Created
June 26, 2019 10:32
-
-
Save versae/706a3ac54e235e518986ea5741bbbeb0 to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "<div style=\"display: flex;\">\n", | |
| " <div style=\"flex: 33%;\">\n", | |
| " <img src=\"https://www.dropbox.com/s/bbvz7v1rz4hygwn/uned.png?raw=1\" width=150>\n", | |
| " </div>\n", | |
| " <div style=\"flex: 33%; margin: 1em; text-align: center;\">\n", | |
| "\n", | |
| "<h1> Experto Profesional en Programación Python para Retail </h1>\n", | |
| "<h2> Módulo III: Fundamentos de IA en Python </h2>\n", | |
| "\n", | |
| " </div>\n", | |
| " <div style=\"flex: 33%;\">\n", | |
| " <img src=\"https://www.dropbox.com/s/y210rrea88niff5/ceura.png?raw=1\" width=200/>\n", | |
| " </div>\n", | |
| "</div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "MD3-NsWAgCSh" | |
| }, | |
| "source": [ | |
| "### Instructor\n", | |
| "<br/>\n", | |
| "<div style=\"display: flex;\">\n", | |
| " <div style=\"flex: 50%;\">\n", | |
| " <img src=\"https://www.dropbox.com/s/8u2cy57qpz4yx1y/profile_pic.jpg?raw=1\" width=200/>\n", | |
| " </div>\n", | |
| " <div style=\"flex: 50%;margin: 1em;\">\n", | |
| " **Javier de la Rosa**, <a href=\"mailto:versae@linhd.uned.es\">*versae@linhd.uned.es*</a>, <a href=\"https://twitter.com/versae\">*@versae*</a>\n", | |
| " <br />\n", | |
| " <br />\n", | |
| " <div style=\"padding-left: 1em;\">\n", | |
| " Postdoctoral Fellow en el Proyecto POSTDATA de LiNHD, UNED\n", | |
| " <br />\n", | |
| " PhD, Estudios Hispánicos y Humanidades Digitales, University of Western Ontario, Canada\n", | |
| " <br />\n", | |
| " Máster en Inteligencia Artificial, Universidad de Sevilla, España\n", | |
| " <br />\n", | |
| " <br />\n", | |
| " Ex-Ingeniero de Investigación en la Stanford University, California\n", | |
| " <br />\n", | |
| " Ex-Director Técnico del laboratorio de investigación CulturePlex Lab en la University of Western Ontario, Canada\n", | |
| " </div>\n", | |
| " </div>\n", | |
| "</div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Yn8as_dggCSj" | |
| }, | |
| "source": [ | |
| "### Introducción a Machine Learning en Python\n", | |
| "*18 de Junio de 2019, 240 mins*\n", | |
| "\n", | |
| "Este notebook contiene el código y las explicaciones de la sesión 2 del módulo III del Experto Profesional en Programación Python para Retail, en que se abordará una introducción al paquete `scikit-learn` para aprendizaje automático.\n", | |
| "\n", | |
| "Los enlaces de referencia son:\n", | |
| "\n", | |
| "- [Python Data Science Handbook](http://shop.oreilly.com/product/0636920034919.do) de Jake VanderPlas, cuyo contenido está parcialmente disponible en [GitHub](https://github.com/jakevdp/PythonDataScienceHandbook)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Setup" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "%%capture\n", | |
| "!pip install -U numpy pandas scikit-learn matplotlib seaborn version_information" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Veamos rápidamente con qué versiones estamos trabajando." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "%reload_ext version_information\n", | |
| "%version_information numpy, pandas, scikit-learn, matplotlib, seaborn" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Generemos una pequeña función para controlar el tiempo" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import time\n", | |
| "from tqdm import tnrange\n", | |
| "\n", | |
| "countdown = lambda s: ([time.sleep(1) for i in tnrange(s, desc=f\"{s} sec.\")]\n", | |
| " and print(\"Tiempo!\"))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "E importemos los paquetes necesarios." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "%matplotlib inline\n", | |
| "import numpy as np\n", | |
| "import matplotlib.pyplot as plt\n", | |
| "import pandas as pd\n", | |
| "import seaborn as sns; sns.set()\n", | |
| "from sklearn.datasets import fetch_lfw_people\n", | |
| "\n", | |
| "pd.options.mode.chained_assignment = None # Oculta un warning en ciertas operaciones de asignación\n", | |
| "plt.rcParams['figure.figsize'] = (4, 4)\n", | |
| "plt.rcParams['figure.dpi'] = 120\n", | |
| "fetch_lfw_people(min_faces_per_person=60); # Descarga un dataset de caras" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Y en caso de que se necesite descomprimir un fichero ZIP los datos, también se puede hacer en Python!\n", | |
| "\n", | |
| "```python\n", | |
| "import zipfile\n", | |
| "with zipfile.ZipFile(\"datasets.zip\",\"r\") as zip_ref:\n", | |
| " zip_ref.extractall(\".\")\n", | |
| "```" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# Inteligencia Artificial" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "> En informática, el campo de la investigación en **IA** se define como el estudio de los \"agentes inteligentes\", esto es, cualquier dispositivo que percibe su entorno y realiza acciones que maximizan sus posibilidades de éxito con algún objetivo.\n", | |
| "\n", | |
| "<div align=\"right\">— Fuente: <a href=\"https://en.wikipedia.org/wiki/Artificial_intelligence\">Wikipedia</a></div>\n", | |
| "\n", | |
| "> A partir del estudio del reconocimiento de patrones y la teoría del aprendizaje computacional en inteligencia artificial, el **aprendizaje máquina/automático** explora el estudio y la construcción de algoritmos que puedan aprender y hacer predicciones sobre datos - tales algoritmos superan las instrucciones estrictamente estáticas del programa al hacer predicciones o decisiones a través de la construcción de un **modelo** creado a partir de las entradas.\n", | |
| "\n", | |
| "<div align=\"right\">— Fuente: <a href=\"https://en.wikipedia.org/wiki/Machine_learning\">Wikipedia</a></div>\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "<figure>\n", | |
| " <img style=\"margin: 0 0 -55px 0;\" src=\"https://media.licdn.com/dms/image/C4E12AQFSG_cQxa9Zbw/article-inline_image-shrink_1500_2232/0?e=1566432000&v=beta&t=WqXNij6KvFxmszR0VveOmSonrWMQcoKvEnhWyYgFlQI\" /> <figcaption><div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://www.linkedin.com/pulse/deep-learning-next-big-thing-adtech-volker-ballueder\">Is Deep Learning the next big thing in adtech?</a></div></figcaption>\n", | |
| "</figure>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "i98e14vMgCSk" | |
| }, | |
| "source": [ | |
| "# Aprendizaje Automático (*Machine Learning*)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "HHU9Hd5bgCSl" | |
| }, | |
| "source": [ | |
| "En muchos sentidos, el aprendizaje automático es el medio principal por el cual la ciencia de datos se manifiesta en el mundo más amplio.\n", | |
| "El aprendizaje automático es donde estas habilidades computacionales y algorítmicas de la ciencia de datos satisfacen el pensamiento estadístico de la ciencia de datos, y el resultado es una colección de enfoques de inferencia y exploración de datos que no tienen que ver tanto con la teoría efectiva como con la computación efectiva.\n", | |
| "\n", | |
| "Los objetivos de esta sesión son:\n", | |
| "\n", | |
| "- Introducir el vocabulario y los conceptos fundamentales del aprendizaje automático.\n", | |
| "- Presentar la API de `scikit-learn` y mostrar algunos ejemplos de su uso.\n", | |
| "- Profundizar en los detalles de varios de los enfoques más importantes de aprendizaje automático y desarrollar una intuición sobre cómo funcionan, cuándo y dónde son aplicables." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "MrmaaGEogKGm" | |
| }, | |
| "source": [ | |
| "# ¿Qué es el aprendizaje automático?" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "kMS1nVb4gKGn" | |
| }, | |
| "source": [ | |
| "El aprendizaje automático se clasifica a menudo como un subcampo de la inteligencia artificial. El estudio del aprendizaje automático ciertamente surgió de la investigación en este contexto, pero en la aplicación de los métodos de aprendizaje automático en la ciencia de los datos, es más útil pensar en el aprendizaje automático como un medio para *construir modelos de datos*.\n", | |
| "\n", | |
| "Fundamentalmente, el aprendizaje automático implica la construcción de modelos matemáticos para ayudar a entender los datos.\n", | |
| "El \"aprendizaje\" entra en conflicto cuando damos a estos modelos *parámetros ajustables* que pueden ser adaptados a los datos observados; de esta manera el programa puede ser considerado como \"aprendizaje\" a partir de los datos.\n", | |
| "Una vez que estos modelos han sido ajustados a los datos previamente vistos, pueden ser usados para predecir y entender aspectos de los nuevos datos observados.\n", | |
| "\n", | |
| "Comprender la configuración del problema en el aprendizaje automático es esencial para utilizar estas herramientas de manera efectiva, por lo que comenzaremos con algunas categorizaciones generales de los tipos de enfoques que discutiremos aquí." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "jWgFf6sigKGo" | |
| }, | |
| "source": [ | |
| "## Categorías de aprendizaje automático\n", | |
| "\n", | |
| "En el nivel más fundamental, el aprendizaje automático se puede clasificar en dos tipos principales: aprendizaje supervisado y aprendizaje no supervisado.\n", | |
| "\n", | |
| "- **El aprendizaje supervisado** implica de alguna manera modelar la relación entre las características medidas de los datos y algunas etiquetas asociadas con los datos; una vez que se determina este modelo, se puede utilizar para aplicar etiquetas a datos nuevos y desconocidos.\n", | |
| " Esto se subdivide en tareas de *clasificación* y tareas de *regresión*: en la clasificación, las etiquetas son categorías discretas, mientras que en la regresión, las etiquetas son cantidades continuas.\n", | |
| "\n", | |
| "- **El aprendizaje no supervisado** implica modelar las características de un conjunto de datos sin referencia a ninguna etiqueta, y a menudo se describe como \"dejar que el conjunto de datos hable por sí mismo\".\n", | |
| " Estos modelos incluyen tareas como *clustering* y *reducción dimensional*. Los algoritmos de agrupamiento (*clustering*) identifican distintos grupos de datos, mientras que los algoritmos de reducción de la dimensionalidad buscan representaciones más sucintas de los datos.\n", | |
| "\n", | |
| "Además, existen los llamados métodos de *aprendizaje semisupervisado*, que se sitúan entre el aprendizaje supervisado y el aprendizaje no supervisado." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Kt-XsxnvgKGp" | |
| }, | |
| "source": [ | |
| "## Ejemplos cualitativos de aplicaciones de aprendizaje automático\n", | |
| "\n", | |
| "Para hacer estas ideas más concretas, echemos un vistazo a algunos ejemplos muy simples de una tarea de aprendizaje automático." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "awTcH3sBgKGp" | |
| }, | |
| "source": [ | |
| "### Clasificación: Predecir etiquetas discretas\n", | |
| "\n", | |
| "Primero echaremos un vistazo a una simple tarea de *clasificación*, en la que se tiene un conjunto de puntos etiquetados que se quieren usar para clasificar algunos puntos no etiquetados.\n", | |
| "\n", | |
| "Imaginemos que tenemos los datos que se muestran en esta figura:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "3HbPW6ZqgKGq" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "S84Sh0J-gKGr" | |
| }, | |
| "source": [ | |
| "Aquí tenemos datos bidimensionales: es decir, tenemos dos *características* para cada punto, representadas por las posiciones *(x,y)* de los puntos en el plano.\n", | |
| "Además, tenemos una de dos *etiquetas de clase* para cada punto, aquí representadas por los colores de los puntos.\n", | |
| "A partir de estas características y etiquetas, nos gustaría crear un modelo que nos permita decidir si un nuevo punto debe ser etiquetado como \"azul\" o \"rojo\".\n", | |
| "\n", | |
| "Hay una serie de modelos posibles para esta tarea de clasificación, pero aquí usaremos uno extremadamente sencillo. Supondremos que los dos grupos pueden separarse trazando una línea recta a través del plano que los separa, de manera que los puntos a cada lado de la línea caigan en el mismo grupo.\n", | |
| "Aquí el *modelo* es una versión cuantitativa de la frase \"una línea recta separa las clases\", mientras que los *parámetros del modelo* son los números particulares que describen la ubicación y orientación de esa línea para nuestros datos.\n", | |
| "Los valores óptimos para estos parámetros del modelo se aprenden a partir de los datos (esto es, el \"aprendizaje\" en el aprendizaje automático), que a menudo se denomina *entrenamiento o ajuste del modelo*.\n", | |
| "\n", | |
| "La siguiente figura muestra una representación visual de cómo es el modelo entrenado para estos datos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "CtLOBBzpgKGr" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "BiUvc0r4gKGs" | |
| }, | |
| "source": [ | |
| "Ahora que este modelo ha sido entrenado, puede generalizarse a nuevos datos no etiquetados.\n", | |
| "En otras palabras, podemos tomar un nuevo conjunto de datos, dibujar la línea del modelo, y asignar etiquetas a los nuevos puntos basados en el modelo.\n", | |
| "\n", | |
| "Esta etapa se suele llamar *predicción*. Véase la figura siguiente:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "tq3OHtuHgKGt" | |
| }, | |
| "source": [ | |
| "\n", | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "9O7NbQUVgKGu" | |
| }, | |
| "source": [ | |
| "Esta es la idea básica de una tarea de clasificación en el aprendizaje automático, donde la \"clasificación\" indica que los datos tienen etiquetas de clase discretas.\n", | |
| "A primera vista puede parecer bastante trivial: sería relativamente fácil observar los datos y trazar una línea discriminatoria para lograr su clasificación.\n", | |
| "Sin embargo, una ventaja del enfoque de aprendizaje automático es que puede generalizarse a conjuntos de datos mucho más grandes en muchas más dimensiones.\n", | |
| "\n", | |
| "Por ejemplo, es similar a la tarea de detección automática de spam para el correo electrónico; en este caso, podemos utilizar las siguientes funciones y etiquetas:\n", | |
| "\n", | |
| "- *característica 1*, *característica 2*, etc. $\\to$ recuento normalizado de palabras o frases importantes (\"Viagra\", \"Nigerian prince\", etc.)\n", | |
| "- *etiqueta* $\\to$ \"spam\" o \"no spam\"\n", | |
| "\n", | |
| "Para el conjunto de entrenamiento, estas etiquetas podrían determinarse mediante la inspección individual de una pequeña muestra representativa de correos electrónicos; para el resto de los correos electrónicos, la etiqueta se determinaría utilizando el modelo.\n", | |
| "\n", | |
| "Para un algoritmo de clasificación adecuadamente entrenado con suficientes características bien construidas (típicamente miles o millones de palabras o frases), este tipo de enfoque puede ser muy efectivo." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "RjlI_8-tgKGv" | |
| }, | |
| "source": [ | |
| "### Regresión: Predicción de etiquetas continuas\n", | |
| "\n", | |
| "En contraste con las etiquetas discretas de un algoritmo de clasificación, en una tarea de *regresión* las etiquetas son cantidades continuas.\n", | |
| "\n", | |
| "Considere los datos que se muestran en la siguiente figura, que consiste en un conjunto de puntos, cada uno con una etiqueta continua:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "8V1ZXpoOgKGw" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Uij-J3ChgKGw" | |
| }, | |
| "source": [ | |
| "Al igual que con el ejemplo de clasificación, tenemos datos bidimensionales: es decir, hay dos características que describen cada punto de datos.\n", | |
| "El color de cada punto representa la etiqueta continua para ese punto.\n", | |
| "\n", | |
| "Hay varios modelos de regresión posibles que podríamos usar para este tipo de datos, pero aquí usaremos una regresión lineal simple para predecir los puntos.\n", | |
| "Este sencillo modelo de regresión lineal asume que si tratamos la etiqueta como una tercera dimensión espacial, podemos ajustar un plano a los datos.\n", | |
| "Se trata de una generalización a un nivel superior del conocido problema de ajustar una línea a datos con dos coordenadas.\n", | |
| "\n", | |
| "Podemos visualizar esta configuración como se muestra en la siguiente figura:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "70UWZJdzgKGx" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "qkmS-ZDPgKGy" | |
| }, | |
| "source": [ | |
| "Observe que el plano *característica 1-característica 2* aquí es el mismo que en el gráfico bidimensional anterior; en este caso, sin embargo, hemos representado las etiquetas tanto por color como por posición del eje tridimensional.\n", | |
| "Desde este punto de vista, parece razonable que el ajuste de un plano a través de estos datos tridimensionales nos permita predecir la etiqueta esperada para cualquier conjunto de parámetros de entrada.\n", | |
| "Volviendo a la proyección bidimensional, cuando encajamos en un plano así obtenemos el resultado que se muestra en la siguiente figura:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "RBSGVTYJgKGz" | |
| }, | |
| "source": [ | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "qJNtyWo8gKG0" | |
| }, | |
| "source": [ | |
| "Este plano de ajuste nos da lo que necesitamos para predecir etiquetas para nuevos puntos.\n", | |
| "Visualmente, encontramos los resultados que se muestran en la siguiente figura:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "jNaMXti8gKG1" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "0eBBXC4BgKG2" | |
| }, | |
| "source": [ | |
| "Al igual que en el ejemplo de la clasificación, este proceso puede parecer trivial en un número reducido de dimensiones.\n", | |
| "Pero el poder de estos métodos es que pueden ser aplicados y evaluados directamente en el caso de datos con muchas, muchas características.\n", | |
| "\n", | |
| "Por ejemplo, esto es similar a la tarea de calcular la esperanza de vida basándonos en la edad, el peso, etc. de las personas:\n", | |
| "\n", | |
| "- *característica 1*, *característica 2*, etc. $\\to$ edad, peso, o nivel de ingresos.\n", | |
| "- *label* $\\to$ esperanza de vida en años" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "bBZGb7vHgKG3" | |
| }, | |
| "source": [ | |
| "### Agrupación (*Clustering*): Inferir etiquetas en datos no etiquetados\n", | |
| "\n", | |
| "Las ilustraciones de clasificación y regresión que acabamos de ver son ejemplos de algoritmos de aprendizaje supervisado, en los que estamos intentando construir un modelo que prediga etiquetas para nuevos datos.\n", | |
| "El aprendizaje no supervisado incluye modelos que describen datos sin referencia a ninguna etiqueta conocida.\n", | |
| "\n", | |
| "Un caso común de aprendizaje no supervisado es la \"agrupación\", en la que los datos se asignan automáticamente a un número determinado de grupos.\n", | |
| "Por ejemplo, podríamos tener algunos datos bidimensionales como los que se muestran en la siguiente figura:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "LQ1tQpFOgKG4" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "HZRLqzPwgKG6" | |
| }, | |
| "source": [ | |
| "A primera vista, está claro que cada uno de estos puntos forma parte de un grupo distinto, por lo que un modelo de agrupamiento utilizará la estructura intrínseca de los datos para determinar qué puntos están relacionados." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "MV1Cu2RCgKG7" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "95kl4gT-gKG8" | |
| }, | |
| "source": [ | |
| "### Reducción de la dimensionalidad: Inferir la estructura de datos no etiquetados\n", | |
| "\n", | |
| "La reducción de la dimensionalidad es otro ejemplo de un algoritmo no supervisado, en el que las etiquetas u otra información se infieren de la estructura del propio conjunto de datos.\n", | |
| "La reducción de la dimensionalidad es un poco más abstracta que los ejemplos que vimos antes, pero generalmente busca sacar alguna representación de datos de baja dimensión que de alguna manera preserve las cualidades relevantes del conjunto de datos completo.\n", | |
| "\n", | |
| "Como ejemplo de esto, considere los datos que se muestran en la siguiente figura:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "MqS5H9PlgKG9" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "pH0tMbG2gKHA" | |
| }, | |
| "source": [ | |
| "Visualmente, está claro que hay alguna estructura en estos datos: se dibuja a partir de una línea unidimensional que está dispuesta en espiral dentro de este espacio bidimensional.\n", | |
| "En cierto modo, se podría decir que estos datos son \"intrínsecamente\" unidimensionales, aunque estos datos unidimensionales están incrustados en un espacio de dimensiones superiores.\n", | |
| "Un modelo adecuado de reducción de la dimensionalidad en este caso sería sensible a esta estructura empotrada no lineal, y sería capaz de extraer esta representación de menor dimensionalidad.\n", | |
| "\n", | |
| "La siguiente figura muestra una visualización de los resultados del algoritmo Isomap, un algoritmo de aprendizaje múltiple que hace exactamente esto:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "gJz4pUmdgKHC" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "d_9oyAImgKHD" | |
| }, | |
| "source": [ | |
| "Observe que los colores (que representan la variable latente unidimensional extraída) cambian uniformemente a lo largo de la espiral, lo que indica que el algoritmo detectó de hecho la estructura que vimos a simple vista.\n", | |
| "Al igual que en los ejemplos anteriores, el poder de los algoritmos de reducción de la dimensionalidad se hace más claro en los casos de mayor dimensión.\n", | |
| "Por ejemplo, es posible que deseemos visualizar relaciones importantes dentro de un set de datos que tenga 100 o 1.000 características.\n", | |
| "Visualizar datos en 1.000 dimensiones es un desafío, y una forma de hacerlo más manejable es utilizar una técnica de reducción de la dimensionalidad para reducir los datos a dos o tres dimensiones." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "También puede verse visualmente cómo un espacio tridimensional se puede reducir a 2 sin perder poder discriminativo: http://setosa.io/ev/principal-component-analysis/" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "wjFDqHcIgKHE" | |
| }, | |
| "source": [ | |
| "## Resumen\n", | |
| "\n", | |
| "En resumen:\n", | |
| "\n", | |
| "- *Aprendizaje supervisado*: Modelos que pueden predecir etiquetas basadas en datos de entrenamiento etiquetados\n", | |
| "\n", | |
| " - *Clasificación*: Modelos que predicen las etiquetas como dos o más categorías discretas\n", | |
| " - *Regresión*: Modelos que predicen etiquetas continuas\n", | |
| " \n", | |
| "- *Aprendizaje no supervisado*: Modelos que identifican la estructura en datos no etiquetados\n", | |
| "\n", | |
| " - *Clustering*: Modelos que detectan e identifican distintos grupos en los datos\n", | |
| " - *Reducción dimensional*: Modelos que detectan e identifican estructuras de baja dimensión en datos de alta dimensión." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "RpatnfwkgOzg" | |
| }, | |
| "source": [ | |
| "# Scikit-Learn" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "5r4jHMZegOzh" | |
| }, | |
| "source": [ | |
| "Existen varias librerías Python que proporcionan implementaciones sólidas de una gama de algoritmos de aprendizaje de máquina.\n", | |
| "Uno de los más conocidos es [Scikit-Learn](http://scikit-learn.org), un paquete que proporciona versiones eficientes de un gran número de algoritmos comunes.\n", | |
| "Scikit-Learn se caracteriza por una API limpia, uniforme y racionalizada, así como por una documentación en línea muy útil y completa.\n", | |
| "Un beneficio de esta uniformidad es que una vez que se entiende el uso básico y la sintaxis de Scikit-Learn para un tipo de modelo, el cambio a un nuevo modelo o algoritmo es muy sencillo." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "5eItciYigOzh" | |
| }, | |
| "source": [ | |
| "## Representación de datos en Scikit-Learn" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "NJ-0gDYIgOzi" | |
| }, | |
| "source": [ | |
| "El aprendizaje automático consiste en crear modelos a partir de datos: por esa razón, empezaremos por discutir cómo se pueden representar los datos para que sean entendidos por el ordenador.\n", | |
| "La mejor manera de pensar sobre los datos dentro de Scikit-Learn es en términos de tablas de datos." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "tscGCctMgOzj" | |
| }, | |
| "source": [ | |
| "#### Datos como tabla\n", | |
| "\n", | |
| "Una tabla básica es una cuadrícula bidimensional de datos, en la que las filas representan elementos individuales del set de datos y las columnas representan cantidades relacionadas con cada uno de estos elementos.\n", | |
| "Por ejemplo, consideremos el [conjunto de datos de Iris](https://en.wikipedia.org/wiki/Iris_flower_data_set), que fue analizado por Ronald Fisher en 1936.\n", | |
| "\n", | |
| "Podemos descargar este conjunto de datos en forma de Pandas ``DataFrame`` usando la biblioteca [seaborn](http://seaborn.pydata.org/):" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "Z0_oa8RtgOzj", | |
| "outputId": "28c85182-7061-489e-c76b-8689c69c9c1d" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import seaborn as sns\n", | |
| "iris = sns.load_dataset('iris')\n", | |
| "iris.head()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "LqiC6ZHKgOzp" | |
| }, | |
| "source": [ | |
| "Aquí cada fila de los datos se refiere a una sola flor observada, y el número de filas es el número total de flores en el conjunto de datos.\n", | |
| "En general, nos referiremos a las filas de la matriz como *muestras* (*samples*), y al número de filas como ``n_samples``.\n", | |
| "\n", | |
| "Asimismo, cada columna de los datos se refiere a un dato cuantitativo particular que describe cada muestra.\n", | |
| "En general, nos referiremos a las columnas de la matriz como *características* (*features*), y al número de columnas como ``n_features``." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "c_tA9HdggOzp" | |
| }, | |
| "source": [ | |
| "#### Matriz de características\n", | |
| "\n", | |
| "Este diseño de tabla deja claro que la información puede ser pensada como un array numérico bidimensional o matriz, al que llamaremos la *matriz de características*.\n", | |
| "\n", | |
| "Por convención, esta matriz de características se almacena a menudo en una variable llamada ``X``.\n", | |
| "Se supone que la matriz de características es bidimensional, con forma ``[n_samples, n_features]``, y a menudo está contenida en una matriz NumPy o en un ``DataFrame`` Pandas , aunque algunos modelos Scikit-Learn también aceptan matrices dispersas de SciPy.\n", | |
| "\n", | |
| "Los muestreos (es decir, las filas) se refieren siempre a los objetos individuales descritos por el set de datos.\n", | |
| "Por ejemplo, la muestra puede ser una flor, una persona, un documento, una imagen, un archivo de sonido, un vídeo, un objeto astronómico o cualquier otra cosa que pueda describir con un conjunto de mediciones cuantitativas.\n", | |
| "\n", | |
| "Las características (es decir, las columnas) siempre se refieren a las distintas observaciones que describen cada muestra de manera cuantitativa.\n", | |
| "Las características son generalmente de valor real, pero pueden ser booleanas o de valor discreto en algunos casos." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "krDXbf2AgOzq" | |
| }, | |
| "source": [ | |
| "#### Matriz de etiquetas\n", | |
| "\n", | |
| "Además de la matriz de características ``X``, también trabajamos generalmente con una matriz *etiqueta* u *objetivo*, a la que por convención llamaremos ``y``.\n", | |
| "La matriz de etiquetas suele ser unidimensional, con longitud ``n_samples``, y generalmente está contenida en una matriz NumPy o una ``Series`` Pandas.\n", | |
| "La matriz de etiquetas puede tener valores numéricos continuos o clases/etiquetas discretas.\n", | |
| "Mientras que algunos estimadores de Scikit-Learn manejan múltiples valores objetivo en la forma de una matriz de etiquetas bidimensional ``[n_samples, n_labels]``, trabajaremos principalmente con el caso común de una matriz de etiquetas unidimensional.\n", | |
| "\n", | |
| "A menudo, un punto de confusión es la diferencia entre la matriz de etiquetas y las otras columnas de características. La característica distintiva del array de etiquetas es que normalmente es la cantidad que queremos *predecir a partir de los datos*: en términos estadísticos, es la variable dependiente.\n", | |
| "Por ejemplo, en los datos anteriores podemos querer construir un modelo que pueda predecir la especie de flor basado en las otras medidas; en este caso, la columna ``species`` se consideraría la matriz de etiquetas." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "gy-QO9qBgOzr", | |
| "outputId": "5c2ea94b-8e93-4781-d9ab-d5ba9c3ec543" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "sns.pairplot(iris, hue='species', height=1.5);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "j10QulAlgOzw" | |
| }, | |
| "source": [ | |
| "Para su uso en Scikit-Learn, extraeremos la matriz de características y la matriz de objetivos del mismo ``DataFrame``, lo cual podemos hacer usando algunas de las operaciones de Pandas." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "bKjheDaTgOzx", | |
| "outputId": "9019d9a4-ae2c-4273-9d5e-ecc9cd9ec6dd" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X_iris = iris.drop('species', axis=1)\n", | |
| "X_iris.shape" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "MhdV-bnPgOz0", | |
| "outputId": "e3b41c10-f63b-48b2-f9e6-423ff23cd1f5" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "y_iris = iris['species']\n", | |
| "y_iris.shape" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "XJjhfyvmgOz3" | |
| }, | |
| "source": [ | |
| "Por resumir, la disposición prevista de características y valores previstos se visualiza en el siguiente diagrama:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "8J53ZgvDgOz4" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "lM8Xp2JegOz5" | |
| }, | |
| "source": [ | |
| "Con estos datos formateados correctamente, podemos pasar a considerar la API del *estimador* de Scikit-Learn:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "w3G-5_LfgOz5" | |
| }, | |
| "source": [ | |
| "## API del Estimador de Scikit-Learn" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "EhoYz5uQgOz7" | |
| }, | |
| "source": [ | |
| "La API de Scikit-Learn está diseñada con los siguientes principios rectores en mente, tal como se describe en el documento [Scikit-Learn API](http://arxiv.org/abs/1309.0238):\n", | |
| "\n", | |
| "- *Consistencia*: Todos los objetos comparten una interfaz común extraída de un conjunto limitado de métodos, con una documentación coherente.\n", | |
| "\n", | |
| "- *Inspección*: Todos los valores de parámetros especificados se exponen como atributos públicos.\n", | |
| "\n", | |
| "- *Jerarquía de objetos limitada*: Sólo los algoritmos están representados por las clases Python; los conjuntos de datos están representados en formatos estándar (matrices NumPy, ``DataFrame``s Pandas, matrices dispersas de SciPy) y cadenas Python estándar.\n", | |
| "\n", | |
| "- *Composición*: Muchas tareas de aprendizaje pueden expresarse como secuencias de algoritmos más fundamentales, y Scikit-Learn hace uso de esto siempre que es posible.\n", | |
| "\n", | |
| "- *Valores predeterminados razonables*: Cuando los modelos requieren parámetros especificados por el usuario, la biblioteca define un valor por defecto apropiado.\n", | |
| "\n", | |
| "En la práctica, estos principios hacen que Scikit-Learn sea muy fácil de usar, una vez que se entienden los principios básicos.\n", | |
| "Cada algoritmo de aprendizaje automático en Scikit-Learn se implementa a través del `Estimator`, que proporciona una interfaz consistente para una amplia gama de aplicaciones de aprendizaje de máquinas." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "rkh5jU1TgOz7" | |
| }, | |
| "source": [ | |
| "### Conceptos básicos de la API\n", | |
| "\n", | |
| "Los pasos más comunes para usar la API del estimador Scikit-Learn son los siguientes:\n", | |
| "\n", | |
| "1. Elija una clase de modelo importando la clase de estimador apropiada de Scikit-Learn.\n", | |
| "2. Elija los hiperparámetros del modelo instanciando la clase con los valores deseados.\n", | |
| "3. Organice los datos en una matriz de características y en un vector objetivo siguiendo.\n", | |
| "4. Ajuste el modelo a sus datos llamando al método ``fit()`` de la instancia de modelo.\n", | |
| "5. Aplicar el modelo a los nuevos datos:\n", | |
| " - Para el aprendizaje supervisado, a menudo predecimos etiquetas para datos desconocidos usando el método ``predict()``.\n", | |
| " - Para el aprendizaje no supervisado, a menudo transformamos o inferimos propiedades de los datos usando el método ``transform()`` o ``predict()``." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "SDuidpqWgOz8" | |
| }, | |
| "source": [ | |
| "### Ejemplo de aprendizaje supervisado: Regresión lineal simple\n", | |
| "\n", | |
| "Como ejemplo de este proceso, consideremos una regresión lineal simple, es decir, el caso común de ajustar una línea a datos $(x, y)$.\n", | |
| "Usaremos los siguientes datos simples para nuestro ejemplo de regresión:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "MqnpFntGgOz9", | |
| "outputId": "ae5785f6-c937-448b-a100-97453009567a" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "rng = np.random.RandomState(42)\n", | |
| "x = 10 * rng.rand(50)\n", | |
| "y = 2 * x - 1 + rng.randn(50)\n", | |
| "plt.scatter(x, y);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "up-R5CnxgO0A" | |
| }, | |
| "source": [ | |
| "#### 1. Elija una clase de modelo\n", | |
| "\n", | |
| "En Scikit-Learn, cada clase de modelo está representada por una clase Python.\n", | |
| "Así, por ejemplo, si queremos calcular un modelo de regresión lineal simple, podemos importar la clase de regresión lineal:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "dlA_NQJ8gO0B" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.linear_model import LinearRegression" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "h_4Qii35gO0D" | |
| }, | |
| "source": [ | |
| "Existen otros modelos de regresión lineal más generales sobre los que se puede leer más en la documentación del módulo [``sklearn.linear_model``](http://Scikit-Learn.org/stable/modules/linear_model.html)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "2BalIaZ8gO0D" | |
| }, | |
| "source": [ | |
| "#### 2. Elija los hiperparámetros del modelo\n", | |
| "\n", | |
| "Un punto importante es que *una clase de modelo no es lo mismo que una instancia de un modelo*.\n", | |
| "\n", | |
| "Una vez que nos hemos decidido por nuestra clase de modelo, todavía hay algunas opciones disponibles para nosotros.\n", | |
| "Dependiendo de la clase de modelo con la que estamos trabajando, es posible que necesitemos responder a una o más preguntas como las siguientes:\n", | |
| "\n", | |
| "- ¿Nos gustaría ajustarnos al offset (es decir, a la intercepción o constante de *y*)?\n", | |
| "- ¿Nos gustaría que el modelo se normalizara?\n", | |
| "- ¿Nos gustaría preprocesar nuestras características para añadir flexibilidad al modelo?\n", | |
| "- ¿Qué grado de regularización nos gustaría utilizar en nuestro modelo?\n", | |
| "- ¿Cuántos componentes del modelo nos gustaría utilizar?\n", | |
| "\n", | |
| "Estos son ejemplos de las elecciones importantes que deben hacerse *una vez que se selecciona la clase de modelo*.\n", | |
| "Estas opciones se representan a menudo como *hiperparámetros*, o parámetros que deben ajustarse antes de que el modelo se ajuste a (sea entrenado con) los datos.\n", | |
| "En Scikit-Learn, los hiperparámetros se eligen pasando valores en la instancia del modelo.\n", | |
| "\n", | |
| "Para nuestro ejemplo de regresión lineal, podemos instanciar la clase ``LinearRegression`` y especificar que nos gustaría ajustar la intercepción/constante usando el hiperparámetro ``fit_intercept``:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "4zZCpvXPgO0E", | |
| "outputId": "b6bb5c21-1432-48c7-c928-0c2891882570" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model = LinearRegression(fit_intercept=True)\n", | |
| "model" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "93As93vHgO0H" | |
| }, | |
| "source": [ | |
| "Tenga en cuenta que cuando el modelo es instanciado, la única acción es el almacenamiento de estos valores de hiperparámetro.\n", | |
| "En particular, aún no hemos aplicado el modelo a ningún dato: la API de Scikit-Learn deja muy clara la distinción entre *elección de modelo* y *aplicación del modelo a los datos*." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "hNyJEtargO0H" | |
| }, | |
| "source": [ | |
| "#### 3. Ordenar los datos en una matriz de características y vector de destino\n", | |
| "\n", | |
| "Aquí nuestra variable objetivo ``y`` ya está en la forma correcta (una matriz de longitud ``n_samples``), pero necesitamos masajear los datos ``X`` para hacer una matriz de tamaño ``[n_samples, n_features]``.\n", | |
| "En este caso, esto equivale a una simple remodelación de la matriz unidimensional:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "6Infsr0KgO0I", | |
| "outputId": "fe8e0068-64ec-4512-e887-41f6a181ee7a" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X = x[:, np.newaxis]\n", | |
| "X.shape" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "CqtJV0ClgO0L" | |
| }, | |
| "source": [ | |
| "#### 4. Ajuste el modelo a sus datos\n", | |
| "\n", | |
| "Ahora es el momento de aplicar nuestro modelo a los datos.\n", | |
| "Esto se puede hacer con el método ``fit()`` del modelo:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "KBW9zyLNgO0M", | |
| "outputId": "c1a54c1f-ff94-4491-f1a9-3df59cdcc48f" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model.fit(X, y)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "08PJ2uF9gO0O" | |
| }, | |
| "source": [ | |
| "Este comando ``fit()`` hace que se realicen varios cálculos internos dependientes del modelo, y los resultados de estos cálculos se almacenan en atributos específicos del modelo que el usuario puede explorar.\n", | |
| "En Scikit-Learn, por convención todos los parámetros del modelo que se aprendieron durante el proceso ``fit()`` tienen subrayados al final; por ejemplo en este modelo lineal, tenemos lo siguiente:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "fv3DR_osgO0R", | |
| "outputId": "a87701e4-0a85-4e85-d376-5a895583c44e" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model.coef_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "LRCduIoqgO0X", | |
| "outputId": "ffe5dda2-0668-43e7-a286-0871d465d6fc" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model.intercept_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "vnF1n8k5gO0a" | |
| }, | |
| "source": [ | |
| "Estos dos parámetros representan la pendiente y la intercepción del ajuste lineal simple a los datos.\n", | |
| "Comparando con la definición de los datos, vemos que están muy cerca de la pendiente de entrada de 2 y la intercepción de -1.\n", | |
| "\n", | |
| "Una pregunta que surge con frecuencia se refiere a la incertidumbre en tales parámetros internos del modelo.\n", | |
| "En general, Scikit-Learn no proporciona herramientas para sacar conclusiones de los parámetros internos del modelo en sí: interpretar los parámetros del modelo es mucho más una pregunta de *modelado estadístico* que una de *aprendizaje automático*.\n", | |
| "El aprendizaje automático se centra más bien en lo que el modelo *prevé*." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "qymTNUNCgO0e" | |
| }, | |
| "source": [ | |
| "#### 5. Predecir etiquetas para datos desconocidos\n", | |
| "\n", | |
| "Una vez que el modelo es entrenado, la tarea principal del aprendizaje supervisado de la máquina es evaluarla en base a lo que dice sobre los nuevos datos que no formaban parte del conjunto de entrenamiento.\n", | |
| "En Scikit-Learn, esto se puede hacer usando el método ``predict()``.\n", | |
| "\n", | |
| "Para este ejemplo, nuestros \"nuevos datos\" serán una cuadrícula de valores *x*, y nos preguntaremos qué valores *y* predice el modelo:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "KaLP6LkogO0f" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "xfit = np.linspace(-1, 11)\n", | |
| "xfit" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "LzNNwVtqgO0j" | |
| }, | |
| "source": [ | |
| "Como antes, necesitamos transformar estos valores *x* en una matriz de características ``[n_samples, n_features]``, después de lo cual podremos pasarlos al modelo:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "Ct1wR0RngO0j" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "Xfit = xfit[:, np.newaxis]\n", | |
| "yfit = model.predict(Xfit)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "XmMAYnYAgO0m" | |
| }, | |
| "source": [ | |
| "Finalmente, visualicemos los resultados trazando primero los datos sin procesar, y luego este modelo encaja:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "ryQkhh3AgO0n", | |
| "outputId": "277ed461-781f-4b8b-8f8f-b68c14a47b5a" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "plt.scatter(x, y)\n", | |
| "plt.plot(xfit, yfit);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "1sQXU9XCgO0r" | |
| }, | |
| "source": [ | |
| "Típicamente la eficacia del modelo se evalúa comparando sus resultados con alguna base conocida (*baseline*)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "rNjeB4LogO0r" | |
| }, | |
| "source": [ | |
| "### Ejemplo de aprendizaje supervisado: Clasificación del dataset `iris`\n", | |
| "\n", | |
| "Echemos un vistazo a otro ejemplo de este proceso, usando el conjunto de datos de Iris: dado un modelo entrenado en una parte de los datos del Iris, ¿qué tan bien podemos predecir las etiquetas restantes?\n", | |
| "\n", | |
| "Para esta tarea, usaremos un modelo generativo extremadamente simple conocido como Gaussian Naive Bayes, que procede asumiendo que cada clase se dibuja a partir de una distribución gaussiana.\n", | |
| "Debido a que es muy rápido y no tiene hiperparámetros para elegir, un Gaussian Naive Bayes es a menudo un buen modelo para usar como clasificación de base con la que comparar antes de explorar si hay mejoras con modelos más sofisticados.\n", | |
| "\n", | |
| "Nos gustaría evaluar el modelo en datos que no ha visto antes, y por lo tanto dividiremos los datos en un *conjunto de entrenamiento* y un *conjunto de pruebas*.\n", | |
| "\n", | |
| "Esto podría hacerse a mano, pero es más conveniente usar la función de utilidad ``train_test_split``:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "4gkHEXvYgO0s" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.model_selection import train_test_split\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(X_iris, y_iris,\n", | |
| " random_state=1)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "8ukEGLDzgO0u" | |
| }, | |
| "source": [ | |
| "Con los datos organizados, podemos seguir nuestra receta para predecir las etiquetas:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "6d7ueMehgO0u" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.naive_bayes import GaussianNB # 1. choose model class\n", | |
| "\n", | |
| "model = GaussianNB() # 2. instantiate model\n", | |
| "model.fit(Xtrain, ytrain) # 3. fit model to data\n", | |
| "y_model = model.predict(Xtest) # 4. predict on new data" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "sKVaqbJOgO0w" | |
| }, | |
| "source": [ | |
| "Finalmente, podemos usar la función ``accuracy_score`` para ver la fracción de etiquetas previstas que coinciden con su verdadero valor:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "Lvg9Qw-wgO0x", | |
| "outputId": "d05fb367-9f94-4737-a06e-fc7642d3e390", | |
| "scrolled": true | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.metrics import accuracy_score\n", | |
| "accuracy_score(ytest, y_model)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "OJf2_QBkgO01" | |
| }, | |
| "source": [ | |
| "Con una precisión que supera el 97%, vemos que incluso este ingenuo algoritmo de clasificación es efectivo para este conjunto de datos en particular." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "2jopFRNugO02" | |
| }, | |
| "source": [ | |
| "### Ejemplo de aprendizaje sin supervisión: Dimensionalidad del dataset `iris`\n", | |
| "\n", | |
| "Como ejemplo de un problema de aprendizaje no supervisado, echemos un vistazo a la reducción de la dimensionalidad de los datos del Iris para visualizarlos más fácilmente.\n", | |
| "Recordemos que los datos del Iris son cuatridimensionales: hay cuatro características registradas para cada muestra.\n", | |
| "\n", | |
| "La tarea de la reducción de la dimensionalidad consiste en preguntarse si existe una representación adecuada de las dimensiones inferior que conserve las características esenciales de los datos.\n", | |
| "A menudo la reducción de la dimensionalidad se utiliza como ayuda para visualizar los datos: después de todo, es mucho más fácil trazar los datos en dos dimensiones que en cuatro o más. En este caso, queremos que el modelo devuelva dos componentes, es decir, una representación bidimensional de los datos." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "UojUwLK1gO03" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.decomposition import PCA # 1. Choose the model class\n", | |
| "\n", | |
| "model = PCA(n_components=2) # 2. Instantiate the model with hyperparameters\n", | |
| "model.fit(X_iris) # 3. Fit to data. Notice y is not specified!\n", | |
| "X_2D = model.transform(X_iris) # 4. Transform the data to two dimensions" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "p9p5s608gO06" | |
| }, | |
| "source": [ | |
| "Ahora grafiquemos los resultados. Una forma rápida de hacerlo es insertar los resultados en el ``DataFrame`` original, y usar el ```lmplot``` de Seaborn para mostrar los resultados:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "iFBBhzSEgO07", | |
| "outputId": "4fd5032e-2ea1-408a-8f98-2b2332040ae4" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "iris['PCA1'] = X_2D[:, 0]\n", | |
| "iris['PCA2'] = X_2D[:, 1]\n", | |
| "sns.lmplot(\"PCA1\", \"PCA2\", hue='species', data=iris, fit_reg=False);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "T6aDuKu5gO0_" | |
| }, | |
| "source": [ | |
| "Vemos que en la representación bidimensional, las especies están bastante bien separadas, a pesar de que el algoritmo PCA no tenía conocimiento de las etiquetas de las especies!\n", | |
| "Esto nos indica que una clasificación relativamente sencilla será probablemente efectiva en el conjunto de datos, como vimos antes." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "mITCSyKKgO0_" | |
| }, | |
| "source": [ | |
| "### Aprendizaje sin supervisión: Agrupamiento del iris\n", | |
| "\n", | |
| "Veamos a continuación la aplicación de la agrupación en clúster a los datos del Iris.\n", | |
| "Un algoritmo de agrupamiento intenta encontrar grupos distintos de datos sin referencia a ninguna etiqueta.\n", | |
| "Aquí usaremos un poderoso método de agrupación llamado modelo de mezcla gaussiano (GMM). Un GMM intenta modelar los datos como una colección de regiones gaussianas.\n", | |
| "\n", | |
| "Podemos ajustar el modelo de mezcla gaussiano de la siguiente manera:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "r8jxHeqjgO1A" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.mixture import GaussianMixture as GMM # 1. Choose the model class\n", | |
| "\n", | |
| "model = GMM(n_components=3) # 2. Instantiate the model with hyperparameters\n", | |
| "model.fit(X_iris) # 3. Fit to data. Notice y is not specified!\n", | |
| "y_gmm = model.predict(X_iris) # 4. Determine cluster labels" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "bhB4b0otgO1D" | |
| }, | |
| "source": [ | |
| "Como antes, añadiremos la etiqueta del cluster al ``DataFrame`` Iris y usaremos Seaborn para graficar los resultados:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "ecE0UBs-gO1E", | |
| "outputId": "6a1ec594-842a-478b-e79a-00327baf370d" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "iris['cluster'] = y_gmm\n", | |
| "sns.lmplot(\"PCA1\", \"PCA2\", data=iris, hue='species',\n", | |
| " col='cluster', fit_reg=False);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "hi2hu6cJgO1I" | |
| }, | |
| "source": [ | |
| "Al dividir los datos por número de conglomerados, vemos exactamente qué tan bien el algoritmo del MMG ha recuperado la etiqueta subyacente: la especie *setosa* está perfectamente separada en su propia región, mientras que queda una pequeña cantidad de mezcla entre *versicolor* y *virgenica*.\n", | |
| "Esto significa que incluso sin un experto que nos diga las etiquetas de las especies de las flores individuales, las medidas de estas flores son lo suficientemente distintas como para que podamos *automáticamente* identificar la presencia de estos diferentes grupos de especies con un simple algoritmo de agrupamiento!\n", | |
| "Este tipo de algoritmo podría dar más pistas a los expertos en la materia sobre la relación entre las muestras que están observando." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "<div style=\"font-size: 1em; margin: 1em 0 1em 0; border: 1px solid #86989B; background-color: #f7f7f7; padding: 0;\">\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; font-weight: bold; background-color: #AFC1C4;\">\n", | |
| "Ejercicio\n", | |
| "</p>\n", | |
| "<p style=\"margin: 0.5em 1em 0.5em 1em; padding: 0;\">\n", | |
| "\n", | |
| "La función `load_digits` de `sklearn.datasets` carga un dataset con imágenes de números escritos a mano alzada. Los datos de las imágenes, en `digits.images`, están en una matriz tridimensional: 1.797 muestras, cada una de las cuales consta de una cuadrícula de 8 × 8 píxeles. Las etiquetas correspondientes se encuentran en `digits.target`. Se pide, usando este dataset, construir un sistema para el reconocimiento óptico de caractéres (OCR) usando un modelo Gaussian Naive Bayes de aprendizaje automático y reportar la exactitud (*accuracy*) del sistema para el dataset usado dada una división arbitraria del conjunto de entrenamiento y testeo (`train_test_split`).\n", | |
| "\n", | |
| "(*Pista*: La matrix de características debe ser `n_samples` × `n_features`, por tanto habrá que considerar **cada píxel** de la imagen como una característica, de manera que la matrix sea de la forma `[1797, 64]`)\n", | |
| "\n", | |
| "</p>\n", | |
| "</div>\n", | |
| "\n", | |
| "<details>\n", | |
| " <summary style=\"float: right; position: relative;\"><em>Solution</em></summary>\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; background-color: #EEEFF0;\">\n", | |
| "<code>\n", | |
| "from sklearn.metrics import accuracy_score\n", | |
| "from sklearn.naive_bayes import GaussianNB\n", | |
| "X = digits.images.reshape((digits.images.shape[0], digits.images.shape[1] * digits.images.shape[2]))\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=0)\n", | |
| "model = GaussianNB()\n", | |
| "model.fit(Xtrain, ytrain)\n", | |
| "y_model = model.predict(Xtest)\n", | |
| "accuracy_score(ytest, y_model)\n", | |
| "</code>\n", | |
| "</p>\n", | |
| "\n", | |
| "</details>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "3jVVoyx5gO1N", | |
| "outputId": "02158129-d4df-4787-c159-9d7fb4662a5e" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets import load_digits\n", | |
| "\n", | |
| "digits = load_digits()\n", | |
| "print(\"digits.image:\", digits.images.shape)\n", | |
| "print(\"digits.target:\", digits.target)\n", | |
| "\n", | |
| "fig, axes = plt.subplots(10, 10, figsize=(4, 4),\n", | |
| " subplot_kw={'xticks':[], 'yticks':[]},\n", | |
| " gridspec_kw=dict(hspace=0.1, wspace=0.1))\n", | |
| "\n", | |
| "for i, ax in enumerate(axes.flat):\n", | |
| " ax.imshow(digits.images[i], cmap='binary', interpolation='nearest')\n", | |
| " ax.text(0.025, 0.025, str(digits.target[i]),\n", | |
| " transform=ax.transAxes, color='green')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "2cMyIGF3gO1k" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Escriba su respuesta aquí\n", | |
| "from sklearn.metrics import accuracy_score\n", | |
| "from sklearn.naive_bayes import GaussianNB\n", | |
| "\n", | |
| "X = digits.images.reshape((digits.images.shape[0],\n", | |
| " digits.images.shape[1] * digits.images.shape[2]))\n", | |
| "y = digits.target\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=0)\n", | |
| "\n", | |
| "model = GaussianNB()\n", | |
| "model.fit(Xtrain, ytrain)\n", | |
| "y_model = model.predict(Xtest)\n", | |
| "accuracy_score(ytest, y_model)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "2tr4j6lygO1r" | |
| }, | |
| "source": [ | |
| "Incluso con este modelo extremadamente simple, encontramos una precisión de aproximadamente el 80% para la clasificación de los dígitos.\n", | |
| "\n", | |
| "Sin embargo, este único número no nos dice *donde* hemos ido mal. Una buena manera de solventar esto es usar la *matriz de confusión*, que podemos calcular con Scikit-Learn y pintar con Seaborn:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "mxcR7q3cgO1s", | |
| "outputId": "11841967-045a-4afb-df74-3253bfe49959" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.metrics import confusion_matrix\n", | |
| "\n", | |
| "# mat = confusion_matrix(ytest, y_model)\n", | |
| "\n", | |
| "# sns.heatmap(mat, square=True, annot=True, cbar=False)\n", | |
| "# plt.xlabel('predicted value')\n", | |
| "# plt.ylabel('true value');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "mJqKEgHogRRZ" | |
| }, | |
| "source": [ | |
| "# Hiperparámetros y validación del modelo" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "collapsed": true, | |
| "id": "LVh51Pt-gRRa" | |
| }, | |
| "source": [ | |
| "En la sección anterior, vimos la receta básica para aplicar un modelo de aprendizaje supervisado de máquina:\n", | |
| "\n", | |
| "1. Elija una clase de modelo\n", | |
| "2. Elija los hiperparámetros del modelo\n", | |
| "3. Adaptar el modelo a los datos de entrenamiento\n", | |
| "4. Utilice el modelo para predecir etiquetas para nuevos datos\n", | |
| "\n", | |
| "Las dos primeras piezas de esto -la elección del modelo y la elección de los hiperparámetros- son quizás la parte más importante de la utilización eficaz de estas herramientas y técnicas.\n", | |
| "Para hacer una elección informada, necesitamos una manera de *validar* que nuestro modelo y nuestros hiperparámetros encajan bien con los datos.\n", | |
| "Si bien esto puede parecer simple, hay algunas trampas que usted debe evitar para hacer esto de manera efectiva." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "N-etkq8rgRRb" | |
| }, | |
| "source": [ | |
| "## Pensando en la validación de modelos\n", | |
| "\n", | |
| "En principio, la validación del modelo es muy simple: después de elegir un modelo y sus hiperparámetros, podemos estimar su eficacia aplicándolo a algunos de los datos de entrenamiento y comparando la predicción con el valor conocido.\n", | |
| "\n", | |
| "Las siguientes secciones muestran primero un enfoque ingenuo de la validación de modelos y por qué\n", | |
| "falla, antes de explorar el uso de conjuntos de retención y validación cruzada para obtener una mayor robustez\n", | |
| "evaluación del modelo." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "SA7ex2OogRRb" | |
| }, | |
| "source": [ | |
| "### Validación de modelos (la forma incorrecta)\n", | |
| "\n", | |
| "Vamos a demostrar el enfoque ingenuo de la validación utilizando los datos de Iris, que vimos en la sección anterior.\n", | |
| "Comenzaremos por cargar los datos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "cO2RlsWggRRc" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets import load_iris\n", | |
| "\n", | |
| "iris = load_iris()\n", | |
| "X = iris.data\n", | |
| "y = iris.target" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "nSgW9zwNgRRg" | |
| }, | |
| "source": [ | |
| "A continuación elegimos un modelo e hiperparámetros. Aquí usaremos un clasificador de vecinos *k* con ``n_neighbors=1``.\n", | |
| "Se trata de un modelo muy sencillo e intuitivo que dice que \"la etiqueta de un punto desconocido es la misma que la de su punto de entrenamiento más cercano\"." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "KXGRJA0_gRRh" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.neighbors import KNeighborsClassifier\n", | |
| "\n", | |
| "model = KNeighborsClassifier(n_neighbors=1)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "joeB0LQsgRRk" | |
| }, | |
| "source": [ | |
| "Luego entrenamos el modelo y lo usamos para predecir etiquetas de datos que ya conocemos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "6JP5-ab7gRRm" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model.fit(X, y)\n", | |
| "y_model = model.predict(X)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "UNyrdjSJgRRq" | |
| }, | |
| "source": [ | |
| "Finalmente, calculamos la fracción de puntos correctamente etiquetados:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "aMM7i5RvgRRr", | |
| "outputId": "a3778837-2def-4fb9-c164-583a9dd12581" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.metrics import accuracy_score\n", | |
| "\n", | |
| "accuracy_score(y, y_model)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "S78Z9_ingRRw" | |
| }, | |
| "source": [ | |
| "Vemos una puntuación de precisión de 1,0, lo que indica que el 100% de los puntos fueron correctamente etiquetados por nuestro modelo!\n", | |
| "Pero, ¿es esto realmente medir la precisión esperada? ¿Realmente hemos encontrado un modelo que esperamos que sea correcto el 100% de las veces?\n", | |
| "\n", | |
| "Como habrás deducido, la respuesta es no.\n", | |
| "De hecho, este enfoque contiene un defecto fundamental: *trata y evalúa el modelo sobre los mismos datos*.\n", | |
| "Además, el modelo vecino más cercano es un estimador *basado en instancias* que simplemente almacena los datos de entrenamiento y predice las etiquetas comparando los nuevos datos con estos puntos almacenados: excepto en casos artificiales, obtendrá un 100% de precisión *cada vez*." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "M51jQSYDgRRx" | |
| }, | |
| "source": [ | |
| "### Validación de modelos (la forma correcta): Conjuntos de retención\n", | |
| "\n", | |
| "Entonces, ¿qué se puede hacer?\n", | |
| "Un mejor sentido del rendimiento de un modelo se puede encontrar usando lo que se conoce como un *set de retención*: es decir, retenemos algún subconjunto de los datos de la formación del modelo, y luego usamos este set de retención para comprobar el rendimiento del modelo.\n", | |
| "Esta división se puede hacer usando la utilidad ``train_test_split`` de Scikit-Learn:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "XitQHZ3fgRRy", | |
| "outputId": "a7d9ba6a-ac52-49ce-e798-211e1fe45ab0" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# split the data with 50% in each set\n", | |
| "X1, X2, y1, y2 = train_test_split(X, y, random_state=0,\n", | |
| " train_size=0.5)\n", | |
| "\n", | |
| "# fit the model on one set of data\n", | |
| "model.fit(X1, y1)\n", | |
| "\n", | |
| "# evaluate the model on the second set of data\n", | |
| "y2_model = model.predict(X2)\n", | |
| "accuracy_score(y2, y2_model)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "KWsKTMm-gRR4" | |
| }, | |
| "source": [ | |
| "Vemos aquí un resultado más razonable: el clasificador del vecino más cercano tiene una precisión de aproximadamente el 90% en este conjunto de retención.\n", | |
| "El conjunto de retención es similar a los datos desconocidos, porque el modelo no lo ha \"visto\" antes." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "yovQw5qIgRR6" | |
| }, | |
| "source": [ | |
| "### Validación de modelos mediante validación cruzada\n", | |
| "\n", | |
| "Una desventaja de usar un conjunto de retenciones para la validación del modelo es que hemos perdido una porción de nuestros datos en el entrenamiento del modelo.\n", | |
| "En el caso anterior, la mitad del conjunto de datos no contribuye a la formación del modelo!\n", | |
| "Esto no es óptimo y puede causar problemas, especialmente si el conjunto inicial de datos de entrenamiento es pequeño.\n", | |
| "\n", | |
| "Una manera de abordar esto es usar *validación cruzada*; es decir, hacer una secuencia de ajustes en la que cada subconjunto de los datos se utiliza como un conjunto de entrenamiento y como un conjunto de validación.\n", | |
| "Visualmente, podría parecerse a esto:\n", | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n", | |
| "\n", | |
| "Aquí hacemos dos pruebas de validación, usando alternativamente cada mitad de los datos como un conjunto de retención.\n", | |
| "Usando los datos divididos de antes, podríamos implementarlos así:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "M2ZATou5gRR6", | |
| "outputId": "6bd1de0d-7ef1-4e91-d6bb-4142c19ebb82" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "y2_model = model.fit(X1, y1).predict(X2)\n", | |
| "y1_model = model.fit(X2, y2).predict(X1)\n", | |
| "accuracy_score(y1, y1_model), accuracy_score(y2, y2_model)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "HNHWklZbgRSC" | |
| }, | |
| "source": [ | |
| "Lo que resulta son dos puntuaciones de precisión, que podríamos combinar (por ejemplo, tomando la media) para obtener una mejor medida del rendimiento del modelo global.\n", | |
| "Esta forma particular de validación cruzada es una *validación cruzada doble*, es decir, una en la que hemos dividido los datos en dos conjuntos y usado cada uno de ellos como un conjunto de validación.\n", | |
| "\n", | |
| "Podríamos ampliar esta idea para usar aún más ensayos y más pliegues en los datos; por ejemplo, aquí hay una representación visual de una validación cruzada quíntuple:\n", | |
| "\n", | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n", | |
| "\n", | |
| "Aquí dividimos los datos en cinco grupos, y usamos cada uno de ellos a su vez para evaluar el ajuste del modelo en los otros 4/5 de los datos.\n", | |
| "Esto sería bastante tedioso de hacer a mano, así que podemos usar la rutina de conveniencia ``cross_val_score`` de Scikit-Learn para hacerlo sucintamente:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "qEdq8ZwCgRSD", | |
| "outputId": "751b7b12-35df-4112-f7ec-0e54fc7bef1a" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.model_selection import cross_val_score\n", | |
| "\n", | |
| "scores = cross_val_score(model, X, y, cv=5)\n", | |
| "scores" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "h96Gm79pgRSK" | |
| }, | |
| "source": [ | |
| "La repetición de la validación a través de diferentes subconjuntos de los datos nos da una idea aún mejor del rendimiento del algoritmo." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "scores.mean()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "D3kfTRxrgRSU" | |
| }, | |
| "source": [ | |
| "## Selección del mejor modelo\n", | |
| "\n", | |
| "Ahora que hemos visto los fundamentos de la validación y la validación cruzada, entraremos en un poco más de profundidad con respecto a la selección del modelo y la selección de hiperparámetros.\n", | |
| "Estos temas son algunos de los aspectos más importantes de la práctica del aprendizaje automático, y creo que esta información a menudo se pasa por alto en los tutoriales introductorios de aprendizaje automático.\n", | |
| "\n", | |
| "De importancia central es la siguiente pregunta: *si nuestro estimador no está rindiendo lo suficiente, ¿cómo deberíamos seguir adelante?*\n", | |
| "Hay varias respuestas posibles:\n", | |
| "\n", | |
| "- Utilizar un modelo más complicado/más flexible\n", | |
| "- Usar un modelo menos complicado/menos flexible\n", | |
| "- Recopilar más muestras de entrenamiento\n", | |
| "- Recopilar más datos para añadir características a cada muestra\n", | |
| "\n", | |
| "La respuesta a esta pregunta es a menudo contraintuitiva.\n", | |
| "En particular, a veces el uso de un modelo más complicado dará peores resultados, y la adición de más muestras de entrenamiento puede no mejorar sus resultados!\n", | |
| "La capacidad de determinar qué pasos mejorarán su modelo es lo que separa a los practicantes exitosos de aprendizaje de máquinas de los que no lo logran." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "VhiLQpaYgRSV" | |
| }, | |
| "source": [ | |
| "#### El compromiso entre sesgo y varianza\n", | |
| "\n", | |
| "Fundamentalmente, la cuestión del \"mejor modelo\" se trata de encontrar un punto de equilibrio entre *bias* y *varianza*.\n", | |
| "Considere la siguiente figura, que presenta dos ajustes de regresión al mismo conjunto de datos:\n", | |
| "\n", | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n", | |
| "\n", | |
| "Está claro que ninguno de estos modelos encaja particularmente bien en los datos, pero fracasan de diferentes maneras.\n", | |
| "\n", | |
| "El modelo de la izquierda intenta encontrar un ajuste en línea recta a través de los datos.\n", | |
| "Debido a que los datos son intrínsecamente más complicados que una línea recta, el modelo de línea recta nunca podrá describir bien este conjunto de datos.\n", | |
| "Se dice que dicho modelo *ajusta insuficientemente* (*underfits*) los datos: es decir, no tiene la flexibilidad suficiente para dar cuenta adecuadamente de todas las características de los datos; otra forma de decir esto es que el modelo tiene un alto *sesgo*.\n", | |
| "\n", | |
| "El modelo de la derecha intenta encajar un polinomio de alto orden a través de los datos.\n", | |
| "En este caso, el ajuste del modelo tiene suficiente flexibilidad para tener en cuenta casi perfectamente las características finas de los datos, pero aunque describe con mucha precisión los datos de entrenamiento, su forma precisa parece reflejar más las propiedades particulares de ruido de los datos que las propiedades intrínsecas de cualquier proceso que haya generado esos datos.\n", | |
| "Se dice que un modelo de este tipo *ajusta excesivamente* los datos: es decir, tiene tanta flexibilidad que el modelo termina contabilizando los errores aleatorios así como la distribución de datos subyacente; otra forma de decir esto es que el modelo tiene una alta *varianza*." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "O23vVF-9gRSW" | |
| }, | |
| "source": [ | |
| "Para ver esto desde otro punto de vista, considere lo que sucede si usamos estos dos modelos para predecir el valor y para algunos datos nuevos.\n", | |
| "En los siguientes diagramas, los puntos rojos/menos claros indican datos que se omiten del conjunto de entrenamiento:\n", | |
| "\n", | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n", | |
| "\n", | |
| "El puntaje aquí es el puntaje de $R^2$, o [coeficiente de determinación](https://en.wikipedia.org/wiki/Coefficient_of_determination), que mide qué tan bien se desempeña un modelo en relación con una media simple de los valores objetivo. $R^2=1$ indica una coincidencia perfecta, $R^2=0$ indica que el modelo no es mejor que simplemente tomar la media de los datos, y los valores negativos significan modelos aún peores.\n", | |
| "A partir de las puntuaciones asociadas a estos dos modelos, podemos hacer una observación que se mantiene de forma más general:\n", | |
| "\n", | |
| "- Para los modelos de alto sesgo, el rendimiento del modelo en el conjunto de validación es similar al rendimiento en el conjunto de entrenamiento.\n", | |
| "- Para los modelos de alta variación, el rendimiento del modelo en el conjunto de validación es mucho peor que el rendimiento en el conjunto de entrenamiento." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "8CS38cvwgRSY" | |
| }, | |
| "source": [ | |
| "Si imaginamos que tenemos alguna capacidad para ajustar la complejidad del modelo, esperaríamos que la puntuación de la formación y la puntuación de validación se comportaran como se ilustra en la siguiente figura:\n", | |
| "\n", | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n", | |
| "\n", | |
| "El diagrama que se muestra aquí a menudo se llama *curva de validación*, y vemos las siguientes características esenciales:\n", | |
| "\n", | |
| "- La puntuación de la formación es en todas partes más alta que la puntuación de validación. Este es generalmente el caso: el modelo se ajustará mejor a los datos que ha visto que a los datos que no ha visto.\n", | |
| "- Para una complejidad de modelo muy baja (un modelo de alto sesgo), los datos de entrenamiento son inadecuados, lo que significa que el modelo es un predictor pobre tanto para los datos de entrenamiento como para cualquier dato que no se haya visto anteriormente.\n", | |
| "- Para una complejidad de modelo muy alta (un modelo de alta varianza), los datos de entrenamiento son demasiado ajustados, lo que significa que el modelo predice los datos de entrenamiento muy bien, pero falla para cualquier dato que no se haya visto anteriormente.\n", | |
| "- Para algunos valores intermedios, la curva de validación tiene un máximo. Este nivel de complejidad indica un equilibrio adecuado entre sesgo y varianza.\n", | |
| "\n", | |
| "La forma de afinar la complejidad del modelo varía de un modelo a otro; cuando discutamos en profundidad los modelos individuales en secciones posteriores, veremos cómo cada modelo permite dicha afinación." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "collapsed": true, | |
| "id": "DbheB2I0gRSZ" | |
| }, | |
| "source": [ | |
| "### Curvas de validación en Scikit-Learn\n", | |
| "\n", | |
| "Veamos un ejemplo de cómo utilizar la validación cruzada para calcular la curva de validación de una clase de modelos.\n", | |
| "Aquí usaremos un modelo de regresión polinómica: se trata de un modelo lineal generalizado en el que el grado del polinomio es un parámetro sintonizable.\n", | |
| "Por ejemplo, un polinomio de grado 1 ajusta una línea recta a los datos; para los parámetros del modelo $a$ y $b$:\n", | |
| "\n", | |
| "$$\n", | |
| "y = ax + b\n", | |
| "$$\n", | |
| "\n", | |
| "Un polinomio de grado 3 ajusta una curva cúbica a los datos; para los parámetros del modelo $a, b, c, d$:\n", | |
| "\n", | |
| "$$\n", | |
| "y = ax^3 + bx^2 + cx + d\n", | |
| "$$\n", | |
| "\n", | |
| "Podemos generalizar esto a cualquier número de características polinómicas.\n", | |
| "En Scikit-Learn, podemos implementar esto con una simple regresión lineal combinada con el preprocesador polinómico.\n", | |
| "Usaremos un *pipeline* para encadenar estas operaciones:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "ICX0LxTLgRSa" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.preprocessing import PolynomialFeatures\n", | |
| "from sklearn.linear_model import LinearRegression\n", | |
| "from sklearn.pipeline import make_pipeline\n", | |
| "\n", | |
| "def PolynomialRegression(degree=2, **kwargs):\n", | |
| " return make_pipeline(PolynomialFeatures(degree),\n", | |
| " LinearRegression(**kwargs))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "collapsed": true, | |
| "id": "pBQDW2iYgRSd" | |
| }, | |
| "source": [ | |
| "Ahora vamos a crear algunos datos a los que ajustaremos nuestro modelo:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "K8O1QGQngRSe" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import numpy as np\n", | |
| "\n", | |
| "def make_data(N, err=1.0, rseed=1):\n", | |
| " # randomly sample the data\n", | |
| " rng = np.random.RandomState(rseed)\n", | |
| " X = rng.rand(N, 1) ** 2\n", | |
| " y = 10 - 1. / (X.ravel() + 0.1)\n", | |
| " if err > 0:\n", | |
| " y += err * rng.randn(N)\n", | |
| " return X, y\n", | |
| "\n", | |
| "X, y = make_data(40)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "mWBqlaZrgRSj" | |
| }, | |
| "source": [ | |
| "Ahora podemos visualizar nuestros datos, junto con los ajustes polinómicos de varios grados:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "v1Gl12RtgRSl", | |
| "outputId": "9a3c63f4-0917-42eb-e3d8-6118da556c51" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X_test = np.linspace(-0.1, 1.1, 500)[:, None]\n", | |
| "\n", | |
| "plt.scatter(X.ravel(), y, color='black')\n", | |
| "axis = plt.axis()\n", | |
| "for degree in [1, 3, 5]:\n", | |
| " y_test = PolynomialRegression(degree).fit(X, y).predict(X_test)\n", | |
| " plt.plot(X_test.ravel(), y_test, label='degree={0}'.format(degree))\n", | |
| "plt.xlim(-0.1, 1.0)\n", | |
| "plt.ylim(-2, 12)\n", | |
| "plt.legend(loc='best');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "WmE1wPpagRSv" | |
| }, | |
| "source": [ | |
| "Lo que controla la complejidad del modelo en este caso es el grado del polinomio, que puede ser cualquier número entero no negativo.\n", | |
| "Una pregunta útil para responder es la siguiente: ¿qué grado de polinomio proporciona un equilibrio adecuado entre sesgo (ajuste insuficiente) y varianza (ajuste excesivo)?\n", | |
| "\n", | |
| "Podemos avanzar en esto visualizando la curva de validación para este dato y modelo en particular; esto se puede hacer directamente usando la rutina de conveniencia ``validation_curve`` proporcionada por Scikit-Learn.\n", | |
| "Dado un modelo, datos, nombre del parámetro y un rango para explorar, esta función calculará automáticamente tanto la puntuación de entrenamiento como la puntuación de validación en todo el rango:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "GXPUIgNhgRSx", | |
| "outputId": "85931098-8c88-40da-aab3-277b8ea8668b" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.model_selection import validation_curve\n", | |
| "degree = np.arange(0, 21)\n", | |
| "train_score, val_score = validation_curve(PolynomialRegression(), X, y,\n", | |
| " 'polynomialfeatures__degree', degree, cv=7)\n", | |
| "\n", | |
| "plt.plot(degree, np.median(train_score, 1), color='blue', label='training score')\n", | |
| "plt.plot(degree, np.median(val_score, 1), color='red', label='validation score')\n", | |
| "plt.legend(loc='best')\n", | |
| "plt.ylim(0, 1)\n", | |
| "plt.xlabel('degree')\n", | |
| "plt.ylabel('score');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Yu5SttukgRS3" | |
| }, | |
| "source": [ | |
| "Esto muestra precisamente el comportamiento cualitativo que esperamos: la puntuación de la formación es en todas partes superior a la puntuación de validación; la puntuación de la formación mejora de forma monótona con el aumento de la complejidad del modelo; y la puntuación de la validación alcanza un máximo antes de caer cuando el modelo se vuelve demasiado ajustado.\n", | |
| "\n", | |
| "A partir de la curva de validación, podemos leer que el equilibrio óptimo entre sesgo y varianza se encuentra para un polinomio de tercer orden; podemos calcular y mostrar este ajuste sobre los datos originales de la siguiente manera:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "tGf8vUaYgRS3", | |
| "outputId": "b439542e-7630-4bc6-c1c2-1a67f7449310" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "plt.scatter(X.ravel(), y)\n", | |
| "lim = plt.axis()\n", | |
| "y_test = PolynomialRegression(3).fit(X, y).predict(X_test)\n", | |
| "plt.plot(X_test.ravel(), y_test);\n", | |
| "plt.axis(lim);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "85jxNHWVgRS7" | |
| }, | |
| "source": [ | |
| "Note que encontrar este modelo óptimo no requirió que calculáramos la puntuación de entrenamiento, pero examinar la relación entre la puntuación de entrenamiento y la puntuación de validación puede darnos una idea útil del rendimiento del modelo." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "rs2XPPZogRS-" | |
| }, | |
| "source": [ | |
| "## Curvas de aprendizaje\n", | |
| "\n", | |
| "Un aspecto importante de la complejidad del modelo es que el modelo óptimo generalmente dependerá del tamaño de sus datos de entrenamiento.\n", | |
| "Por ejemplo, vamos a generar un nuevo conjunto de datos con un factor de cinco puntos más:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "HdKjjL2mgRS_", | |
| "outputId": "245ffedb-22ed-4114-e213-930acf1a29ed" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X2, y2 = make_data(200)\n", | |
| "plt.scatter(X2.ravel(), y2);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "p0kg3vajgRTG" | |
| }, | |
| "source": [ | |
| "Duplicaremos el código anterior para trazar la curva de validación para este conjunto de datos más grande; para referencia, trazaremos también los resultados anteriores:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "mZXzYwoDgRTH", | |
| "outputId": "90c0907f-0188-49e6-fb11-fa9f834bdc99" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "degree = np.arange(21)\n", | |
| "train_score2, val_score2 = validation_curve(PolynomialRegression(), X2, y2,\n", | |
| " 'polynomialfeatures__degree', degree, cv=7)\n", | |
| "\n", | |
| "plt.plot(degree, np.median(train_score2, 1), color='blue', label='training score')\n", | |
| "plt.plot(degree, np.median(val_score2, 1), color='red', label='validation score')\n", | |
| "plt.plot(degree, np.median(train_score, 1), color='blue', alpha=0.3, linestyle='dashed')\n", | |
| "plt.plot(degree, np.median(val_score, 1), color='red', alpha=0.3, linestyle='dashed')\n", | |
| "plt.legend(loc='lower center')\n", | |
| "plt.ylim(0, 1)\n", | |
| "plt.xlabel('degree')\n", | |
| "plt.ylabel('score');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "lFBQLNfggRTK" | |
| }, | |
| "source": [ | |
| "Las líneas sólidas muestran los nuevos resultados, mientras que las líneas discontinuas más tenues muestran los resultados del anterior conjunto de datos más pequeño.\n", | |
| "De la curva de validación se desprende claramente que el conjunto de datos más grande puede soportar un modelo mucho más complicado: el pico aquí es probablemente de alrededor de un grado de 6, pero incluso un modelo de grado 20 no estaría sobre-ajustando los datos - la validación y las puntuaciones de formación siguen siendo muy cercanas.\n", | |
| "\n", | |
| "Así vemos que el comportamiento de la curva de validación no tiene una sino dos entradas importantes: la complejidad del modelo y el número de puntos de entrenamiento.\n", | |
| "A menudo es útil explorar el comportamiento del modelo en función del número de puntos de entrenamiento, lo que podemos hacer utilizando subconjuntos cada vez más grandes de los datos para adaptarlos a nuestro modelo.\n", | |
| "Un gráfico de la puntuación de entrenamiento/validación con respecto al tamaño del conjunto de entrenamiento se conoce como *curva de aprendizaje*.\n", | |
| "\n", | |
| "El comportamiento general que esperaríamos de una curva de aprendizaje es este:\n", | |
| "\n", | |
| "- Un modelo de una determinada complejidad sobrecargará un pequeño conjunto de datos: esto significa que la puntuación de la formación será relativamente alta, mientras que la puntuación de validación será relativamente baja.\n", | |
| "- Un modelo de una determinada complejidad *adaptará* un gran conjunto de datos: esto significa que la puntuación de la formación disminuirá, pero la puntuación de la validación aumentará.\n", | |
| "- Un modelo nunca, excepto por casualidad, dará una mejor puntuación al conjunto de validación que al conjunto de entrenamiento: esto significa que las curvas deben seguir acercándose pero nunca cruzarse.\n", | |
| "\n", | |
| "Con estas características en mente, esperaríamos que la curva de aprendizaje se pareciera cualitativamente a la que se muestra en la siguiente figura:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "EkKABN0ZgRTL" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "0wibM77AgRTM" | |
| }, | |
| "source": [ | |
| "La característica notable de la curva de aprendizaje es la convergencia hacia una puntuación particular a medida que aumenta el número de muestras de formación.\n", | |
| "En particular, una vez que tenga suficientes puntos que un modelo en particular haya convergido, *¡añadir más datos de entrenamiento no le ayudará!\n", | |
| "La única manera de aumentar el rendimiento del modelo en este caso es utilizar otro modelo (a menudo más complejo)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "50BfnvC3gRTN" | |
| }, | |
| "source": [ | |
| "### Curvas de aprendizaje en Scikit-Learn\n", | |
| "\n", | |
| "Scikit-Learn ofrece una utilidad conveniente para calcular tales curvas de aprendizaje a partir de sus modelos; aquí calcularemos una curva de aprendizaje para nuestro conjunto de datos original con un modelo polinomial de segundo orden y un polinomio de noveno orden:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "uj_4m675gRTQ", | |
| "outputId": "413ada90-ce3b-4582-922b-f0c13c9fd2d2" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.model_selection import learning_curve\n", | |
| "\n", | |
| "fig, ax = plt.subplots(1, 2, figsize=(16, 6))\n", | |
| "fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)\n", | |
| "\n", | |
| "for i, degree in enumerate([2, 9]):\n", | |
| " N, train_lc, val_lc = learning_curve(PolynomialRegression(degree),\n", | |
| " X, y, cv=7,\n", | |
| " train_sizes=np.linspace(0.3, 1, 25))\n", | |
| "\n", | |
| " ax[i].plot(N, np.mean(train_lc, 1), color='blue', label='training score')\n", | |
| " ax[i].plot(N, np.mean(val_lc, 1), color='red', label='validation score')\n", | |
| " ax[i].hlines(np.mean([train_lc[-1], val_lc[-1]]), N[0], N[-1],\n", | |
| " color='gray', linestyle='dashed')\n", | |
| "\n", | |
| " ax[i].set_ylim(0, 1)\n", | |
| " ax[i].set_xlim(N[0], N[-1])\n", | |
| " ax[i].set_xlabel('training size')\n", | |
| " ax[i].set_ylabel('score')\n", | |
| " ax[i].set_title('degree = {0}'.format(degree), size=14)\n", | |
| " ax[i].legend(loc='best')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "JhKJDjmHgRTV" | |
| }, | |
| "source": [ | |
| "Este es un diagnóstico valioso, porque nos da una descripción visual de cómo nuestro modelo responde al aumento de los datos de entrenamiento.\n", | |
| "En particular, cuando su curva de aprendizaje ya ha convergido (es decir, cuando las curvas de entrenamiento y validación ya están cerca una de la otra) *¡Añadir más datos de entrenamiento no mejorará significativamente el ajuste!\n", | |
| "Esta situación se observa en el panel izquierdo, con la curva de aprendizaje para el modelo de grado 2.\n", | |
| "\n", | |
| "La única manera de aumentar la puntuación convergente es utilizar un modelo diferente (normalmente más complicado).\n", | |
| "Vemos esto en el panel de la derecha: al pasar a un modelo mucho más complicado, aumentamos la puntuación de convergencia (indicada por la línea punteada), pero a expensas de una mayor varianza del modelo (indicada por la diferencia entre las puntuaciones de formación y de validación).\n", | |
| "Si agregáramos aún más puntos de datos, la curva de aprendizaje para el modelo más complicado eventualmente convergería.\n", | |
| "\n", | |
| "Trazar una curva de aprendizaje para su elección particular de modelo y conjunto de datos puede ayudarle a tomar este tipo de decisión sobre cómo avanzar en la mejora de su análisis." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "pOZYINaRgRTV" | |
| }, | |
| "source": [ | |
| "## Validación en la práctica: Búsqueda en cuadrícula (*GridSearchCV*)\n", | |
| "\n", | |
| "La discusión anterior tiene el propósito de darle cierta intuición sobre el equilibrio entre sesgo y varianza, y su dependencia de la complejidad del modelo y el tamaño del conjunto de capacitación.\n", | |
| "En la práctica, los modelos generalmente tienen más de un interruptor que pulsar y, por lo tanto, los gráficos de validación y las curvas de aprendizaje cambian de líneas a superficies multidimensionales.\n", | |
| "En estos casos, estas visualizaciones son difíciles y preferimos simplemente encontrar el modelo particular que maximiza la puntuación de validación.\n", | |
| "\n", | |
| "Scikit-Learn proporciona herramientas automatizadas para hacer esto en el módulo de búsqueda en cuadrícula.\n", | |
| "A continuación se muestra un ejemplo de cómo utilizar la búsqueda en cuadrícula para encontrar el modelo polinómico óptimo.\n", | |
| "Exploraremos una cuadrícula tridimensional de las características del modelo; a saber, el grado polinómico, la bandera que nos dice si debemos ajustar la intercepción y la bandera que nos dice si debemos normalizar el problema.\n", | |
| "Esto puede ser configurado usando el meta-estimador ``GridSearchCV`` de Scikit-Learn:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "497RrKcqgRTX" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.model_selection import GridSearchCV\n", | |
| "\n", | |
| "param_grid = {'polynomialfeatures__degree': np.arange(21),\n", | |
| " 'linearregression__fit_intercept': [True, False],\n", | |
| " 'linearregression__normalize': [True, False]}\n", | |
| "\n", | |
| "grid = GridSearchCV(PolynomialRegression(), param_grid, cv=7)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "x2y0QL4pgRTa" | |
| }, | |
| "source": [ | |
| "Note que al igual que un estimador normal, esto aún no se ha aplicado a ningún dato.\n", | |
| "Llamar al método ``fit()`` se ajustará al modelo en cada punto de la cuadrícula, manteniendo un registro de las puntuaciones a lo largo del camino:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "5vXGOsRwgRTc" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "grid.fit(X, y);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Gy3LJGcDgRTf" | |
| }, | |
| "source": [ | |
| "Ahora que esto está bien, podemos pedir los mejores parámetros de la siguiente manera:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "lFb9tuBBgRTh", | |
| "outputId": "5073b49b-64ee-4f6e-9b5f-77a8b9da1599" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "grid.best_params_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "QqmNa8H3gRTm" | |
| }, | |
| "source": [ | |
| "Finalmente, si lo deseamos, podemos utilizar el mejor modelo y mostrar el ajuste a nuestros datos utilizando código de antes:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "qXY0pj9RgRTm", | |
| "outputId": "6f824de0-5d52-4472-ef76-b0521ce0ba81" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model = grid.best_estimator_\n", | |
| "\n", | |
| "plt.scatter(X.ravel(), y)\n", | |
| "lim = plt.axis()\n", | |
| "y_test = model.fit(X, y).predict(X_test)\n", | |
| "plt.plot(X_test.ravel(), y_test);\n", | |
| "plt.axis(lim);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "esXTz7R_gTc1" | |
| }, | |
| "source": [ | |
| "# Ingeniería de características" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "oBuCnXrUgTc2" | |
| }, | |
| "source": [ | |
| "Las secciones anteriores esbozan las ideas fundamentales del aprendizaje automático, pero todos los ejemplos asumen que usted tiene datos numéricos en un formato ordenado, ``[n_muestras, n_características]``.\n", | |
| "En el mundo real, los datos raramente llegan de esa forma.\n", | |
| "Con esto en mente, uno de los pasos más importantes en el uso del aprendizaje de la máquina en la práctica es *ingeniería de características*: es decir, tomar cualquier información que tenga sobre su problema y convertirla en números que pueda utilizar para construir su matriz de características.\n", | |
| "\n", | |
| "En esta sección, cubriremos algunos ejemplos comunes de tareas de ingeniería de características: características para representar *datos categóricos*, características para representar *texto* y características para representar *imágenes*.\n", | |
| "Además, discutiremos las *características derivadas* para aumentar la complejidad del modelo y la *imputación* de los datos faltantes.\n", | |
| "A menudo este proceso se conoce como *vectorización*, ya que implica convertir datos arbitrarios en vectores de buen comportamiento." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "hXVOu6hpgTc2" | |
| }, | |
| "source": [ | |
| "## Características categóricas\n", | |
| "\n", | |
| "Un tipo común de datos no numéricos son los datos *categoricos*.\n", | |
| "Por ejemplo, imagine que está explorando algunos datos sobre los precios de la vivienda, y junto con características numéricas como \"precio\" y \"habitaciones\", también tiene información sobre \"vecindarios\".\n", | |
| "Por ejemplo, sus datos podrían ser algo así:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "WGqSgRIjgTc3" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "data = [\n", | |
| " {'price': 850000, 'rooms': 4, 'neighborhood': 'Queen Anne'},\n", | |
| " {'price': 700000, 'rooms': 3, 'neighborhood': 'Fremont'},\n", | |
| " {'price': 650000, 'rooms': 3, 'neighborhood': 'Wallingford'},\n", | |
| " {'price': 600000, 'rooms': 2, 'neighborhood': 'Fremont'}\n", | |
| "]\n", | |
| "pd.DataFrame(data)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "ohPNIrmcgTc6" | |
| }, | |
| "source": [ | |
| "Usted podría estar tentado a codificar estos datos con un mapeo numérico directo:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "8u1jGpUpgTc6" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "{'Queen Anne': 1, 'Fremont': 2, 'Wallingford': 3};" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "cpukCWO7gTc8" | |
| }, | |
| "source": [ | |
| "Resulta que este no es generalmente un enfoque útil en Scikit-Learn: los modelos del paquete hacen la suposición fundamental de que las características numéricas reflejan cantidades algebraicas.\n", | |
| "Así, tal mapeo implicaría, por ejemplo, que *Queen Anne < Fremont < Wallingford*, o incluso que *Wallingford - Queen Anne = Fremont*, lo que no tiene mucho sentido.\n", | |
| "\n", | |
| "En este caso, una técnica probada es utilizar *one-hot encoding*, que crea efectivamente columnas adicionales que indican la presencia o ausencia de una categoría con un valor de 1 o 0, respectivamente.\n", | |
| "Cuando tus datos vienen en forma de una lista de diccionarios, el ```DictVectorizer``` de Scikit-Learn lo hará por ti:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "1V8ult5rgTc9", | |
| "outputId": "46bd8297-7933-4747-90c7-1f9fce1802db" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.feature_extraction import DictVectorizer\n", | |
| "\n", | |
| "vec = DictVectorizer(sparse=False, dtype=int)\n", | |
| "vec.fit_transform(data)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "KQwN17wAgTdA" | |
| }, | |
| "source": [ | |
| "Note que la columna'vecindario' se ha expandido en tres columnas separadas, representando las tres etiquetas de vecindario, y que cada fila tiene un 1 en la columna asociada con su vecindario.\n", | |
| "Con estas características categóricas así codificadas, puedes proceder como de costumbre con la instalación de un modelo Scikit-Learn.\n", | |
| "\n", | |
| "Para ver el significado de cada columna, puede inspeccionar los nombres de las características:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "dXeDYIPGgTdB", | |
| "outputId": "c9e4fc37-93e7-4134-d1d7-54e5ab6c9313" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "vec.get_feature_names()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "pd.DataFrame(vec.fit_transform(data), columns=vec.get_feature_names())" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "xGprvFOUgTdF" | |
| }, | |
| "source": [ | |
| "Hay una clara desventaja de este enfoque: si su categoría tiene muchos valores posibles, esto puede aumentar *en gran medida* el tamaño de su conjunto de datos.\n", | |
| "Sin embargo, debido a que los datos codificados contienen principalmente ceros, una salida dispersa puede ser una solución muy eficiente:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "ObCMr_FfgTdG", | |
| "outputId": "f210eed2-990d-46aa-ed82-87199a2b50f6" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "vec = DictVectorizer(sparse=True, dtype=int)\n", | |
| "vec.fit_transform(data)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "vdTrLCaNgTdJ" | |
| }, | |
| "source": [ | |
| "Muchos (aunque no todos) de los estimadores Scikit-Learn aceptan estos arrays dispersos a la hora de ajustar y evaluar los modelos. El ``sklearn.preprocessing.OneHotEncoder`` y el ``sklearn.feature_extraction.FeatureHasher`` son dos herramientas adicionales que Scikit-Learn incluye para soportar este tipo de codificación." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "X-bizFgvgTdJ" | |
| }, | |
| "source": [ | |
| "## Características de texto\n", | |
| "\n", | |
| "Otra necesidad común en la ingeniería de características es convertir el texto en un conjunto de valores numéricos representativos.\n", | |
| "Por ejemplo, la mayoría de la minería automática de datos de medios sociales se basa en alguna forma de codificación del texto como números.\n", | |
| "Uno de los métodos más simples de codificación de datos es por *cuentas de palabras*: tomas cada fragmento de texto, cuentas las ocurrencias de cada palabra dentro de él, y pones los resultados en una tabla.\n", | |
| "\n", | |
| "Por ejemplo, considere el siguiente conjunto de tres frases:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "v-pb-6SAgTdK" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "sample = ['problem of evil',\n", | |
| " 'evil queen',\n", | |
| " 'horizon problem']" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "zgTJq38LgTdN" | |
| }, | |
| "source": [ | |
| "Para una vectorización de estos datos basada en el número de palabras, podríamos construir una columna que represente la palabra \"problema\", la palabra \"maldad\", la palabra \"horizonte\", etc.\n", | |
| "Si bien hacer esto a mano sería posible, el tedio puede evitarse utilizando el \"CountVectorizer\" de Scikit-Learn:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "3M_P3INsgTdP", | |
| "outputId": "9915f4b0-184f-4fe7-b853-475a6ee6cb96" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.feature_extraction.text import CountVectorizer\n", | |
| "\n", | |
| "vec = CountVectorizer()\n", | |
| "X = vec.fit_transform(sample)\n", | |
| "X" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "6itJOefagTdT" | |
| }, | |
| "source": [ | |
| "El resultado es una matriz dispersa que registra el número de veces que aparece cada palabra; es más fácil de inspeccionar si la convertimos en un ``DataFrame`` con columnas etiquetadas:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "KcLz6TtMgTdU", | |
| "outputId": "fe4934e9-5043-49a4-ea01-b0d8ac94afb1" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import pandas as pd\n", | |
| "pd.DataFrame(X.toarray(), columns=vec.get_feature_names())" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "oGojGQdxgTdX" | |
| }, | |
| "source": [ | |
| "Sin embargo, hay algunos problemas con este enfoque: el recuento de palabras en bruto conduce a características que ponen demasiado peso en las palabras que aparecen con mucha frecuencia, y esto puede ser subóptimo en algunos algoritmos de clasificación.\n", | |
| "Un método para solucionar este problema se conoce como *frecuencia de documento de término de frecuencia inversa* (*TF-IDF*), que pondera los recuentos de palabras en función de la frecuencia con la que aparecen en los documentos.\n", | |
| "La sintaxis para calcular estas características es similar a la del ejemplo anterior:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "xeNOrwYbgTdX", | |
| "outputId": "43f4541c-b964-4ebd-dac8-2f08b48ac1a9" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.feature_extraction.text import TfidfVectorizer\n", | |
| "\n", | |
| "vec = TfidfVectorizer()\n", | |
| "X = vec.fit_transform(sample)\n", | |
| "pd.DataFrame(X.toarray(), columns=vec.get_feature_names())" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "AQxt5gtKgTdx" | |
| }, | |
| "source": [ | |
| "## Imputación de datos perdidos\n", | |
| "\n", | |
| "Otra necesidad común en la ingeniería de características es el manejo de los datos faltantes." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "X0J2eQNTgTdy" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from numpy import nan\n", | |
| "X = np.array([[ nan, 0, 3 ],\n", | |
| " [ 3, 7, 9 ],\n", | |
| " [ 3, 5, 2 ],\n", | |
| " [ 4, nan, 6 ],\n", | |
| " [ 8, 8, 1 ]])\n", | |
| "y = np.array([14, 16, -1, 8, -5])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "4uM40_dUgTd1" | |
| }, | |
| "source": [ | |
| "Al aplicar un modelo típico de aprendizaje de máquina a dichos datos, primero tendremos que reemplazar los datos faltantes con algún valor de relleno apropiado.\n", | |
| "Esto se conoce como *imputación* de valores perdidos, y las estrategias van desde simples (por ejemplo, reemplazar los valores perdidos con la media de la columna) hasta sofisticadas (por ejemplo, usar la terminación de la matriz o un modelo robusto para manejar tales datos).\n", | |
| "\n", | |
| "Los enfoques sofisticados tienden a ser muy específicos para cada aplicación, y no vamos a profundizar en ellos aquí.\n", | |
| "Para un enfoque de imputación de línea de base, utilizando el valor medio, mediano o más frecuente, Scikit-Learn proporciona la clase \"SimpleImputer\":" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "8hKcdCIugTd1", | |
| "outputId": "5f28081c-7443-40fd-8896-7917b11e945a" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.impute import SimpleImputer\n", | |
| "imp = SimpleImputer(strategy='mean')\n", | |
| "X2 = imp.fit_transform(X)\n", | |
| "X2" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Yi5Ye2k-gTd4" | |
| }, | |
| "source": [ | |
| "Vemos que en los datos resultantes, los dos valores faltantes han sido reemplazados por la media de los valores restantes en la columna. Estos datos imputados pueden entonces ser introducidos directamente en, por ejemplo, un estimador ``LinearRegression``:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "UIG9xi3AgTd5", | |
| "outputId": "3963d7bb-be42-4f1b-a3cc-4822deb84940" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model = LinearRegression().fit(X2, y)\n", | |
| "model.predict(X2)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "BbIGhH_MgTd8" | |
| }, | |
| "source": [ | |
| "## Pipelines de características\n", | |
| "\n", | |
| "Con cualquiera de los ejemplos anteriores, puede resultar tedioso hacer las transformaciones a mano, especialmente si se desea encadenar múltiples pasos.\n", | |
| "Por ejemplo, es posible que queramos un pipeline de procesamiento que se parezca a éste:\n", | |
| "\n", | |
| "1. Imputar valores perdidos utilizando la media\n", | |
| "2. Transformar características a cuadráticas\n", | |
| "3. Ajustar una regresión lineal\n", | |
| "\n", | |
| "Para agilizar este tipo de tuberías de procesamiento, Scikit-Learn proporciona un objeto ```Pipeline`` que puede ser utilizado de la siguiente manera:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "k5NZYJOdgTd9" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.pipeline import make_pipeline\n", | |
| "\n", | |
| "model = make_pipeline(SimpleImputer(strategy='mean'),\n", | |
| " PolynomialFeatures(degree=2),\n", | |
| " LinearRegression())" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "ojxBfPoAgTd_" | |
| }, | |
| "source": [ | |
| "Esta tubería actúa como un objeto estándar de Scikit-Learn, y aplicará todos los pasos especificados a cualquier dato de entrada." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "VIMRysQvgTeA", | |
| "outputId": "01371e53-26ba-409d-ac6d-d0b89de6dd3f" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model.fit(X, y) # X with missing values, from above\n", | |
| "print(y)\n", | |
| "print(model.predict(X))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "FTMJ8YxGgea2" | |
| }, | |
| "source": [ | |
| "# Supervisado: Máquinas de Soporte Vectorial" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "WdV8-Aohgea2" | |
| }, | |
| "source": [ | |
| "Las máquinas de soporte vectorial (SVM) son una clase particularmente potente y flexible de algoritmos supervisados tanto para la clasificación como para la regresión." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "u95P3Xp3gea6" | |
| }, | |
| "source": [ | |
| "Se trata de *clasificación discriminatoria*: en lugar de modelar cada clase, simplemente encontraremos una línea o curva (en dos dimensiones) o múltiple (en múltiples dimensiones) que divida las clases entre sí.\n", | |
| "\n", | |
| "Como ejemplo de esto, considere el caso simple de una tarea de clasificación, en la que las dos clases de puntos están bien separadas:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "_SFocSg_gea8", | |
| "outputId": "d5862dbd-1362-4e70-bc6f-98b090dc7049" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets.samples_generator import make_blobs\n", | |
| "\n", | |
| "X, y = make_blobs(n_samples=50, centers=2,\n", | |
| " random_state=0, cluster_std=0.60)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "WXWulenNgebA" | |
| }, | |
| "source": [ | |
| "Un clasificador discriminatorio lineal trataría de trazar una línea recta que separara los dos conjuntos de datos, creando así un modelo de clasificación.\n", | |
| "Para datos bidimensionales como los que se muestran aquí, esta es una tarea que podemos hacer a mano.\n", | |
| "Pero inmediatamente vemos un problema: ¡hay más de una posible línea divisoria que puede discriminar perfectamente entre las dos clases!\n", | |
| "\n", | |
| "Podemos dibujarlos de la siguiente manera:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "u2WN_-_1gebB", | |
| "outputId": "78de0b0c-0cf8-4e45-d5c0-6029e973ff9d" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "xfit = np.linspace(-1, 3.5)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')\n", | |
| "plt.plot([0.6], [2.1], 'x', color='red', markeredgewidth=2, markersize=10)\n", | |
| "\n", | |
| "for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:\n", | |
| " plt.plot(xfit, m * xfit + b, '-k')\n", | |
| "\n", | |
| "plt.xlim(-1, 3.5);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "m5u27a7ygebE" | |
| }, | |
| "source": [ | |
| "Se trata de tres *muy* diferentes separadores que, sin embargo, discriminan perfectamente entre estas muestras.\n", | |
| "Dependiendo de lo que elija, se le asignará una etiqueta diferente a un nuevo punto de datos (por ejemplo, el marcado con una \"X\" en este gráfico).\n", | |
| "Evidentemente, nuestra simple intuición de \"trazar una línea entre clases\" no es suficiente, y necesitamos pensar un poco más profundamente." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "58n6yJFqgebF" | |
| }, | |
| "source": [ | |
| "## Maximizar el *Margen*\n", | |
| "\n", | |
| "Las máquinas vectoriales de soporte ofrecen una forma de mejorar esto.\n", | |
| "La intuición es la siguiente: en lugar de simplemente trazar una línea de ancho cero entre las clases, podemos trazar alrededor de cada línea un *margen* de algún ancho, hasta el punto más cercano.\n", | |
| "He aquí un ejemplo de cómo podría verse esto:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "VPm25Ls5gebF", | |
| "outputId": "bb3684b0-9648-435d-8e77-662193927d48" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "xfit = np.linspace(-1, 3.5)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')\n", | |
| "\n", | |
| "for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:\n", | |
| " yfit = m * xfit + b\n", | |
| " plt.plot(xfit, yfit, '-k')\n", | |
| " plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',\n", | |
| " color='#AAAAAA', alpha=0.4)\n", | |
| "\n", | |
| "plt.xlim(-1, 3.5);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "6n_DbOj_gebK" | |
| }, | |
| "source": [ | |
| "En las máquinas de soporte vectorial, la línea que maximiza este margen es la que elegiremos como modelo óptimo.\n", | |
| "Las máquinas de vectores de soporte son un ejemplo de este tipo de estimador de *margen máximo*." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Fai4ORXCgebL" | |
| }, | |
| "source": [ | |
| "### Montar una máquina de soporte vectorial\n", | |
| "\n", | |
| "Veamos el resultado de un ajuste real a estos datos: usaremos el clasificador vectorial de soporte de Scikit-Learn para entrenar un modelo SVM sobre estos datos.\n", | |
| "Por el momento, usaremos un kernel lineal y pondremos el parámetro ``C`` a un número muy grande (discutiremos el significado de estos en más profundidad momentáneamente)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "vpbUnjPhgebL", | |
| "outputId": "47946439-d2d3-413e-e067-80520ccfab08" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.svm import SVC # \"Support vector classifier\"\n", | |
| "model = SVC(kernel='linear', C=1e10)\n", | |
| "model.fit(X, y)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "wt0BXPiigebU" | |
| }, | |
| "source": [ | |
| "Para visualizar mejor lo que está sucediendo aquí, vamos a crear una función de conveniencia rápida que trazará los límites de las decisiones del SVM para nosotros:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "He4grdUygebV" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def plot_svc_decision_function(model, ax=None, plot_support=True):\n", | |
| " \"\"\"Plot the decision function for a 2D SVC\"\"\"\n", | |
| " if ax is None:\n", | |
| " ax = plt.gca()\n", | |
| " xlim = ax.get_xlim()\n", | |
| " ylim = ax.get_ylim()\n", | |
| " \n", | |
| " # create grid to evaluate model\n", | |
| " x = np.linspace(xlim[0], xlim[1], 30)\n", | |
| " y = np.linspace(ylim[0], ylim[1], 30)\n", | |
| " Y, X = np.meshgrid(y, x)\n", | |
| " xy = np.vstack([X.ravel(), Y.ravel()]).T\n", | |
| " P = model.decision_function(xy).reshape(X.shape)\n", | |
| " \n", | |
| " # plot decision boundary and margins\n", | |
| " ax.contour(X, Y, P, colors='k',\n", | |
| " levels=[-1, 0, 1], alpha=0.5,\n", | |
| " linestyles=['--', '-', '--'])\n", | |
| " \n", | |
| " # plot support vectors\n", | |
| " if plot_support:\n", | |
| " ax.scatter(model.support_vectors_[:, 0],\n", | |
| " model.support_vectors_[:, 1],\n", | |
| " s=35, linewidth=1);\n", | |
| " ax.set_xlim(xlim)\n", | |
| " ax.set_ylim(ylim)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "zFVCk3VogebY", | |
| "outputId": "b77aa0ba-b903-42f7-d656-1edc4e13dcf1" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')\n", | |
| "plot_svc_decision_function(model);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "uwBol7Pdgebb" | |
| }, | |
| "source": [ | |
| "Esta es la línea divisoria que maximiza el margen entre los dos grupos de puntos.\n", | |
| "Observe que algunos de los puntos de entrenamiento sólo tocan el margen: están indicados por los círculos negros de esta figura.\n", | |
| "Estos puntos son los elementos pivotantes de este ajuste, y se conocen como los *vectores de apoyo*, y dan al algoritmo su nombre.\n", | |
| "En Scikit-Learn, la identidad de estos puntos se almacena en el atributo ``support_vectors_`` del clasificador:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "S3o27U46gebb", | |
| "outputId": "95eda190-b36d-43d2-839b-215fe60c36cf" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "model.support_vectors_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "FX-CGeBOgebd" | |
| }, | |
| "source": [ | |
| "Una de las claves del éxito de este clasificador es que, para el ajuste, sólo importa la posición de los vectores de apoyo; los puntos más alejados del margen que están en el lado correcto no modifican el ajuste.\n", | |
| "Técnicamente, esto se debe a que estos puntos no contribuyen a la función de pérdida utilizada para ajustar el modelo, por lo que su posición y número no importan mientras no crucen el margen.\n", | |
| "\n", | |
| "Podemos ver esto, por ejemplo, si trazamos el modelo aprendido de los primeros 60 puntos y los primeros 120 puntos de este conjunto de datos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "wHWWGPiigebe", | |
| "outputId": "aaebe91f-4116-4649-99e9-abaa427e1882" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def plot_svm(N=10, ax=None):\n", | |
| " X, y = make_blobs(n_samples=200, centers=2,\n", | |
| " random_state=0, cluster_std=0.60)\n", | |
| " X = X[:N]\n", | |
| " y = y[:N]\n", | |
| " model = SVC(kernel='linear', C=1E10)\n", | |
| " model.fit(X, y)\n", | |
| " \n", | |
| " ax = ax or plt.gca()\n", | |
| " ax.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')\n", | |
| " ax.set_xlim(-1, 4)\n", | |
| " ax.set_ylim(-1, 6)\n", | |
| " plot_svc_decision_function(model, ax)\n", | |
| "\n", | |
| "fig, ax = plt.subplots(1, 2, figsize=(16, 6))\n", | |
| "fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)\n", | |
| "for axi, N in zip(ax, [60, 120]):\n", | |
| " plot_svm(N, axi)\n", | |
| " axi.set_title('N = {0}'.format(N))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "G-cF6Utvgebg" | |
| }, | |
| "source": [ | |
| "En el panel izquierdo, vemos el modelo y los vectores de apoyo para 60 puntos de entrenamiento.\n", | |
| "En el panel derecho, hemos duplicado el número de puntos de entrenamiento, pero el modelo no ha cambiado: los tres vectores de apoyo del panel izquierdo siguen siendo los vectores de apoyo del panel derecho.\n", | |
| "Esta insensibilidad al comportamiento exacto de los puntos distantes es uno de los puntos fuertes del modelo SVM." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "bKrKT78Jgebl" | |
| }, | |
| "source": [ | |
| "### Más allá de los límites lineales: Núcleo SVM\n", | |
| "\n", | |
| "Donde SVM se vuelve extremadamente poderoso es cuando se combina con *kernels*." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "kcqzNRX3gebm", | |
| "outputId": "b0f201c8-bd6e-4e74-db63-dbc840bab339" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets.samples_generator import make_circles\n", | |
| "X, y = make_circles(100, factor=.1, noise=.1)\n", | |
| "\n", | |
| "clf = SVC(kernel='linear').fit(X, y)\n", | |
| "\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')\n", | |
| "plot_svc_decision_function(clf, plot_support=False);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "7AoRvKvMgeb2", | |
| "outputId": "e56c4013-7b51-4179-c7f6-8424b45309f4" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "clf = SVC(kernel='rbf', C=1E6, gamma=\"auto\")\n", | |
| "clf.fit(X, y)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "SYGvOicqgeb5", | |
| "outputId": "b9e42e4e-1f81-4358-d8aa-f6476a822f39" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')\n", | |
| "plot_svc_decision_function(clf)\n", | |
| "plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],\n", | |
| " s=300, lw=1, facecolors='none');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "7gGnNfCVgeb7" | |
| }, | |
| "source": [ | |
| "Usando esta máquina vectorial de soporte kernelizada, aprendemos un límite de decisión no lineal adecuado.\n", | |
| "Esta estrategia de transformación del núcleo se utiliza a menudo en el aprendizaje automático para convertir métodos lineales rápidos en métodos no lineales rápidos, especialmente para modelos en los que se puede utilizar el truco del núcleo." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "XBG8TBBdgeb7" | |
| }, | |
| "source": [ | |
| "### Afinando el SVM: Márgenes de ablandamiento\n", | |
| "\n", | |
| "Nuestra discusión hasta ahora se ha centrado en conjuntos de datos muy limpios, en los que existe un límite de decisión perfecto.\n", | |
| "¿Pero qué pasa si los datos se solapan un poco?\n", | |
| "Por ejemplo, es posible que tenga datos como estos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "I9VLsEemgeb8", | |
| "outputId": "2fea0611-0689-4912-a02c-76e020899c6d" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X, y = make_blobs(n_samples=100, centers=2,\n", | |
| " random_state=0, cluster_std=1.2)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "KmtLUJDOgecA" | |
| }, | |
| "source": [ | |
| "Para manejar este caso, la implementación de SVM tiene un poco de un factor fudge que \"suaviza\" el margen: es decir, permite que algunos de los puntos se introduzcan en el margen si eso permite un mejor ajuste.\n", | |
| "La dureza del margen es controlada por un parámetro conocido como $C$.\n", | |
| "Para $C$ muy grandes, el margen es duro, y los puntos no pueden estar en él.\n", | |
| "Para $C$ más pequeños, el margen es más suave, y puede crecer hasta abarcar algunos puntos.\n", | |
| "\n", | |
| "El gráfico que se muestra a continuación ofrece una imagen visual de cómo un parámetro $C$ cambiante afecta al ajuste final, a través del suavizado del margen:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "p42RvaD9gecC", | |
| "outputId": "7b0f18a3-96c3-4c55-ec0b-34b82c09e9cf" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X, y = make_blobs(n_samples=100, centers=2,\n", | |
| " random_state=0, cluster_std=0.8)\n", | |
| "\n", | |
| "fig, ax = plt.subplots(1, 2, figsize=(16, 6))\n", | |
| "fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)\n", | |
| "\n", | |
| "for axi, C in zip(ax, [10.0, 0.1]):\n", | |
| " model = SVC(kernel='linear', C=C).fit(X, y)\n", | |
| " axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')\n", | |
| " plot_svc_decision_function(model, axi)\n", | |
| " axi.scatter(model.support_vectors_[:, 0],\n", | |
| " model.support_vectors_[:, 1],\n", | |
| " s=300, lw=1, facecolors='none');\n", | |
| " axi.set_title('C = {0:.1f}'.format(C), size=14)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "CY0If98-gecE" | |
| }, | |
| "source": [ | |
| "El valor óptimo del parámetro $C$ dependerá de su conjunto de datos, y debe ser ajustado usando validación cruzada o un procedimiento similar." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "<div style=\"font-size: 1em; margin: 1em 0 1em 0; border: 1px solid #86989B; background-color: #f7f7f7; padding: 0;\">\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; font-weight: bold; background-color: #AFC1C4;\">\n", | |
| "Ejercicio\n", | |
| "</p>\n", | |
| "<p style=\"margin: 0.5em 1em 0.5em 1em; padding: 0;\">\n", | |
| "\n", | |
| "Usando `fetch_lfw_people`:\n", | |
| "```\n", | |
| "from sklearn.datasets import fetch_lfw_people\n", | |
| "faces = fetch_lfw_people(min_faces_per_person=60)\n", | |
| "print(faces.target_names)\n", | |
| "print(faces.images.shape)\n", | |
| "```\n", | |
| "\n", | |
| "Se obtiene un dataset con imágenes de caras (60 por cara) donde cada imagen contiene [62×47] o casi 3.000 píxeles. Se pide crear un `pipeline` de clasificación de personas:\n", | |
| "\n", | |
| "1. En lugar de usar los casi 3000 pixels como features, utilice PCA como técnica de reducción de dimensionalidad hasta obtener 150 características. (*Pista*: Use `svd_solver='randomized'` y <acronym title=\"En ciertos casos, blanquear las entradas, esto es, asegurar que las salidas estén no correlacionadas y con varianzas unitarias, puede mejorar la predicción.\">`whiten=True`</acronym> para mejor rendimiento)\n", | |
| "2. Como segundo paso en el `pipeline`, añadiremos un clasificador de soporte vectorial con kernel no lineal `rbf`.\n", | |
| "3. Se efectuará una búsqueda por cuadrícula con 3 validaciones cruzadas sobre el espacio de hyper parámetros definido para `C` como `[1, 5, 10]`, para `gamma` como `[0.0001, 0.0005, 0.001]`, y para `class_weight` como `[None, \"balanced\"]`.\n", | |
| "4. Imprima por pantalla las características del mejor modelo y reporte su exactitud.\n", | |
| "\n", | |
| "(*Pista*: No olvide separar al menos un 30% del dataset para validación (Xtrain, Xtest, ytrain, ytest))\n", | |
| "</p>\n", | |
| "</div>\n", | |
| "\n", | |
| "<details>\n", | |
| " <summary style=\"float: right; position: relative;\"><em>Solution</em></summary>\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; background-color: #EEEFF0;\">\n", | |
| "<code>\n", | |
| "pca = PCA(n_components=150, svd_solver='randomized', whiten=True, random_state=42)\n", | |
| "svc = SVC(kernel='rbf', class_weight='balanced')\n", | |
| "model = make_pipeline(pca, svc)\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,\n", | |
| " random_state=42)\n", | |
| "param_grid = {'svc__C': [1, 5, 10],\n", | |
| " 'svc__gamma': [0.0001, 0.0005, 0.001]}\n", | |
| "grid = GridSearchCV(model, param_grid, cv=3)\n", | |
| "\n", | |
| "%time grid.fit(Xtrain, ytrain)\n", | |
| "print(grid.best_params_)\n", | |
| "best = grid.best_estimator_\n", | |
| "yfit = best.predict(Xtest)\n", | |
| "accuracy_score(ytest, yfit)\n", | |
| "</code>\n", | |
| "</p>\n", | |
| "\n", | |
| "</details>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "sCAp3D56gecK", | |
| "outputId": "2379cb4b-de99-4e15-f4a0-efc0cc1fb7d2" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets import fetch_lfw_people\n", | |
| "faces = fetch_lfw_people(min_faces_per_person=60)\n", | |
| "print(faces.target_names)\n", | |
| "print(faces.images.shape)\n", | |
| "fig, ax = plt.subplots(3, 5, figsize=(8, 6))\n", | |
| "for i, axi in enumerate(ax.flat):\n", | |
| " axi.imshow(faces.images[i], cmap='bone')\n", | |
| " axi.set(xticks=[], yticks=[],\n", | |
| " xlabel=faces.target_names[faces.target[i]])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "8xGDxH5EgecM" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Escriba aquí su solución\n", | |
| "pca = PCA(n_components=150, svd_solver='randomized', whiten=True, random_state=42)\n", | |
| "svc = SVC(kernel='rbf', class_weight='balanced')\n", | |
| "model = make_pipeline(pca, svc)\n", | |
| "\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,\n", | |
| " random_state=42)\n", | |
| "\n", | |
| "param_grid = {'svc__C': [1, 5, 10],\n", | |
| " 'svc__gamma': [0.0001, 0.0005, 0.001]}\n", | |
| "grid = GridSearchCV(model, param_grid, cv=3)\n", | |
| "\n", | |
| "%time grid.fit(Xtrain, ytrain)\n", | |
| "print(grid.best_params_)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "jtSHkul3gecU" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "best = grid.best_estimator_\n", | |
| "yfit = best.predict(Xtest)\n", | |
| "accuracy_score(ytest, yfit)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "LT-m6YyUgecZ", | |
| "outputId": "2c68f09c-bb46-49b6-f335-23ab266391e7" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "fig, ax = plt.subplots(4, 6, figsize=(8, 6))\n", | |
| "for i, axi in enumerate(ax.flat):\n", | |
| " axi.imshow(Xtest[i].reshape(62, 47), cmap='bone')\n", | |
| " axi.set(xticks=[], yticks=[])\n", | |
| " axi.set_ylabel(faces.target_names[yfit[i]].split()[-1],\n", | |
| " color='black' if yfit[i] == ytest[i] else 'red')\n", | |
| "fig.suptitle('Predicted Names; Incorrect Labels in Red', size=14);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "8CTx91Tdgecc" | |
| }, | |
| "source": [ | |
| "Podemos obtener una mejor idea del rendimiento de nuestro estimador utilizando el informe de clasificación, que enumera las estadísticas de recuperación etiqueta por etiqueta:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "P0lzc2h-gecc", | |
| "outputId": "2e916594-2014-40ee-c4b7-97b1ce187add" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.metrics import classification_report\n", | |
| "print(classification_report(ytest, yfit,\n", | |
| " target_names=faces.target_names))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "EXEFv9Pugecf" | |
| }, | |
| "source": [ | |
| "También podríamos mostrar la matriz de confusión entre estas clases:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "laCOycy0gecf", | |
| "outputId": "8d3040e8-3b93-475f-95e0-0cd62894db4b" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.metrics import confusion_matrix\n", | |
| "mat = confusion_matrix(ytest, yfit)\n", | |
| "sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,\n", | |
| " xticklabels=faces.target_names,\n", | |
| " yticklabels=faces.target_names)\n", | |
| "plt.xlabel('true label')\n", | |
| "plt.ylabel('predicted label');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "zhDisebqghF1" | |
| }, | |
| "source": [ | |
| "# Supervisado: Árboles de decisión y bosques aleatorios" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "kmLG08CRghF2" | |
| }, | |
| "source": [ | |
| "Los bosques aleatorios son un ejemplo de un método *ensemble* construido sobre árboles de decisión, lo que significa que se basa en la agregación de los resultados de un conjunto de estimadores más simples.\n", | |
| "\n", | |
| "El resultado con tales métodos de conjunto es algo sorprendente, que la suma puede ser mayor que las partes: es decir, un voto mayoritario entre un número de estimadores puede terminar siendo mejor que cualquiera de los estimadores individuales que hacen la votación." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "NEdF5UV1ghF6" | |
| }, | |
| "source": [ | |
| "Los árboles de decisión son formas extremadamente intuitivas de clasificar o etiquetar objetos: sólo tiene que hacer una serie de preguntas diseñadas para que la clasificación sea cero. Por ejemplo, si desea construir un árbol de decisión para clasificar un animal con el que se encuentre durante una caminata, puede construir el que se muestra aquí:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "aHZYvnZkghF7" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "GnfunHAYghF8" | |
| }, | |
| "source": [ | |
| "La división binaria lo hace extremadamente eficiente: en un árbol bien construido, cada pregunta reducirá el número de opciones aproximadamente a la mitad, reduciendo rápidamente las opciones incluso entre un gran número de clases.\n", | |
| "El truco, por supuesto, consiste en decidir qué preguntas hacer en cada paso.\n", | |
| "En las implementaciones de árboles de decisión de aprendizaje automático, las preguntas generalmente toman la forma de divisiones alineadas con el eje en los datos: es decir, cada nodo del árbol divide los datos en dos grupos utilizando un valor de corte dentro de una de las características.\n", | |
| "Veamos ahora un ejemplo de esto." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "lEjrLz4VghF8" | |
| }, | |
| "source": [ | |
| "### Creando un árbol de decisión\n", | |
| "\n", | |
| "Considere los siguientes datos bidimensionales, que tienen una de las cuatro etiquetas de clase:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "TAnR266zghF9", | |
| "outputId": "cc5ac740-95dd-400e-b03e-cdb5f4c546f4" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets import make_blobs\n", | |
| "\n", | |
| "X, y = make_blobs(n_samples=300, centers=4,\n", | |
| " random_state=0, cluster_std=1.0)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='rainbow');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "TDFBrrK6ghGB" | |
| }, | |
| "source": [ | |
| "Un simple árbol de decisión construido sobre estos datos dividirá los datos de forma iterativa a lo largo de uno u otro eje de acuerdo con algún criterio cuantitativo, y en cada nivel asignará la etiqueta de la nueva región de acuerdo con un voto mayoritario de puntos dentro de ella.\n", | |
| "Esta figura presenta una visualización de los primeros cuatro niveles de un clasificador de árbol de decisión para estos datos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "I_Wmj6wbghGC" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Je7__ai5ghGD" | |
| }, | |
| "source": [ | |
| "Note que después de la primera división, cada punto en la rama superior permanece sin cambios, así que no hay necesidad de subdividir más esta rama.\n", | |
| "A excepción de los nodos que contienen todo un color, en cada nivel *cada* región se divide de nuevo a lo largo de una de las dos características." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "2mP99CVdghGD" | |
| }, | |
| "source": [ | |
| "Este proceso de ajuste de un árbol de decisión a nuestros datos puede realizarse en Scikit-Learn con el estimador ``DecisionTreeClassifier``:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "ilfcNujFghGE" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.tree import DecisionTreeClassifier\n", | |
| "tree = DecisionTreeClassifier().fit(X, y)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "43GeGtSRghGG" | |
| }, | |
| "source": [ | |
| "Escribamos una función de utilidad rápida que nos ayude a visualizar la salida del clasificador:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "oJSFUVwHghGH" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def visualize_classifier(model, X, y, ax=None, cmap='rainbow'):\n", | |
| " ax = ax or plt.gca()\n", | |
| " \n", | |
| " # Plot the training points\n", | |
| " ax.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=cmap,\n", | |
| " zorder=3)\n", | |
| " ax.axis('tight')\n", | |
| " ax.axis('off')\n", | |
| " xlim = ax.get_xlim()\n", | |
| " ylim = ax.get_ylim()\n", | |
| " \n", | |
| " # fit the estimator\n", | |
| " model.fit(X, y)\n", | |
| " xx, yy = np.meshgrid(np.linspace(*xlim, num=200),\n", | |
| " np.linspace(*ylim, num=200))\n", | |
| " Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)\n", | |
| "\n", | |
| " # Create a color plot with the results\n", | |
| " n_classes = len(np.unique(y))\n", | |
| " contours = ax.contourf(xx, yy, Z, alpha=0.3,\n", | |
| " levels=np.arange(n_classes + 1) - 0.5,\n", | |
| " cmap=cmap,\n", | |
| " zorder=1)\n", | |
| "\n", | |
| " ax.set(xlim=xlim, ylim=ylim)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "LefgeSF2ghGJ" | |
| }, | |
| "source": [ | |
| "Ahora podemos examinar cómo es la clasificación del árbol de decisión:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "vk0rdbF8ghGK", | |
| "outputId": "75ae780d-d5e0-4a96-f99c-9f73dec13a2d" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "visualize_classifier(DecisionTreeClassifier(), X, y)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "KS3WUY_gghGR" | |
| }, | |
| "source": [ | |
| "### Árboles de decisión y sobreadaptación\n", | |
| "\n", | |
| "Este ajuste excesivo resulta ser una propiedad general de los árboles de decisión: es muy fácil profundizar demasiado en el árbol y, por lo tanto, ajustar los detalles de los datos particulares en lugar de las propiedades generales de las distribuciones de las que se extraen.\n", | |
| "Otra manera de ver este sobreajuste es mirar modelos entrenados en diferentes subconjuntos de los datos - por ejemplo, en esta figura entrenamos dos árboles diferentes, cada uno en la mitad de los datos originales:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "yHUDTx_mghGS" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "3TwSW5s7ghGT" | |
| }, | |
| "source": [ | |
| "Es claro que en algunos lugares, los dos árboles producen resultados consistentes (por ejemplo, en las cuatro esquinas), mientras que en otros lugares, los dos árboles dan clasificaciones muy diferentes (por ejemplo, en las regiones entre dos grupos cualesquiera).\n", | |
| "La observación clave es que las inconsistencias tienden a ocurrir cuando la clasificación es menos segura, y por lo tanto, utilizando información de *ambos* de estos árboles, ¡podríamos llegar a un mejor resultado!" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "cNfvOc8yghGY" | |
| }, | |
| "source": [ | |
| "## Ensembles de estimadores: Bosques aleatorios (*RandonForest*)\n", | |
| "\n", | |
| "Esta noción -que múltiples estimadores de sobreadaptaciones pueden combinarse para reducir el efecto de esta sobreadaptación- es lo que subyace a un método de ensamble llamado *bagging*.\n", | |
| "El embolsado utiliza un conjunto de estimadores paralelos, cada uno de los cuales se ajusta en exceso a los datos, y promedia los resultados para encontrar una mejor clasificación.\n", | |
| "Un conjunto de árboles de decisión aleatorios se conoce como *bosque aleatorio*.\n", | |
| "\n", | |
| "Este tipo de clasificación de ensacado se puede hacer manualmente usando el meta-estimador ``BaggingClassifier`` de Scikit-Learn, como se muestra aquí:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "YqKdJ0R4ghGY", | |
| "outputId": "611f6861-a5c4-4465-fd91-ee6f13d8863b" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.tree import DecisionTreeClassifier\n", | |
| "from sklearn.ensemble import BaggingClassifier\n", | |
| "\n", | |
| "tree = DecisionTreeClassifier()\n", | |
| "bag = BaggingClassifier(tree, n_estimators=100, max_samples=0.8,\n", | |
| " random_state=1)\n", | |
| "\n", | |
| "bag.fit(X, y)\n", | |
| "visualize_classifier(bag, X, y)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "SezH8MpYghGb" | |
| }, | |
| "source": [ | |
| "En este ejemplo, hemos aleatorizado los datos ajustando cada estimador con un subconjunto aleatorio del 80% de los puntos de entrenamiento.\n", | |
| "En la práctica, los árboles de decisión se aleatorizan de forma más eficaz inyectando cierta estocástico en la forma en que se eligen las divisiones: de esta manera, todos los datos contribuyen al ajuste cada vez, pero los resultados del ajuste siguen teniendo la aleatoriedad deseada.\n", | |
| "\n", | |
| "En Scikit-Learn, este conjunto optimizado de árboles de decisión aleatorios se implementa en el estimador \"RandomForestClassifier\", que se encarga automáticamente de toda la aleatorización.\n", | |
| "Todo lo que tiene que hacer es seleccionar un número de estimadores, y muy rápidamente (en paralelo, si lo desea) se ajustará al conjunto de árboles:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "8u8phLEpghGc", | |
| "outputId": "8cedb698-6044-488b-f76d-d353bfb2d152" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.ensemble import RandomForestClassifier\n", | |
| "\n", | |
| "model = RandomForestClassifier(n_estimators=100, random_state=0)\n", | |
| "visualize_classifier(model, X, y);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "_gyf4DywghGf" | |
| }, | |
| "source": [ | |
| "Vemos que al promediar más de 100 modelos aleatoriamente perturbados, terminamos con un modelo general que está mucho más cerca de nuestra intuición acerca de cómo se debe dividir el espacio de parámetros." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "WVMQbRQMghGf" | |
| }, | |
| "source": [ | |
| "## Bosques aleatorios de regresión\n", | |
| "\n", | |
| "En la sección anterior se consideraron los bosques aleatorios dentro del contexto de la clasificación.\n", | |
| "También se puede hacer que los bosques aleatorios funcionen en el caso de regresión (es decir, variables continuas en lugar de categóricas). El estimador a usar para esto es el ``RandomForestRegressor``, y la sintaxis es muy similar a la que vimos anteriormente.\n", | |
| "\n", | |
| "Considere los siguientes datos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "c95kZ0CgghGg", | |
| "outputId": "fcef2115-49b8-4831-c0aa-d77fdcb3f177" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "rng = np.random.RandomState(42)\n", | |
| "x = 10 * rng.rand(200)\n", | |
| "\n", | |
| "def model(x, sigma=0.3):\n", | |
| " fast_oscillation = np.sin(5 * x)\n", | |
| " slow_oscillation = np.sin(0.5 * x)\n", | |
| " noise = sigma * rng.randn(len(x))\n", | |
| "\n", | |
| " return slow_oscillation + fast_oscillation + noise\n", | |
| "\n", | |
| "y = model(x)\n", | |
| "plt.errorbar(x, y, 0.3, fmt='o');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "lRLWZ6cRghGk" | |
| }, | |
| "source": [ | |
| "Usando el regresor forestal aleatorio, podemos encontrar la curva de mejor ajuste de la siguiente manera:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "m1azwun3ghGl", | |
| "outputId": "6054fd50-c740-430a-89c2-6621841894df" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.ensemble import RandomForestRegressor\n", | |
| "forest = RandomForestRegressor(200)\n", | |
| "forest.fit(x[:, None], y)\n", | |
| "\n", | |
| "xfit = np.linspace(0, 10, 1000)\n", | |
| "yfit = forest.predict(xfit[:, None])\n", | |
| "ytrue = model(xfit, sigma=0)\n", | |
| "\n", | |
| "# plt.errorbar(x, y, 0.3, fmt='o', alpha=0.5)\n", | |
| "plt.plot(xfit, yfit, '-r');\n", | |
| "plt.plot(xfit, ytrue, '-k', alpha=0.5);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "HQFsW1JNghGp" | |
| }, | |
| "source": [ | |
| "Aquí el modelo verdadero se muestra en la curva gris lisa, mientras que el modelo de bosque aleatorio se muestra en la curva roja dentada.\n", | |
| "Como puede ver, el modelo de bosque aleatorio no paramétrico es lo suficientemente flexible como para adaptarse a los datos de varios períodos, sin necesidad de especificar un modelo de varios períodos." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "<div style=\"font-size: 1em; margin: 1em 0 1em 0; border: 1px solid #86989B; background-color: #f7f7f7; padding: 0;\">\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; font-weight: bold; background-color: #AFC1C4;\">\n", | |
| "Ejercicio\n", | |
| "</p>\n", | |
| "<p style=\"margin: 0.5em 1em 0.5em 1em; padding: 0;\">\n", | |
| "\n", | |
| "Usando el dataset de `digits`, ajuste un clasificador de bosque aleatorio con 1000 estimadores y imprima por pantalla el informe de clasificación y el mapa de calor de la matrix de confusión. ¿Es este OCR mejor que el anterior?\n", | |
| "\n", | |
| "(*Pista*: En esta ocasión no necesitará `xticklabels` ni `yticklabels` en el mapa de calor)\n", | |
| "</p>\n", | |
| "</div>\n", | |
| "\n", | |
| "<details>\n", | |
| " <summary style=\"float: right; position: relative;\"><em>Solution</em></summary>\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; background-color: #EEEFF0;\">\n", | |
| "<code>\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(digits.data, digits.target,\n", | |
| " random_state=0)\n", | |
| "model = RandomForestClassifier(n_estimators=1000)\n", | |
| "model.fit(Xtrain, ytrain)\n", | |
| "ypred = model.predict(Xtest)\n", | |
| "print(classification_report(ypred, ytest))\n", | |
| "mat = confusion_matrix(ytest, ypred)\n", | |
| "sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False)\n", | |
| "plt.xlabel('true label')\n", | |
| "plt.ylabel('predicted label');\n", | |
| "</code>\n", | |
| "</p>\n", | |
| "\n", | |
| "</details>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "mpgf8r3RghGt", | |
| "outputId": "8f984680-d470-465a-8d9a-aa6a31f53667" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# set up the figure\n", | |
| "fig = plt.figure(figsize=(6, 6)) # figure size in inches\n", | |
| "fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)\n", | |
| "\n", | |
| "# plot the digits: each image is 8x8 pixels\n", | |
| "for i in range(64):\n", | |
| " ax = fig.add_subplot(8, 8, i + 1, xticks=[], yticks=[])\n", | |
| " ax.imshow(digits.images[i], cmap=plt.cm.binary, interpolation='nearest')\n", | |
| " \n", | |
| " # label the image with the target value\n", | |
| " ax.text(0, 7, str(digits.target[i]))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "6DWyab8BghGx" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "# Escriba su solución aquí\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(digits.data, digits.target,\n", | |
| " random_state=0)\n", | |
| "model = RandomForestClassifier(n_estimators=1000)\n", | |
| "model.fit(Xtrain, ytrain)\n", | |
| "ypred = model.predict(Xtest)\n", | |
| "print(classification_report(ypred, ytest))\n", | |
| "mat = confusion_matrix(ytest, ypred)\n", | |
| "sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False)\n", | |
| "plt.xlabel('true label')\n", | |
| "plt.ylabel('predicted label');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "yNqthOK2gjSN" | |
| }, | |
| "source": [ | |
| "# No supervisado: Análisis de componentes principales (PCA)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "SwM6J0h-gjSO" | |
| }, | |
| "source": [ | |
| "El PCA es fundamentalmente un algoritmo de reducción de la dimensionalidad, pero también puede ser útil como herramienta para la visualización, para el filtrado de ruido, para la extracción e ingeniería de características, y mucho más." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "c0osy0PRgjST" | |
| }, | |
| "source": [ | |
| "## Introducción al análisis de componentes principales\n", | |
| "\n", | |
| "El análisis de componentes principales es un método rápido y flexible no supervisado para la reducción de la dimensionalidad de los datos." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "1Bi7a0GCgjSU", | |
| "outputId": "4f1ed6c7-0868-4a3f-9d97-49d8e21c2929" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "rng = np.random.RandomState(1)\n", | |
| "X = np.dot(rng.rand(2, 2), rng.randn(2, 200)).T\n", | |
| "plt.scatter(X[:, 0], X[:, 1])\n", | |
| "plt.axis('equal');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "cjQkcDacgjSa" | |
| }, | |
| "source": [ | |
| "A simple vista, está claro que existe una relación casi lineal entre las variables x e y. En lugar de intentar *predecir* los valores de y a partir de los valores de x como en la regresión, el problema de aprendizaje no supervisado intenta aprender sobre la *relación* entre los valores de x e y.\n", | |
| "\n", | |
| "En el análisis de componentes principales, esta relación se cuantifica encontrando una lista de los *ejes principales* en los datos, y usando esos ejes para describir el conjunto de datos.\n", | |
| "Usando el estimador ``PCA`` de Scikit-Learn, podemos calcular esto de la siguiente manera:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "d-FYtDjKgjSb", | |
| "outputId": "69fa9754-c008-4165-87ec-ef89384c74c9" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.decomposition import PCA\n", | |
| "pca = PCA(n_components=2)\n", | |
| "pca.fit(X)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "Rc_RhREPgjSe" | |
| }, | |
| "source": [ | |
| "El ajuste aprende algunas cantidades de los datos, sobre todo los \"componentes\" y la \"varianza explicada\":" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "Gu3dXipDgjSf", | |
| "outputId": "0bf32a58-9d12-4247-b5b5-01b92a76cd04" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "print(pca.components_)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "Q4yT1W05gjSj", | |
| "outputId": "8e9358f9-4b00-46ca-ed5a-54948096bc22" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "print(pca.explained_variance_)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "PQ3Q-0kHgjSm" | |
| }, | |
| "source": [ | |
| "Para ver lo que significan estos números, visualicémoslos como vectores sobre los datos de entrada, usando los \"componentes\" para definir la dirección del vector, y la \"varianza explicada\" para definir la longitud cuadrada del vector:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "J-TliAzsgjSn", | |
| "outputId": "c156c078-f27a-44cb-af63-ac72df732bfa" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def draw_vector(v0, v1, ax=None):\n", | |
| " ax = ax or plt.gca()\n", | |
| " arrowprops=dict(arrowstyle='->',\n", | |
| " linewidth=2,\n", | |
| " shrinkA=0, shrinkB=0)\n", | |
| " ax.annotate('', v1, v0, arrowprops=arrowprops)\n", | |
| "\n", | |
| "# plot data\n", | |
| "plt.scatter(X[:, 0], X[:, 1], alpha=0.2)\n", | |
| "for length, vector in zip(pca.explained_variance_, pca.components_):\n", | |
| " v = vector * 3 * np.sqrt(length)\n", | |
| " draw_vector(pca.mean_, pca.mean_ + v)\n", | |
| "plt.axis('equal');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "bzUzoPQfgjSq" | |
| }, | |
| "source": [ | |
| "Estos vectores representan los *ejes principales* de los datos, y la longitud del vector es una indicación de cuán \"importante\" es ese eje para describir la distribución de los datos; más precisamente, es una medida de la varianza de los datos cuando se proyectan sobre ese eje.\n", | |
| "La proyección de cada punto de datos sobre los ejes principales son los \"componentes principales\" de los datos.\n", | |
| "\n", | |
| "Si representamos estos componentes principales junto con los datos originales, veremos los gráficos que se muestran aquí:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "OcR_GUm3gjSr" | |
| }, | |
| "source": [ | |
| "\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "5vyIDomxgjSs" | |
| }, | |
| "source": [ | |
| "Esta transformación de ejes de datos a ejes principales es una *transformación afín*, lo que básicamente significa que está compuesta por una traslación, rotación y escalado uniforme.\n", | |
| "\n", | |
| "Mientras que este algoritmo para encontrar los componentes principales puede parecer sólo una curiosidad matemática, resulta tener aplicaciones de gran alcance en el mundo del aprendizaje automático y la exploración de datos." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "CJnC07gVgjSt" | |
| }, | |
| "source": [ | |
| "### PCA como reducción de la dimensionalidad\n", | |
| "\n", | |
| "El uso de PCA para la reducción de la dimensionalidad implica la puesta a cero de uno o más de los componentes principales más pequeños, lo que resulta en una proyección de menor dimensión de los datos que preserva la máxima varianza de los datos.\n", | |
| "\n", | |
| "He aquí un ejemplo del uso del PCA como una transformación de reducción de la dimensionalidad:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "9G9MkYaogjSu", | |
| "outputId": "65ea1cba-d525-4333-84c8-23ee9779b917" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "pca = PCA(n_components=1)\n", | |
| "pca.fit(X)\n", | |
| "X_pca = pca.transform(X)\n", | |
| "print(\"original shape: \", X.shape)\n", | |
| "print(\"transformed shape:\", X_pca.shape)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "M9IGyu9RgjSx" | |
| }, | |
| "source": [ | |
| "Los datos transformados se han reducido a una sola dimensión.\n", | |
| "Para entender el efecto de esta reducción de la dimensionalidad, podemos realizar la transformación inversa de estos datos reducidos y graficarlos junto con los datos originales:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "p32hhhWFgjSy", | |
| "outputId": "3a54803a-49bb-4590-b269-631d2201fade" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X_new = pca.inverse_transform(X_pca)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], alpha=0.2)\n", | |
| "plt.scatter(X_new[:, 0], X_new[:, 1], alpha=0.8)\n", | |
| "plt.axis('equal');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "xXtIupa3gjS2" | |
| }, | |
| "source": [ | |
| "Los puntos de luz son los datos originales, mientras que los puntos oscuros son la versión proyectada.\n", | |
| "Esto deja claro lo que significa una reducción de la dimensionalidad de la PCA: se elimina la información a lo largo del eje o ejes principales menos importantes, dejando sólo el componente o componentes de los datos con la mayor varianza.\n", | |
| "La fracción de varianza que se recorta (proporcional a la extensión de los puntos sobre la línea formada en esta figura) es aproximadamente una medida de cuánta \"información\" se descarta en esta reducción de la dimensionalidad.\n", | |
| "\n", | |
| "Este conjunto de datos de dimensiones reducidas es en algunos sentidos \"suficientemente bueno\" para codificar las relaciones más importantes entre los puntos: a pesar de reducir la dimensión de los datos en un 50%, la relación global entre los puntos de datos se mantiene en su mayor parte." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "6Kjn4yjSgjS3" | |
| }, | |
| "source": [ | |
| "### PCA para visualización: Dígitos escritos a mano\n", | |
| "\n", | |
| "La utilidad de la reducción de la dimensionalidad puede no ser completamente aparente en sólo dos dimensiones, pero se vuelve mucho más clara cuando se observan datos de alta dimensión.\n", | |
| "Para ver esto, echemos un vistazo rápido a la aplicación de PCA a los datos de dígitos que vimos en[En Profundidad: Árboles de Decisión y Bosques al Azar] (05.08-Random-Forests.ipynb).\n", | |
| "\n", | |
| "Comenzamos cargando los datos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "iqI5aR8-gjS4", | |
| "outputId": "5ee09d54-b090-4c17-c432-38707caadb04" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets import load_digits\n", | |
| "digits = load_digits()\n", | |
| "digits.data.shape" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "MLYLhMkogjS8" | |
| }, | |
| "source": [ | |
| "Recuerde que los datos consisten en imágenes de 8×8 píxeles, lo que significa que son de 64 dimensiones.\n", | |
| "Para ganar algo de intuición en las relaciones entre estos puntos, podemos usar PCA para proyectarlas a un número más manejable de dimensiones, digamos dos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "sIZ2CHSdgjS8", | |
| "outputId": "2f376c4c-348f-4f67-a865-3495a778703e" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "pca = PCA(2) # project from 64 to 2 dimensions\n", | |
| "projected = pca.fit_transform(digits.data)\n", | |
| "print(digits.data.shape)\n", | |
| "print(projected.shape)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "ea3W-b6qgjTB" | |
| }, | |
| "source": [ | |
| "Ahora podemos trazar los dos primeros componentes principales de cada punto para aprender sobre los datos:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "iGEwuOWjgjTC", | |
| "outputId": "b77ce977-4874-4331-b9b1-0c76d1166547" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "plt.scatter(projected[:, 0], projected[:, 1],\n", | |
| " c=digits.target, edgecolor='none', alpha=0.5,\n", | |
| " cmap=plt.cm.get_cmap('nipy_spectral', 10))\n", | |
| "plt.xlabel('component 1')\n", | |
| "plt.ylabel('component 2')\n", | |
| "plt.colorbar();" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "U5kTu4aAgjTH" | |
| }, | |
| "source": [ | |
| "Recordemos lo que significan estos componentes: los datos completos son una nube de puntos de 64 dimensiones, y estos puntos son la proyección de cada punto de datos a lo largo de las direcciones con la mayor varianza.\n", | |
| "Esencialmente, hemos encontrado el estiramiento y la rotación óptimos en un espacio de 64 dimensiones que nos permite ver la disposición de los dígitos en dos dimensiones, y lo hemos hecho de manera no supervisada, es decir, sin referencia a las etiquetas." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "2Cg-W0y6gjTQ" | |
| }, | |
| "source": [ | |
| "### Elegir el número de componentes\n", | |
| "\n", | |
| "Una parte vital del uso de la PCA en la práctica es la capacidad de estimar cuántos componentes son necesarios para describir los datos.\n", | |
| "Esto se puede determinar observando el ratio de varianza acumulativo *explicado* como una función del número de componentes:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "bgPDXjb-gjTR", | |
| "outputId": "796c1be1-ddba-4ffc-e77b-7f70f07b3179" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "pca = PCA().fit(digits.data)\n", | |
| "plt.plot(np.cumsum(pca.explained_variance_ratio_))\n", | |
| "plt.xlabel('number of components')\n", | |
| "plt.ylabel('cumulative explained variance');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "e8DPAUmVgjTX" | |
| }, | |
| "source": [ | |
| "Esta curva cuantifica qué parte de la varianza total de 64 dimensiones se encuentra dentro de los primeros componentes de $N$.\n", | |
| "Por ejemplo, vemos que con los dígitos los primeros 10 componentes contienen aproximadamente el 75% de la desviación, mientras que se necesitan alrededor de 50 componentes para describir cerca del 100% de la varianza.\n", | |
| "\n", | |
| "Aquí vemos que nuestra proyección bidimensional pierde mucha información (medida por la varianza explicada) y que necesitaríamos unos 20 componentes para retener el 90% de la varianza. Mirar este gráfico para obtener un conjunto de datos de alta dimensión puede ayudarle a comprender el nivel de redundancia presente en múltiples observaciones." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "<div style=\"font-size: 1em; margin: 1em 0 1em 0; border: 1px solid #86989B; background-color: #f7f7f7; padding: 0;\">\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; font-weight: bold; background-color: #AFC1C4;\">\n", | |
| "Ejercicio\n", | |
| "</p>\n", | |
| "<p style=\"margin: 0.5em 1em 0.5em 1em; padding: 0;\">\n", | |
| "\n", | |
| "A patir del fichero `min_venta.csv`:\n", | |
| "```\n", | |
| "pd.read_csv(\"min_venta.csv\", index_col=\"fecha\", parse_dates=True)\n", | |
| "```\n", | |
| "Usar la columna `codigo_cliente` como etiquetas y estimar cuántas componentes necesitaría PCA para explicar el menos un 99% de la varizan del dataset.\n", | |
| "\n", | |
| "(*Pista*: Aplicar `np.cumsum` sobre el ratio de varianza explicada puede ser una buena idea)\n", | |
| "</p>\n", | |
| "</div>\n", | |
| "\n", | |
| "<details>\n", | |
| " <summary style=\"float: right; position: relative;\"><em>Solution</em></summary>\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; background-color: #EEEFF0;\">\n", | |
| "<code>\n", | |
| "venta = pd.read_csv(\"min_venta.csv\", index_col=\"fecha\", parse_dates=True)\n", | |
| "y = venta.codigo_cliente\n", | |
| "X = venta.drop(\"codigo_cliente\", axis=\"columns\")\n", | |
| "pca = PCA().fit(X)\n", | |
| "print(\"Components:\", 1 + np.argmax(np.cumsum(pca.explained_variance_ratio_) > .99))\n", | |
| "plt.plot(np.cumsum(pca.explained_variance_ratio_))\n", | |
| "plt.xlabel('number of components')\n", | |
| "plt.ylabel('cumulative explained variance');\n", | |
| "</p>\n", | |
| "\n", | |
| "</details>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "venta = pd.read_csv(\"min_venta.csv\", index_col=\"fecha\", parse_dates=True)\n", | |
| "y = venta.codigo_cliente\n", | |
| "X = venta.drop(\"codigo_cliente\", axis=\"columns\")\n", | |
| "pca = PCA().fit(X)\n", | |
| "print(\"Components:\", 1 + np.argmax(np.cumsum(pca.explained_variance_ratio_) > .99))\n", | |
| "plt.plot(np.cumsum(pca.explained_variance_ratio_))\n", | |
| "plt.xlabel('number of components')\n", | |
| "plt.ylabel('cumulative explained variance');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "hqDufwkygoft" | |
| }, | |
| "source": [ | |
| "# No supervisado: k-Means Clustering" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "WCepN02Lgofu" | |
| }, | |
| "source": [ | |
| "Los algoritmos de agrupación buscan aprender, a partir de las propiedades de los datos, una división óptima o un etiquetado discreto de los grupos de puntos.\n", | |
| "\n", | |
| "Muchos algoritmos de clustering están disponibles en Scikit-Learn y en otros lugares, pero quizás el más simple de entender es un algoritmo conocido como *k-means clustering*, que se implementa en ``sklearn.cluster.KMeans``." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "FIhLrG6Igofy" | |
| }, | |
| "source": [ | |
| "## Presentamos a K-Means" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "SyecQZTmgofy" | |
| }, | |
| "source": [ | |
| "El algoritmo *k* significa que busca un número predeterminado de clusters dentro de un conjunto de datos multidimensional sin etiquetar.\n", | |
| "Esto se logra usando un concepto simple de cómo se ve la agrupación óptima:\n", | |
| "\n", | |
| "- El \"centro del cluster\" es la media aritmética de todos los puntos que pertenecen al cluster.\n", | |
| "- Cada punto está más cerca de su propio centro de conglomerados que de otros centros de conglomerados.\n", | |
| "\n", | |
| "Estas dos suposiciones son la base del modelo *k*-Means." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "iibPGfBOgofz", | |
| "outputId": "62f58019-0faa-4887-a612-82ca60189271" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "X, y_true = make_blobs(n_samples=300, centers=4,\n", | |
| " cluster_std=0.60, random_state=0)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], s=50);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "S43jsTFcgof4" | |
| }, | |
| "source": [ | |
| "A simple vista, es relativamente fácil distinguir los cuatro grupos.\n", | |
| "El algoritmo *k*-means lo hace automáticamente, y en Scikit-Learn utiliza la típica API del estimador:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "Lco3pWH2gof4" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.cluster import KMeans\n", | |
| "kmeans = KMeans(n_clusters=4)\n", | |
| "kmeans.fit(X)\n", | |
| "y_kmeans = kmeans.predict(X)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "7kCQWeDggof7" | |
| }, | |
| "source": [ | |
| "Visualicemos los resultados trazando los datos coloreados por estas etiquetas.\n", | |
| "También trazaremos los centros de conglomerados según lo determinado por el estimador de medios *k*:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "rJgyhD9cgof7", | |
| "outputId": "5ba6b9fe-6a5c-4b41-9c4e-188e31be7ce8" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')\n", | |
| "\n", | |
| "centers = kmeans.cluster_centers_\n", | |
| "plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5);" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "k4NvJM0bgof-" | |
| }, | |
| "source": [ | |
| "La buena noticia es que el algoritmo k-means (al menos en este simple caso) asigna los puntos a los clusters de forma muy similar a como los asignamos a ojo.\n", | |
| "Pero se preguntarán cómo este algoritmo encuentra estos clusters tan rápidamente! Después de todo, el número de combinaciones posibles de asignaciones de conglomerados es exponencial en el número de puntos de datos: una búsqueda exhaustiva sería muy, muy costosa.\n", | |
| "Afortunadamente para nosotros, una búsqueda tan exhaustiva no es necesaria: en cambio, el enfoque típico de k-means implica un enfoque iterativo intuitivo conocido como *expectativa-maximización*." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "vSJawTlwgof_" | |
| }, | |
| "source": [ | |
| "## Algoritmo k-Means: Esperanza-Maximización " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "-S_jjw1ggogA" | |
| }, | |
| "source": [ | |
| "*k*-means es una aplicación del algoritmo de maximización de esperanzas o expectativas particularmente simple y fácil de entender, y vamos a repasarla brevemente aquí.\n", | |
| "En resumen, el enfoque de maximización de expectativas consiste:\n", | |
| "\n", | |
| "1. Proponer aleatoriamente algunos centros de conglomerados\n", | |
| "2. Repetir hasta que converjan\n", | |
| " 1. *Paso E*: Asignar puntos al centro de conglomerados más cercano.\n", | |
| " 2. *Paso M*: poner los centros del cluster en la media.\n", | |
| "\n", | |
| "Aquí el \"paso E\" o \"paso de la expectativa\" se llama así porque implica actualizar nuestra expectativa de a qué grupo pertenece cada punto.\n", | |
| "El \"paso M\" o \"paso de maximización\" se denomina así porque implica maximizar alguna función de aptitud que define la ubicación de los centros de clústeres; en este caso, la maximización se logra tomando una media simple de los datos de cada clúster.\n", | |
| "\n", | |
| "La literatura sobre este algoritmo es vasta, pero se puede resumir de la siguiente manera: bajo circunstancias típicas, cada repetición de los pasos E y M siempre resultará en una mejor estimación de las características del cluster." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "oktReupQgogB" | |
| }, | |
| "source": [ | |
| "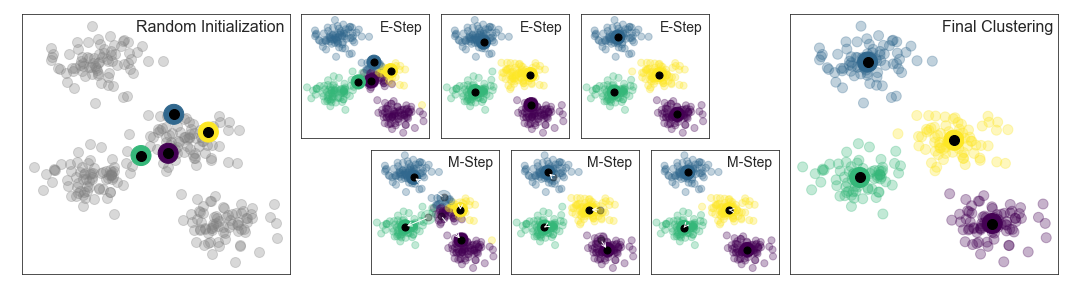\n", | |
| "<div align=\"right\" style=\"padding-top: 4px;\">— Fuente: <a href=\"https://github.com/jakevdp/PythonDataScienceHandbook\">Python Data Science Handbook</a></div>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "bs1QV-wBgogB" | |
| }, | |
| "source": [ | |
| "El algoritmo *k*-Means es tan simple que podemos escribirlo en unas pocas líneas de código.\n", | |
| "La siguiente es una implementación muy básica:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "DyvnFnHDgogC", | |
| "outputId": "d0dd4fdd-0772-4d7c-8d40-f6b0fb3392c2" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.metrics import pairwise_distances_argmin\n", | |
| "\n", | |
| "def find_clusters(X, n_clusters, rseed=2):\n", | |
| " # 1. Randomly choose clusters\n", | |
| " rng = np.random.RandomState(rseed)\n", | |
| " i = rng.permutation(X.shape[0])[:n_clusters]\n", | |
| " centers = X[i]\n", | |
| " \n", | |
| " while True:\n", | |
| " # 2a. Assign labels based on closest center\n", | |
| " labels = pairwise_distances_argmin(X, centers)\n", | |
| " \n", | |
| " # 2b. Find new centers from means of points\n", | |
| " new_centers = np.array([X[labels == i].mean(0)\n", | |
| " for i in range(n_clusters)])\n", | |
| " \n", | |
| " # 2c. Check for convergence\n", | |
| " if np.all(centers == new_centers):\n", | |
| " break\n", | |
| " centers = new_centers\n", | |
| " \n", | |
| " return centers, labels\n", | |
| "\n", | |
| "centers, labels = find_clusters(X, 4)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=labels,\n", | |
| " s=50, cmap='viridis');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "EPc1o_BQgogG" | |
| }, | |
| "source": [ | |
| "La mayoría de las implementaciones bien probadas harán un poco más que esto, pero la función anterior da la esencia del enfoque de maximización de expectativas." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "gv1DPZEVgogG" | |
| }, | |
| "source": [ | |
| "### Advertencias de maximización de expectativas\n", | |
| "\n", | |
| "Hay algunos problemas que hay que tener en cuenta cuando se utiliza el algoritmo de maximización de expectativas." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "aihKL-h0gogH" | |
| }, | |
| "source": [ | |
| "#### El resultado globalmente óptimo puede que no se logre\n", | |
| "En primer lugar, aunque el procedimiento de E-M está garantizado para mejorar el resultado en cada paso, no hay seguridad de que conduzca a la mejor solución *global*.\n", | |
| "Por ejemplo, si utilizamos una semilla aleatoria diferente en nuestro procedimiento simple, las suposiciones iniciales particulares conducen a resultados pobres:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "AGinKBJagogI", | |
| "outputId": "ef61225a-71a6-44c9-db1a-2f962e7b0c9d" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "centers, labels = find_clusters(X, 4, rseed=0)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=labels,\n", | |
| " s=50, cmap='viridis');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "02zkbal-gogL" | |
| }, | |
| "source": [ | |
| "Aquí el enfoque de E-M ha convergido, pero no ha convergido hacia una configuración globalmente óptima. Por esta razón, es común que el algoritmo se ejecute para múltiples suposiciones iniciales, como lo hace Scikit-Learn por defecto (establecido por el parámetro ``n_init``, que por defecto es 10)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "-fQH3nA5gogM" | |
| }, | |
| "source": [ | |
| "#### El número de conglomerados debe ser seleccionado de antemano\n", | |
| "Otro desafío común con *k* significa que usted debe decirle cuántos clústeres espera: no puede aprender el número de clústeres a partir de los datos.\n", | |
| "Por ejemplo, si le pedimos al algoritmo que identifique seis clusters, con mucho gusto procederá y encontrará los mejores seis clusters:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "Vyx4NvxkgogN", | |
| "outputId": "5f430710-f211-46a3-d7c8-d2d1a28b7a7a" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "labels = KMeans(6, random_state=0).fit_predict(X)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=labels,\n", | |
| " s=50, cmap='viridis');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "rszTc71YgogS" | |
| }, | |
| "source": [ | |
| "#### k-means se limita a los límites de los cúmulos lineales\n", | |
| "Las suposiciones fundamentales del modelo de *k*-means (los puntos estarán más cerca de su propio centro de clústeres que de otros) significa que el algoritmo a menudo será ineficaz si los clústeres tienen geometrías complicadas.\n", | |
| "\n", | |
| "En particular, los límites entre $k$ significa que los clusters siempre serán lineales, lo que significa que fallarán en el caso de límites más complicados.\n", | |
| "Considere los siguientes datos, junto con las etiquetas de los clústeres que se encuentran en el típico método *k*-means:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "VULFZPpWgogT" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.datasets import make_moons\n", | |
| "X, y = make_moons(200, noise=.05, random_state=0)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "T9hoY6yCgogV", | |
| "outputId": "a4bc855f-6581-4c7c-b433-79a4fb6c1488" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "labels = KMeans(2, random_state=0).fit_predict(X)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=labels,\n", | |
| " s=50, cmap='viridis');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "LHS1UDoogogY" | |
| }, | |
| "source": [ | |
| "Como hacíamos con las máquinas de soporte vectorial, una versión similar existe para *k* kernelizados en el estimador ``SpectralClustering``.\n", | |
| "Utiliza el gráfico de los vecinos más cercanos para calcular una representación de mayor dimensión de los datos, y luego asigna etiquetas utilizando un algoritmo *k*-means:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "colab": {}, | |
| "colab_type": "code", | |
| "id": "nqIIjJR6gogZ", | |
| "outputId": "b7ea7445-e8c0-4f93-8a32-5930a38fd7da" | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.cluster import SpectralClustering\n", | |
| "model = SpectralClustering(n_clusters=2, affinity='nearest_neighbors',\n", | |
| " assign_labels='kmeans')\n", | |
| "labels = model.fit_predict(X)\n", | |
| "plt.scatter(X[:, 0], X[:, 1], c=labels,\n", | |
| " s=50, cmap='viridis');" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "tkmjsSPNgogc" | |
| }, | |
| "source": [ | |
| "Vemos que con este enfoque de transformación del núcleo, el medio *k* kernelizado es capaz de encontrar los límites no lineales más complicados entre los clusters." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "colab_type": "text", | |
| "id": "qekJKxJ_gogd" | |
| }, | |
| "source": [ | |
| "#### Puede ser lento para un gran número de muestras.\n", | |
| "Debido a que cada iteración de k significa que debe acceder a cada punto del conjunto de datos, el algoritmo puede ser relativamente lento a medida que el número de muestras crece.\n", | |
| "Puede que se pregunte si este requisito de utilizar todos los datos en cada iteración puede relajarse; por ejemplo, puede utilizar un subconjunto de los datos para actualizar los centros de clústeres en cada paso.\n", | |
| "Esta es la idea detrás de los algoritmos k-means basados en lotes, una de cuyas formas se implementa en ``sklearn.cluster.MiniBatchKMeans``." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "<div style=\"font-size: 1em; margin: 1em 0 1em 0; border: 1px solid #86989B; background-color: #f7f7f7; padding: 0;\">\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; font-weight: bold; background-color: #AFC1C4;\">\n", | |
| "Ejercicio\n", | |
| "</p>\n", | |
| "<p style=\"margin: 0.5em 1em 0.5em 1em; padding: 0;\">\n", | |
| "\n", | |
| "A patir del dataset `sns.load_dataset('titanic')`, se pide crear varios modelo binario de supervivencia usando `KMeans`, `SVC`, `RandomForestClassifier`, reportar su exactitud y predecir si los siguientes pasajeros morirían o sobrevivirían para cada uno:\n", | |
| "\n", | |
| "- Rose DeWitt Bukater, 17 años, mujer, 1ª clase, el billete costó £60.\n", | |
| "- Jack Dawson, 20 años, hombre, 3ª clase, el billete costó £8.\n", | |
| "</div>\n", | |
| "\n", | |
| "<details>\n", | |
| " <summary style=\"float: right; position: relative;\"><em>Solution</em></summary>\n", | |
| "<p style=\"margin: 0; padding: 0.1em 0 0.1em 0.5em; color: white; border-bottom: 1px solid #86989B; background-color: #EEEFF0;\">\n", | |
| "<code>\n", | |
| "titanic = sns.load_dataset('titanic').dropna()\n", | |
| "titanic[\"male\"] = titanic[\"sex\"] == \"male\"\n", | |
| "X = titanic[[\"age\", \"male\", \"pclass\", \"fare\"]]\n", | |
| "y = titanic[\"survived\"]\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=1)\n", | |
| "for clf in (KMeans, SVC, RandomForestClassifier):\n", | |
| " print(clf)\n", | |
| " model = clf(2)\n", | |
| " model.fit(Xtrain, ytrain)\n", | |
| " accuracy = accuracy_score(model.predict(Xtest), ytest)\n", | |
| " print(\"Accuracy:\", accuracy)\n", | |
| " print(\"Rose DeWitt Bukater:\", model.predict([[17, 0, 1, 60]])[0])\n", | |
| " print(\"Jack Dawson:\", model.predict([[20, 1, 3, 8]])[0])\n", | |
| " print()\n", | |
| "</code>\n", | |
| "</p>\n", | |
| "\n", | |
| "</details>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "titanic = sns.load_dataset('titanic').dropna()\n", | |
| "titanic[\"male\"] = titanic[\"sex\"] == \"male\"\n", | |
| "X = titanic[[\"age\", \"male\", \"pclass\", \"fare\"]]\n", | |
| "y = titanic[\"survived\"]\n", | |
| "Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=1)\n", | |
| "for clf in (KMeans, SVC, RandomForestClassifier):\n", | |
| " print(clf)\n", | |
| " model = clf(2)\n", | |
| " model.fit(Xtrain, ytrain)\n", | |
| " accuracy = accuracy_score(model.predict(Xtest), ytest)\n", | |
| " print(\"Accuracy:\", accuracy)\n", | |
| " print(\"Rose DeWitt Bukater:\", model.predict([[17, 0, 1, 60]])[0])\n", | |
| " print(\"Jack Dawson:\", model.predict([[20, 1, 3, 8]])[0])\n", | |
| " print()" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "colab": { | |
| "name": "05.00-Machine-Learning.ipynb", | |
| "provenance": [], | |
| "version": "0.3.2" | |
| }, | |
| "kernelspec": { | |
| "display_name": "Python 3", | |
| "language": "python", | |
| "name": "python3" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.7.3" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 1 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment