This Notebook is the source code for the published blog article here.
@rmoff / January 11, 2017
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# Getting Started with Spark Streaming with Python and Kafka" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Last month I wrote a [series of articles](https://www.rittmanmead.com/blog/2016/12/etl-offload-with-spark-and-amazon-emr-part-5/) in which I looked at the use of Spark for performing data transformation and manipulation. This was in the context of replatforming an existing Oracle-based ETL and datawarehouse solution onto cheaper and more elastic alternatives. The processing that I wrote was very much batch-focussed; read a set of files from block storage ('disk'), process and enrich the data, and write it back to block storage.\n", | |
| "\n", | |
| "In this article I am going to look at [Spark Streaming](http://spark.apache.org/streaming/). This is one of several libraries that the [Spark platform](http://spark.apache.org) provides (others include [Spark SQL](http://spark.apache.org/sql/), [Spark MLlib](http://spark.apache.org/mllib/), and [Spark GraphX](http://spark.apache.org/graphx/)). Spark Streaming provides a way of processing \"unbounded\" data - commonly referred to as \"streaming\" data. It does this by breaking it up into microbatches, and supporting windowing capabilities for processing across multiple batches. \n", | |
| "\n", | |
| "\n", | |
| "\n", | |
| "([img src](http://spark.apache.org/docs/latest/streaming-programming-guide.html))\n", | |
| "\n", | |
| "The use-case I'm going to put together is - almost inevitably for a generic unbounded data example - using Twitter, read from a Kafka topic. We'll start simply, counting the number of tweets per user within each batch and doing some very simple string manipulations. After that we'll see how to do the same but over a period of time (windowing). In the next blog we'll extend this further into a more useful example, still based on Twitter but demonstrating how to satisfy some real-world requirements in the processing.\n", | |
| "\n", | |
| "I developed all of this code using Jupyter Notebooks. I've written before about how awesome notebooks are (as well as Jupyter, there's Apache Zeppelin). As well as providing a superb development environment in which the results of code can be seen, Jupyter gives the option to download a Notebook to [Markdown]](https://en.wikipedia.org/wiki/Markdown), on which this blog runs - so in fact what you're reading here comes natively from the notebook in which I developed the code. Pretty cool.\n", | |
| "\n", | |
| " \n", | |
| "\n", | |
| "I used the docker image [all-spark-notebook](https://github.com/jupyter/docker-stacks/tree/master/all-spark-notebook) to provide both Jupyter and the Spark runtime environment. The only external aspect was a Kafka cluster that I had already, with tweets from the live Twitter feed on a kafka topic imaginatively called `twitter`. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Preparing the Environment\n", | |
| "\n", | |
| "We need to make sure that the packages we're going to use are available to Spark. Instead of downloading `jar` files and worrying about paths, we can instead use the `--packages` option and specify the group/artifact/version based on what's available on [Maven](http://search.maven.org/#search%7Cgav%7C1%7Cg%3A%22org.apache.spark%22%20AND%20a%3A%22spark-streaming-kafka-0-8-assembly_2.11%22) and Spark will handle the downloading. We specify `PYSPARK_SUBMIT_ARGS` for this to get passed correctly when executing from within Jupyter. \n", | |
| "\n", | |
| "To run the code in Jupyter, you can put the cursor in each cell and press Shift-Enter to run it each cell at a time -- or you can use menu option `Kernel` -> `Restart & Run All`. When a cell is executing you'll see a `[*]` next to it, and once the execution is complete this changes to `[y]` where `y` is execution step number. Any output from that step will be shown immediately below it.\n", | |
| "\n", | |
| "To run the code standalone, you would download the `.py` from Jupyter, and execute it using \n", | |
| "\n", | |
| " /usr/local/spark-2.0.2-bin-hadoop2.7/bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.2 spark_code.py" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 1, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import os\n", | |
| "os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.2 pyspark-shell'" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Import dependencies\n", | |
| "\n", | |
| "We need to import the necessary pySpark modules for Spark, Spark Streaming, and Spark Streaming with Kafka. We also need the python `json` module for parsing the inbound twitter data" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 2, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Spark\n", | |
| "from pyspark import SparkContext\n", | |
| "# Spark Streaming\n", | |
| "from pyspark.streaming import StreamingContext\n", | |
| "# Kafka\n", | |
| "from pyspark.streaming.kafka import KafkaUtils\n", | |
| "# json parsing\n", | |
| "import json" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Create Spark context\n", | |
| "\n", | |
| "The Spark context is the primary object under which everything else is called. The `setLogLevel` call is optional, but saves a lot of noise on stdout that otherwise can swamp the actual outputs from the job. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 3, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "sc = SparkContext(appName=\"PythonSparkStreamingKafka_RM_01\")\n", | |
| "sc.setLogLevel(\"WARN\")" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Create Streaming Context\n", | |
| "\n", | |
| "We pass the Spark context (from above) along with the batch duration (here, 60 seconds). \n", | |
| "\n", | |
| "See the [API reference](http://spark.apache.org/docs/latest/api/python/pyspark.streaming.html#pyspark.streaming.StreamingContext) and [programming guide](http://spark.apache.org/docs/latest/streaming-programming-guide.html#initializing-streamingcontext) for more details. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 4, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "ssc = StreamingContext(sc, 60)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Connect to Kafka\n", | |
| "\n", | |
| "Using the native Spark Streaming Kafka capabilities, we use the streaming context from above to connect to our Kafka cluster. The topic connected to is `twitter`, from consumer group `spark-streaming`. The latter is an arbitrary name that can be changed as required. \n", | |
| "\n", | |
| "For more information see the [documentation](http://spark.apache.org/docs/latest/streaming-kafka-0-8-integration.html)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 5, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "kafkaStream = KafkaUtils.createStream(ssc, 'cdh57-01-node-01.moffatt.me:2181', 'spark-streaming', {'twitter':1})" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Message Processing" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Parse the inbound message as json\n", | |
| "\n", | |
| "The inbound stream is a [`DStream`](http://spark.apache.org/docs/2.0.0/api/python/pyspark.streaming.html#pyspark.streaming.DStream), which supports various built-in [transformations](http://spark.apache.org/docs/latest/streaming-programming-guide.html#transformations-on-dstreams) such as `map` which is used here to parse the inbound messages from their native JSON format. \n", | |
| "\n", | |
| "Note that this will fail horribly if the inbound message _isn't_ valid JSON. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 6, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "parsed = kafkaStream.map(lambda v: json.loads(v[1]))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Count number of tweets in the batch\n", | |
| "\n", | |
| "The [`DStream`](http://spark.apache.org/docs/2.0.0/api/python/pyspark.streaming.html#pyspark.streaming.DStream) object provides native functions to count the number of messages in the batch, and to print them to the output: \n", | |
| "\n", | |
| "* [`count`](http://spark.apache.org/docs/2.0.0/api/python/pyspark.streaming.html#pyspark.streaming.DStream.count)\n", | |
| "* [`pprint`](http://spark.apache.org/docs/2.0.0/api/python/pyspark.streaming.html#pyspark.streaming.DStream.pprint) \n", | |
| "\n", | |
| "We use the `map` function to add in some text explaining the value printed. \n", | |
| "\n", | |
| "_Note that nothing gets written to output from the Spark Streaming context and descendent objects until the Spark Streaming Context is started, which happens later in the code_\n", | |
| "\n", | |
| "_*`pprint` by default only prints the first 10 values*_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 7, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "parsed.count().map(lambda x:'Tweets in this batch: %s' % x).pprint()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "source": [ | |
| "Note that if you jump ahead and try to use Windowing at this point, for example to count the number of tweets in the last hour using the `countByWindow` function, it'll fail. This is because we've not set up the streaming context with a checkpoint directory yet. You'll get the error: `java.lang.IllegalArgumentException: requirement failed: The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().`. See later on in the blog for details about how to do this. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Extract Author name from each tweet\n", | |
| "\n", | |
| "Tweets come through in a JSON structure, of which you can see an [example here](https://gist.github.com/rmoff/3968605712f437a1f37e7be52129cade). We're going to analyse tweets by author, which is accessible in the json structure at `user.screen_name`. \n", | |
| "\n", | |
| "The [`lambda`](https://pythonconquerstheuniverse.wordpress.com/2011/08/29/lambda_tutorial/) anonymous function is used to apply the `map` to each RDD within the DStream. The result is a DStream holding just the author's screenname for each tweet in the original DStream." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 8, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "authors_dstream = parsed.map(lambda tweet: tweet['user']['screen_name'])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Count the number of tweets per author\n", | |
| "\n", | |
| "With our authors DStream, we can now count them using the `countByValue` function. This is conceptually the same as this quasi-SQL statement: \n", | |
| "\n", | |
| " SELECT AUTHOR, COUNT(*)\n", | |
| " FROM DSTREAM\n", | |
| " GROUP BY AUTHOR\n", | |
| "\n", | |
| "_Using `countByValue` is a more legible way of doing the same thing that you'll see done in tutorials elsewhere with a map / reduceBy. _" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 9, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "author_counts = authors_dstream.countByValue()\n", | |
| "author_counts.pprint()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Sort the author count\n", | |
| "\n", | |
| "If you try and use the `sortBy` function directly against the DStream you get an error: \n", | |
| "\n", | |
| " 'TransformedDStream' object has no attribute 'sortBy'\n", | |
| " \n", | |
| "This is because sort is not a built-in [DStream](http://spark.apache.org/docs/2.0.0/api/python/pyspark.streaming.html#pyspark.streaming.DStream) function, we use the [`transform`](http://spark.apache.org/docs/latest/streaming-programming-guide.html#transform-operation) function to access [`sortBy`](http://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD.sortBy) from pySpark. \n", | |
| "\n", | |
| "To use `sortBy` you specify a lambda function to define the sort order. Here we're going to do it based on first the author name (index 0 of the RDD), and then of that order, by number of tweets (index 1 of the RDD). You'll note these index references being used in the `sortBy` lambda function `x[0]` and `x[1]`. Thanks to [user6910411](http://stackoverflow.com/a/41485394/350613) on StackOverflow for a better way of doing this. \n", | |
| "\n", | |
| "_Here I'm using `\\` as line continuation characters to make the code more legible._" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 10, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "author_counts_sorted_dstream = author_counts.transform(\\\n", | |
| " (lambda foo:foo\\\n", | |
| " .sortBy(lambda x:( -x[1]))))\n", | |
| "# .sortBy(lambda x:(x[0].lower(), -x[1]))\\\n", | |
| "# ))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 11, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "author_counts_sorted_dstream.pprint()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Get top 5 authors by tweet count\n", | |
| "\n", | |
| "To display just the top five authors, based on number of tweets in the batch period, we'll using the [`take`](http://spark.apache.org/docs/2.0.2/api/python/pyspark.html#pyspark.RDD.take) function. My first attempt at this failed with: \n", | |
| "\n", | |
| " AttributeError: 'list' object has no attribute '_jrdd'\n", | |
| " \n", | |
| "Per my [woes on StackOverflow](http://stackoverflow.com/questions/41483746/transformed-dstream-in-pyspark-gives-error-when-pprint-called-on-it) a `parallelize` is necessary to return the values into a DStream form." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 12, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "top_five_authors = author_counts_sorted_dstream.transform\\\n", | |
| " (lambda rdd:sc.parallelize(rdd.take(5)))\n", | |
| "top_five_authors.pprint()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Get authors with more than one tweet, or whose username starts with 'a'\n", | |
| "\n", | |
| "Let's get a bit more fancy now - filtering the resulting list of authors to only show the ones who have tweeted more than once in our batch window, or -arbitrarily- whose screenname begins with `rm`.." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 13, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "filtered_authors = author_counts.filter(lambda x:\\\n", | |
| " x[1]>1 \\\n", | |
| " or \\\n", | |
| " x[0].lower().startswith('rm'))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "We'll print this list of authors matching the criteria, sorted by the number of tweets. Note how the sort is being done inline to the calling of the `pprint` function. Assigning variables and then `pprint`ing them as I've done above is only done for clarity. It also makes sense if you're going to subsequently reuse the derived stream variable (such as with the `author_counts` in this code). " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 14, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "filtered_authors.transform\\\n", | |
| " (lambda rdd:rdd\\\n", | |
| " .sortBy(lambda x:-x[1]))\\\n", | |
| " .pprint()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### List the most common words in the tweets\n", | |
| "\n", | |
| "Every example has to have a version of wordcount, right? Here's an all-in-one with line continuations to make it clearer what's going on. It makes for tidier code, but it also makes it harder to debug..." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 15, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "parsed.\\\n", | |
| " flatMap(lambda tweet:tweet['text'].split(\" \"))\\\n", | |
| " .countByValue()\\\n", | |
| " .transform\\\n", | |
| " (lambda rdd:rdd.sortBy(lambda x:-x[1]))\\\n", | |
| " .pprint()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Start the streaming context\n", | |
| "\n", | |
| "Having defined the streaming context, now we're ready to actually start it! When you run this cell, the program will start, and you'll see the result of all the `pprint` functions above appear in the output to this cell below. If you're running it outside of Jupyter (via `spark-submit`) then you'll see the output on stdout.\n", | |
| "\n", | |
| "_I've added a `timeout` to deliberately cancel the execution after three minutes. In practice, you would not set this :)_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 16, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:34:00\n", | |
| "-------------------------------------------\n", | |
| "Tweets in this batch: 188\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:34:00\n", | |
| "-------------------------------------------\n", | |
| "(u'jenniekmz', 1)\n", | |
| "(u'SpamNewton', 1)\n", | |
| "(u'ShawtieMac', 1)\n", | |
| "(u'agathatochetti', 1)\n", | |
| "(u'Tommyguns_____', 1)\n", | |
| "(u'zwonderwomanzzz', 1)\n", | |
| "(u'Blesschubstin', 1)\n", | |
| "(u'Prikes5', 1)\n", | |
| "(u'MayaParms', 1)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:34:00\n", | |
| "-------------------------------------------\n", | |
| "(u'RitaBezerra12', 3)\n", | |
| "(u'xKYLN', 2)\n", | |
| "(u'yourmydw', 2)\n", | |
| "(u'wintersheat', 2)\n", | |
| "(u'biebercuzou', 2)\n", | |
| "(u'pchrin_', 2)\n", | |
| "(u'uslaybieber', 2)\n", | |
| "(u'rowblanchsrd', 2)\n", | |
| "(u'__Creammy__', 2)\n", | |
| "(u'jenniekmz', 1)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:34:00\n", | |
| "-------------------------------------------\n", | |
| "(u'RitaBezerra12', 3)\n", | |
| "(u'xKYLN', 2)\n", | |
| "(u'yourmydw', 2)\n", | |
| "(u'wintersheat', 2)\n", | |
| "(u'biebercuzou', 2)\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:34:00\n", | |
| "-------------------------------------------\n", | |
| "(u'RitaBezerra12', 3)\n", | |
| "(u'xKYLN', 2)\n", | |
| "(u'yourmydw', 2)\n", | |
| "(u'wintersheat', 2)\n", | |
| "(u'biebercuzou', 2)\n", | |
| "(u'pchrin_', 2)\n", | |
| "(u'uslaybieber', 2)\n", | |
| "(u'rowblanchsrd', 2)\n", | |
| "(u'__Creammy__', 2)\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:34:00\n", | |
| "-------------------------------------------\n", | |
| "(u'RT', 135)\n", | |
| "(u'Justin', 61)\n", | |
| "(u'Bieber', 59)\n", | |
| "(u'on', 41)\n", | |
| "(u'a', 32)\n", | |
| "(u'&', 32)\n", | |
| "(u'Ros\\xe9', 31)\n", | |
| "(u'Drake', 31)\n", | |
| "(u'the', 29)\n", | |
| "(u'Love', 28)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:35:00\n", | |
| "-------------------------------------------\n", | |
| "Tweets in this batch: 399\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:35:00\n", | |
| "-------------------------------------------\n", | |
| "(u'iAmDrugzz', 1)\n", | |
| "(u'neocthings', 1)\n", | |
| "(u'nuanearr', 1)\n", | |
| "(u'loitersquadvid', 1)\n", | |
| "(u'__jaaaync', 1)\n", | |
| "(u'cocolofm', 2)\n", | |
| "(u'mrinamoreira', 1)\n", | |
| "(u'rxxxaedner03', 1)\n", | |
| "(u'BriceWagner', 1)\n", | |
| "(u'anaflsvia', 1)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:35:00\n", | |
| "-------------------------------------------\n", | |
| "(u'BoybelieberUsaf', 4)\n", | |
| "(u'RadioRideTheWav', 3)\n", | |
| "(u'cocolofm', 2)\n", | |
| "(u'lalainexxi', 2)\n", | |
| "(u'UpdatedCeleb', 2)\n", | |
| "(u'IPOmaven', 2)\n", | |
| "(u'JBVotesAwards', 2)\n", | |
| "(u'Melanie7118', 2)\n", | |
| "(u'cutesp0sjb', 2)\n", | |
| "(u'Trulyml', 2)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:35:00\n", | |
| "-------------------------------------------\n", | |
| "(u'BoybelieberUsaf', 4)\n", | |
| "(u'RadioRideTheWav', 3)\n", | |
| "(u'cocolofm', 2)\n", | |
| "(u'lalainexxi', 2)\n", | |
| "(u'UpdatedCeleb', 2)\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:35:00\n", | |
| "-------------------------------------------\n", | |
| "(u'BoybelieberUsaf', 4)\n", | |
| "(u'RadioRideTheWav', 3)\n", | |
| "(u'cocolofm', 2)\n", | |
| "(u'lalainexxi', 2)\n", | |
| "(u'UpdatedCeleb', 2)\n", | |
| "(u'IPOmaven', 2)\n", | |
| "(u'JBVotesAwards', 2)\n", | |
| "(u'Melanie7118', 2)\n", | |
| "(u'cutesp0sjb', 2)\n", | |
| "(u'Trulyml', 2)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:35:00\n", | |
| "-------------------------------------------\n", | |
| "(u'RT', 282)\n", | |
| "(u'Justin', 116)\n", | |
| "(u'Drake', 104)\n", | |
| "(u'Bieber', 102)\n", | |
| "(u'is', 85)\n", | |
| "(u'-', 78)\n", | |
| "(u'Love', 70)\n", | |
| "(u'in', 61)\n", | |
| "(u'the', 57)\n", | |
| "(u'Yourself', 50)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:36:00\n", | |
| "-------------------------------------------\n", | |
| "Tweets in this batch: 435\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:36:00\n", | |
| "-------------------------------------------\n", | |
| "(u'TushShan', 1)\n", | |
| "(u'tonkhawjaa', 1)\n", | |
| "(u'terrispiffybndz', 1)\n", | |
| "(u'YGIKON_0113', 1)\n", | |
| "(u'Chloeprotz', 1)\n", | |
| "(u'hvnybee', 1)\n", | |
| "(u'77u7uI8OXd2MXut', 1)\n", | |
| "(u'neewromantics', 1)\n", | |
| "(u'flatlinwz', 1)\n", | |
| "(u'lizzardkings', 1)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:36:00\n", | |
| "-------------------------------------------\n", | |
| "(u'socialvidpress1', 10)\n", | |
| "(u'leonilotp', 3)\n", | |
| "(u'boo_u_stink', 3)\n", | |
| "(u'bIaqpinked', 2)\n", | |
| "(u'itspinosanow', 2)\n", | |
| "(u'ultkimjichu', 2)\n", | |
| "(u'rannie_95', 2)\n", | |
| "(u'damiancarenza', 2)\n", | |
| "(u'dinughsaur', 2)\n", | |
| "(u'millenameirele4', 2)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:36:00\n", | |
| "-------------------------------------------\n", | |
| "(u'socialvidpress1', 10)\n", | |
| "(u'leonilotp', 3)\n", | |
| "(u'boo_u_stink', 3)\n", | |
| "(u'bIaqpinked', 2)\n", | |
| "(u'itspinosanow', 2)\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:36:00\n", | |
| "-------------------------------------------\n", | |
| "(u'socialvidpress1', 10)\n", | |
| "(u'leonilotp', 3)\n", | |
| "(u'boo_u_stink', 3)\n", | |
| "(u'bIaqpinked', 2)\n", | |
| "(u'itspinosanow', 2)\n", | |
| "(u'ultkimjichu', 2)\n", | |
| "(u'rannie_95', 2)\n", | |
| "(u'damiancarenza', 2)\n", | |
| "(u'dinughsaur', 2)\n", | |
| "(u'millenameirele4', 2)\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 15:36:00\n", | |
| "-------------------------------------------\n", | |
| "(u'RT', 292)\n", | |
| "(u'Justin', 143)\n", | |
| "(u'Bieber', 134)\n", | |
| "(u'a', 87)\n", | |
| "(u'Love', 86)\n", | |
| "(u'Drake', 75)\n", | |
| "(u'on', 68)\n", | |
| "(u'Yourself', 59)\n", | |
| "(u'is', 59)\n", | |
| "(u'Ros\\xe9', 55)\n", | |
| "...\n", | |
| "\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "ssc.start()\n", | |
| "ssc.awaitTermination(timeout=180)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "So there we have it, a very simple Spark Streaming application doing some basic processing against an inbound data stream from Kafka." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Windowed Stream Processing" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Now let's have a look at how we can do windowed processing. This is where data is processed based on a 'window' which is a multiple of the batch duration that we worked with above. So instead of counting how many tweets there are every batch (say, 5 seconds), we could instead count how many there are per hour - an hour (/60 minutes/3600 seconds is the _window_ interval). We can perform this count potentially every time the batch runs; how frequently we do the count is known as the _slide_ interval.\n", | |
| "\n", | |
| "_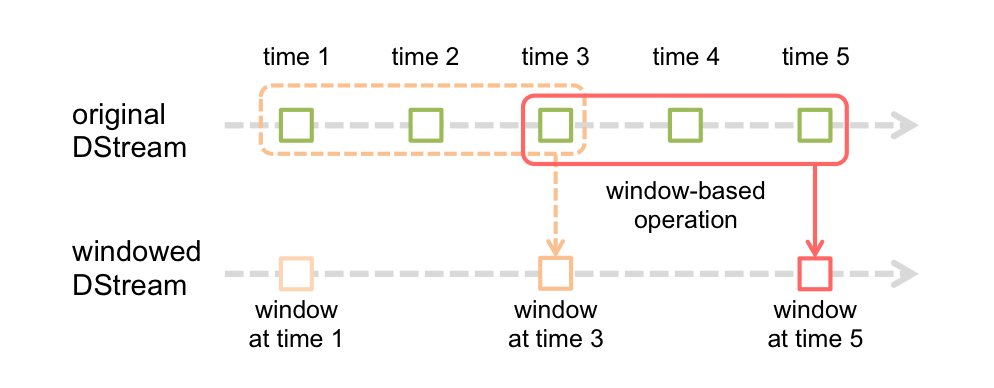\n", | |
| "Image credit, and more details about window processing, [here](http://spark.apache.org/docs/latest/streaming-programming-guide.html#window-operations)._" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "The first thing to do to enable windowed processing in Spark Streaming is to launch the Streaming Context with a [checkpoint directory](http://spark.apache.org/docs/latest/streaming-programming-guide.html#checkpointing) configured. This is used to store information between batches if necessary, and also to recover from failures. You need to rework your code into the pattern [shown here](http://spark.apache.org/docs/latest/streaming-programming-guide.html#how-to-configure-checkpointing). All the code to be executed by the streaming context goes in a function - which makes it less easy to present in a step-by-step form in a notebook as I have above. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Reset the Environment \n", | |
| "\n", | |
| "If you're running this code in the same session as above, first go to the Jupyter **Kernel** menu and select **Restart**." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Prepare the environment\n", | |
| "\n", | |
| "These are the same steps as above. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 2, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import os\n", | |
| "os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.2 pyspark-shell'\n", | |
| "from pyspark import SparkContext\n", | |
| "from pyspark.streaming import StreamingContext\n", | |
| "from pyspark.streaming.kafka import KafkaUtils\n", | |
| "import json" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Define the stream processing code" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "collapsed": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def createContext():\n", | |
| " sc = SparkContext(appName=\"PythonSparkStreamingKafka_RM_02\")\n", | |
| " sc.setLogLevel(\"WARN\")\n", | |
| " ssc = StreamingContext(sc, 5)\n", | |
| " \n", | |
| " # Define Kafka Consumer\n", | |
| " kafkaStream = KafkaUtils.createStream(ssc, 'cdh57-01-node-01.moffatt.me:2181', 'spark-streaming2', {'twitter':1})\n", | |
| " \n", | |
| " ## --- Processing\n", | |
| " # Extract tweets\n", | |
| " parsed = kafkaStream.map(lambda v: json.loads(v[1]))\n", | |
| " \n", | |
| " # Count number of tweets in the batch\n", | |
| " count_this_batch = kafkaStream.count().map(lambda x:('Tweets this batch: %s' % x))\n", | |
| " \n", | |
| " # Count by windowed time period\n", | |
| " count_windowed = kafkaStream.countByWindow(60,5).map(lambda x:('Tweets total (One minute rolling count): %s' % x))\n", | |
| "\n", | |
| " # Get authors\n", | |
| " authors_dstream = parsed.map(lambda tweet: tweet['user']['screen_name'])\n", | |
| " \n", | |
| " # Count each value and number of occurences \n", | |
| " count_values_this_batch = authors_dstream.countByValue()\\\n", | |
| " .transform(lambda rdd:rdd\\\n", | |
| " .sortBy(lambda x:-x[1]))\\\n", | |
| " .map(lambda x:\"Author counts this batch:\\tValue %s\\tCount %s\" % (x[0],x[1]))\n", | |
| "\n", | |
| " # Count each value and number of occurences in the batch windowed\n", | |
| " count_values_windowed = authors_dstream.countByValueAndWindow(60,5)\\\n", | |
| " .transform(lambda rdd:rdd\\\n", | |
| " .sortBy(lambda x:-x[1]))\\\n", | |
| " .map(lambda x:\"Author counts (One minute rolling):\\tValue %s\\tCount %s\" % (x[0],x[1]))\n", | |
| "\n", | |
| " # Write total tweet counts to stdout\n", | |
| " # Done with a union here instead of two separate pprint statements just to make it cleaner to display\n", | |
| " count_this_batch.union(count_windowed).pprint()\n", | |
| "\n", | |
| " # Write tweet author counts to stdout\n", | |
| " count_values_this_batch.pprint(5)\n", | |
| " count_values_windowed.pprint(5)\n", | |
| " \n", | |
| " return ssc" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Launch the stream processing\n", | |
| "\n", | |
| "This uses local disk to store the checkpoint data. In a Production deployment this would be on resilient storage such as HDFS.\n", | |
| "\n", | |
| "Note that, by design, if you restart this code using the same checkpoint folder, it will execute the *previous* code - so if you need to amend the code being executed, specify a different checkpoint folder." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "collapsed": false | |
| }, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:45\n", | |
| "-------------------------------------------\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:45\n", | |
| "-------------------------------------------\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:45\n", | |
| "-------------------------------------------\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:50\n", | |
| "-------------------------------------------\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:50\n", | |
| "-------------------------------------------\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:50\n", | |
| "-------------------------------------------\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:55\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 782\n", | |
| "Tweets total (One minute rolling count): 782\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:55\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue AnnaSabryan\tCount 8\n", | |
| "Author counts this batch:\tValue KHALILSAFADO\tCount 7\n", | |
| "Author counts this batch:\tValue socialvidpress\tCount 6\n", | |
| "Author counts this batch:\tValue SabSad_\tCount 5\n", | |
| "Author counts this batch:\tValue CooleeBravo\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:08:55\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 7\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 5\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:00\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 25\n", | |
| "Tweets total (One minute rolling count): 807\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:00\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue DawnExperience\tCount 1\n", | |
| "Author counts this batch:\tValue KHALILSAFADO\tCount 1\n", | |
| "Author counts this batch:\tValue Alchemister5\tCount 1\n", | |
| "Author counts this batch:\tValue uused2callme\tCount 1\n", | |
| "Author counts this batch:\tValue comfyjongin\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:00\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 5\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:05\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 27\n", | |
| "Tweets total (One minute rolling count): 834\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:05\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue fixdwmi\tCount 2\n", | |
| "Author counts this batch:\tValue yyggbpbt\tCount 1\n", | |
| "Author counts this batch:\tValue naveenarunkuma2\tCount 1\n", | |
| "Author counts this batch:\tValue briannalucas_\tCount 1\n", | |
| "Author counts this batch:\tValue bmvmedia\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:05\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 5\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:10\n", | |
| "-------------------------------------------\n", | |
| "Tweets total (One minute rolling count): 834\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:10\n", | |
| "-------------------------------------------\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:10\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 5\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:15\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 42\n", | |
| "Tweets total (One minute rolling count): 876\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:15\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue VideoHotHot1\tCount 1\n", | |
| "Author counts this batch:\tValue keratikarn\tCount 1\n", | |
| "Author counts this batch:\tValue titelegina\tCount 1\n", | |
| "Author counts this batch:\tValue OMRProductions\tCount 1\n", | |
| "Author counts this batch:\tValue SouthernAssBoi\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:15\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:20\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 28\n", | |
| "Tweets total (One minute rolling count): 904\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:20\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue Lesliesantoy\tCount 1\n", | |
| "Author counts this batch:\tValue msgrvce\tCount 1\n", | |
| "Author counts this batch:\tValue dhavalshah_\tCount 1\n", | |
| "Author counts this batch:\tValue Elmedina_se\tCount 1\n", | |
| "Author counts this batch:\tValue yoonoonz\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:20\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:25\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 17\n", | |
| "Tweets total (One minute rolling count): 921\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:25\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue trillltaee\tCount 1\n", | |
| "Author counts this batch:\tValue mononeuronico_\tCount 1\n", | |
| "Author counts this batch:\tValue OdaSethre\tCount 1\n", | |
| "Author counts this batch:\tValue Nesssly_\tCount 1\n", | |
| "Author counts this batch:\tValue whotfislarry\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:25\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:30\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 20\n", | |
| "Tweets total (One minute rolling count): 941\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:30\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue thiagotaria\tCount 1\n", | |
| "Author counts this batch:\tValue anku_91\tCount 1\n", | |
| "Author counts this batch:\tValue fuzztone71\tCount 1\n", | |
| "Author counts this batch:\tValue eipyeol_110\tCount 1\n", | |
| "Author counts this batch:\tValue SydSalesman\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:30\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 7\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:35\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 21\n", | |
| "Tweets total (One minute rolling count): 962\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:35\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue gagagatyatyatya\tCount 1\n", | |
| "Author counts this batch:\tValue morsepattama\tCount 1\n", | |
| "Author counts this batch:\tValue revagomes\tCount 1\n", | |
| "Author counts this batch:\tValue Eiregirl_420ppl\tCount 1\n", | |
| "Author counts this batch:\tValue imarcellofranca\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:35\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 7\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:40\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 17\n", | |
| "Tweets total (One minute rolling count): 979\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:40\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue DevanMoura\tCount 1\n", | |
| "Author counts this batch:\tValue JustinBieber4v\tCount 1\n", | |
| "Author counts this batch:\tValue historymalik_\tCount 1\n", | |
| "Author counts this batch:\tValue preamthanatcha\tCount 1\n", | |
| "Author counts this batch:\tValue coulkat767\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:40\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 7\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 5\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:45\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 5\n", | |
| "Tweets total (One minute rolling count): 984\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:45\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue OdaSethre\tCount 1\n", | |
| "Author counts this batch:\tValue ThePeeplzLyrics\tCount 1\n", | |
| "Author counts this batch:\tValue PrezDetroit\tCount 1\n", | |
| "Author counts this batch:\tValue Makeupbysagee\tCount 1\n", | |
| "Author counts this batch:\tValue tokyoten\tCount 1\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:45\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 7\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 6\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:50\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 28\n", | |
| "Tweets total (One minute rolling count): 1012\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:50\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue mat_lucidream\tCount 1\n", | |
| "Author counts this batch:\tValue OdaSethre\tCount 1\n", | |
| "Author counts this batch:\tValue _pneixhoq_\tCount 1\n", | |
| "Author counts this batch:\tValue airialjohnson00\tCount 1\n", | |
| "Author counts this batch:\tValue noelmorganho\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:50\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| "Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 7\n", | |
| "Author counts (One minute rolling):\tValue socialvidpress\tCount 7\n", | |
| "Author counts (One minute rolling):\tValue SabSad_\tCount 6\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:55\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 24\n", | |
| "Tweets total (One minute rolling count): 254\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:55\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue kvylvox\tCount 1\n", | |
| "Author counts this batch:\tValue sia_010\tCount 1\n", | |
| "Author counts this batch:\tValue itsz_sal\tCount 1\n", | |
| "Author counts this batch:\tValue EmpleoOfertas\tCount 1\n", | |
| "Author counts this batch:\tValue gmzftbreezy\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:09:55\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 3\n", | |
| "Author counts (One minute rolling):\tValue Iam_xlimzy\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue HIROMETAL1220\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue fixdwmi\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue ArrezinaR\tCount 2\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:00\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 16\n", | |
| "Tweets total (One minute rolling count): 245\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:00\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue smileygrands\tCount 1\n", | |
| "Author counts this batch:\tValue gibirdicalista\tCount 1\n", | |
| "Author counts this batch:\tValue 46WgkfQfbMFgfu1\tCount 1\n", | |
| "Author counts this batch:\tValue BenzTYB\tCount 1\n", | |
| "Author counts this batch:\tValue naturelleyxshe\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:00\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 3\n", | |
| "Author counts (One minute rolling):\tValue Iam_xlimzy\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue HIROMETAL1220\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue fixdwmi\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 2\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:05\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 22\n", | |
| "Tweets total (One minute rolling count): 240\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:05\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue fkinaw3some\tCount 1\n", | |
| "Author counts this batch:\tValue Ofmiceandbrinaa\tCount 1\n", | |
| "Author counts this batch:\tValue Stefania_pdc\tCount 1\n", | |
| "Author counts this batch:\tValue iagodns\tCount 1\n", | |
| "Author counts this batch:\tValue meredith413\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:05\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 3\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue ArrezinaR\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue blackpinkkot4\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue mat_lucidream\tCount 1\n", | |
| "...\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:10\n", | |
| "-------------------------------------------\n", | |
| "Tweets this batch: 5\n", | |
| "Tweets total (One minute rolling count): 245\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:10\n", | |
| "-------------------------------------------\n", | |
| "Author counts this batch:\tValue NowOnFR\tCount 1\n", | |
| "Author counts this batch:\tValue IKeepIt2000\tCount 1\n", | |
| "Author counts this batch:\tValue PCH_Intl\tCount 1\n", | |
| "Author counts this batch:\tValue ___GlBBS\tCount 1\n", | |
| "Author counts this batch:\tValue lauracoutinho24\tCount 1\n", | |
| "\n", | |
| "-------------------------------------------\n", | |
| "Time: 2017-01-11 17:10:10\n", | |
| "-------------------------------------------\n", | |
| "Author counts (One minute rolling):\tValue OdaSethre\tCount 3\n", | |
| "Author counts (One minute rolling):\tValue CooleeBravo\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue ArrezinaR\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue blackpinkkot4\tCount 2\n", | |
| "Author counts (One minute rolling):\tValue mat_lucidream\tCount 1\n", | |
| "...\n", | |
| "\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "ssc = StreamingContext.getOrCreate('/tmp/checkpoint_v06',lambda: createContext())\n", | |
| "ssc.start()\n", | |
| "ssc.awaitTermination()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "You can see in the above output cell the full output from the job, but let's take some extracts and walk through them. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Total tweet counts" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "First, the total tweet counts. In the first slide window, they're the same, since we only have one batch of data so far: \n", | |
| "\n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:08:55\n", | |
| " -------------------------------------------\n", | |
| " Tweets this batch: 782\n", | |
| " Tweets total (One minute rolling count): 782 \n", | |
| " \n", | |
| "Five seconds later, we have 25 tweets in the current batch - giving us a total of 807 (782 + 25): \n", | |
| "\n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:09:00\n", | |
| " -------------------------------------------\n", | |
| " Tweets this batch: 25\n", | |
| " Tweets total (One minute rolling count): 807 \n", | |
| " \n", | |
| "Fast forward just over a minute and we see that the windowed count for a minute is not just going up - in some cases it goes down - since our window is now not simply the full duration of the inbound data stream, but is shifting along and giving a total count for (now - 60 seconds)\n", | |
| "\n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:09:50\n", | |
| " -------------------------------------------\n", | |
| " Tweets this batch: 28\n", | |
| " Tweets total (One minute rolling count): 1012\n", | |
| "\n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:09:55\n", | |
| " -------------------------------------------\n", | |
| " Tweets this batch: 24\n", | |
| " Tweets total (One minute rolling count): 254\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### Count by Author\n", | |
| "\n", | |
| "In the first batch, as with the total tweets, the batch tally is the same as the windowed one: \n", | |
| " \n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:08:55\n", | |
| " -------------------------------------------\n", | |
| " Author counts this batch:\tValue AnnaSabryan\tCount 8\n", | |
| " Author counts this batch:\tValue KHALILSAFADO\tCount 7\n", | |
| " Author counts this batch:\tValue socialvidpress\tCount 6\n", | |
| " Author counts this batch:\tValue SabSad_\tCount 5\n", | |
| " Author counts this batch:\tValue CooleeBravo\tCount 5\n", | |
| " ...\n", | |
| "\n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:08:55\n", | |
| " -------------------------------------------\n", | |
| " Author counts (One minute rolling):\tValue AnnaSabryan\tCount 8\n", | |
| " Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 7\n", | |
| " Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| " Author counts (One minute rolling):\tValue SabSad_\tCount 5\n", | |
| " Author counts (One minute rolling):\tValue CooleeBravo\tCount 5 \n", | |
| " \n", | |
| "But notice in subsequent batches the rolling totals are accumulating for each author. Here we can see `KHALILSAFADO` (with a previous rolling total of 7, as above) has another tweet in this batch, giving a rolling total of 8: \n", | |
| "\n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:09:00\n", | |
| " -------------------------------------------\n", | |
| " Author counts this batch:\tValue DawnExperience\tCount 1\n", | |
| " Author counts this batch:\tValue KHALILSAFADO\tCount 1\n", | |
| " Author counts this batch:\tValue Alchemister5\tCount 1\n", | |
| " Author counts this batch:\tValue uused2callme\tCount 1\n", | |
| " Author counts this batch:\tValue comfyjongin\tCount 1\n", | |
| " ...\n", | |
| "\n", | |
| " -------------------------------------------\n", | |
| " Time: 2017-01-11 17:09:00\n", | |
| " -------------------------------------------\n", | |
| " Author counts (One minute rolling):\tValue AnnaSabryan\tCount 9\n", | |
| " Author counts (One minute rolling):\tValue KHALILSAFADO\tCount 8\n", | |
| " Author counts (One minute rolling):\tValue socialvidpress\tCount 6\n", | |
| " Author counts (One minute rolling):\tValue SabSad_\tCount 5\n", | |
| " Author counts (One minute rolling):\tValue CooleeBravo\tCount 5" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Summary\n", | |
| "\n", | |
| "Processing unbounded data sets, or \"stream processing\", is a new way of looking at what has always been done as batch in the past. Whilst intra-day ETL and frequent batch executions have brought latencies down, they are still standalone executions with optional bespoke code in place to handle intra-batch accumulations. With Spark Streaming we have a framework that enables this processing to be done natively and with support as default for both within-batch and across-batch (windowing). \n", | |
| "\n", | |
| "Here I used Spark Streaming because of its native support for Python, a language that I am familiar with and is (in my view) more accessible to non-coders than Java or Scala. Jupyter Notebooks are a fantastic environment in which to prototype code, and for a local environment providing both Jupyter and Spark it all you can't beat the Docker image [all-spark-notebook](https://github.com/jupyter/docker-stacks/tree/master/all-spark-notebook). \n", | |
| "\n", | |
| "There are other stream processing frameworks and languages out there, including Apache Flink, Kafka Streams, and Apache Beam, to name but three. Apache Storm and Apache Samza are also relevant, but whilst were early to the party seem to crop up less frequently in stream processing discussions and literature nowadays. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "In the next blog we'll see how to extend this Spark Stremaing further with processing that includes: \n", | |
| "\n", | |
| "* Matching tweet contents to predefined list of filter terms, and filtering out retweets\n", | |
| "* Including only tweets that include URLs, and comparing those URLs to a whitelist of domains\n", | |
| "* Sending tweets matching a given condition to a Kafka topic\n", | |
| "* Keeping a tally of tweet counts per batch and over a longer period of time, as well as counts for terms matched within the tweets" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "kernelspec": { | |
| "display_name": "Python 2", | |
| "language": "python", | |
| "name": "python2" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 2 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython2", | |
| "version": "2.7.12" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 1 | |
| } |