I released MessagePack for Ruby 0.5.1. This version is optimized for Rubinius 2.0.0rc1 as well as CRuby 1.9. I improved ruby-serializers benchmark so that it generates simple graphical reports using Google Chart Tools API. (See MessagePack for Ruby version 5 for optimizations I implemented for CRuby)
Here is the result with Rubinius 2.0.0rc1:
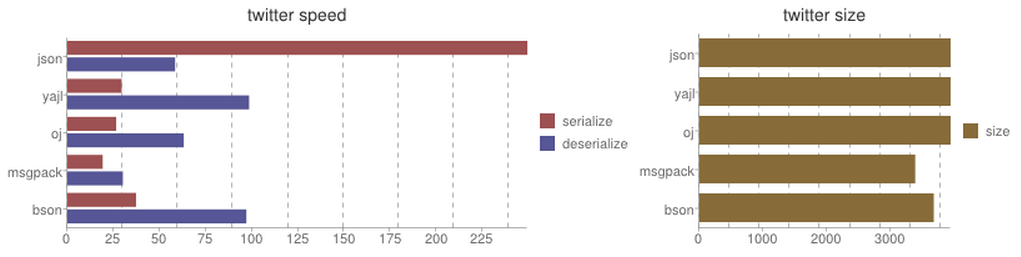
| Library | Serialize | Deserialize | Size |
|---|
json| 249.28 sec| 58.38 sec| 3946 bytes
yajl| 29.42 sec| 98.49 sec| 3946 bytes
oj| 26.47 sec| 63.08 sec| 3946 bytes
msgpack| 19.15 sec| 30.09 sec| 3390 bytes bson| 37.23 sec| 97.01 sec| 3682 bytes
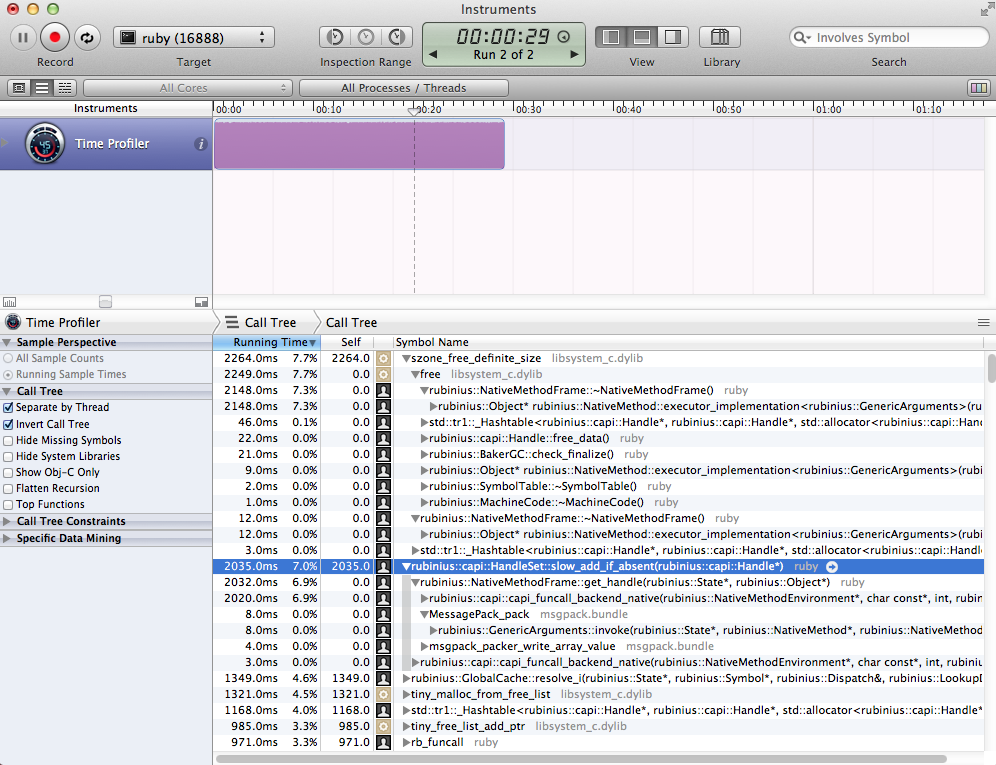
Instruments, a software bundled with XCode, is very useful for performance optimization. According its CPU profiling result, rb_hash_foreach function call consumed lots of CPU time.
So I optimized this function call, and the most time consuming procedure shifted to memory allocation/releasing (as following screenshot shows). I'll need some fundamental changes to improve it.
By the way, MRI-compatible C-API implementation of Rubinius is awesome. I needed few changes for Rubinius.
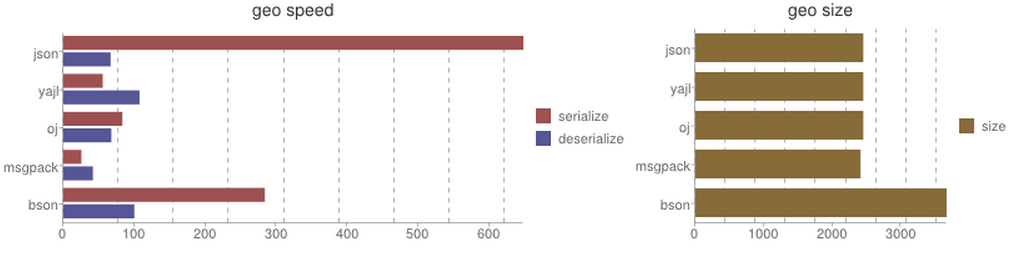
| Library | Serialize | Deserialize | Size |
|---|
json| 647.87 sec| 66.53 sec| 2451 bytes
yajl| 55.51 sec| 107.27 sec| 2451 bytes
oj| 83.15 sec| 67.57 sec| 2451 bytes
msgpack| 25.40 sec| 41.65 sec| 2411 bytes bson| 283.76 sec| 99.90 sec| 3667 bytes
Rubinius implements some core libraries in Ruby. It's difficult to reduce function calling overhead for extensions written in C (without tricky technique?) in contrast to CRuby. I guess that's why performance is worse than the benchmark with CRuby 1.9. I once prototyped a pure-ruby implementation but its performance was much worse than C extensions (a hundred times slower). Even though C extensions grab GVL and cause concurrency degradation, I think C extension is better to implement serialization libraries.
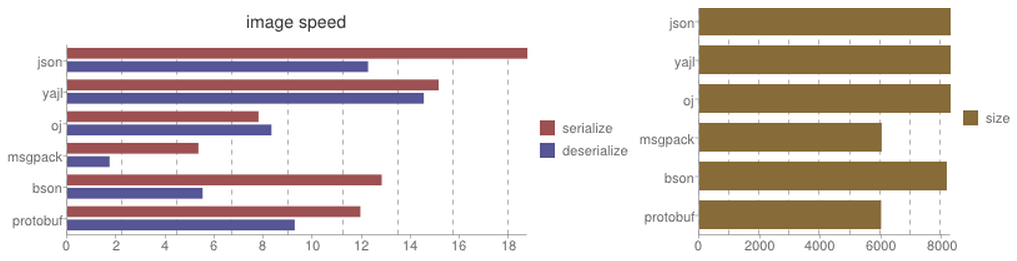
| Library | Serialize | Deserialize | Size |
|---|
json| 18.75 sec| 12.26 sec| 8278 bytes
yajl| 15.13 sec| 14.53 sec| 8278 bytes
oj| 7.79 sec| 8.32 sec| 8278 bytes
msgpack| 5.34 sec| 1.72 sec| 6008 bytes bson| 12.82 sec| 5.51 sec| 8153 bytes protobuf| 11.94 sec| 9.27 sec| 5988 bytes
Serializing/deserializing large binary object consumes most of time to copy data, while function calls affect performance with small objects. I tried to optimize it but I gave up this time. I need to understand architecture of Rubinius furthermore to implement zero-copy. So advantage of msgpack at this benchmark mostly comes from a shared memory pool.
I used following environment for the benchmark:
- OS: Mac OS X 10.8.2
- CPU: Intel COre i7 2.7GHz
- Memory: 16GB 1600MHz DDR3
- rubinius 2.0.0rc1 (1.9.3 a06055d7 2012-11-02 JI) [x86_64-apple-darwin12.2.0]
- gems
- json 1.7.5
- yajl-ruby 1.1.0
- oj 1.4.7
- msgpack 0.5.1
- bson_ext 1.8.0
- protobuf 2.5.5
Awesome! If you have anything that we should improve in Rubinius let us know! I'm sure there are plenty of places in the C-API that could be improved performance wise. Also C extensions don't have a global lock anymore in Rubinius, so they should run concurrently.
Regarding a pure Ruby implementation, this is something we would love to investigate performance wise. Our goals are that Ruby is a viable option, also for these situations. It probably won't happen overnight, but having benchmarks to work with would be great.
Zero copy is more tricky, we do have RSTRING_NOT_MODIFIED that can be defined if a C extension doesn't modify the data that RSTRING_PTR() points at. This can result in nice performance improvements, but does have the restriction then that you can't modify that string data directly.
Don't hesitate to contact us to see how we can improve things :). Usually a good place is to ask around on IRC at irc://freenode.net/rubinius.