Last active
October 29, 2020 16:58
-
-
Save visualDust/ace69ba8db6e145fa47df967a935a4af to your computer and use it in GitHub Desktop.
TF2基本操作
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "nbformat": 4, | |
| "nbformat_minor": 0, | |
| "metadata": { | |
| "colab": { | |
| "name": "TF2基本操作", | |
| "provenance": [], | |
| "collapsed_sections": [], | |
| "toc_visible": true, | |
| "mount_file_id": "1_XDqwYGmE1SnE6XRp9bJGSqE64aT6tC4", | |
| "authorship_tag": "ABX9TyOan6/extE0XfSsRDY8lci6", | |
| "include_colab_link": true | |
| }, | |
| "kernelspec": { | |
| "name": "python3", | |
| "display_name": "Python 3" | |
| } | |
| }, | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "view-in-github", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "<a href=\"https://colab.research.google.com/gist/visualDust/ace69ba8db6e145fa47df967a935a4af/tf2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "so5VssGiw4jn" | |
| }, | |
| "source": [ | |
| "# 索引和切片 \n", | |
| "索引和切片能够很方便的帮你拿到你想要的部分数据。" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "KK4vDUbbugmw" | |
| }, | |
| "source": [ | |
| "# importing\n", | |
| "import os\n", | |
| "os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' \n", | |
| "import tensorflow as tf\n", | |
| "from tensorflow.keras import layers\n", | |
| "import pandas as pd" | |
| ], | |
| "execution_count": 1, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "IpFfED28HFKj", | |
| "outputId": "bee608e6-dabc-4e15-b6ab-abf59d3f7c27", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/" | |
| } | |
| }, | |
| "source": [ | |
| "a = tf.constant([[0,1,0,0],[1,0,1,0],[0,0,0,1],[0,1,0,0]])\n", | |
| "print(a@a)" | |
| ], | |
| "execution_count": 3, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "tf.Tensor(\n", | |
| "[[1 0 1 0]\n", | |
| " [0 1 0 1]\n", | |
| " [0 1 0 0]\n", | |
| " [1 0 1 0]], shape=(4, 4), dtype=int32)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "ZM0morMG1Wzk" | |
| }, | |
| "source": [ | |
| "## List \n", | |
| "List是python的builtin,是一种非常灵活的数据载体, 可以包含任何类型的数据" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "ME-KlE-Ivt83", | |
| "outputId": "b7e8389a-7c41-418b-d2ad-aea070827035", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/" | |
| } | |
| }, | |
| "source": [ | |
| "a = ['a', 'b', 'c']\n", | |
| "b = [1, 2, 3]\n", | |
| "c = [1, 2, 'c']\n", | |
| "d = [1, 'b', [3]]\n", | |
| "e = [1, b, [c, '4']]\n", | |
| "print(\"a=\",a,\"b=\",b,\"c=\",c,\"d=\",d,\"e=\",e)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "a= ['a', 'b', 'c'] b= [1, 2, 3] c= [1, 2, 'c'] d= [1, 'b', [3]] e= [1, [1, 2, 3], [[1, 2, 'c'], '4']]\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "L4riZa9W0Gi0" | |
| }, | |
| "source": [ | |
| "## Tensor \n", | |
| "Tensor意味着张量,是一种自由的多维度数据载体,也是tensorflow使用的数据载体。" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "--h6Eyr5v1-W", | |
| "outputId": "cda07bc7-d18d-48e1-c436-d75f57ac473d", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/" | |
| } | |
| }, | |
| "source": [ | |
| "tensor_0 = tf.random.normal([4,28,28,3]) # 假设这是一个含有四张28x28像素彩色图片的数据集\n", | |
| "print(\"数据集的shape: \",tensor_0.shape) \n", | |
| "# 省略号...代表任意长度的冒号,只要能在逻辑上推断的都可以使用省略号\n", | |
| "print(\"第一张照片的shape: \",tensor_0[0,:,:,:].shape)\n", | |
| "print(\"和上一行等效,时第一张图片的shape: \",tensor_0[0,...].shape)\n", | |
| "# 省略号也可以用来省略前面的冒号\n", | |
| "print(\"所有照片的所有像素的Red通道的shape: \",tensor_0[:,:,:,0].shape)\n", | |
| "print(\"和上一行等效,时所有像素的Red通道的shape: \",tensor_0[...,0].shape)\n" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "数据集的shape: (4, 28, 28, 3)\n", | |
| "第一张照片的shape: (28, 28, 3)\n", | |
| "和上一行等效,时第一张图片的shape: (28, 28, 3)\n", | |
| "所有照片的所有像素的Red通道的shape: (4, 28, 28)\n", | |
| "和上一行等效,时所有像素的Red通道的shape: (4, 28, 28)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "ThuXo1Ys1CDb" | |
| }, | |
| "source": [ | |
| "## Selective index \n", | |
| "使用冒号等能获得连续的一段数据,而SelectiveIndex能获取可以定义具体的采样方式。" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "sOTU37kJEodh" | |
| }, | |
| "source": [ | |
| "### tensorflow.gather" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "q-MG8Org0Dmz", | |
| "outputId": "1cd11de2-6d38-4d8a-e2a0-4a7b57380154", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 104 | |
| } | |
| }, | |
| "source": [ | |
| "\n", | |
| "# indices意味指标。在使用gather时需要一个选择的指标作为参数。\n", | |
| "# 举个例子,有4个班级,每个班级5名学生,每个学生有5门课程。数据集表示所有学生的所有课程的成绩。\n", | |
| "course_score = tf.random.normal([4,35,8])\n", | |
| "print(\"二班和三班成绩的shape: \",tf.gather(course_score,axis=0,indices=[2,3]).shape) # 在维度0中选择下标2和3。\n", | |
| "print(\"通过简单索引获得相同效果: \",course_score[2:4].shape) # 与上述语句等效的传统的选择方式\n", | |
| "# 使用gather能让你在选择顺序上下手脚\n", | |
| "print(\"三班和二班的成绩的shape: \",tf.gather(course_score,axis=0,indices=[3,2]).shape) # 改变了选择的顺序\n", | |
| "print(\"抽取每个班第 2 3 4 个学生的成绩\",tf.gather(course_score,axis=1,indices=[1,2,3]).shape) # gather可以取任意维度\n", | |
| "print(\"抽取所有学生的第 2 3 门课程的成绩\",tf.gather(course_score,axis=2,indices=[1,2]).shape) # 还是演示改变选择的维度" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "二班和三班成绩的shape: (2, 35, 8)\n", | |
| "通过简单索引获得相同效果: (2, 35, 8)\n", | |
| "三班和二班的成绩的shape: (2, 35, 8)\n", | |
| "抽取每个班第 2 3 4 个学生的成绩 (4, 3, 8)\n", | |
| "抽取所有学生的第 2 3 门课程的成绩 (4, 35, 2)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "lO8nK8xqEuW0" | |
| }, | |
| "source": [ | |
| "### tensorflow.gather_nd" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "qlPVAyS8Ezgd", | |
| "outputId": "ad8094f9-c5f1-440f-d74d-0e0070cb2fdb", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/" | |
| } | |
| }, | |
| "source": [ | |
| "# gater_nd 能够使用更复杂的筛选条件\n", | |
| "print(\"取第1个班级的第2个同学的第3门课的成绩\",tf.gather_nd(course_score,[0,1,2]).shape)\n", | |
| "print(\"分别取第1和第2个班级的第3个和第4个学生的成绩\",tf.gather_nd(course_score,[[0,1],[2,3]]).shape)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "取第1个班级的第2个同学的第3门课的成绩 ()\n", | |
| "分别取第1和第2个班级的第3个和第4个学生的成绩 (2, 8)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "Wk31KEIUE5Hk" | |
| }, | |
| "source": [ | |
| "### tensorflow.boolean_mask" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "8slrTf1DE-XP" | |
| }, | |
| "source": [ | |
| "# boolean_mask 能通过一个布尔序列进行筛选。boolean_mask可以在某种程度上实现reshape\n", | |
| "print(\"对第一个维度进行筛选,只选择前两个\",tf.boolean_mask(tensor_0,mask=[True,True,False,False]).shape)\n", | |
| "print(\"筛选出每张图片所有像素的R和G通道\",tf.boolean_mask(tensor_0,axis=3,mask=[True,True,False]))\n", | |
| "\n", | |
| "a=tf.ones([2,3,4])\n", | |
| "# 在这里我们选用一个两行三列的mask,涉及到原样本a的前两个维度的筛选\n", | |
| "print(\"筛选出[0,0]<4>[1,1]<4>[1,2]<4>\",tf.boolean_mask(a,[[True,False,False],[False,True,True]])); # 不懂,等着再看看" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "6MBMO5ZLvzb_" | |
| }, | |
| "source": [ | |
| "" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "NTPDWl7Av-yG" | |
| }, | |
| "source": [ | |
| "# 维度变换 \n", | |
| "维度变换是学习人工神经网络需要理解的基本概念之一。 \n", | |
| "对于一个多维的数据,可以有不同的理解方式。例如,我们有一份[4,28,28,3]的数据集,代表一个含有四张28x28像素的彩色图片的数据集。接下来我们提供两种理解方式: \n", | |
| "这是四张图片。 \n", | |
| "这是4x28行像素,每行有28个。 \n", | |
| "其实理论上理解方式可以有很多种。但是无论采用何种方式理解,数据的content本身是不会变化的。我们称不同的理解方式为不同的View。" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "NRDNGZ0g4WiI" | |
| }, | |
| "source": [ | |
| "### tensorflow.reshape \n", | |
| "Reshape就是一个用不同的View理解Tensor的过程。Reshape是全连接层常用操作之一。 " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "-UA5YnDwwCe0", | |
| "outputId": "94df938a-8fcd-4887-919b-5b5827196a6c", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/" | |
| } | |
| }, | |
| "source": [ | |
| "tensor_1 = tf.random.normal([4,28,28,3])\n", | |
| "print(\"原来的tensor_1: \",tensor_1.shape)\n", | |
| "# tensorflow.reshape需要传入一个原始数据和一个你希望得到的view,就能在允许的范围内进行reshape\n", | |
| "print(\"在reshape为view[4, 28*28, 3]之后: \",tf.reshape(tensor_1,[4,784,3]).shape)\n", | |
| "# 上述代码中的view可以等价写为以下代码中的形式\n", | |
| "print(\"在reshape为view[4,-1,3]之后: \",tf.reshape(tensor_1,[4,-1,3]).shape)\n", | |
| "# 注意,一个view中只能写下一个-1,reshape方法会根据你写下的-1自动推算维度。如果同时出现多个-1,就会导致无法推算的问题\n", | |
| "print(\"在reshape为view[4,28*28*3]之后: \",tf.reshape(tensor_1,[4,28*28*3]).shape)\n", | |
| "# 同样,上述代码可以使用-1\n", | |
| "print(\"在reshape为view[4,-1]之后: \",tf.reshape(tensor_1,[4,-1]).shape)\n", | |
| "# 这种类型情况下的reshape通常是可逆的。你可以把它reshape回来\n", | |
| "print(\"试图reshape回veiw[4,28,28,3]: \",tf.reshape(tf.reshape(tensor_1,[4,-1]),[4,28,28,3]).shape)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "原来的tensor_1: (4, 28, 28, 3)\n", | |
| "在reshape为view[4, 28*28, 3]之后: (4, 784, 3)\n", | |
| "在reshape为view[4,-1,3]之后: (4, 784, 3)\n", | |
| "在reshape为view[4,28*28*3]之后: (4, 2352)\n", | |
| "在reshape为view[4,-1]之后: (4, 2352)\n", | |
| "试图reshape回veiw[4,28,28,3]: (4, 28, 28, 3)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "tnj4m42iEzMY" | |
| }, | |
| "source": [ | |
| "### tensorflow.transpose \n", | |
| "`tensorflow.reshape`可以帮助你获得不同view下的content,但是并不能改变content。而`转置(transpose)`可以帮助你更换content中各个维度的顺序。\n", | |
| "转置操作可以是线性代数意义上的(默认情况),也可以根据你传入的参数按需改变content。" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "q8Hldbl1Ey2Y", | |
| "outputId": "b32fab23-f746-4c5d-9451-b7deea123573", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/" | |
| } | |
| }, | |
| "source": [ | |
| "matrix = tf.random.normal([4,3,2,1])\n", | |
| "print(\"原矩阵形状: \",matrix.shape)\n", | |
| "# 不带参数的默认的转置是线性代数意义上的矩阵转置\n", | |
| "print(\"转置后的矩阵形状: \",tf.transpose(matrix).shape)\n", | |
| "# 可以传入参数规定矩阵中各个维度出现的顺序\n", | |
| "print(\"将维度顺序换为0,1,3,2后的形状: \",tf.transpose(matrix,perm=[0,1,3,2]).shape)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "原矩阵形状: (4, 3, 2, 1)\n", | |
| "转置后的矩阵形状: (1, 2, 3, 4)\n", | |
| "将维度顺序换为0,1,3,2后的形状: (4, 3, 1, 2)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "thh0my-vgvK1" | |
| }, | |
| "source": [ | |
| "### tensorflow.expand_dims\n", | |
| "还是用学生成绩的例子,现在有分别来自两个学校的四个班级,每个班级35名学生,每名学生有8门课有成绩。" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "167WFcFrhjup" | |
| }, | |
| "source": [ | |
| "# students' score of the two schools \n", | |
| "course_score = tf.random.normal([4,35,8])\n", | |
| "print(\"原来的成绩的shape: \",course_score.shape)\n", | |
| "# 追加维度时axis给出0,则在首位追加一个维度\n", | |
| "print(\"在下标0前追加一个维度后的shape: \",tf.expand_dims(course_score,axis=0).shape)\n", | |
| "# 给出的axis等于现存维度总数,会在最后追加一个维度\n", | |
| "print(\"在下标3处追加一个维度后的shape: \",tf.expand_dims(course_score,axis=3).shape)\n", | |
| "# 给出的axis是任意小于维度总数的整数x,会在现有的x维度之前追加一个维度。\n", | |
| "print(\"在下标2之前追加一个维度后的shape: \",tf.expand_dims(course_score,axis=2).shape)\n", | |
| "# 给出的axis是负数-x,则会从后往前index到x并追加一个维度 \n", | |
| "print(\"给出axis=-1追加一个维度后的shape: \",tf.expand_dims(course_score,axis=-1).shape)\n", | |
| "print(\"给出axis=-4追加一个维度后的shape: \",tf.expand_dims(course_socre,axis=-4).shape)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "Ol9FApOsl2c9" | |
| }, | |
| "source": [ | |
| "### tensorflow.queeze\n", | |
| "`squeeze`本身是压榨、挤压的意思。其功能如起义,能够帮你将为1的维度挤压掉。" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "Lvc3ZZRamVDU" | |
| }, | |
| "source": [ | |
| "# only squeeze for shape=1 dim\n", | |
| "shape_0 = tf.zeros([1,2,1,1,3])\n", | |
| "print(\"原始的shape_0的shape: \",shape_0.shape)\n", | |
| "print(\"挤压掉为1的维度后的shape: \",tf.squeeze(shape_0).shape)\n", | |
| "print(\"挤压掉下标为0的维度后的shape: \",tf.squeeze(shape_0,axis=0).shape)\n", | |
| "print(\"挤压掉下标为2的维度后的shape: \",tf.squeeze(shape_0,axis=2).shape)\n", | |
| "print(\"挤压掉下标为-2的维度后的shape: \",tf.squeeze(shape_0,axis=-2).shape)\n" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "V5wO8Wy9Z04S" | |
| }, | |
| "source": [ | |
| "# Brodcasting \n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "xIC-fMP617iq" | |
| }, | |
| "source": [ | |
| "## tensorflow.broadcast\n", | |
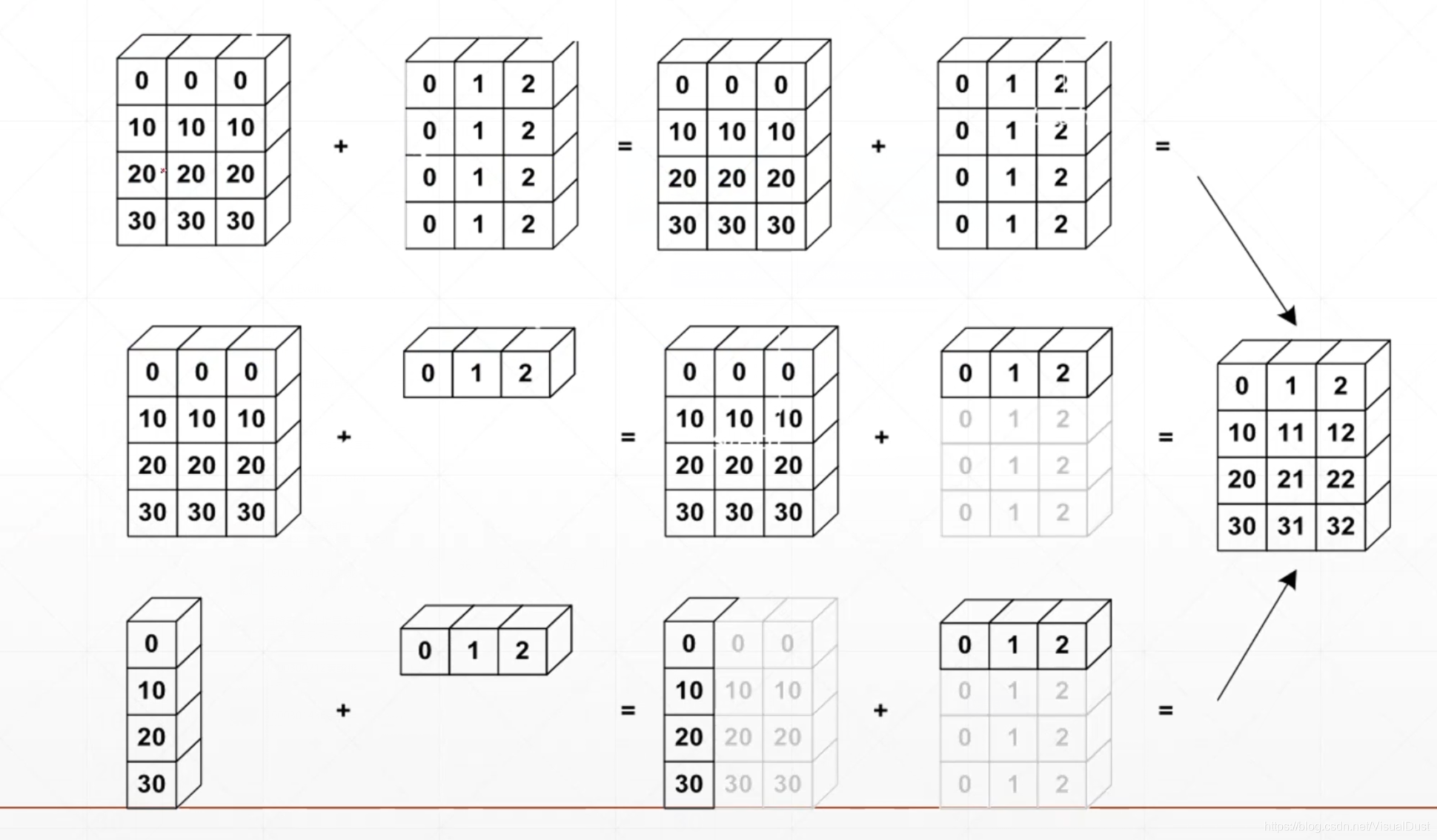
| "以班级和学生成绩为例,现在有四个班级,每个班级有35名学生,每个学生有八门课的成绩。现规定[4,35,8]为全体学生的成绩。例如,第二门科目是物理,而本次物理考试较难,老师打算为所有学生的物理成绩加上5分。也就是,对于每个学生的成绩[4,x]\\(一个八维数据)加上[0,5,0,0,0,0,0,0]。我们可以这样操作: \n", | |
| "```python\n", | |
| "origin = tensorflow.random.normal([4,35,8])\n", | |
| "another = tensorflow.constant([0,5,0,0,0,0,0,0])\n", | |
| "result = tensorflow.broadcast_to(another, origin)\n", | |
| "# 这样another就会被扩展到origin的维度\n", | |
| "```\n", | |
| "\n", | |
| "[4<大维度>, 16, 16, 32<小维度>]习惯上将前面的维度称为大维度,后面的维度称为小维度。Broadcasting会先将小维度对齐,然后对于之前的每一个相对较大的维度,如果缺失,就补1。在这之后,这些为1的维度会被扩展到与目标相同的size。例如,将[32]进行broadcasting,目标是[4,16,16,32]: \n", | |
| "```\n", | |
| "(1) [32]->[1,1,1,32]\n", | |
| "(2) [1,1,1,32]->[4,16,16,32]\n", | |
| "```\n", | |
| "原API描述为: \n", | |
| "```\n", | |
| "(1) Insert 1 dim ahead if needed\n", | |
| "(2) Expand dims with size 1 to the same size\n", | |
| "```\n", | |
| "以下是一个更为现实的例子 \n", | |
| "\n", | |
| "\n", | |
| "需要注意的是比并不是所有的情况都能broadcasting。例如[4]与[1,3],4并不能通过broadcasting变为3。 \n", | |
| "* 关于优化 \n", | |
| "broadcasting进行了特别的优化。在进行broadcasting的过程中不会产生大量的数据复制。这会帮你减少复制带来的内存占用。\n", | |
| "> 请注意,你并不额能随便Broadcasting。 \n", | |
| "\n", | |
| "例如,[2,32,32,14]并不能通过Broadingcast变为[4,32,32,14]。允许broadcasting的条件要求被扩展的维度缺失或为1." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "-V0FOAbvYgFz" | |
| }, | |
| "source": [ | |
| "## Summary of dim expanding \n", | |
| "也就是说,我们现在有了三种扩展维度的方式。以[3,4]扩展到[2,3,4]为例: \n", | |
| "第一种是broadcasting: " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "1yXwQ9Dc1-B_", | |
| "outputId": "c68244ae-ac65-400a-b9b9-fa35954b3d49", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 151 | |
| } | |
| }, | |
| "source": [ | |
| "origin = tf.ones([3,4])\n", | |
| "result = tf.broadcast_to(origin, [2,3,4])\n", | |
| "print(result)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "tf.Tensor(\n", | |
| "[[[1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]]\n", | |
| "\n", | |
| " [[1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]]], shape=(2, 3, 4), dtype=float32)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "62J2hjW6Hudv" | |
| }, | |
| "source": [ | |
| "第二种是expand_dims: " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "KbCoS2NIHe9k", | |
| "outputId": "fcc87cc6-d86c-4c1f-b816-e7c90698491b", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 151 | |
| } | |
| }, | |
| "source": [ | |
| "origin = tf.ones([3,4])\n", | |
| "result = tf.expand_dims(origin, axis=0)\n", | |
| "result = tf.tile(result, [2,1,1])\n", | |
| "print(result)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "tf.Tensor(\n", | |
| "[[[1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]]\n", | |
| "\n", | |
| " [[1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]\n", | |
| " [1. 1. 1. 1.]]], shape=(2, 3, 4), dtype=float32)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "6u12z-eAH5Fn" | |
| }, | |
| "source": [ | |
| "可以看到,两种方法得到的结果是一样的。不过区别是broadcasting存在优化,而expand和tile并没有优化。" | |
| ] | |
| } | |
| ] | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment