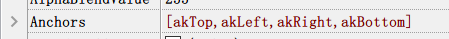Last active
December 23, 2023 04:17
-
-
Save 0x1F9F1/3744179f47e190cbbf35dac34e048c66 to your computer and use it in GitHub Desktop.
Unpack Cheat Engine Trainer
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import zlib | |
| import struct | |
| import base64 | |
| import json | |
| import os | |
| import xml.etree.ElementTree as ET | |
| ce_base85_char_map = dict(zip( | |
| '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz!#$%()*+,-./:;=?@[]^_{}', | |
| '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz!#$%&()*+-;<=>?@^_`{|}~' | |
| )) | |
| def decode_ce_base85(data): | |
| return base64.b85decode(''.join(ce_base85_char_map[v] for v in data)) | |
| def decrypt_ce_trainer(data): | |
| for j in range(2, len(data)): | |
| data[j] ^= data[j - 2] | |
| for j in reversed(range(0, len(data) - 1)): | |
| data[j] ^= data[j + 1] | |
| key = 0xCE | |
| for j in range(len(data)): | |
| data[j] ^= key | |
| key = (key + 1) & 0xFF | |
| assert (data[0:5].decode('ascii') == 'CHEAT'), 'Invalid Trainer' | |
| return zlib.decompress(data[5:], -zlib.MAX_WBITS)[4:] | |
| def read_pascal_string(data, offset): | |
| length = data[offset] | |
| offset += 1 | |
| result = data[offset:offset+length].decode('ascii') | |
| offset += length | |
| return result, offset | |
| def read_form_raw_data(data): | |
| offset = 0 | |
| data_length, = struct.unpack_from('<I', data, offset) | |
| offset += 4 | |
| assert data_length == (len(data) - offset), 'Nope' | |
| offset += 14 | |
| data_length2, = struct.unpack_from('<I', data, offset) | |
| offset += 4 | |
| offset += 4 | |
| assert data_length2 == (len(data) - offset), 'Nope' | |
| return data[offset:] | |
| def read_form_entry(data, offset): | |
| field_type = data[offset] | |
| offset += 1 | |
| result = None | |
| if field_type == 2: # Byte | |
| result, = struct.unpack_from('<B', data, offset) | |
| offset += 1 | |
| elif field_type == 3: # Short | |
| result, = struct.unpack_from('<H', data, offset) | |
| offset += 2 | |
| elif field_type == 6: # String | |
| result, offset = read_pascal_string(data, offset) | |
| elif field_type == 7: # Enum | |
| result, offset = read_pascal_string(data, offset) | |
| elif field_type == 8: # False | |
| result = False | |
| elif field_type == 9: # True | |
| result = True | |
| elif field_type == 10: # Binary Data | |
| data_length, = struct.unpack_from('<I', data, offset) | |
| offset += 4 | |
| raw_data = read_form_raw_data(data[offset:offset+data_length]) | |
| result = 'bytes[0x%X] (%s)' % (data_length, ' '.join('%02X' % (v) for v in raw_data[0:4])) | |
| offset += data_length | |
| else: | |
| raise Exception('Invalid Type %i' % (field_type)) | |
| return result, offset | |
| def process_ce_object(data, offset): | |
| object_fields = { } | |
| object_type, offset = read_pascal_string(data, offset) | |
| object_name, offset = read_pascal_string(data, offset) | |
| while offset < len(data): | |
| field_name, offset = read_pascal_string(data, offset) | |
| if field_name: | |
| field_value, offset = read_form_entry(data, offset) | |
| object_fields[field_name] = field_value | |
| elif data[offset]: | |
| nested_object, offset = process_ce_object(data, offset) | |
| object_fields['%s %s' % (nested_object[0], nested_object[1])] = nested_object[2] | |
| else: | |
| break | |
| return (object_type, object_name, object_fields), offset | |
| def process_ce_form(data): | |
| assert data[0:4].decode('ascii') == 'TPF0', 'Invalid Form' | |
| offset = 4 | |
| form, offset = process_ce_object(data, offset) | |
| assert (offset + 1) == len(data), 'Pending Data' | |
| return form | |
| def process_trainer_xml(output_path, trainer_xml): | |
| forms = trainer_xml.find('Forms') | |
| if forms is not None: | |
| for i, val in enumerate(forms): | |
| assert (val.attrib['Encoding'] == 'Ascii85'), 'Invalid Form' | |
| form_data = zlib.decompress(decode_ce_base85(val.text), -zlib.MAX_WBITS)[4:] | |
| with open('%s/%s_%s_%i.bin' % (output_path, val.tag, val.attrib['Class'], i), 'wb') as f: | |
| f.write(form_data) | |
| form_type, form_name, form_fields = process_ce_form(form_data) | |
| with open('%s/%s_%s_%i_%s_%s.json' % (output_path, val.tag, val.attrib['Class'], i, form_type, form_name), 'w') as f: | |
| f.write(json.dumps(form_fields, indent = 4)) | |
| Files = trainer_xml.find('Files') | |
| if Files is not None: | |
| for i, val in enumerate(Files): | |
| assert (val.attrib['Encoding'] == 'Ascii85'), 'Invalid Form' | |
| file_data = zlib.decompress(decode_ce_base85(val.text), -zlib.MAX_WBITS)[4:] | |
| with open('%s/%s' % (output_path, val.tag), 'wb') as f: | |
| f.write(file_data) | |
| def read_cet_trainer(output_path, raw_data): | |
| file_count, = struct.unpack_from('<I', raw_data, 0); | |
| raw_data = zlib.decompress(raw_data[4:], -zlib.MAX_WBITS) | |
| offset = 0 | |
| print(file_count) | |
| for i in range(file_count): | |
| length, = struct.unpack_from('<I', raw_data, offset); offset += 4 | |
| file_name = raw_data[offset:offset+length].decode('ascii') | |
| offset += length | |
| length, = struct.unpack_from('<I', raw_data, offset); offset += 4 | |
| folder_name = raw_data[offset:offset+length].decode('ascii') | |
| offset += length | |
| length, = struct.unpack_from('<I', raw_data, offset); offset += 4 | |
| file_data = bytearray(raw_data[offset:offset+length]) | |
| offset += length | |
| print(i, file_name, folder_name, len(file_data)) | |
| if file_name == 'CET_TRAINER.CETRAINER': | |
| file_data = decrypt_ce_trainer(file_data) | |
| trainer_xml = ET.fromstring(file_data.decode('ascii')) | |
| process_trainer_xml(output_path, trainer_xml) | |
| else: | |
| continue | |
| with open('%s/%s' % (output_path, file_name), 'wb') as f: | |
| f.write(file_data) | |
| assert (offset == len(raw_data)), 'Invalid Data' | |
| output_path = 'Output' | |
| if not os.path.exists(output_path): | |
| os.makedirs(output_path) | |
| read_cet_trainer(output_path, open('ARCHIVE.bin', 'rb').read()) | |
| process_trainer_xml(output_path, ET.parse('GenericTrainer.CT')) |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Exception occurs at here (Anchors)