-
-
Save mohammedkhalilia/72c3261734d7715094089bdf4de74b4a to your computer and use it in GitHub Desktop.
train_flat_arabic_ner.ipynb
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "nbformat": 4, | |
| "nbformat_minor": 0, | |
| "metadata": { | |
| "colab": { | |
| "provenance": [], | |
| "authorship_tag": "ABX9TyPMhCxt1IEvsn94kp3EylPp", | |
| "include_colab_link": true | |
| }, | |
| "kernelspec": { | |
| "name": "python3", | |
| "display_name": "Python 3" | |
| }, | |
| "language_info": { | |
| "name": "python" | |
| }, | |
| "accelerator": "GPU", | |
| "gpuClass": "standard" | |
| }, | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "view-in-github", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "<a href=\"https://colab.research.google.com/gist/mohammedkhalilia/72c3261734d7715094089bdf4de74b4a/train_flat_arabic_ner.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "id": "BtmgHNnvrbNI" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Verify that you have the GPU recognized\n", | |
| "!nvidia-smi" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "source": [ | |
| "# Install dependencies\n", | |
| "!pip uninstall torch torchtext torchvision torchvision torchdata torchaudio\n", | |
| "!pip install torch==1.13.0\n", | |
| "!pip install transformers==4.24.0\n", | |
| "!pip install torchtext==0.14.0\n", | |
| "!pip install torchvision==0.14.0\n", | |
| "!pip install torchdata==0.5.1\n", | |
| "!pip install seqeval==1.2.2" | |
| ], | |
| "metadata": { | |
| "id": "dtO91IXuujsZ" | |
| }, | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "source": [ | |
| "# Remove existing package and clone again from Github\n", | |
| "!rm -rf /content/ArabicNER\n", | |
| "!git clone https://github.com/SinaLab/ArabicNER.git" | |
| ], | |
| "metadata": { | |
| "id": "jLHHpnFXr7-K" | |
| }, | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "source": [ | |
| "# Add the ArabicNER package to the system path\n", | |
| "import sys\n", | |
| "import argparse\n", | |
| "sys.path.append('/content/ArabicNER/')" | |
| ], | |
| "metadata": { | |
| "id": "o4EvIlcrssU6" | |
| }, | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "source": [ | |
| "# Import train function\n", | |
| "from arabiner.bin.train import main as train" | |
| ], | |
| "metadata": { | |
| "id": "-rM-8p4nsztp" | |
| }, | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "source": [ | |
| "# Setup the model arguments\n", | |
| "args_dict = {\n", | |
| " # Model output path to save artifacts and model predictions\n", | |
| " \"output_path\": \"/content/output/\",\n", | |
| "\n", | |
| " # train/test/validation data paths\n", | |
| " \"train_path\": \"/content/ArabicNER/data/train.txt\",\n", | |
| " \"test_path\": \"/content/ArabicNER/data/test.txt\",\n", | |
| " \"val_path\": \"/content/ArabicNER/data/val.txt\",\n", | |
| "\n", | |
| " # seed for randomization\n", | |
| " \"seed\": 1,\n", | |
| "\n", | |
| " \"batch_size\": 8,\n", | |
| "\n", | |
| " # Nmber of workers for the dataloader\n", | |
| " \"num_workers\": 1,\n", | |
| "\n", | |
| " # GPU/device Ids to train model on\n", | |
| " # For two GPUs use [0, 1]\n", | |
| " # For three GPUs use [0, 1, 2], etc.\n", | |
| " \"gpus\": [0],\n", | |
| "\n", | |
| " # Overwrite data in output_path directory specified above\n", | |
| " \"overwrite\": True,\n", | |
| "\n", | |
| " # How often to print the logs in terms of number of steps\n", | |
| " \"log_interval\": 10,\n", | |
| "\n", | |
| " # Data configuration\n", | |
| " # Here we specify the dataset class and there are two options:\n", | |
| " # arabiner.data.datasets.DefaultDataset: for flat NER\n", | |
| " # arabiner.data.datasets.NestedTagsDataset: for nested NER\n", | |
| " #\n", | |
| " # kwargs: keyword arguments to the dataset class\n", | |
| " # This notebook used the DefaultDataset for flat NER\n", | |
| " \"data_config\": {\n", | |
| " \"fn\": \"arabiner.data.datasets.DefaultDataset\",\n", | |
| " \"kwargs\": {\"max_seq_len\": 512}\n", | |
| " },\n", | |
| "\n", | |
| " # Neural net configuration\n", | |
| " # There are two NNs:\n", | |
| " # arabiner.nn.BertSeqTagger: flat NER tagger\n", | |
| " # arabiner.nn.BertNestedTagger: nested NER tagger\n", | |
| " #\n", | |
| " # kwargs: keyword arguments to the NN\n", | |
| " # This notebook uses BertSeqTagger for flat NER tagging\n", | |
| " \"network_config\": {\n", | |
| " \"fn\": \"arabiner.nn.BertSeqTagger\",\n", | |
| " \"kwargs\": {\"dropout\": 0.1, \"bert_model\": \"aubmindlab/bert-base-arabertv2\"}\n", | |
| " },\n", | |
| "\n", | |
| " # Model trainer configuration\n", | |
| " #\n", | |
| " # arabiner.trainers.BertTrainer: for flat NER training\n", | |
| " # arabiner.trainers.BertNestedTrainer: for nested NER training\n", | |
| " #\n", | |
| " # kwargs: keyword arguments to arabiner.trainers.BertTrainer\n", | |
| " # additional arguments you can pass includes\n", | |
| " # - clip: for gradient clpping\n", | |
| " # - patience: number of epochs for early termination\n", | |
| " # This notebook uses BertTrainer for fat NER training\n", | |
| " \"trainer_config\": {\n", | |
| " \"fn\": \"arabiner.trainers.BertTrainer\",\n", | |
| " \"kwargs\": {\"max_epochs\": 50}\n", | |
| " },\n", | |
| "\n", | |
| " # Optimizer configuration\n", | |
| " # Our experiments use torch.optim.AdamW, however, you are free to pass\n", | |
| " # any other optmizers such as torch.optim.Adam or torch.optim.SGD\n", | |
| " # lr: learning rate\n", | |
| " # kwargs: keyword arguments to torch.optim.AdamW or whatever optimizer you use\n", | |
| " #\n", | |
| " # Additional optimizers can be found here:\n", | |
| " # https://pytorch.org/docs/stable/optim.html\n", | |
| " \"optimizer\": {\n", | |
| " \"fn\": \"torch.optim.AdamW\",\n", | |
| " \"kwargs\": {\"lr\": 0.0001}\n", | |
| " },\n", | |
| "\n", | |
| " # Learning rate scheduler configuration\n", | |
| " # You can pass a learning scheduler such as torch.optim.lr_scheduler.StepLR\n", | |
| " # kwargs: keyword arguments to torch.optim.AdamW or whatever scheduler you use\n", | |
| " #\n", | |
| " # Additional schedulers can be found here:\n", | |
| " # https://pytorch.org/docs/stable/optim.html\n", | |
| " \"lr_scheduler\": {\n", | |
| " \"fn\": \"torch.optim.lr_scheduler.ExponentialLR\",\n", | |
| " \"kwargs\": {\"gamma\": 1}\n", | |
| " },\n", | |
| "\n", | |
| " # Loss function configuration\n", | |
| " # We use cross entropy loss\n", | |
| " # kwargs: keyword arguments to torch.nn.CrossEntropyLoss or whatever loss function you use\n", | |
| " \"loss\": {\n", | |
| " \"fn\": \"torch.nn.CrossEntropyLoss\",\n", | |
| " \"kwargs\": {}\n", | |
| " }\n", | |
| "}\n", | |
| "\n", | |
| "# Convert args dictionary to argparse namespace\n", | |
| "args = argparse.Namespace()\n", | |
| "args.__dict__ = args_dict" | |
| ], | |
| "metadata": { | |
| "id": "UqqvY1fXtZpD" | |
| }, | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "source": [ | |
| "# Start training the model\n", | |
| "train(args)" | |
| ], | |
| "metadata": { | |
| "id": "EJQMuAC8taZB" | |
| }, | |
| "execution_count": null, | |
| "outputs": [] | |
| } | |
| ] | |
| } |
I have not tried MARBERTv2 and ARBERTv2.
Can you let me know what error are you getting with either of those two models?
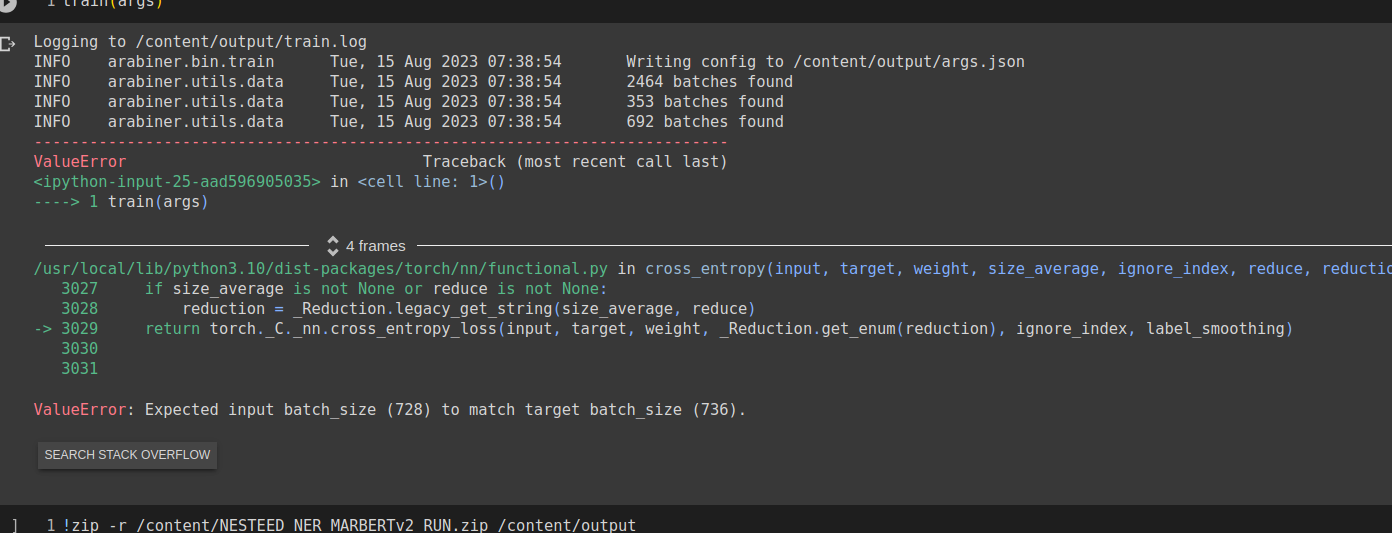
Can you change the batch size? Try higher or lower value and let me know.
used small batch size and higher one and it didn't work.
maybe the tokenizer ignores some non arabic words?
even though arabertv2 which has small vocab size work fine on the data.
You can increase the "patience" parameter to a higher value.
I think the default is 5.
…On Wed, Apr 24, 2024 at 9:12 AM NahedAbdelgaber ***@***.***> wrote:
***@***.**** commented on this gist.
------------------------------
Hello Dr. Mohammed,
During training, I got Early termination triggered after Epoch 6, Do you
have an idea why I am getting this? and How can I train it for longer?
Thank you, I appreciate your help!
—
Reply to this email directly, view it on GitHub
<https://gist.github.com/mohammedkhalilia/72c3261734d7715094089bdf4de74b4a#gistcomment-5034818>
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ABORGPUSVW4V3EMJNBOQHR3Y67KWLBFKMF2HI4TJMJ2XIZLTSKBKK5TBNR2WLJDUOJ2WLJDOMFWWLO3UNBZGKYLEL5YGC4TUNFRWS4DBNZ2F6YLDORUXM2LUPGBKK5TBNR2WLJDHNFZXJJDOMFWWLK3UNBZGKYLEL52HS4DFVRZXKYTKMVRXIX3UPFYGLK2HNFZXIQ3PNVWWK3TUUZ2G64DJMNZZDAVEOR4XAZNEM5UXG5FFOZQWY5LFVEYTEMJRGU3TKMJTU52HE2LHM5SXFJTDOJSWC5DF>
.
You are receiving this email because you authored the thread.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>
.
--
MK
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Hello Dr. Mohammed, thanks for the notebook.
I just noticed that it does not work with other models such as MARBERTv2 and ARBERTv2.
Maybe you can look into that when you have some time.
Thanks