generated by OpenAI ChatGPT, data fetched from https://en.wikipedia.org/wiki/2022_FIFA_World_Cup_squads
import requests
from bs4 import BeautifulSoup
import csv
# Define the URL of the Wikipedia pagegenerated by OpenAI ChatGPT, data fetched from https://en.wikipedia.org/wiki/2022_FIFA_World_Cup_squads
import requests
from bs4 import BeautifulSoup
import csv
# Define the URL of the Wikipedia pagebrew install node_exporterdeploy dashboard in docker-compose ...
Add gh action:
name: release
on:
release:
types:
- publishedFor k8s deployment, see https://gist.github.com/wey-gu/699b9a2ef5dff5f0fb5f288d692ddfd5
If not leveraging multiple interfaces, we have to use TLS instead to leverage SNI routing
ip address add 10.1.1.157/24 dev eth0
ip address add 10.1.1.156/24 dev eth0
ip address add 10.1.1.155/24 dev eth0像一般的 Web 应用之于数据库一样,一个典型的基于 NebulaGraph 的传统线上应用可以又三部分组成:
今天,我们给大家简单演示如何开发一个基于 NebulaGraph 的智能机器人应用。本节课旨在快速将我们在 NebulaGraph 入门课程所学与实践开发落地场景连接起来,不会拘泥所有的开发细节, 然而所有的细节在这个示例项目作者的博客中(地址 https://www.siwei.io/siwi/ )都有更详细介绍,如果同学们感兴趣,欢迎访问博客和它的 Github 代码仓库了解。
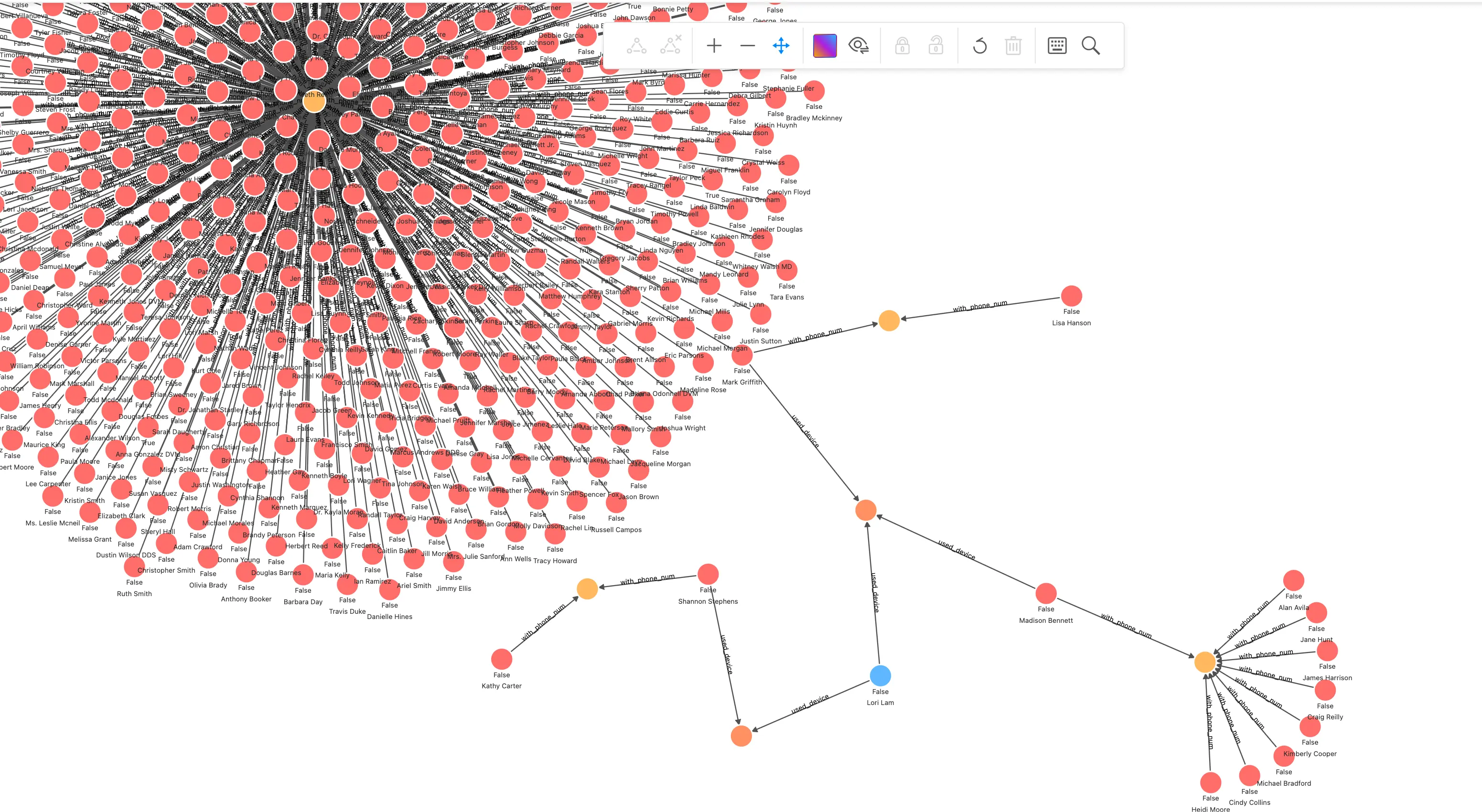
-- 针对一笔交易申请关联查询MATCH (n) WHERE id(n) == "200000010265"
Let's setup Nebula Graph with a graph, Spark, Hadoop, run Nebula Algoritm Node2vec to read Graph from Nebula and Sink result data into a file.
Reference:
def bytes_to_long(bytes):
assert len(bytes) == 8
return sum((b << (k * 8) for k, b in enumerate(bytes)))for Docker compose deployment, see https://gist.github.com/wey-gu/950e4f4c673badae375e59007d80d372
a. create services per metad and storaged pod with LoadBalancer type to expose outside the cluster
b. Use TCP Proxy(b.1) or/and DNS(b.2) to resolve endpoint as their : inside the cluster
In this example, in b. I give a demo where both TCP Proxy and DNS are used, actually only DNS is enough if the exposed port remains same of src and target.