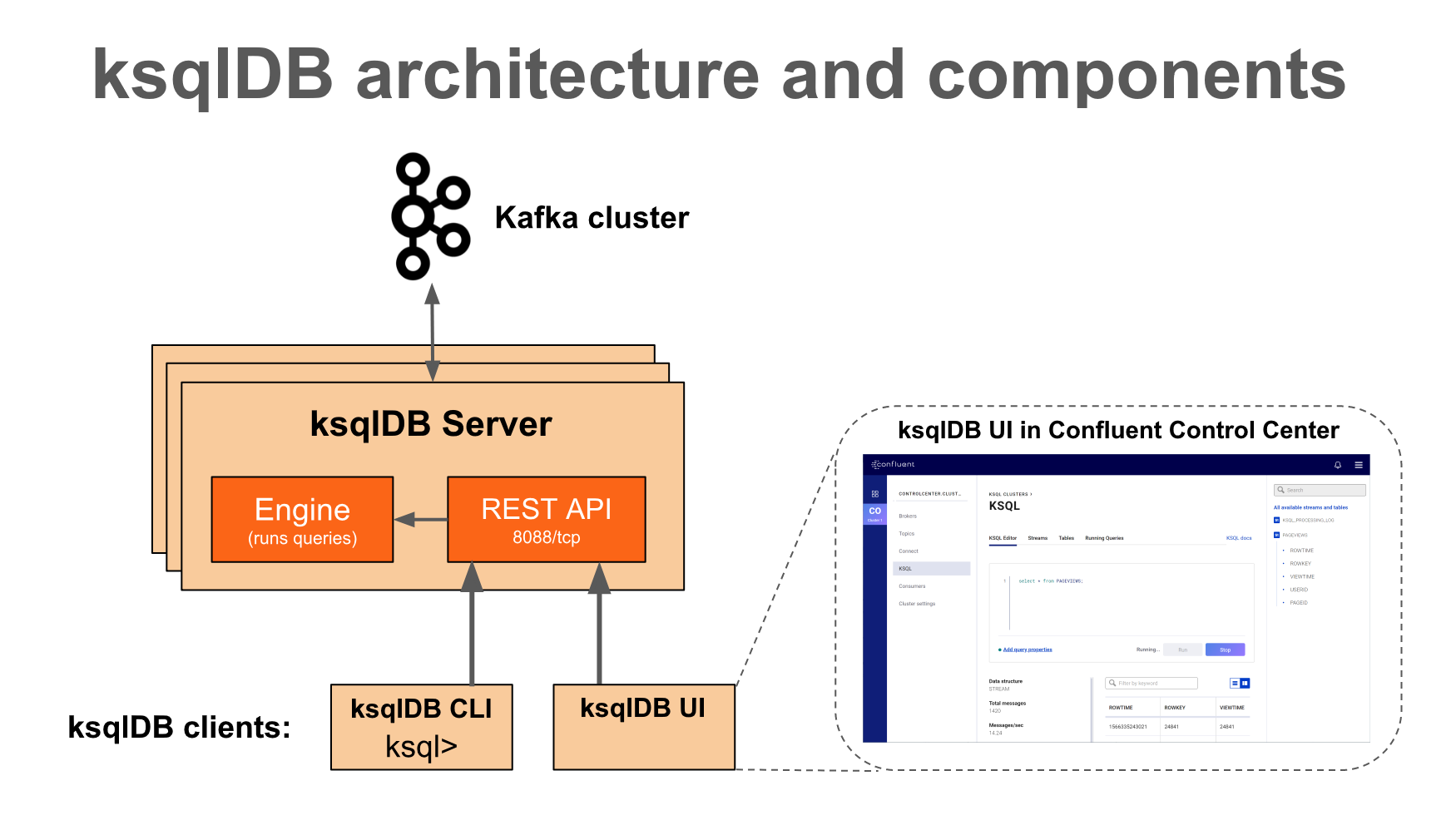\n", | |
| "\n", | |
| "The above diagram shows the architecture of KSQL. It consists of a KSQL server that runs KSQL queries and a KSQL CLI that is used to issue queries to the KSQL server. The KSQL server interacts with the Kafka cluster to read from and write to Kafka topics. The KSQL server also uses a Kafka topic to store the state of its queries." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "c601adc3-f885-427b-a1d9-9ab7c9e3a075" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "## Why KafkaStreams, KSQL, and KDB on Kubernetes for Data Pipelines?\n", | |
| "Now that we understand the key components, let's discuss why this combination is particularly effective for creating data pipelines, especially for analyzing filesystem events for anomalous behavior.\n", | |
| "\n", | |
| "- **Real-time Processing**: KafkaStreams and KSQL allow for real-time data processing. This is crucial when monitoring filesystem events where timely detection of anomalies can prevent potential data breaches or system failures.\n", | |
| "\n", | |
| "- **Scalability**: Both Kafka and Kubernetes are designed to be highly scalable. Kafka can handle high volumes of real-time data, and Kubernetes can easily scale your applications based on demand. This is particularly useful when dealing with large filesystems or multiple systems.\n", | |
| "\n", | |
| "- **Fault-Tolerance**: Kafka and Kubernetes both provide fault-tolerance capabilities. In Kafka, data is replicated across multiple nodes to prevent data loss. Kubernetes provides self-healing capabilities such as auto-restarting, re-scheduling, and replicating nodes.\n", | |
| "\n", | |
| "- **Streamlined SQL-like Interface**: KSQL provides a simple SQL-like interface for processing Kafka streams. This makes it accessible to users who are familiar with SQL but not necessarily with more complex stream processing concepts.\n", | |
| "\n", | |
| "- **High-Performance Analytics**: KDB+ is known for its high-performance analytics capabilities, particularly with time-series data. This makes it suitable for analyzing filesystem events, which are inherently time-series data.\n", | |
| "\n", | |
| "- **Microservices Architecture**: The combination of Kafka and Kubernetes lends itself well to a microservices architecture. This allows for the development of small, loosely coupled services, which can be developed, deployed, and scaled independently." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "ba9e605a-7321-46e5-a3d5-d0247df226ed" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "\n", | |
| "\n", | |
| "The above diagram shows the lifecycle of a KSQL query. When a query is issued, it is first parsed and analyzed to ensure it is valid. Then, the query is optimized and a physical plan is created for its execution. The query is then executed and the results are returned to the user." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "3f417897-5f9f-4c6a-9e3b-58855b0a3a6c" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "## Example: Filesystem Events Data Pipeline with KafkaStreams, KSQL, KDB, and Kubernetes\n", | |
| "Now, let's walk through an example of how we can set up a data pipeline for analyzing filesystem events using these technologies. We'll start by setting up our Kafka cluster and Kubernetes environment, then we'll create Kafka topics for our filesystem events, set up KSQL for stream processing, and finally, use KDB for data analysis.\n", | |
| "\n", | |
| "Please note that the following sections are conceptual and for illustrative purposes. They do not contain executable code." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "f7f532cd-6543-41c2-b977-0fe3c13ad2fc" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "### Step 1: Setting Up Kafka Cluster and Kubernetes Environment\n", | |
| "First, we need to set up our Kafka cluster and Kubernetes environment. We can use a managed service like Confluent Cloud for Kafka and a cloud provider like Google Cloud, AWS, or Azure for Kubernetes. Once we have these set up, we can deploy our Kafka cluster on our Kubernetes environment.\n", | |
| "\n", | |
| "We'll also need to set up our Kafka producers and consumers. The producers will be responsible for sending filesystem events to Kafka, and the consumers will be responsible for processing these events. We can set up our producers and consumers as separate services in our Kubernetes environment." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "49953804-ce82-4116-acf7-267971ca3535" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "### Step 2: Creating Kafka Topics for Filesystem Events\n", | |
| "Next, we need to create Kafka topics for our filesystem events. Each topic will correspond to a specific type of filesystem event, such as file creation, file deletion, file modification, etc. Our Kafka producers will send filesystem events to the corresponding topics, and our Kafka consumers will subscribe to these topics to process the events.\n", | |
| "\n", | |
| "For example, we might have a topic for file creation events, another for file deletion events, and so on. The events sent to these topics will contain details about the event, such as the file path, the timestamp of the event, the user who performed the action, etc." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "f1cee5bf-5749-498a-8412-cdc87a9512d0" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "### Step 3: Setting Up KSQL for Stream Processing\n", | |
| "Once we have our Kafka topics set up, we can use KSQL to process the filesystem events in real-time. We can create KSQL streams and tables from our Kafka topics, and then use KSQL queries to filter, transform, and aggregate the data.\n", | |
| "\n", | |
| "For example, we might create a KSQL stream from our file creation events topic, and then write a KSQL query to filter out events where the file size is greater than a certain threshold. This could help us detect potential anomalies, such as unusually large files being created, which could indicate a potential security threat." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "0f74429e-780c-48cb-a6c8-afbff896264a" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "### Step 4: Using KDB for Data Analysis\n", | |
| "After processing our filesystem events with KSQL, we can use KDB for further analysis. We can load our processed data into a KDB database and then use q, the query language for KDB, to perform complex analytics.\n", | |
| "\n", | |
| "For example, we might use q to calculate the average file size for each user, find the user with the most file modifications, or detect patterns in file access times. These insights could help us identify potential anomalies or suspicious behavior." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "9191a83a-43ff-4e99-bd16-6e2509486593" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "## Data Pipeline Diagram\n", | |
| "The following diagram illustrates the data pipeline we've discussed. It shows the flow of data from the filesystem events, through the Kafka topics, KSQL processing, and KDB analysis, and finally to the detection of anomalous behavior.\n", | |
| "\n", | |
| "Please note that this is a conceptual diagram and does not represent the actual architecture of a real-world data pipeline.\n", | |
| "\n", | |
| "```\n", | |
| "Filesystem Events --> Kafka Producers --> Kafka Topics --> Kafka Consumers --> KSQL Processing --> KDB Analysis --> Anomaly Detection\n", | |
| "```\n", | |
| "In this pipeline:\n", | |
| "\n", | |
| "- Filesystem events are captured and sent to Kafka producers.\n", | |
| "- Kafka producers send the events to the appropriate Kafka topics.\n", | |
| "- Kafka consumers subscribe to the Kafka topics and process the events.\n", | |
| "- The processed events are sent to KSQL for further processing.\n", | |
| "- The KSQL-processed events are loaded into a KDB database for analysis.\n", | |
| "- The results of the KDB analysis are used to detect anomalous behavior." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "7c222c56-7386-4f71-bbee-21abfdfc9836" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "## KSQL Functions\n", | |
| "\n", | |
| "### String Functions\n", | |
| "\n", | |
| "1. `CONCAT(string1, string2)`: Concatenates string1 and string2.\n", | |
| "2. `LCASE(string)`: Converts a string to lowercase.\n", | |
| "3. `LENGTH(string)`: Gets the length of a string.\n", | |
| "4. `SUBSTRING(string, start, end)`: Extracts a substring from a string.\n", | |
| "5. `TRIM(string)`: Removes leading and trailing whitespace from a string.\n", | |
| "6. `UCASE(string)`: Converts a string to uppercase.\n", | |
| "\n", | |
| "### Numeric Functions\n", | |
| "\n", | |
| "1. `ABS(number)`: Gets the absolute value of a number.\n", | |
| "2. `CEIL(number)`: Rounds a number up to the nearest integer.\n", | |
| "3. `FLOOR(number)`: Rounds a number down to the nearest integer.\n", | |
| "4. `ROUND(number)`: Rounds a number to the nearest integer.\n", | |
| "\n", | |
| "### Date and Time Functions\n", | |
| "\n", | |
| "1. `NOW()`: Gets the current date and time.\n", | |
| "2. `UNIX_TIMESTAMP()`: Gets the current Unix timestamp.\n", | |
| "3. `TIMESTAMPTOSTRING(timestamp, 'yyyy-MM-dd HH:mm:ss')`: Converts a Unix timestamp to a string.\n", | |
| "4. `STRINGTOTIMESTAMP(text, 'yyyy-MM-dd HH:mm:ss')`: Converts a string to a Unix timestamp.\n", | |
| "\n", | |
| "### Array Functions\n", | |
| "\n", | |
| "1. `ARRAY_LENGTH(array)`: Gets the length of an array.\n", | |
| "2. `ARRAY_CONTAINS(array, value)`: Checks if an array contains a value.\n", | |
| "\n", | |
| "### Map Functions\n", | |
| "\n", | |
| "1. `MAP_KEYS(map)`: Gets the keys of a map.\n", | |
| "2. `MAP_VALUES(map)`: Gets the values of a map." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "069f9f22-2164-495c-99a5-44ff7340ffbf" | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "source": [ | |
| "\n", | |
| "\n", | |
| "The above diagram shows the KSQL processing log. The processing log provides a record of all the processing steps a KSQL server takes to execute a query. This includes information about the source and sink topics of the query, the query itself, and any errors that occurred during the processing of the query." | |
| ], | |
| "metadata": { | |
| "noteable": { | |
| "cell_type": "markdown" | |
| }, | |
| "noteable-chatgpt": { | |
| "version": "0.16.0" | |
| } | |
| }, | |
| "id": "76f32197-4672-4029-8f37-9ea8e0fc9c4e" | |
| } | |
| ], | |
| "metadata": { | |
| "selected_hardware_size": "small", | |
| "noteable": { | |
| "last_transaction_id": "96d13a5a-5655-428d-8cf2-6705d17391a2", | |
| "last_delta_id": "96d13a5a-5655-428d-8cf2-6705d17391a2" | |
| }, | |
| "nteract": { | |
| "version": "noteable@2.9.0" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 5 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment