- Что такое функциональное программирование?
- Какие основные преимущества функционального программирования?
- В чем разница между императивным и функциональным программированием?
- Что такое функции высшего порядка и как их использовать в Kotlin?
- Как объявить лямбда-функцию в Kotlin?
- Как передать лямбда-функцию в качестве аргумента другой функции?
- Что такое замыкание (closure) в функциональном программировании?
- Что такое неизменяемость (immutability) и почему она важна в функциональном программировании?
- Как создать неизменяемую переменную в Kotlin?
- Как обрабатываются коллекции в Kotlin с помощью функций высшего порядка?.
- Как использовать функцию map() для преобразования элементов коллекции?
- Как использовать функцию filter() для фильтрации элементов коллекции?
- Что такое функция reduce() и как ее использовать для агрегации значений коллекции?
- Как сортировать коллекции с использованием функции sortedBy() в Kotlin?
- Как объединить несколько коллекций с помощью функции flatMap()?
- Как работает ленивая инициализация (lazy initialization) в Kotlin?
- Что такое каррирование (currying) и как его использовать в Kotlin?
- Что такое чистые функции (pure functions) и какие основные свойства они должны иметь?
- Какие конструкции в Kotlin позволяют обеспечить безопасную работу с nullable значениями в контексте функционального программирования?
- Что такое неизменяемые коллекции (immutable collections) и какие преимущества они предоставляют в функциональном программировании?
- Как использовать функцию fold() для агрегации значений коллекции с начальным значением?
- Как использовать функцию zip() для объединения двух коллекций в пары?
- Какие особенности языка Kotlin способствуют функциональному программированию?
- Какие конструкции в Kotlin позволяют работать с последовательностями (sequences) и какова их практическая польза?
- Как использовать функцию groupBy() для группировки элементов коллекции по определенному критерию?
- Какие возможности предоставляются в Kotlin для работы с функциями-расширениями (extension functions)?
- Как использовать функцию takeWhile() для выбора элементов коллекции до тех пор, пока выполняется определенное условие?
- Что такое ленивые вычисления (lazy evaluation) и как их использовать в Kotlin?
- Что такое карта (map) в функциональном программировании и как ее можно использовать для преобразования значений?
- Какие есть ограничения или потенциальные проблемы, с которыми сталкиваются при использовании функционального программирования на языке Kotlin?
- Какие основные принципы функционального программирования вы можете назвать?
- В чем разница между иммутабельностью (immutability) и неизменяемостью (non-mutability)?
- Какие функции Kotlin позволяют создавать список (List) из элементов и применять операции к нему?
- Какие функции Kotlin позволяют объединять две коллекции?
- Каким образом функции Kotlin могут работать с nullable значениями?
- Какие функции Kotlin позволяют сортировать элементы коллекции?
- Какие функции Kotlin позволяют создавать множество (Set) и применять операции к нему?
- Какие функции Kotlin позволяют преобразовывать элементы коллекции в другой тип данных?
- Что такое функциональный интерфейс (functional interface) и как его использовать в Kotlin?
- Какие функции Kotlin позволяют объединять элементы коллекции в одно значение?
- Что такое частичное применение функций (partial function application) и как его реализовать в Kotlin?
- Какие методы доступны для работы с коллекциями в Kotlin, которые позволяют применять функции к элементам коллекции?
- Каким образом функции Kotlin могут использовать замыкания (closures)?
- Какие функции Kotlin позволяют преобразовывать и композировать функции?
- Что такое сопоставление с образцом (pattern matching) и как оно применяется в Kotlin?
- Что такое функциональная композиция (function composition) и как она применяется в Kotlin?
- Что такое монады (monads) и как они используются в функциональном программировании на Kotlin?
- Что такое функторы (functors) и как они применяются в функциональном программировании на Kotlin?
- Что такое линзы (lenses) и как они применяются в функциональном программировании на Kotlin?
- Что такое инъективность (injectivity) функций и как она применяется в Kotlin?
- Что такое функциональное связывание (functional binding) и как оно применяется в Kotlin?
- Что такое корутины (coroutines) в Kotlin и как они используются для асинхронного программирования?
- Что такое мемоизация (memoization) и как она применяется в функциональном программировании на Kotlin?
- Какие функции Kotlin позволяют создавать и работать с бесконечными последовательностями?
- Какие функции Kotlin позволяют применять операции разбиения (split) и соединения (join) к строкам?
- Какие функции Kotlin позволяют применять операции сравнения (compare) и сортировки к объектам?
- Что такое инвариантность (invariance) и ковариантность (covariance) типов в Kotlin и как они связаны с функциональным программированием?
- Что такое инвариантность типов и как она отличается от ковариантности и контравариантности?
- Функциональное программирование – это раздел дискретной математики и парадигма программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
- Противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательность изменения состояний.
- Функциональное программирование не предполагает изменяемость данных (в отличие от императивного, где одной из базовых концепций является переменная).
- Функции высших порядков
- Чистые функции
- Рекурсия (в функционалке нет такого понятия как цикл, всё реализуется через рекурсию(функция вызывает сама себя), но не всегда)
Лямбда-исчисление являются основой для функционального программирования
Функция— это описание процесса, связывающего вход с каким-то выводом. Так же как в любом другом языке программирования.Функция— это базовый элемент функционального программирования.- Функции используются почти для всего, даже для простейших расчётов.
- Даже переменные заменяются функциями.
Неизменяемость (Immutability): Данные в функциональном программировании являются неизменяемыми, то есть после создания их нельзя изменить. Вместо этого создаются новые данные путем применения функций.
Чистые функции (Pure Functions): Функции в функциональном программировании должны быть чистыми, то есть не должны иметь побочных эффектов и всегда возвращать одинаковый результат для одинаковых параметров.
Функции высшего порядка (Higher-Order Functions): Функции могут принимать другие функции в качестве аргументов и возвращать функции в качестве результата.
Рекурсия (Recursion): Рекурсия является основным способом итерации в функциональном программировании.
Каррирование (Currying): Каррирование - это процесс преобразования функции, которая принимает несколько аргументов, в последовательность функций, каждая из которых принимает только один аргумент.
Анонимные функции (Anonymous Functions): Анонимные функции позволяют создавать функции на лету и передавать их в качестве аргументов другим функциям.
Ленивые вычисления (Lazy Evaluation): Ленивые вычисления позволяют откладывать вычисления до тех пор, пока они не понадобятся, что может уменьшить потребление памяти и повысить производительность программы.
Эти принципы и концепции помогают создавать более чистый, модульный и легко поддерживаемый код в функциональном стиле.
-
Основной особенностьюфункционального программирования, определяющей как преимущества, так и недостатки данной парадигмы, является то, что в ней реализуется модель вычислений без состояний. -
Если императивная программа на любом этапе исполнения имеет состояние, то есть совокупность значений всех переменных, и производит побочные эффекты, то чисто функциональная программа ни целиком, ни частями состояния не имеет и побочных эффектов не производит.
-
То, что в императивных языках делается путём присваивания значений переменным, в функциональных достигается путём передачи выражений в параметры функций.
-
Непосредственным следствием становится то, что чисто функциональная программа не может изменять уже имеющиеся у неё данные, а может лишь порождать новые путём копирования и/или расширения старых.
-
Следствием того же является отказ от циклов в пользу рекурсии.
Чистота функций: функции в функциональном программировании обычно являются "чистыми" - они не имеют побочных эффектов и всегда возвращают одинаковый результат для одинаковых входных данных. Это делает функции более предсказуемыми и проще для тестирования и отладки.
Рекурсия: функциональное программирование обычно активно использует рекурсию, что позволяет писать более компактный и выразительный код.
Параллелизм: функциональное программирование облегчает параллелизм, поскольку функции не имеют побочных эффектов и могут выполняться независимо друг от друга.
Выразительность: функциональное программирование обычно позволяет писать более выразительный и лаконичный код.
- Функциональное программирование противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательность изменения состояний.
- Функциональное программирование не предполагает изменяемость данных (в отличие от императивного, где одной из базовых концепций является переменная).
-
Основной особенностьюфункционального программирования, определяющей как преимущества, так и недостатки данной парадигмы, является то, что в ней реализуется модель вычислений без состояний. -
Если императивная программа на любом этапе исполнения имеет состояние, то есть совокупность значений всех переменных, и производит побочные эффекты, то чисто функциональная программа ни целиком, ни частями состояния не имеет и побочных эффектов не производит.
-
То, что в императивных языках делается путём присваивания значений переменным, в функциональных достигается путём передачи выражений в параметры функций.
-
Непосредственным следствием становится то, что чисто функциональная программа не может изменять уже имеющиеся у неё данные, а может лишь порождать новые путём копирования и/или расширения старых.
-
Следствием того же является отказ от циклов в пользу рекурсии.
Функция высшего порядка - это функция, которая принимает функции как параметры, или возвращает функцию в качестве результата.
fun List<String>.mapString(transform: (String) -> Int): List<Int> {
val result = mutableListOf<Int>()
for (item in this) {
result.add(transform(item))
}
return result
}fun <T> operations(key:String, a: T): (T) -> Boolean {
when(key){
"compare" -> return { b -> a == b}
"comparePrint" -> {
println("A : $a")
return {b -> a == b}
}
else -> return { b -> a == b}
}
}Можно присвоить функциональному типу альтернативное имя, используя псевдонимы типов.
typealias ClickHandler = (Button, ClickEvent) -> UnitСуществует несколько способов получить экземпляр функционального типа:
- Используя блок с кодом внутри функционального литерала в одной из форм:
- лямбда-выражение:
{ a, b -> a + b } - анонимная функция:
fun(s: String): Int { return s.toIntOrNull() ?: 0 }
- лямбда-выражение:
- Используя вызываемую ссылку на существующее объявление:
- функции верхнего уровня, локальной функции, функции-члена или функции расширения:
::isOdd,String::toInt - свойства верхнего уровня, члена или свойства-расширения:
List::size - конструктора:
::Regex
- функции верхнего уровня, локальной функции, функции-члена или функции расширения:
Лямбда-выражения и анонимные функции - это "функциональный литерал", то есть необъявленная функция, которая немедленно используется в качестве выражения.
max(strings, { a, b -> a.length < b.length })Очень часто лямбда-выражение имеет только один параметр.
Если компилятор способен самостоятельно определить сигнатуру, то объявление параметра можно опустить вместе с ->. Параметр будет неявно объявлен под именем it.
ints.filter { it > 0 } // этот литерал имеет тип '(it: Int) -> Boolean’Мы можем вернуть значение из лямбды явно, используя оператор return. Либо неявно будет возвращено значение последнего выражения. Таким образом, два следующих фрагмента равнозначны.
ints.filter
{
val shouldFilter = it > 0
shouldFilter
}
ints.filter
{
val shouldFilter = it > 0
return@filter shouldFilter
}Kotlin использует семейство функциональных типов, таких как (Int) -> String, для объявлений, которые являются частью функций: val onClick: () -> Unit = ....
Эти типы имеют специальные обозначения, которые соответствуют сигнатурам функций, то есть их параметрам и возвращаемым значениям:
-
(A, B) -> Cобозначает тип, который предоставляет функции два принятых аргумента типаAиB, а также возвращает значение типаC. Список с типами параметров может быть пустым, как, например, в() -> A. -
У функциональных типов может быть дополнительный тип -
получатель(receiver), который указывается в объявлении перед точкой: типA.(B) -> Cописывает функции, которые могут быть вызваны для объекта-получателяAс параметромBи возвращаемым значениемC. Литералы функций с объектом-приёмником часто используются вместе с этими типами.
fun main() {
val repeatFun: String.(Int) -> String = { times -> this.repeat(times) }
val str = "eee"
println(str.repeatFun(3))
}- Останавливаемые функции
(suspending functions)принадлежат к особому виду функциональных типов, у которых в объявлении присутствует модификаторsuspend, например, suspend () -> Unit или suspend A.(B) -> C.
Объявление функционального типа также может включать именованные параметры: (x: Int, y: Int) -> Point. Именованные параметры могут быть использованы для описания смысла каждого из параметров.
fun List<String>.mapString(transform: (String) -> Int): List<Int> {
val result = mutableListOf<Int>()
for (item in this) {
result.add(transform(item))
}
return result
}Можно присвоить функциональному типу альтернативное имя, используя псевдонимы типов.
typealias ClickHandler = (Button, ClickEvent) -> Unit- Использование функций высшего порядка влечёт за собой снижение производительности: во-первых, функция является объектом, а во-вторых, происходит захват контекста замыканием, то есть функции становятся доступны переменные, объявленные вне её тела. А выделения памяти (как для объекта функции, так и для её класса) и виртуальные вызовы занимают системные ресурсы.
- Как правило, лямбда-выражения компилируются в анонимные классы. То есть каждый раз, когда
используется лямбда-выражение, создаётся дополнительный класс. Отсюда вытекают дополнительные накладные расходы у функций, которые принимают лямбду в качестве аргумента. Если же функцию отметить модификатором
inline, то компилятор не будет создавать анонимные классы и их объекты для каждого лямбда-выражения, а просто вставит код её реализации в место вызова. Или другими словами встроит её.
Чтобы заставить компилятор поступить именно так, нам необходимо отметить функцию lock модификатором inline.
inline fun lock(lock: Lock, body: () -> T): T { // ... }Модификатор inline влияет и на функцию, и на лямбду, переданную ей: они обе будут встроены в место вызова.
Неизменяемое состояние — состояние объекта, которое не может быть изменено после того, как объект был создан. Под состоянием объекта здесь, подразумевается набор значений его свойств.
Так как неизменяемые объекты гарантируют нам, что на протяжении своего жизненного цикла они не могут менять свое состояние, то мы можем быть уверены, что использование или передача таких объектов в другие места программы не приведет к каким либо непредвиденным последствиям. Это особенно важно при работе в многопоточном окружении.
Kotlin не является чисто-функциональным языком, поэтому неизменяемые объекты сосуществуют с изменяемыми на равных правах. Дизайн ненавязчиво подталкивает программиста к использованию неизменяемых объектов, но в целом выбор каждый раз остается за разработчиком.
val a: Int = 1
val b = 1 // Тип `Int` выведен автоматически
val c: Int // Тип обязателен, когда значение не инициализируется
c = 1 // последующее присвоениеvar x = 5 // Тип `Int` выведен автоматически
x += 1val FANCY_VAL = 1
const val FANCY_CONST_VAL = 2Переменная FANCY_CONST_VAL будет заинлайнена, то есть компилятор заменит все полученные значения этой переменной на само значение.
Оригинальный код:
public static void main(String[] args) {
System.out.println(ConstValKt.get_FANCY_VAL());
System.out.println(ConstValKt.MY_FANCY_CONST_VAL);
}Декомпилированный код:
public static void main(String[] var0) {
System.out.println(ConstValKt.getFANCY_VAL());
System.out.println(2);
}Вывод: const val позволяет оптимизировать код, избавившись от ненужных геттеров и обращений к переменным.
Mapping: Первая из самых основных функций - map(): Она позволяет преобразовать исходную коллекцию путём применения заданной лямбда-функции к каждому её элементу, объединяя результаты в новую коллекцию. При этом порядок элементов сохраняется.- Если для преобразования коллекции нужно знать индекс элементов, то используйте функцию mapIndexed().
fun main() {
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 }) // [3, 6, 9]
println(numbers.mapIndexed { idx, value -> value * idx }) // [0, 2, 6]
}Фильтрация коллекций в Kotlin - это процесс выборки элементов из коллекции на основе заданного условия.
| Условия фильтра задаются с помощью предикатов — лямбда-функций, которые принимают элемент коллекции, а возвращают логическое значение (boolean): true означает, что элемент соответствует предикату, false - не соответствует. |
|---|
fun main() {
val numbers = listOf("one", "two", "three", "four")
val longerThan3 = numbers.filter { it.length > 3 }
println(longerThan3) // [three, four]
}- Для более специфичных случаев существуют функции
reduce()иfold(). Они последовательно применяют предоставленную операцию к элементам коллекции и возвращают накопленный результат. Операция принимает два аргумента: ранее накопленное значение и элемент коллекции.
Разница между этими двумя функциями состоит в том, что fold() принимает начальное значение и использует его как накопленное значение на первом шаге, тогда как reduce() на первом шаге в качестве аргументов операции использует первый и второй элементы коллекции.
fun main() {
val numbers = listOf(5, 2, 10, 4)
val simpleSum = numbers.reduce { sum, element -> sum + element }
println(simpleSum) // 21
val sumDoubled = numbers.fold(0) { sum, element -> sum + element * 2 }
println(sumDoubled) // 42
// некорректно: первый элемент не будет удвоен
// val sumDoubledReduce = numbers.reduce { sum, element -> sum + element * 2 }
// println(sumDoubledReduce)
}Mapping: Первая из самых основных функций - map(): Она позволяет преобразовать исходную коллекцию путём применения заданной лямбда-функции к каждому её элементу, объединяя результаты в новую коллекцию. При этом порядок элементов сохраняется.- Если для преобразования коллекции нужно знать индекс элементов, то используйте функцию mapIndexed().
fun main() {
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 }) // [3, 6, 9]
println(numbers.mapIndexed { idx, value -> value * idx }) // [0, 2, 6]
}- Если какой-либо элемент или элементы могут быть преобразованы в значение равное null, то вместо
map()можно использовать функциюmapNotNull(), которая отфильтрует такие элементы и они не попадут в новую коллекцию. Соответственно, вместоmapIndexed()можно использоватьmapIndexedNotNull().
fun main() {
val numbers = setOf(1, 2, 3)
println(numbers.mapNotNull { if ( it == 2) null else it * 3 }) // [3, 9]
println(numbers.mapIndexedNotNull { idx, value -> if (idx == 0) null else value * idx }) // [2, 6]
}- Также можно преобразовывать ассоциативные списки двумя способами: преобразовывать ключи, не изменяя значения, и наоборот (mapKeys() и mapValues()). Они обе используют функцию преобразования, которая в качестве аргумента принимает пару "ключ-значение".
fun main() {
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
println(numbersMap.mapKeys { it.key.uppercase() }) // {KEY1=1, KEY2=2, KEY3=3, KEY11=11}
println(numbersMap.mapValues { it.value + it.key.length }) // {key1=5, key2=6, key3=7, key11=16}
}Фильтрация коллекций в Kotlin - это процесс выборки элементов из коллекции на основе заданного условия.
| Условия фильтра задаются с помощью предикатов — лямбда-функций, которые принимают элемент коллекции, а возвращают логическое значение (boolean): true означает, что элемент соответствует предикату, false - не соответствует. |
|---|
-
Основная функция для фильтра коллекций -
filter(): в данной функции предикаты могут проверять только значения элементов. (Для индексовfilterIndexed()) -
Если использовать
filter()с предикатом, то будут возвращены те элементы, которые ему соответствуют. (Для List - результат типа List) -
Если вы хотите отфильтровать элементы, которые не соответствуют заданному условию, то используйте функцию
filterNot(). Она возвращает те элементы, для которых предикат вернул значение false. -
Также есть функция
filterIsInstance(), которая возвращает элементы заданного типа. Она позволяет вызывать специфичные для элементов T функции.
fun main() {
val numbers = listOf(null, 1, "two", 3.0, "four")
println("All String elements in upper case:")
numbers.filterIsInstance<String>().forEach { println(it.uppercase()) }
}
// В логе будет:
// All String elements in upper case:
// TWO
// FOUR- Для более специфичных случаев существуют функции
reduce()иfold(). Они последовательно применяют предоставленную операцию к элементам коллекции и возвращают накопленный результат. Операция принимает два аргумента: ранее накопленное значение и элемент коллекции.
Разница между этими двумя функциями состоит в том, что fold() принимает начальное значение и использует его как накопленное значение на первом шаге, тогда как reduce() на первом шаге в качестве аргументов операции использует первый и второй элементы коллекции.
fun main() {
val numbers = listOf(5, 2, 10, 4)
val simpleSum = numbers.reduce { sum, element -> sum + element }
println(simpleSum) // 21
val sumDoubled = numbers.fold(0) { sum, element -> sum + element * 2 }
println(sumDoubled) // 42
// некорректно: первый элемент не будет удвоен
// val sumDoubledReduce = numbers.reduce { sum, element -> sum + element * 2 }
// println(sumDoubledReduce)
}Чтобы сохранить промежуточное накопленное значение, существуют функции runningFold() и runningReduce().
fun main() {
val numbers = listOf(0, 1, 2, 3, 4, 5)
val runningReduceSum = numbers.runningReduce { sum, item -> sum + item }
val runningFoldSum = numbers.runningFold(10) { sum, item -> sum + item }
val transform = { index: Int, element: Int -> "N = ${index + 1}: $element" }
println(runningReduceSum.mapIndexed(transform).joinToString("\n", "Sum of first N elements with runningReduce:\n"))
println(runningFoldSum.mapIndexed(transform).joinToString("\n", "Sum of first N elements with runningFold:\n"))
}
// В логе будет:
// Sum of first N elements with runningReduce:
// N = 1: 0
// N = 2: 1
// N = 3: 3
// N = 4: 6
// N = 5: 10
// N = 6: 15
// Sum of first N elements with runningFold:
// N = 1: 10
// N = 2: 10
// N = 3: 11
// N = 4: 13
// N = 5: 16
// N = 6: 20
// N = 7: 25
В Kotlin для сортировки коллекций предусмотрены несколько функций-расширений, которые позволяют отсортировать элементы коллекции в заданном порядке.
Способы задать порядок объектов
- Естественный порядок - для наследников интерфейса Comparable. (Также, если для экземпляров не был указан другой порядок сортировки, то они будут отсортированы в естественном порядке).
- Пользовательский порядок - позволяет сортировать экземпляры любого типа так, как вам нравится.
- Для сортировки объектов в пользовательском порядке или для сортировки объектов, которые не реализуют
Comparable, можно использовать функцииsortedBy()иsortedByDescending(). Они используют функцию-селектор для преобразования элементов коллекции вComparableзначения и сортируют коллекцию в естественном порядке этих значений.
fun main() {
val numbers = listOf("one", "two", "three", "four")
val sortedNumbers = numbers.sortedBy { it.length }
println("Sorted by length ascending: $sortedNumbers")
// Sorted by length ascending: [one, two, four, three]
val sortedByLast = numbers.sortedByDescending { it.last() }
println("Sorted by the last letter descending: $sortedByLast")
// Sorted by the last letter descending: [four, two, one, three]
}flatten()- функция возвращает объединённый List, состоящий из всех элементов всех вложенных коллекций. (Её можно использовать для коллекции, содержащей другие коллекции)
fun main() {
val numberSets = listOf(setOf(1, 2, 3), setOf(4, 5, 6), setOf(1, 2))
println(numberSets.flatten()) // [1, 2, 3, 4, 5, 6, 1, 2]
}flatMap()- обеспечивает гибкий способ работы с вложенными коллекциями. Она принимает функцию, которая маппит элемент исходной коллекции в другую коллекцию. В качестве результатаflatMap()возвращает объединённый список из всех обработанных элементов. По сутиflatMap()ведёт себя как вызовmap()(с возвращением коллекции в качестве результата маппинга) иflatten().
data class StringContainer(val values: List<String>)
fun main() {
val containers = listOf( StringContainer(listOf("one", "two", "three")), StringContainer(listOf("four",
"five", "six")), StringContainer(listOf("seven", "eight")) )
println(containers.flatMap { it.values }) // [one, two, three, four, five, six, seven, eight]
}Ленивое вычисление — стратегия вычисления, которая откладывает вычисления выражения до момента, когда значение этого выражения будет необходимо.
Позволяет отложить вычисление некоторого кода до определенного или заранее неопределенного момента времени.
class Work
class Person {
lateinit var work: Work
fun init() {
work = Work()
}
}Модификатор lateinit говорит о том, что данная переменная будет инициализирована позже. При этом инициализировать свойство можно из любого места, откуда она видна.
Правила использования модификатора lateinit:
- используется только совместно с ключевым словом var;
- свойство может быть объявлено только внутри тела класса (не в основном конструкторе);
- тип свойства не может быть нулевым и примитивным;
- у свойства не должно быть пользовательских геттеров и сеттеров;
- с версии Kotlin 1.2 можно применять к свойствам верхнего уровня и локальным переменным.
Если обратиться к свойству с модификатором lateinit до того, как оно будет проинициализировано, то получите ошибку, которая явно указывает, что свойство не было определено.
Стандартная библиотека Kotlin предоставляет несколько полезных видов делегатов:
- Ленивые свойства
(lazy properties) Observableсвойства
lazy() это функция, которая принимает лямбду и возвращает экземпляр класса Lazy, который служит делегатом для реализации ленивого свойства: первый вызов get() запускает лямбда выражение, переданное lazy() в качестве аргумента, и запоминает полученное значение, а последующие вызовы просто возвращают вычисленное значение.
val lazyValue: String by lazy {
println("computed!")
"Hello"
}
fun main(args: Array<String>) {
println(lazyValue)
println(lazyValue)
}Вывод:
computed!
Hello
Hello
Каррирование позволяет нам разбить функцию с несколькими параметрами на несколько функций с одним параметром. Это дает нам возможность получать результат вычисления промежуточных функций и применять к этим функциям разные аргументы для получения нескольких результатов.
fun subtract(x: Int, y: Int): Int {
return x - y
}
println(subtract(50, 8))subtract(50)(8)Мы можем вернуть функцию из другой функции:
fun subtract(x: Int): (Int) -> Int {
return fun(y: Int): Int {
return x - y
}
}в сокращенной форме:
fun subtract(x: Int) = fun(y: Int): Int {
return x - y
}в еще более короткой форме:
fun subtract(x: Int) = {y: Int -> x - y}Kotlin не предоставляет такие изыски «из коробки», но он достаточно гибок, чтобы все это можно было элегантно реализовать в библиотеке funKtionale:
import org.funktionale.currying.*
val sum2ints = { x: Int, y: Int -> x + y }
val curried: (Int) -> (Int) -> Int = sum2ints.curried()
//assertEquals(curried(2)(4), 6)
val add5 = curried(5)
//assertEquals(add5(7), 12)Это функция, которая выполняет два условия.
- Функция всегда возвращает один и тот же результат при одних и тех же входных параметрах.
Прежде всего, он должен быть ссылочно прозрачным (referentially transparent). Ссылочно прозрачная функция всегда дает один и тот же результат, если вы предоставляете ей одни и те же аргументы. Это означает, что такая функция должна работать только со значениями, которые мы передаем, она не должна ссылаться на глобальное состояние.
- И вычисление результата не вызывает видимых семантических побочных эффектов или вывода во вне.
Во-вторых, сигнатура математической функции должна передавать всю информацию о возможных входных значениях, которые она принимает, и о возможных результатах, которые она может дать. Можно называть эту черту честность сигнатуры метода (method signature honesty).
19. Какие конструкции в Kotlin позволяют обеспечить безопасную работу с nullable значениями в контексте функционального программирования?
В Kotlin есть механизмы, которые помогают избежать ошибок, связанных с использованием null значений. Этот механизм называется "null-безопасность"
Kotlin нацелен на исключение ошибок, связанных с null значениями, из кода программы. В отличие от многих других языков, таких как Java, в Kotlin NullPointerException (NPE) может возникать только в следующих случаях:
- Явное выбрасывание исключения
NullPointerException(). - Использования оператора
!!(описано далее) - Исключение было вызвано внешним
Java-кодом. - Несоответствие данных при их инициализации, например, использование ссылки
thisна данные, которые еще не были проинициализированы.
Основной инструмент null-безопасности в Kotlin - это система типов, которая позволяет отличать переменные, которые могут содержать null, от переменных, которые не могут. Для этого используется оператор ?, который позволяет объявить переменную, которая может содержать null.
Оператор !! в Kotlin называется оператором "не-null утверждения" (not-null assertion operator). Он используется для явного указания компилятору, что переменная не может быть null.
val l = if (b != null) b.length else -1Компилятор отслеживает информацию о проведённой вами проверке и позволяет вызывать length внутри блока if.
Обратите внимание: это работает только в том случае, если b является неизменной переменной.
Вторым способом является оператор безопасного вызова ?.:
b?.lengthЭтот код возвращает b.length в том, случае, если b не имеет значение null. Иначе он возвращает null. Типом этого выражения будет Int?.
val l = b?.length ?: -1Если выражение, стоящее слева от Элвис-оператора, не является null, то элвис оператор его вернёт. В противном случае, в качестве возвращаемого значения послужит то, что стоит справа.
Так как throw и return тоже являются выражениями в Kotlin, их также можно использовать справа от Элвис-оператора. Это может быть крайне полезным для проверки аргументов функции:
fun foo(node: Node): String? {
val parent = node.getParent() ?: return null
val name = node.getName() ?: throw IllegalArgumentException("name expected")
// ...
}Для любителей NPE существует ещё один способ. Мы можем написать b!! и это вернёт нам либо non-null значение b (в нашем примере вернётся String), либо выкинет NPE:
val l = b!!.lengthОбычное приведение типа может вызвать ClassCastException в случае, если объект имеет другой тип. Можно использовать безопасное приведение, которое вернёт null, если попытка не удалась:
val aInt: Int? = a as? IntЕсли у вас есть коллекция nullable элементов и вы хотите отфильтровать все non-null элементы, используйте функцию filterNotNull.
val nullableList: List<Int?> = listOf(1, 2, null, 4)
val intList: List<Int> = nullableList.filterNotNull()20. Что такое неизменяемые коллекции (immutable collections) и какие преимущества они предоставляют в функциональном программировании?
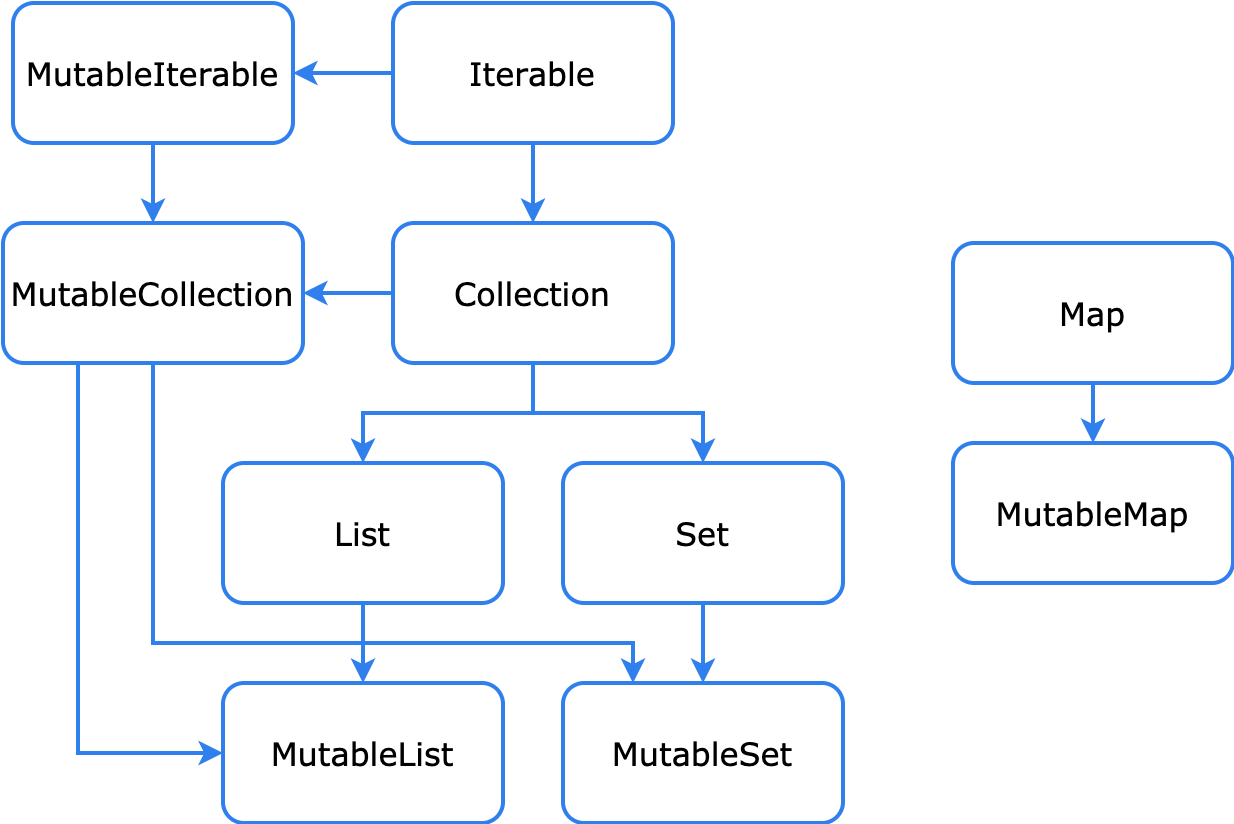
-
List (список)- упорядоченная коллекция, в которой к элементам можно обращаться по индексам — целым числам, отражающим положение элементов в коллекции. Идентичные элементы (дубликаты) могут встречаться в списке более одного раза. Примером списка является предложение: это группа слов, их порядок важен, и они могут повторяться. -
Set (множество)- коллекция уникальных элементов. Отражает математическую абстракцию множества: группа объектов без повторов. Как правило, порядок расположения элементов здесь не имеет значения. Примером множества является алфавит. -
Map (словарь, ассоциативный список)- набор из пар "ключ-значение". Ключи уникальны и каждый из них соответствует ровно одному значению. Значения могут иметь дубликаты. Ассоциативные списки полезны для хранения логических связей между объектами, например, ID сотрудников и их должностей.
Интерфейсы коллекций и связанные с ними функции находятся в пакете kotlin.collections.
-
неизменяемый (read-only)- предоставляет операции, которые дают доступ к элементам коллекции. -
изменяемый (mutable)- расширяет предыдущий интерфейс и дополнительно даёт доступ к операциям добавления, удаления и обновления элементов коллекции.
Так как неизменяемые объекты гарантируют нам, что на протяжении своего жизненного цикла они не могут менять свое состояние, то мы можем быть уверены, что использование или передача таких объектов в другие места программы не приведет к каким либо непредвиденным последствиям. Это особенно важно при работе в многопоточном окружении.
Неизменяемые типы коллекций ковариантны. Это означает, что если класс Rectangle наследуется от Shape, вы можете использовать List<Rectangle> там, где требуется List<Shape>. Другими словами, типы коллекций имеют такое же отношение подтипов, что и типы элементов. Map-ы ковариантны по типу значения, но не по типу ключа.
В свою очередь, изменяемые коллекции не являются ковариантными; в противном случае это привело бы к сбоям во время выполнения. Если MutableList<Rectangle> был подтипом MutableList<Shape>, вы могли добавить в него других наследников Shape (например, Circle), таким образом нарушая изначальный тип коллекции - Rectangle.
- Для более специфичных случаев существуют функции
reduce()иfold(). Они последовательно применяют предоставленную операцию к элементам коллекции и возвращают накопленный результат. Операция принимает два аргумента: ранее накопленное значение и элемент коллекции.
Разница между этими двумя функциями состоит в том, что fold() принимает начальное значение и использует его как накопленное значение на первом шаге, тогда как reduce() на первом шаге в качестве аргументов операции использует первый и второй элементы коллекции.
fun main() {
val numbers = listOf(5, 2, 10, 4)
val simpleSum = numbers.reduce { sum, element -> sum + element }
println(simpleSum) // 21
val sumDoubled = numbers.fold(0) { sum, element -> sum + element * 2 }
println(sumDoubled) // 42
// некорректно: первый элемент не будет удвоен
// val sumDoubledReduce = numbers.reduce { sum, element -> sum + element * 2 }
// println(sumDoubledReduce)
}Чтобы сохранить промежуточное накопленное значение, существуют функции runningFold() и runningReduce().
fun main() {
val numbers = listOf(0, 1, 2, 3, 4, 5)
val runningReduceSum = numbers.runningReduce { sum, item -> sum + item }
val runningFoldSum = numbers.runningFold(10) { sum, item -> sum + item }
val transform = { index: Int, element: Int -> "N = ${index + 1}: $element" }
println(runningReduceSum.mapIndexed(transform).joinToString("\n", "Sum of first N elements with runningReduce:\n"))
println(runningFoldSum.mapIndexed(transform).joinToString("\n", "Sum of first N elements with runningFold:\n"))
}
// В логе будет:
// Sum of first N elements with runningReduce:
// N = 1: 0
// N = 2: 1
// N = 3: 3
// N = 4: 6
// N = 5: 10
// N = 6: 15
// Sum of first N elements with runningFold:
// N = 1: 10
// N = 2: 10
// N = 3: 11
// N = 4: 13
// N = 5: 16
// N = 6: 20
// N = 7: 25
Zipping(функций преобразования) - берёт два списка и создаёт из их элементов пары. При этом пары создаются из элементов с одинаковыми индексами. Функция-расширениеzip().- Если коллекции имеют разные размеры, то
zip()вернёт новую коллекцию, длина которой равняется минимальной из исходных коллекций; последние элементы бОльшей коллекции будут отсечены. - zip() можно вызывать в инфиксной форме
a zip b
fun main() {
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors zip animals) // [(red, fox), (brown, bear), (grey, wolf)]
val twoAnimals = listOf("fox", "bear")
println(colors.zip(twoAnimals)) // [(red, fox), (brown, bear)]
}- Также в
zip()можно передавать функцию преобразования вместе с коллекцией
fun main() {
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors.zip(animals) { color, animal -> "The ${animal.replaceFirstChar { it.uppercase() }} is $color" })
// [The Fox is red, The Bear is brown, The Wolf is grey]
}unzip()для "распаковки" списка типаList<Pair<K, V>>
fun main() {
val numberPairs = listOf("one" to 1, "two" to 2, "three" to 3, "four" to 4)
println(numberPairs.unzip()) // ([one, two, three, four], [1, 2, 3, 4])
}Также есть отдельная функция - zipWithNext() для создания диапазонов из двух элементов.
fun main() {
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.zipWithNext()) // [(one, two), (two, three), (three, four), (four, five)]
println(numbers.zipWithNext() {
s1, s2 -> s1.length > s2.length
}) // [false, false, true, false]
}Kotlin был создан с учетом функционального программирования и имеет несколько особенностей, которые способствуют использованию функционального стиля программирования:
-
Функции являются объектами первого класса. Это означает, что функции могут быть переданы в качестве аргументов, возвращены из других функций и хранены в переменных.
-
Неизменяемые переменные и коллекции. Kotlin поддерживает неизменяемые переменные и коллекции, что способствует функциональной работе с данными, так как она позволяет избежать побочных эффектов и сделать код более безопасным;
-
Функции-расширения. Kotlin позволяет определять функции-расширения, которые могут быть вызваны на объектах классов, даже если эти классы не были спроектированы с учетом функционального программирования. Это позволяет использовать функциональные паттерны в коде, который не был написан в функциональном стиле;
-
Встроенная поддержка лямбда-выражений. Kotlin поддерживает лямбда-выражения, что делает возможным использование функциональных паттернов, таких как функции высшего порядка и замыкания;
-
Опциональный тип — обобщенный (generic) тип, который представляет инкапсуляцию опционального значения. Такой тип содержит в себе либо определенное значение, либо пустое (null) значение.
-
Ленивое вычисление — стратегия вычисления, которая откладывает вычисления выражения до момента, когда значение этого выражения будет
-
Объекты-компаньоны. Kotlin позволяет определять объекты-компаньоны, которые могут использоваться для создания функциональных интерфейсов и решения других задач, связанных с функциональным программированием.
-
Inline-функции. Kotlin поддерживает inline-функции, которые могут уменьшить накладные расходы при вызове функций высшего порядка, так как они могут быть встроены в вызывающий код;
24. Какие конструкции в Kotlin позволяют работать с последовательностями (sequences) и какова их практическая польза?
Стандартная библиотека Kotlin помимо коллекций содержит еще один тип контейнера - последовательности (Sequence). Последовательности предлагают те же функции, что и Iterable, но реализуют другой подход к многоэтапной обработке коллекции.
Если обработка Iterable состоит из нескольких шагов, то они выполняются немедленно: при завершении обработки каждый шаг возвращает свой результат - промежуточную коллекцию. Следующий шаг выполняется для этой промежуточной коллекции. В свою очередь, многоступенчатая обработка последовательностей по возможности выполняется "лениво": фактически вычисления происходят только тогда, когда запрашивается результат выполнения всех шагов.
Порядок выполнения операций также различается: Sequence выполняет все шаги один за другим для каждого отдельного элемента. Тогда как Iterable завершает каждый шаг для всей коллекции, а затем переходит к следующему шагу.
Таким образом, последовательности позволяют избежать создания промежуточных результатов для каждого шага, тем самым повышая производительность всей цепочки вызовов. Однако "ленивый" характер последовательностей добавляет некоторые накладные расходы, которые могут быть значительными при обработке небольших коллекций или при выполнении более простых вычислений. Следовательно, вы должны рассмотреть, а затем самостоятельно решить, что вам подходит больше - Sequence или Iterable.
Чтобы создать последовательность, вызовите функцию sequenceOf() и передайте ей элементы в качестве аргументов.
val numbersSequence = sequenceOf("four", "three", "two", "one")Если у вас уже есть объект Iterable (например, List или Set), то вы можете создать из него последовательность, вызвав функцию asSequence()
val numbers = listOf("one", "two", "three", "four")
val numbersSequence = numbers.asSequence()Ещё один способ создать последовательность - использовать функцию, которая вычисляет элементы последовательности. Для этого вызовите generateSequence() и в качестве аргумента передайте ей эту функцию. При желании вы можете указать первый элемент как явное значение или результат вызова функции. Генерация последовательности останавливается, когда предоставленная функция возвращает null. Последовательность в приведённом ниже примере бесконечна.
fun main() {
val oddNumbers = generateSequence(1) { it + 2 } // `it` - это предыдущее значение
println(oddNumbers.take(5).toList()) // [1, 3, 5, 7, 9]
//println(oddNumbers.count()) // ошибка: последовательность бесконечна
}Для создания конечной последовательности передайте в generateSequence() такую функцию, которая после последнего нужного вам элемента вернёт null.
fun main() {
val oddNumbersLessThan10 = generateSequence(1) { if (it < 8) it + 2 else null }
println(oddNumbersLessThan10.count()) // 5
}Наконец, есть функция sequence(), которая позволяет создавать элементы последовательности один за другим или кусками (chunks) произвольного размера.
Эта функция принимает лямбда-выражение, содержащее вызовы функций yield() и yieldAll().
Они возвращают элемент потребителю последовательности и приостанавливают выполнение sequence() до тех пор, пока потребитель не запросит следующий элемент. Функция yield() принимает в качестве аргумента один элемент; yieldAll() может принимать объект Iterable, Iterator или другую Sequence. Аргумент Sequence, переданный в yieldAll(), может быть бесконечным. Однако такой вызов должен быть последним, иначе все последующие вызовы никогда не будут выполнены.
fun main() {
val oddNumbers = sequence {
yield(1)
yieldAll(listOf(3, 5))
yieldAll(generateSequence(7) { it + 2 })
}
println(oddNumbers.take(5).toList()) // [1, 3, 5, 7, 9]
}Операции с последовательностями можно разделить на следующие группы:
Stateless(без сохранения состояния) - операции, которым не требуется создавать промежуточное состояние. Они обрабатывают каждый элемент независимо, например, функцииmap()иfilter(). К этой же группе относятся операции, которым требуется создавать небольшое константное количество промежуточных состояний, например,take()илиdrop().Stateful(с отслеживанием состояния) - данным операциям требуется создавать большое количество промежуточных состояний, которое, как правило, пропорционально количеству элементов в последовательности.
Если операция возвращает другую последовательность, которая создаётся "лениво", то такая операция называется промежуточной (intermediate). В противном случае эта операция будет терминальной (terminal). Примеры терминальных операций: toList() или sum(). Элементы последовательности можно получить только с помощью терминальных операций.
Последовательности можно итерировать несколько раз; однако некоторые реализации последовательностей могут ограничивать итерацию до одного раза. Это специально упоминается в их документации.
Предположим, у вас есть список слов. Отфильтруем слова длиной более трёх символов и выведем на печать длину первых четырёх таких слов.
fun main() {
val words = "The quick brown fox jumps over the lazy dog".split(" ")
val lengthsList = words.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4) println("Lengths of first 4 words longer than 3 chars:")
println(lengthsList) // [5, 5, 5, 4]
}Попробуйте запустить этот код и увидите, что функции filter() и map() выполняются в том же порядке, в котором они появляются в коде. Сначала все слова фильтруются с помощью filter(), а затем для оставшихся слов вычисляется их длина с помощью map()
Визуально это выглядит следующим образом:

Теперь напишем такой же код, но с использованием последовательности:
fun main() {
val words = "The quick brown fox jumps over the lazy dog".split(" ")
//convert the List to a Sequence
val wordsSequence = words.asSequence()
val lengthsSequence = wordsSequence.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars")
// terminal operation: obtaining the result as a List
println(lengthsSequence.toList()) // [5, 5, 5, 4]
}Если вы запустите этот код, то увидите, что функции filter() и map() вызываются в момент обращения к списку. Сначала в лог будет выведена строка “Lengths of..” и только после неё начинается вычисление результата. Обратите внимание и на порядок вызова функций. Если элемент соответствует условию фильтра, то функция map(), не дожидаясь окончания фильтрации, вычисляет длину слова. Когда размер последовательности достигает 4, вычисление останавливается, потому что это максимально возможный размер, который может вернуть take(4).
Визуально это выглядит следующим образом:

В этом примере вычисление результата занимает 18 шагов, а в аналогичном примере с Iterable - 23 шага.
25. Как использовать функцию groupBy() для группировки элементов коллекции по определенному критерию?
Для группировки элементов коллекции в Kotlin есть функции-расширения.
Основная функция для группировки - groupBy(). Она принимает лямбда-функцию и возвращает Map. В этой Map каждый ключ — это результат вычисления лямбда-функции.
fun main() {
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.groupBy { it.first().uppercase() }) // {O=[one], T=[two, three], F=[four, five]}
println(numbers.groupBy( keySelector = { it.first() }, valueTransform = { it.uppercase() } ))
// {o=[ONE], t=[TWO, THREE], f=[FOUR, FIVE]}
}Функцию groupBy() можно использовать, например, для группировки списка, строк по их первой букве.
- Функцию
groupingBy()удобно использовать, если требуется сгруппировать элементы, а затем применить какую-либо операцию ко всем группам одновременно. (Она возвращает экземпляр типа Grouping. В свою очередь Grouping позволяет "лениво" применять операции ко всем группам: фактически группы будут создаваться прямо перед выполнением операции.)
Grouping поддерживает следующие функции:
- eachCount() - подсчитывает количество элементов в каждой группе.
- fold() и reduce() - выполняют операции fold и reduce для каждой группы как для отдельной коллекции, после чего возвращают результат.
- aggregate() - последовательно применяет данную операцию ко всем элементам в каждой группе, после чего возвращает результат.
fun main() {
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.groupingBy { it.first() }.eachCount()) // {o=1, t=2, f=2, s=1}
}26. Какие возможности предоставляются в Kotlin для работы с функциями-расширениями (extension functions)?
Аналогично таким языкам программирования, как C# и Gosu, Kotlin позволяет расширять класс путём добавления нового функционала. Это реализовано с помощью специальных выражений, называемых расширениями. Kotlin поддерживает функции расширения и свойства-расширения.
Для того, чтобы объявить функцию-расширение, нам нужно указать в качестве префикса расширяемый тип, то есть тип, который мы расширяем. Следующий пример добавляет функцию swap к MutableList.
fun MutableList.swap(index1: Int, index2: Int)
{
val tmp = this[index1]
this[index1] = this[index2]
this[index2] = tmp
}Ключевое слово this внутри функции-расширения соотносится с объектом расширяемого типа (этот тип ставится перед точкой). Теперь мы можем вызывать такую функцию в любом MutableList.
val l = mutableListOf(1, 2, 3)
l.swap(0, 2) // 'this' внутри 'swap()' будет содержать значение 'l'Аналогично функциям, Kotlin поддерживает расширения свойств.
val List.lastIndex: Int
get() = size – 1Если в классе есть и функция-член, и функция-расширение с тем же возвращаемым типом, таким же именем и применяется с такими же аргументами, то функция-член имеет более высокий приоритет.
Однако, для функций-расширений совершенно нормально перегружать функции члены, которые имеют такое же имя, но другую сигнатуру.
Расширения могут быть объявлены для
null-допустимых типов. Такие расширения могут ссылаться на переменные объекта, даже если значение переменной равноnull. В таком случае есть возможность провести проверкуthis == nullвнутри тела функции.
27. Как использовать функцию takeWhile() для выбора элементов коллекции до тех пор, пока выполняется определенное условие?
Функции-расширения в Kotlin предоставляют множество способов выбора элементов: явное перечисление их позиций, указание размера, результата и пр.
- Для получения определённого количества элементов, находящихся в начале коллекции применяется функция
take(). (ПротивоположноtakeLast()).
fun main() {
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.take(3))
// [one, two, three]
println(numbers.takeLast(3))
// [four, five, six]
}takeWhile()- это аналог функции take(): возвращает первые элементы, соответствующие заданному предикату. Элементы отбираются с начала коллекции и до тех пор, пока не встретится элемент, несоответствующий предикату. Если первый элемент коллекции не соответствует предикату, то результат будет пустым.takeLastWhile()- это аналог функции takeLast().
fun main() {
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.takeWhile { !it.startsWith('f') })
// [one, two, three]
println(numbers.takeLastWhile { it != "three" })
// [four, five, six]
}Стандартная библиотека Kotlin предоставляет несколько полезных видов делегатов:
- Ленивые свойства
(lazy properties) Observableсвойства
lazy() это функция, которая принимает лямбду и возвращает экземпляр класса Lazy, который служит делегатом для реализации ленивого свойства: первый вызов get() запускает лямбда выражение, переданное lazy() в качестве аргумента, и запоминает полученное значение, а последующие вызовы просто возвращают вычисленное значение.
val lazyValue: String by lazy {
println("computed!")
"Hello"
}
fun main(args: Array<String>) {
println(lazyValue)
println(lazyValue)
}Вывод:
computed!
Hello
Hello
29. Что такое карта (map) в функциональном программировании и как ее можно использовать для преобразования значений?
Map (словарь, ассоциативный список)- набор из пар "ключ-значение". Ключи уникальны и каждый из них соответствует ровно одному значению. Значения могут иметь дубликаты. Ассоциативные списки полезны для хранения логических связей между объектами, например, ID сотрудников и их должностей.
Map<K, V> не является наследником интерфейса Collection; однако это один из типов коллекций в Kotlin. Map хранит пары "ключ-значение" (или entries); ключи уникальны, но разные ключи могут иметь одинаковые значения. Интерфейс Mapпредоставляет такие функции, как доступ к значению по ключу, поиск ключей и значений и т. д.
fun main() {
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key4" to 1)
println("All keys: ${numbersMap.keys}") // [key1, key2, key3, key4]
println("All values: ${numbersMap.values}") // [1, 2, 3, 1]
if ("key2" in numbersMap)
println("Value by key \"key2\": ${numbersMap["key2"]}")
if (1 in numbersMap.values)
println("The value 1 is in the map")
if (numbersMap.containsValue(1))
println("The value 1 is in the map") // аналогичен предыдущему условию
}Две Map-ы, содержащие равные пары, равны независимо от порядка пар.
MutableMap - это Map с операциями записи, например, можно добавить новую пару "ключ-значение" или обновить значение, связанное с указанным ключом.
fun main() {
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
numbersMap.put("three", 3)
numbersMap["one"] = 11
println(numbersMap) // {one=11, two=2, three=3}
}По умолчанию реализацией Map является LinkedHashMap - сохраняет порядок элементов. Альтернативная реализация - HashMap - не сохраняет порядок элементов.
Неизменяемые типы коллекций
ковариантны. Это означает, что если класс Rectangle наследуется от Shape, вы можете использоватьList<Rectangle>там, где требуетсяList<Shape>. Другими словами, типы коллекций имеют такое же отношение подтипов, что и типы элементов. Map-ы ковариантны по типу значения, но не по типу ключа.
В свою очередь, изменяемые коллекции
не являются ковариантными; в противном случае это привело бы к сбоям во время выполнения. ЕслиMutableList<Rectangle>был подтипомMutableList<Shape>, вы могли добавить в него других наследников Shape (например, Circle), таким образом нарушая изначальный тип коллекции - Rectangle.
Один из самых частых сценариев использования делегированных свойств заключается в хранении свойств в ассоциативном списке. Это полезно в "динамическом" коде, например, при работе с JSON:
class User(val map: Map<String, Any?>) {
val name: String by map
val age: Int by map
}В этом примере конструктор принимает ассоциативный список
val user = User(mapOf( "name" to "John Doe", "age" to 25 ))Делегированные свойства берут значения из этого ассоциативного списка (по строковым ключам)
println(user.name) // Prints "John Doe"
println(user.age) // Prints 25
Также, если вы используете MutableMap вместо Map, поддерживаются изменяемые свойства (var):
class MutableUser(val map: MutableMap<String, Any?>) {
var name: String by map
var age: Int by map
}30. Какие есть ограничения или потенциальные проблемы, с которыми сталкиваются при использовании функционального программирования на языке Kotlin?
- Использование функций высшего порядка влечёт за собой снижение производительности: во-первых, функция является объектом, а во-вторых, происходит захват контекста замыканием, то есть функции становятся доступны переменные, объявленные вне её тела. А выделения памяти (как для объекта функции, так и для её класса) и виртуальные вызовы занимают системные ресурсы.
- Как правило, лямбда-выражения компилируются в анонимные классы. То есть каждый раз, когда
используется лямбда-выражение, создаётся дополнительный класс. Отсюда вытекают дополнительные накладные расходы у функций, которые принимают лямбду в качестве аргумента. Если же функцию отметить модификатором
inline, то компилятор не будет создавать анонимные классы и их объекты для каждого лямбда-выражения, а просто вставит код её реализации в место вызова. Или другими словами встроит её.
Чтобы заставить компилятор поступить именно так, нам необходимо отметить функцию lock модификатором inline.
inline fun lock(lock: Lock, body: () -> T): T { // ... }Модификатор inline влияет и на функцию, и на лямбду, переданную ей: они обе будут встроены в место вызова.
Изменяемость: Kotlin позволяет изменять состояние объектов, что может привести к неожиданным побочным эффектам при использовании функционального программирования. Это может быть особенно проблематично при работе с параллельными вычислениями, где доступ к изменяемым данным может привести к состоянию гонки.
Проблемы с производительностью: функциональный подход может быть менее эффективным, чем императивный подход, особенно при работе с большими объемами данных, из-за большого количества объектов, создаваемых в процессе выполнения функциональных операций.
Одной из наиболее распространенных операций в современных приложениях является ввод/вывод (I/O). КИз-за непредсказуемого характера задач ввода-вывода они, скорее всего, не являются чистыми, то есть как ввод, так и вывод не являются детерминированными.
-
Неизменяемость (Immutability): Данные в функциональном программировании являются неизменяемыми, то есть после создания их нельзя изменить. Вместо этого создаются новые данные путем применения функций. -
Чистые функции (Pure Functions): Функции в функциональном программировании должны быть чистыми, то есть не должны иметь побочных эффектов и всегда возвращать одинаковый результат для одинаковых параметров. -
Функции высшего порядка (Higher-Order Functions): Функции могут принимать другие функции в качестве аргументов и возвращать функции в качестве результата. -
Рекурсия (Recursion): Рекурсия является основным способом итерации в функциональном программировании. -
Каррирование (Currying): Каррирование - это процесс преобразования функции, которая принимает несколько аргументов, в последовательность функций, каждая из которых принимает только один аргумент. -
Анонимные функции (Anonymous Functions): Анонимные функции позволяют создавать функции на лету и передавать их в качестве аргументов другим функциям. -
Ленивые вычисления (Lazy Evaluation): Ленивые вычисления позволяют откладывать вычисления до тех пор, пока они не понадобятся, что может уменьшить потребление памяти и повысить производительность программы.
-
В общем смысле,
неизменяемость(non-mutability) означает, что объект не может быть изменен после создания, то есть его состояние остается неизменным. Это означает, что любые операции с объектом создают новый объект, а не изменяют существующий. В языках программирования, где нет прямой поддержки неизменяемости, это может быть достигнуто путем создания копии объекта, изменение которого не повлияет на оригинал. -
С другой стороны,
иммутабельность(immutability) означает, что объект не может быть изменен вообще, даже путем создания копии объекта. В языках программирования, где поддерживается иммутабельность, создание копии объекта, который может быть изменен, не является возможным.
33. Какие функции Kotlin позволяют создавать список (List) из элементов и применять операции к нему?
listOf()- создает неизменяемый список из переданных элементов.
val list = listOf("apple", "banana", "orange")
val emptySet = mutableSetOf<String>() // тип пустой коллекцию необходимо указывать явно
// Получение элемента списка по индексу
val firstElement = list[0] // "apple"
val firstElementGet = list.get(0) // "apple"
// Получение индекса по элементу списка
val indexGet = list.indexOf("apple") // 1
// Фильтрация списка по условию
val filteredList = list.filter { it.startsWith("a") } // ["apple"]
// Применение функции к каждому элементу списка и получение нового списка
val mappedList = list.map { it.capitalize() } // ["Apple", "Banana", "Orange"]mutableListOf()- создает изменяемый список из переданных элементов:
val mutableList = mutableListOf("apple", "banana", "orange")
// Добавление нового элемента в список
mutableList.add("grape")
// Удаление элемента из списка
mutableList.remove("banana") //по индексу removeAt(2)
// Сортировка списка
mutableList.sort() // ["apple", "grape", "orange"]arrayListOf()- создает изменяемый список на основе массива:
val arrayList = arrayListOf("apple", "banana", "orange")
// Получение подсписка из списка
val subList = arrayList.subList(0, 2) // ["apple", "banana"]
// Преобразование списка в массив
val array = arrayList.toTypedArray() // ["apple", "banana", "orange"]listOfNotNull()- создает список из переданных элементов, исключая все null-элементы.
val list = listOfNotNull("apple", null, "banana", null, "orange")
// Получение количества элементов в списке
val size = list.size // 3
// Проверка наличия элемента в списке
val containsBanana = list.contains("banana") // trueemptyList(). При создании пустой коллекции вы должны явно указывать тип элементов, которые будет содержать коллекция.
val empty = emptyList<String>()- Чтобы создать коллекцию конкретного типа, например,
ArrayListилиLinkedList, вы можете использовать их конструкторы. .
val linkedList = LinkedList<String>(listOf("one", "two", "three"))
val presizedSet = HashSet<Int>(32)- flatten()` - функция возвращает объединённый List, состоящий из всех элементов всех вложенных коллекций. (Её можно использовать для коллекции, содержащей другие коллекции)
fun main() {
val numberSets = listOf(setOf(1, 2, 3), setOf(4, 5, 6), setOf(1, 2))
println(numberSets.flatten()) // [1, 2, 3, 4, 5, 6, 1, 2]
}flatMap() - обеспечивает гибкий способ работы с вложенными коллекциями. Она принимает функцию, которая маппит элемент исходной коллекции в другую коллекцию. В качестве результата flatMap() возвращает объединённый список из всех обработанных элементов. По сути flatMap() ведёт себя как вызов map() (с возвращением коллекции в качестве результата маппинга) и flatten().
data class StringContainer(val values: List<String>)
fun main() {
val containers = listOf( StringContainer(listOf("one", "two", "three")), StringContainer(listOf("four",
"five", "six")), StringContainer(listOf("seven", "eight")) )
println(containers.flatMap { it.values }) // [one, two, three, four, five, six, seven, eight]
}+(plus) и-(minus). Они позволяют объединять и удалять элементы из коллекций. Первый операнд должен быть коллекцией, а второй - элементом или другой коллекцией.
- Результат использования оператора plus: элементы исходной коллекции и элементы второго операнда.
- Результат использования оператора minus: элементы исходной коллекции за исключением элементов второго операнда.
fun main() {
val numbers = listOf("one", "two", "three", "four")
val plusList = numbers + "five"
val minusList = numbers - listOf("three", "four")
println(plusList) // [one, two, three, four, five]
println(minusList) // [one, two]
}OR
val list1 = listOf("apple", "banana", "orange")
val list2 = listOf("grape", "pear")
val combinedList = list1.plus(list2) // ["apple", "banana", "orange", "grape", "pear"]- Также есть расширенные операторы
plusAssign(+=) иminusAssign(-=). (С неизменяемыми коллекциями они фактически используют операторы plus или minus)
- (Операции для SET).
union()- создает новую коллекцию, которая содержит все уникальные элементы из обеих коллекций. В инфиксной форме -a union b( SET).
val set1 = setOf(1, 2, 3)
val set2 = setOf(3, 4, 5)
val unionSet = set1.union(set2) // [1, 2, 3, 4, 5]- Чтобы найти пересечения между двумя коллекциями , используйте функцию
intersect(). - И наоборот, для поиска элементов, отсутствующих в другой коллекции, используйте
subtract(). - В инфиксной форме,
a intersect b.
fun main() {
val numbers = setOf("one", "two", "three")
println(numbers union setOf("four", "five")) // [one, two, three, four, five]
println(setOf("four", "five") union numbers) // [four, five, one, two, three]
println(numbers intersect setOf("two", "one")) // [one, two]
println(numbers subtract setOf("three", "four")) // [one, two]
println(numbers subtract setOf("four", "three")) // [one, two]
}zip()- создает новую коллекцию из элементов двух коллекций с соответствующими индексами.
val list1 = listOf("apple", "banana", "orange")
val list2 = listOf(1, 2, 3)
val zippedList = list1.zip(list2) // [("apple", 1), ("banana", 2), ("orange", 3)]addAll()- добавляет все элементы второй коллекции в первую коллекцию.
val mutableList1 = mutableListOf("apple", "banana", "orange")
val list2 = listOf("grape", "pear")
mutableList1.addAll(list2) // mutableList1 = ["apple", "banana", "orange", "grape", "pear"]Nullable значение - это значение, которое может содержать значение типа или null.
Для работы с такими значениями в Kotlin используются специальные операторы и функции.
- Оператор
?.(безопасный вызов) позволяет вызывать методы или обращаться к свойствам nullable объекта, не беспокоясь о том, что объект равен null. Если объект равен null, то результатом будет null.
val str: String? = null
val length = str?.length // null- Также в Kotlin есть оператор
?:(элвис-оператор), который позволяет вернуть значение по умолчанию, если nullable значение равно null.
val str1: String? = null
val str2 = str1 ?: "default value" // "default value"- Так как
throwиreturnтоже являются выражениями в Kotlin, их также можно использовать справа от Элвис-оператора. Это может быть крайне полезным для проверки аргументов функции:
fun foo(node: Node): String? {
val parent = node.getParent() ?: return null
val name = node.getName() ?: throw IllegalArgumentException("name expected")
// ...
}- Функция
letпозволяет выполнить блок кода, только если nullable значение не равно null. Это позволяет избежать NullPointerException.
val str: String? = "Hello"
str?.let { println(it) } // "Hello"- Функция
runпозволяет выполнить блок кода на nullable объекте и вернуть результат. Если объект равен null, то результатом будет null.
val str: String? = "Hello"
val result = str?.run { this.length } // 5- Функция
filterNotNullпозволяет отфильтровать nullable элементы из коллекции и вернуть коллекцию, содержащую только не-null элементы.
val list = listOf("apple", null, "banana", null, "orange")
val filteredList = list.filterNotNull() // ["apple", "banana", "orange"]sorted()- создает новую коллекцию, отсортированную по возрастанию элементов.
val list = listOf(3, 2, 1)
val sortedList = list.sorted() // [1, 2, 3]
sortedDescending()- создает новую коллекцию, отсортированную по убыванию элементов.
val list = listOf(1, 2, 3)
val sortedList = list.sortedDescending() // [3, 2, 1]sortedBy()- создает новую коллекцию, отсортированную по результату функции, примененной к каждому элементу коллекции.
val list = listOf("apple", "banana", "orange")
val sortedList = list.sortedBy { it.length } // ["apple", "orange", "banana"]sortedByDescending()- создает новую коллекцию, отсортированную по результату функции в обратном порядке.
val mutableList = mutableListOf("apple", "banana", "orange")
mutableList.sortByDescending { it.length } // mutableList = ["banana", "orange", "apple"]sortWith()- создает новую коллекцию, отсортированную с помощью заданного компаратора.
val list = listOf("apple", "banana", "orange")
val sortedList = list.sortedWith(compareBy { it.length }) // ["apple", "orange", "banana"]fun main() {
val lengthComparator = Comparator { str1: String, str2: String -> str1.length - str2.length }
println(listOf("aaa", "bb", "c").sortedWith(lengthComparator))
// [c, bb, aaa]
}sort()- сортирует саму коллекцию (не копия) в том же порядке с помощью естественного порядка элементов.
val mutableList = mutableListOf("apple", "banana", "orange")
mutableList.sort() // mutableList = ["apple", "banana", "orange"]setOf()- создает неизменяемое множество, содержащее указанные элементы.
val set = setOf("apple", "banana", "orange")mutableSetOf()- создает изменяемое множество, содержащее указанные элементы.
val mutableSet = mutableSetOf("apple", "banana", "orange")Интерфейс MutableSet реализуется следующими типами изменяемых наборов:
LinkedHashSet: объединяет возможности хеш-таблицы и связанного списка. Создается с помощью функцииlinkedSetOf().HashSet: представляет хеш-таблицу. Создается с помощью функцииhashSetOf().
val numbers1: HashSet<Int> = hashSetOf(5, 6, 7)
val numbers2: LinkedHashSet<Int> = linkedSetOf(25, 26, 27)
val numbers3: MutableSet<Int> = mutableSetOf(35, 36, 37)По умолчанию реализацией Set является LinkedHashSet, который сохраняет порядок вставки элементов. Следовательно, функции, которые зависят от порядка элементов, такие как first() или last(), возвращают предсказуемые результаты для таких множеств.
Альтернативная реализация - HashSet - не сохраняет порядок элементов, поэтому при вызове функций first() или last() вернётся непредсказуемый результат. Однако HashSet требует меньше памяти для хранения того же количества элементов.
-
emptySet(). При создании пустой коллекции вы должны явно указывать тип элементов, которые будет содержать коллекция. -
Функции копирования коллекций, такие как
toSet()
add()- добавляет элемент в изменяемое множество.addAll()- добавляет все элементы коллекции в изменяемое множество.
val mutableSet = mutableSetOf("apple", "banana", "orange")
mutableSet.addAll(listOf("grape", "pear"))contains()- проверяет, содержит ли множество указанный элемент.
val set = setOf("apple", "banana", "orange")
val containsApple = set.contains("apple") // trueremove()- удаляет элемент из изменяемого множества.union()- создает новую коллекцию, которая содержит все уникальные элементы из обеих коллекций. В инфиксной форме -a union b( SET).
val set1 = setOf(1, 2, 3)
val set2 = setOf(3, 4, 5)
val unionSet = set1.union(set2) // [1, 2, 3, 4, 5]intersect()- создает новое множество, содержащее только те элементы, которые присутствуют и в первом, и во втором множестве.
val set1 = setOf("apple", "banana", "orange")
val set2 = setOf("orange", "grape", "pear")
val intersection = set1.intersect(set2) // ["orange"]subtract()- создает новое множество, содержащее только те элементы, которые есть в первом множестве, но отсутствуют во втором множестве.
val set1 = setOf("apple", "banana", "orange")
val set2 = setOf("orange", "grape", "pear")
val difference = set1.subtract(set2) // ["apple", "banana"]map()- возвращает новую коллекцию, содержащую результат применения указанного преобразования к каждому элементу исходной коллекции.
fun main() {
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 }) // [3, 6, 9]
println(numbers.mapIndexed { idx, value -> value * idx }) // [0, 2, 6]
}zip()принимает другую коллекцию и лямбда-выражение, которое преобразует пару элементов в новый тип данных, и возвращает список из результатов преобразования.
val names = listOf("Alice", "Bob", "Charlie")
val ages = listOf(25, 30, 35)
val nameAgePairs = names.zip(ages) { name, age -> "$name is $age years old" }flatten()- это еще одна функция коллекций в Kotlin, которая позволяет преобразовывать элементы коллекции в другой тип данных. Она "выравнивает" вложенные коллекции, преобразуя их в одну плоскую коллекцию.
val nestedList = listOf(listOf(1, 2), listOf(3, 4), listOf(5, 6))
val flatList = nestedList.flatten()associate()- создает новый словарь (Map), используя элементы исходной коллекции в качестве ключей и результаты применения указанного преобразования к каждому элементу в качестве значений. Она принимает lambda-выражение, которое определяет, какой ключ и значение должны быть сопоставлены с каждым элементом коллекции.
val names = listOf("Alice", "Bob", "Charlie")
val nameLengths = names.associate { name -> name to name.length }- Функции
joinToString()иjoinTo()- это функции коллекций в Kotlin, которые позволяют объединить элементы коллекции в одну строку с заданным разделителем и префиксом/суффиксом.
separator- разделитель между элементами коллекции (по умолчанию - запятая);prefix- префикс строки (по умолчанию - пустая строка);postfix- суффикс строки (по умолчанию - пустая строка);limit- максимальное количество элементов, которое будет включено в строку (по умолчанию - все элементы);
val numbers = listOf(1, 2, 3, 4, 5)
val string = numbers.joinToString(separator = ", ", prefix = "[", postfix = "]") { it.toString() }- Для группировки элементов коллекции в Kotlin есть функции-расширения. Основная функция для группировки -
groupBy(). Она принимает лямбда-функцию и возвращает Map. В этой Map каждый ключ — это результат вычисления лямбда-функции.
fun main() {
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.groupBy { it.first().uppercase() }) // {O=[one], T=[two, three], F=[four, five]}
println(numbers.groupBy( keySelector = { it.first() }, valueTransform = { it.uppercase() } ))
// {o=[ONE], t=[TWO, THREE], f=[FOUR, FIVE]}
}Функциональный интерфейс - это интерфейс, который содержит только один абстрактный метод.
Функциональный интерфейсможет иметь несколько неабстрактных членов, но только один абстрактный.- Может использоваться в качестве функционального типа.
- То есть вместо объявления отдельной функции, мы можем использовать экземпляр функционального интерфейса.
Пример:
interface MyFunction {
fun invoke(arg: Int): String
}В этом примере MyFunction - функциональный интерфейс, потому что содержит только один абстрактный метод invoke(). Этот метод принимает целочисленный аргумент и возвращает строку.
Функциональные интерфейсытакже могут реализовывать и расширять другие интерфейсы.Функциональные интерфейсыболее гибкие и предоставляют больше возможностей, чем псевдонимы типов, но они могут быть более дорогостоящими как синтаксически, так и во время выполнения, поскольку могут потребовать преобразования в определенный интерфейс.
reduce()принимает лямбда-выражение и последовательно применяет его к элементам коллекции, начиная с первых двух элементов, а затем используя результат для последующих элементов. В итоге, функция возвращает одно значение, которое является результатом последнего применения лямбда-выражения.
val numbers = listOf(1, 2, 3, 4, 5)
val sum = numbers.reduce { acc, n -> acc + n } // 15В этом примере, функция reduce() последовательно складывает элементы списка numbers и возвращает их сумму.
fold()работает аналогично функцииreduce(), но имеет начальное значение, которое передается в качестве первого аргумента. Это позволяет более точно определить результат, если коллекция пуста.
val numbers = listOf(1, 2, 3, 4, 5)
val sum = numbers.fold(0) { acc, n -> acc + n } // 15В этом примере, функция fold() начинает со значения 0 и затем последовательно складывает элементы списка numbers, возвращая их сумму.
joinToString()объединяет элементы коллекции в одну строку с заданным разделителем, префиксом и суффиксом.
val numbers = listOf(1, 2, 3, 4, 5)
val string = numbers.joinToString(separator = ", ", prefix = "[", postfix = "]") // "[1, 2, 3, 4, 5]"sum()возвращает сумму всех элементов коллекции.
val numbers = listOf(1, 2, 3, 4, 5)
val sum = numbers.sum() // 15average()возвращает среднее значение всех элементов коллекции.
val numbers = listOf(1, 2, 3, 4, 5)
val average = numbers.average() // 3.0min()иmax()возвращают минимальный и максимальный элементы коллекции соответственно.
val numbers = listOf(1, 2, 3, 4, 5)
val min = numbers.min() // 1
val max = numbers.max() // 541. Что такое частичное применение функций (partial function application) и как его реализовать в Kotlin?
Частичное применение функций (partial function application) - это техника функционального программирования, которая позволяет создавать новые функции путем фиксирования некоторых аргументов исходной функции. Это означает, что мы можем создавать новую функцию, которая является частично примененной версией исходной функции, и которая уже имеет некоторые аргументы, заданные заранее.
- Или, если своими словами:
частичное применение функциипозволяет создавать новую функцию, которая является измененной версией исходной функции, но уже имеет заранее определенные значения для некоторых из аргументов. Частичное применение функцийможно реализовать с помощью лямбда-выражений и функций высшего порядка.
fun multiply(x: Int, y: Int) = x * y
val multiplyByTwo = { y: Int -> multiply(2, y) }
val result = multiplyByTwo(5) // 10В этом примере, мы объявляем функцию multiply(), которая умножает два целых числа. Затем мы создаем новую функцию multiplyByTwo, которая является частично примененной версией функции multiply(), где первый аргумент равен 2.
- Это достигается за счет создания лямбда-выражения, которое принимает только второй аргумент
y, а первый аргумент уже задан заранее. Затем мы вызываем функциюmultiplyByTwo()с аргументом5, и получаем результат10.
Кроме того, в Kotlin можно использовать функции-расширения для создания новых функций на основе существующих. Например, если у нас есть функция f(x: Int, y: Int), то мы можем создать новую функцию g(x: Int), которая будет вызывать f(x, y) с фиксированным значением y, следующим образом:
fun ((Int, Int) -> Int).partial(x: Int): (Int) -> Int {
return { y -> this(x, y) }
}
val f = { x: Int, y: Int -> x + y }
val g = f.partial(1) // фиксируем x = 1
println(g(2)) // 3
println(g(3)) // 4Здесь мы определили функцию-расширение partial, которая принимает функцию двух аргументов и фиксирует первый аргумент. Затем мы вызываем f.partial(1), чтобы создать новую функцию g, которая будет вызывать f(1, y). Мы можем вызывать g с разными значениями y и получать результаты.
- Также мы можем дополнительно импортировать библиотеку Arrow-kt, которая предоставляет несколько функций для работы с частичным применением функций, таких как
partially1(),partially2()
import arrow.syntax.function.partially1
fun multiply(x: Int, y: Int) = x * y
val multiplyByTwo = ::multiply.partially1(2)
val result = multiplyByTwo(5) // 10partially1() для создания частично примененной функции multiplyByTwo.
42. Какие методы доступны для работы с коллекциями в Kotlin, которые позволяют применять функции к элементам коллекции?
Mapping: Первая из самых основных функций - map(): Она позволяет преобразовать исходную коллекцию путём применения заданной лямбда-функции к каждому её элементу, объединяя результаты в новую коллекцию. При этом порядок элементов сохраняется.- Если для преобразования коллекции нужно знать индекс элементов, то используйте функцию mapIndexed().
fun main() {
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 }) // [3, 6, 9]
println(numbers.mapIndexed { idx, value -> value * idx }) // [0, 2, 6]
}- Если какой-либо элемент или элементы могут быть преобразованы в значение равное null, то вместо
map()можно использовать функциюmapNotNull(), которая отфильтрует такие элементы и они не попадут в новую коллекцию. Соответственно, вместоmapIndexed()можно использоватьmapIndexedNotNull().
fun main() {
val numbers = setOf(1, 2, 3)
println(numbers.mapNotNull { if ( it == 2) null else it * 3 }) // [3, 9]
println(numbers.mapIndexedNotNull { idx, value -> if (idx == 0) null else value * idx }) // [2, 6]
}- Также можно преобразовывать ассоциативные списки двумя способами: преобразовывать ключи, не изменяя значения, и наоборот (mapKeys() и mapValues()). Они обе используют функцию преобразования, которая в качестве аргумента принимает пару "ключ-значение".
fun main() {
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
println(numbersMap.mapKeys { it.key.uppercase() }) // {KEY1=1, KEY2=2, KEY3=3, KEY11=11}
println(numbersMap.mapValues { it.value + it.key.length }) // {key1=5, key2=6, key3=7, key11=16}
}Zipping(функций преобразования) - берёт два списка и создаёт из их элементов пары. При этом пары создаются из элементов с одинаковыми индексами. Функция-расширениеzip().- zip() можно вызывать в инфиксной форме
a zip b
fun main() {
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors zip animals) // [(red, fox), (brown, bear), (grey, wolf)]
val twoAnimals = listOf("fox", "bear")
println(colors.zip(twoAnimals)) // [(red, fox), (brown, bear)]
}- Также в zip() можно передавать функцию преобразования вместе с коллекцией
fun main() {
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors.zip(animals) { color, animal -> "The ${animal.replaceFirstChar { it.uppercase() }} is $color" })
// [The Fox is red, The Bear is brown, The Wolf is grey]
}unzip()для "распаковки" списка типаList<Pair<K, V>>
fun main() {
val numberPairs = listOf("one" to 1, "two" to 2, "three" to 3, "four" to 4)
println(numberPairs.unzip()) // ([one, two, three, four], [1, 2, 3, 4])
}flatten()- функция возвращает объединённый List, состоящий из всех элементов всех вложенных коллекций. (Её можно использовать для коллекции, содержащей другие коллекции)
fun main() {
val numberSets = listOf(setOf(1, 2, 3), setOf(4, 5, 6), setOf(1, 2))
println(numberSets.flatten()) // [1, 2, 3, 4, 5, 6, 1, 2]
}flatMap()- обеспечивает гибкий способ работы с вложенными коллекциями. Она принимает функцию, которая маппит элемент исходной коллекции в другую коллекцию.
data class StringContainer(val values: List<String>)
fun main() {
val containers = listOf( StringContainer(listOf("one", "two", "three")), StringContainer(listOf("four",
"five", "six")), StringContainer(listOf("seven", "eight")) )
println(containers.flatMap { it.values }) // [one, two, three, four, five, six, seven, eight]
}forEach: выполняет заданную функцию для каждого элемента коллекции.
val numbers = listOf(1, 2, 3, 4, 5)
numbers.forEach { println(it) } // выводит каждый элемент коллекции на консольДля группировки элементов коллекции в Kotlin есть функции-расширения. Основная функция для группировки - groupBy(). Она принимает лямбда-функцию и возвращает Map. В этой Map каждый ключ — это результат вычисления лямбда-функции.
fun main() {
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.groupBy { it.first().uppercase() }) // {O=[one], T=[two, three], F=[four, five]}
println(numbers.groupBy( keySelector = { it.first() }, valueTransform = { it.uppercase() } ))
// {o=[ONE], t=[TWO, THREE], f=[FOUR, FIVE]}
}Некоторые функции в качестве параметра принимают целевой объект - destination. Он представляет собой изменяемую коллекцию, в которую функция добавляет результаты своих вычислений, вместо того, чтобы самостоятельно создавать новый объект. Названия таких функций можно отличить по постфиксу To.
В Kotlin замыкания closures используются автоматически, когда функция ссылается на переменные, определенные во внешней области видимости. Это значит, что функция в Kotlin может свободно ссылаться на любые переменные, которые были определены во внешней области видимости, и эти переменные будут автоматически захвачены замыканием closures.
Функции Kotlin могут использовать замыкания (closures) для захвата переменных из внешней области видимости и использования их внутри функции. Замыкание - это функция, которая запоминает значение переменных из своей внешней области видимости, даже если эти переменные уже вышли из области видимости.
fun main() {
var counter = 0
val incrementCounter = {
counter += 1
}
incrementCounter()
incrementCounter()
incrementCounter()
incrementCounter()
incrementCounter()
println(counter) //5
}Лямбда incrementCounter довольно простая: она увеличивает переменную counter на одну единицу. Переменная counter определяется вне лямбды. Лямбда может получить доступ к переменной, потому что лямбда определена в той же области, что и переменная. В таком случае, лямбда захватывает переменную counter. Любые изменения, которые вносятся в переменную, видны как внутри лямбды, так и за её пределами.
Допустим, вы вызываете лямбду пять раз следующим образом. После данных пяти вызовов — переменная counter будет равна 5.
Тот факт, что лямбда может использоваться для захвата переменных из замыкающей области видимости может быть очень полезен. К примеру, вы можете написать следующую функцию:
fun countingLambda(): () -> Int {
var counter = 0
val incrementCounter: () -> Int = {
counter += 1
counter
}
return incrementCounter
}
fun main() {
val counter1 = countingLambda()
val counter2 = countingLambda()
println(counter1()) // > 1
println(counter2()) // > 1
println(counter1()) // > 2
println(counter1()) // > 3
println(counter2()) // > 2
}Данная функция не принимает параметров и возвращает лямбду. Возвращаемая лямбда не принимает параметров и возвращает Int.
Лямбда, возвращаемая данной функцией, будет увеличивать counter при каждом вызове. Каждый раз при вызове функции будет получен новый экземпляр счетчика counter.
Два экземпляра элемента counter, созданные функцией, являются взаимно исключающими и считаются независимо друг от друга — так как имеют разные области видимости.
- Предположим, у нас есть функция
counter(), которая возвращает функцию, считающую количество раз, которое она была вызвана:
fun counter(): () -> Int {
var count = 0
return { ++count }
}- Здесь мы создаем переменную
countвнутри функцииcounter()и возвращаем лямбда-выражение, которое увеличивает значение переменнойcountи возвращает его новое значение при каждом вызове.
val countr = counter()
println(countr()) // 1
println(countr()) // 2
println(countr()) // 3- Мы вызываем эту функцию три раза, используя переменную
count, и каждый раз она возвращает увеличенное значение счетчика.
Заметьте, что значение переменной count сохраняется между вызовами функции count(), потому что она определена во внешней области видимости лямбда-выражения, возвращаемого функцией counter(). Это и есть замыкание в действии. Функция count() ссылается на переменную count, определенную во внешней области видимости, и может использовать ее значение при каждом вызове.
compose()позволяет композировать две функции в одну, так что результат выполнения одной функции становится входными данными для другой функции:
fun addTwo(x: Int) = x + 2
fun multiplyByThree(x: Int) = x * 3
val addTwoAndMultiplyByThree = ::multiplyByThree.compose(::addTwo)
println(addTwoAndMultiplyByThree(4)) // 18- Здесь мы использовали функцию
compose(), чтобы создать новую функциюaddTwoAndMultiplyByThree, которая сначала применяет функциюaddTwo(), а затем функциюmultiplyByThree(). Результат выполнения функцииaddTwoAndMultiplyByThree(4)равен18.
andThen()работает аналогично функцииcompose(), но в обратном порядке: сначала применяется первая функция, затем вторая:
fun addTwo(x: Int) = x + 2
fun multiplyByThree(x: Int) = x * 3
val multiplyByThreeAndAddTwo = ::multiplyByThree.andThen(::addTwo)
println(multiplyByThreeAndAddTwo(4)) // 14- Здесь мы использовали функцию
andThen(), чтобы создать новую функциюmultiplyByThreeAndAddTwo, которая сначала применяет функциюmultiplyByThree(), а затем функциюaddTwo(). Результат выполнения функцииmultiplyByThreeAndAddTwo(4)равен14.
let()принимает объект и функцию, которая принимает этот объект в качестве аргумента, и возвращает результат выполнения этой функции:
val x = 5
val result = x.let { it * 2 }
println(result) // 10- Здесь мы использовали функцию
let(), чтобы умножить переменнуюxна 2, используя лямбда-выражение{ it * 2 }. Результат сохраняется в переменнуюresult.
run()работает аналогично функцииlet(), но возвращает сам объект:
val x = 5
val result = x.run { this * 2 }
println(result) // 10Сопоставление с образцом (pattern matching) - это механизм, который позволяет проверять, соответствует ли значение некоторому шаблону (образцу) и выполнять соответствующие действия в зависимости от соответствия. Эта техника используется для упрощения кода, улучшения его читаемости и уменьшения количества ошибок.
- В Kotlin сопоставление с образцом осуществляется с помощью ключевого слова
when. Конструкцияwhenпринимает выражение и набор условий, которые необходимо проверить.
when (x)
{
1 -> print("x == 1")
2 -> print("x == 2")
else -> {
print("x is neither 1 nor 2")
}
}when можно использовать и как выражение, и как оператор.
При использовании в виде выражения значение ветки, удовлетворяющей условию, становится значением всего выражения. При использовании в виде оператора значения отдельных веток отбрасываются.
Если для нескольких значений выполняется одно и то же действие, то условия можно перечислять в одной ветке через запятую:
when (x)
{
0, 1 -> print("x == 0 or x == 1")
else -> print("otherwise")
}Также можно проверять вхождение аргумента в интервал in или !in или его наличие в коллекции:
when (x)
{
in 1..10 -> print("x is in the range")
in validNumbers -> print("x is valid")
!in 10..20 -> print("x is outside the range")
else -> print("none of the above")
}Помимо этого Кotlin позволяет с помощью is или !is проверить тип аргумента. Обратите внимание, что благодаря умным приведениям вы можете получить доступ к методам и свойствам типа без дополнительной проверки:
val hasPrefix = when(x)
{
is String -> x.startsWith("prefix")
else -> false
}when(x) {
{it: Subject -> it.isTheCoolest} -> doSomething()
}Функциональная композиция (function composition) - это техника программирования, которая позволяет создавать новые функции из существующих путем их комбинирования. Каждая функция принимает на вход некоторое значение и возвращает результат, который становится входным значением для следующей функции. Функциональная композиция позволяет создавать более выразительный и модульный код, разбивая сложные задачи на более простые подзадачи.
Функциональная композицияможет быть достигнута с помощью функций высшего порядка, которые принимают одну или несколько функций в качестве аргументов и возвращают новую функцию, которая является композицией этих функций.
fun addTwo(x: Int) = x + 2
fun multiplyByThree(x: Int) = x * 3
val addTwoAndMultiplyByThree = { x: Int -> multiplyByThree(addTwo(x)) }
println(addTwoAndMultiplyByThree(4)) // 18- В этом примере мы создали две функции
addTwo()иmultiplyByThree(), которые складывают 2 и умножают на 3 соответственно. Затем мы определили новую функциюaddTwoAndMultiplyByThree, которая принимает на вход значение типаInt, применяет функциюaddTwo()к этому значению, а затем применяет функциюmultiplyByThree()к результату. Результат выполнения функцииaddTwoAndMultiplyByThree(4)равен 18.
- Функции, которые позволяют делать функциональную композицию более удобной, такие как
compose()иandThen(). - Функция
compose()позволяет создать новую функцию, которая является композицией двух функций, применяемых в обратном порядке. - Тогда как функция
andThen()позволяет создать новую функцию, которая является композицией двух функций в прямом порядке.
un addTwo(x: Int) = x + 2
fun multiplyByThree(x: Int) = x * 3
val addTwoAndMultiplyByThree = ::multiplyByThree.compose(::addTwo)
println(addTwoAndMultiplyByThree(4)) // 18- Здесь мы использовали функцию
compose(), чтобы создать новую функциюaddTwoAndMultiplyByThree, которая сначала применяет функциюaddTwo(), а затем функциюmultiplyByThree(). Результат выполнения функцииaddTwoAndMultiplyByThree(4)равен 18.

Монада — это функциональный шаблон проектирования, который решает повторяющиеся проблемы, такие как:
- Обнуляемость – монада Возможно/Вариант
- Обработка ошибок — любая монада
- DI (внедрение зависимостей) — монада чтения
- Ведение журнала — монада Writer
- Побочные эффекты — монада IO
- Обработка состояния — монада состояния
- Iterable — монада списка
- Многие другие …
Eitherтип представляет значения с двумя возможностями: либоLeftилиRight- Соглашение диктует, что
Leftиспользуется дляfailureиRightиспользуется дляsuccess.
Монады работают с типом в контексте, где контекст — это общий контейнер, содержащий значение

А вот очень простая реализация:
sealed class Either<out A, out B> {
data class Left<A>(val value: A) : Either<A, Nothing>()
data class Right<B>(val value: B) : Either<Nothing, B>()
}Чтобы создать учетную запись, нам нужно указать способ, мы могли бы использовать конструктор, но он не позволяет нам возвращать другие типы, кроме созданного. Следовательно, мы можем предоставить фабричный метод и сделать конструктор закрытым.
data class Account private constructor(val balance: BigDecimal) {
companion object {
fun create(initialBalance: BigDecimal): Either<NegativeAmount, Account> =
if (initialBalance < 0) Either.Left(NegativeAmount)
else Either.Right(Account(initialBalance))
}
}Account.create(initialBalance: BigDecimal): Either<NegativeAmount, Account>
Монада — это функтор с двумя дополнительными операциями. Прежде всего, монада, в отличие от функтора, содержит операцию создания из константы, эта операция называется lift.
По сути, функтор — это контейнер, который содержит значение и позволяет нам отображать его с помощью одной функции, называемой fmapили map:
data class Account private constructor(val balance: BigDecimal) {
companion object {
fun create(initialBalance: BigDecimal): Either<NegativeAmount, Account> =
if (initialBalance < 0) Either.Left(NegativeAmount)
else Either.Right(Account(initialBalance))
}
fun deposit(amount: BigDecimal): Account = this.copy(balance = this.balance + amount)
}
object NegativeAmountТеперь попробуем добавить денег
val account = Account.create(100.toBigDecimal())
when (account) {
is Either.Right -> account.value.deposit(100.toBigDecimal())
is Either.Left -> TODO() // now what?
}Да ладно, это хуже моего красиво-императивного кода! Что мне теперь делать? Выбросить исключение? И что это за шаблонный код?
sealed class Either<out A, out B> {
class Left<A>(val value: A) : Either<A, Nothing>()
class Right<B>(val value: B) : Either<Nothing, B>()
fun <C> map(fn: (B) -> C): Either<A, C> = when (this) {
is Right -> Right(fn(this.value))
is Left -> this
}
}теперь
val account = Account.create(100.toBigDecimal())
.map { a -> a.deposit(100.toBigDecimal()) }Монады определяют две функции:
- Одна для переноса значения в монаду (контейнер), называемый
returnorunit:

- Другой, известный как
bindилиflatmap, для применения функции к содержащемуся значению, которое выводит другую монаду:

Добавим сюда несколько ошибок
data class Account private constructor(val balance: BigDecimal) {
companion object {
fun create(initialBalance: BigDecimal): Either<NegativeAmount, Account> =
applyAmount(initialBalance) { Account(it) }
private fun applyAmount(amount: BigDecimal, fn: (BigDecimal) -> Account) =
if (amount < ZERO) Either.Left(NegativeAmount)
else Either.Right(fn(amount))
}
fun deposit(amount: BigDecimal): Either<NegativeAmount, Account> =
applyAmount(amount) { this.copy(balance = this.balance + it) }
}Кстати, наши Rightи Leftконструкторы можно рассматривать как unitфункцию, они помещают значение в контекст.
И каверзный вопрос. Не могли бы вы сказать мне тип, выводимый в счет val?
al account: Either<NegativeAmount, Either<NegativeAmount, Account>> = Account.create(100.toBigDecimal())
.map { a -> a.deposit(100.toBigDecimal()) }Помните map, что это функция, которая отображает тип Aв тип B, в нашем случае это функция deposit(A):B:
A: Тип BigDecimalB: Либо<NegativeAmount, Account>
Таким образом, мы применяем fn, который не просто преобразует значение, но и оборачивает контекст в уже обернутый контекст.

Угадайте, что, flatmapисправляет это, потому что ожидает функцию, которая возвращает другое содержащееся значение, исправляя беспорядок для вас:
sealed class Either<out A, out B> {
class Left<A>(val value: A) : Either<A, Nothing>()
class Right<B>(val value: B) : Either<Nothing, B>()
fun <C> map(fn: (B) -> C): Either<A, C> = when (this) {
is Right -> Right(fn(this.value))
is Left -> this
}
fun <A, C> flatMap(fn: (B) -> Either<A, C>): Either<A, C> = when (this) {
is Right -> fn(this.value)
is Left -> this as Either<A, C>
}
}val account: Either<NegativeAmount, Account> = Account.create(100.toBigDecimal())
.flatMap { a -> a.deposit(100.toBigDecimal()) }Монады (monads) - это концепция из функционального программирования, которая помогает обрабатывать вычисления в контексте и побочные эффекты (такие как чтение/запись в файл и тд.) в чистом функциональном стиле.
монадымогут быть реализованы с помощью типов данных, которые представляют вычисление в контексте.
Примеры:
- Монада
Optionиспользуется для представления вычислений, которые могут завершаться неудачно и возвращатьnull. В Kotlin,Optionреализуется с помощью классаOption<T>, который может быть либоSome<T>, если значение присутствует, илиNone, если значение отсутствует.
fun divide(a: Int, b: Int): Option<Int> =
if (b == 0) None else Some(a / b)
val result: Option<Int> = divide(10, 5)
val value: Int = result.getOrElse { 0 }- В этом примере мы определили функцию
divide(), которая делит одно число на другое. Если делитель равен 0, функция возвращаетNone, в противном случае она возвращаетSomeс результатом деления. Затем мы вызываем функциюdivide()с аргументами 10 и 5 и получаем результат, который представлен какSome(2). Наконец, мы вызываем методgetOrElse()для извлечения значения из монады. Если значение присутствует, мы получим 2, иначе мы получим значение по умолчанию 0.
- Библиотеки, такие как Arrow, которые предоставляют более мощные типы монад, такие как
Either,IO.
- Монада
Eitherиспользуется для представления вычислений, которые могут возвращать ошибку. В Kotlin,Eitherреализуется с помощью классаEither<L, R>, который может быть либоLeft<L>, представляющий ошибку, либоRight<R>, представляющий результат.
fun divide(a: Int, b: Int): Either<String, Int> =
if (b == 0) Left("Division by zero") else Right(a / b)
val result: Either<String, Int> = divide(10, 5)
val value: Int = result.getOrElse { 0 }- Монада
IOиспользуется для представления вычислений, которые могут выполняться в контексте, например, чтение и запись в файлы. - В Kotlin,
IOреализуется с помощью классаIO<A>, который представляет вычисление типаAв контексте.
val readFile = IO { File("file.txt").readText() }
val contents = readFile.unsafeRun()
println(contents)48. Что такое функторы (functors) и как они применяются в функциональном программировании на Kotlin?
Функтор - это понятие из функционального программирования, которое позволяет нам применять функции к значениям внутри некоторой структуры данных и сохранять контекст или структуру этих данных.
Давайте представим, что у нас есть корзина с фруктами. Каждый фрукт представляет собой значение, а корзина - структуру, которая содержит эти значения. Функтор позволяет нам применять функцию ко всем фруктам в корзине, сохраняя при этом саму структуру корзины. Например, мы можем применить функцию, которая увеличивает вес фрукта на 10%, ко всем фруктам в корзине, и получить новую корзину с обновленными значениями веса фруктов.
Примеры реализаций функтора:
- константа
- функция с произвольным числом аргументов, возвращающая результат типа
A - псевдослучайный генератор с состоянием (Random)
- аппаратный генератор случайных чисел
- чтение объекта с диска или из сети
- асинхронное вычисление — в реализацию функтора передается callback, который будет вызван когда-нибудь потом
В Kotlin функторы обычно реализуются с использованием функций расширения и функциональных типов данных. Например, в стандартной библиотеке Kotlin тип данных List является функтором, так как он может применять функцию к каждому элементу списка, сохраняя при этом структуру списка. Это достигается с помощью функции map, которая принимает функцию и возвращает новую структуру данных с примененными значениями.
val numbers = listOf(1, 2, 3, 4, 5)
val doubledNumbers = numbers.map { it * 2 }
// doubledNumbers содержит [2, 4, 6, 8, 10]Линзы (lenses) - это понятие из функционального программирования, которое представляет собой способ работы с неизменяемыми данными, позволяя удобно и безопасно изменять и получать значения внутри сложных структур данных.
- В контексте функционального программирования на Kotlin,
линзымогут быть реализованы с использованием функций и типов данных. Они позволяют нам изменять или получать значения внутри неизменяемых объектов, таких как кортежи, записи (data class) или другие структуры данных. - Ключевой концепцией
линзявляется разделение структуры данных на фокус и контекст.Фокус- это значение, которое мы хотим изменить или получить, аконтекст- это оставшаяся часть структуры данных.Линзаопределяет способ получения или изменения фокуса внутри контекста.
Одним из примеров реализации линз в Kotlin является библиотека Arrow, которая предоставляет тип данных Lens. Вот пример использования линзы с помощью библиотеки Arrow:
data class Person(val name: String, val age: Int)
val personLens = Lens(
get = { person: Person -> person.name },
set = { person: Person, newName: String -> person.copy(name = newName) }
)
val john = Person("John", 30)
val name = personLens.get(john)
// name содержит "John"
val updatedJohn = personLens.set(john, "Johnny")
// updatedJohn содержит Person("Johnny", 30)- В этом примере мы определяем линзу
personLens, которая позволяет получить и изменить полеnameв структуреPerson. Функцияgetвозвращает значение поляname, а функцияsetсоздает новый объектPersonс измененным полемname. Мы можем использовать линзуpersonLensдля получения значения поляnameиз объектаjohnили для создания нового объектаupdatedJohnс измененным полемname.
Инъективная функция или функция «один к одному» является наиболее часто используемой функцией. Его можно определить как функцию, в которой каждый элемент одного набора должен иметь отображение с уникальным элементом второго набора. Если есть два множества, множество A и множество B, то согласно определению каждый элемент множества A должен иметь уникальный элемент в множестве B. В инъективной функции ответ никогда не повторяется. Представление инъективной функции описывается следующим образом:

Это свойство полезно для проверки уникальности значений в функциональном программировании.
fun <T> ((T) -> Any).injective(): Boolean {
val seen = mutableSetOf<Any>()
return (1..100).all { seen.add(this(it)) }
}Здесь мы определяем расширение для функции (T) -> Any, которое проверяет, является ли функция инъективной. Мы создаем множество seen, которое содержит все значения, возвращаемые функцией, и затем проверяем, что все значения в диапазоне от 1 до 100 уникальны. Это не гарантирует, что функция инъективна для всех возможных значений, но оно дает некоторое представление о том, является ли функция инъективной.
fun main() {
val f: (Int) -> Int = { it * 2 }
println(f.injective()) // true
val g: (Int) -> Int = { it % 2 }
println(g.injective()) // false
}Здесь мы создаем две функции f и g и проверяем, являются ли они инъективными, используя функцию injective(). Функция f является инъективной, потому что каждому значению входного параметра соответствует уникальное значение выходного параметра. Функция g не является инъективной, потому что несколько различных входных значений могут соответствовать одному и тому же выходному значению.
Написание инфиксной функции — это простой случай следования трем правилам:
- Функция либо определена в классе , либо является методом расширения класса .
- Функция принимает ровно один параметр
- Функция определяется с помощью ключевого слова infix
В качестве простого примера давайте определим простую структуру Assertion для использования в тестах. Мы собираемся разрешить выражения, которые хорошо читаются слева направо, используя инфиксные функции:
class Assertion<T>(private val target: T) {
infix fun isEqualTo(other: T) {
Assert.assertEquals(other, target)
}
infix fun isDifferentFrom(other: T) {
Assert.assertNotEquals(other, target)
}
}val result = Assertion(5)
result isEqualTo 5 // This passes
result isEqualTo 6 // This fails the assertion
result isDifferentFrom 5 // This also fails the assertionФункциональное связывание (functional binding) в Kotlin позволяет нам создавать новые функции, основываясь на уже существующих, и захватывать значения аргументов или переменных из этих функций. Это позволяет нам создавать специализированные версии функций с некоторыми аргументами, которые уже определены.
- Например, предположим, у нас есть функция
add, которая складывает два числа:
fun add(a: Int, b: Int): Int {
return a + b
}- Мы можем использовать функциональное связывание, чтобы создать новую функцию, которая всегда будет складывать число 5 с другим числом:
val addFive: (Int) -> Int = { x -> add(5, x) }- Пример использования функции
addFive:
val result = addFive(10)
println(result) // Выведет 15- Функциональное связывание в Kotlin позволяет нам создавать более специализированные функции на основе уже существующих функций.
52. Что такое корутины (coroutines) в Kotlin и как они используются для асинхронного программирования?
Корутины в Kotlin - это инструмент, который помогает управлять асинхронными задачами. Вместо создания отдельных потоков или использования коллбэков, корутины предлагают легковесный и декларативный подход к асинхронному программированию.
- Основная идея
корутинзаключается в том, что они позволяют нам писать код, который выглядит как последовательный и синхронный, но при этом выполняется асинхронно.Корутиныиспользуются для выполнения задач в фоновом режиме, чтобы не блокировать основной поток выполнения и не делать приложение неотзывчивым. - Мы можем создавать
корутиныс помощью функцииlaunch, указывая код, который должен выполняться внутри них. Мы также можем использовать функциюasync, которая позволяет возвращать результат выполнения задачи. - Для контроля выполнения
корутинмы можем использовать функцииdelay,withContext,async,awaitи другие, чтобы управлять временными задержками, контекстом выполнения и синхронизацией результатов.
Сопрограммы можно рассматривать как легковесные потоки, но есть ряд важных отличий, которые сильно отличают их реальное использование от потоков.
launch — это строитель сопрограмм . Он запускает новую сопрограмму одновременно с остальным кодом, которая продолжает работать независимо.
delay — это специальная функция приостановки . Он приостанавливает сопрограмму на определенное время. Приостановка сопрограммы не блокирует базовый поток, но позволяет запускать другие сопрограммы и использовать базовый поток для своего кода.
runBlocking — также является конструктором сопрограмм.
fun main() = runBlocking { // this: CoroutineScope
launch { // launch a new coroutine and continue
delay(1000L) // non-blocking delay for 1
//second (default time unit is ms)
println("World!") // print after delay
}
println("Hello") // main coroutine continues while
//a previous one is delayed
}Hello
World!Модификатор suspend( функция приостановки) определяет функцию, которая может приостановить свое выполнение и возобновить его через некоторый период времени.
fun main() = runBlocking { // this: CoroutineScope
launch { doWorld() }
println("Hello")
}
// this is your first suspending function
suspend fun doWorld() {
delay(1000L)
println("World!")
}Прежде всего для определения и выполнения корутины надо определить для нее контекст, так как корутина может вызываться только в контексте корутины (coroutine scope). Для этого применяется функция coroutineScope() - создает контекст корутины.
Стоит отметить, что coroutineScope() может применяться только в функции с модификатором suspend.
Строители runBlocking и coroutineScope могут выглядеть одинаково, потому что они оба ждут завершения своего тела и всех его дочерних элементов. Основное отличие состоит в том, что метод runBlocking блокирует текущий поток для ожидания, в то время как coroutineScope просто приостанавливает работу, освобождая базовый поток для других целей. Из-за этой разницы runBlocking является обычной функцией, а coroutineScope — функцией приостановки.
Сама корутина определяется и запускается с помощью построителя корутин - функции launch.
fun main() = runBlocking {
doWorld()
}
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(1000L)
println("World!")
}
println("Hello")
}Конструктор coroutineScope можно использовать внутри любой приостанавливающей функции для выполнения нескольких параллельных операций.
// Sequentially executes doWorld followed by "Done"
fun main() = runBlocking {
doWorld()
println("Done")
}
// Concurrently executes both sections
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(2000L)
println("World 2")
}
launch {
delay(1000L)
println("World 1")
}
println("Hello")
}Оба фрагмента кода внутри launch { ... }блоков выполняются одновременно , причем World 1первый печатается через секунду после запуска, а World 2печатается следующим через две секунды после запуска. CoroutineScope завершается только после завершения обоих.
Строитель сопрограммы launch возвращает объект Job , который может использоваться для явного ожидания ее завершения. Например, вы можете дождаться завершения дочерней сопрограммы, а затем вывести строку «Готово»:
fun main() = runBlocking {
val job = launch { // launch a new coroutine and
//keep a reference to its Job
delay(1000L)
println("World!")
}
println("Hello")
job.join() // wait until child coroutine completes
println("Done")
}Теперь корутина только создается с помощью функции launch, но непосредственно она запускается только при вызове метода job.start().
import kotlinx.coroutines.*
suspend fun main() = coroutineScope{
// корутина создана, но не запущена
val job = launch(start = CoroutineStart.LAZY) {
delay(200L)
println("Coroutine has started")
}
delay(1000L)
job.start() // запускаем корутину
println("Other actions in main method")
}Наряду с launch в пакете kotlinx.coroutines есть еще один построитель корутин - функция async. Эта функция применяется, когда надо получить из корутины некоторый результат.
(отличиеasync от launch - async это обещание вернуть некоторое значение)
async запускает отдельную корутину, которая выполняется параллельно с остальными корутинами. Например:
import kotlinx.coroutines.*
suspend fun main() = coroutineScope{
async{ printHello()}
println("Program has finished")
}
suspend fun printHello(){
delay(500L) // имитация продолжительной работы
println("Hello work!")
}Кроме того, async-корутина возвращает объект Deferred, который ожидает получения результата корутины. (Интерфейс Deferred унаследован от интерфейса Job, поэтому для также доступны весь функционал, определенный для интефейса Job)
Для получения результата из объекта Deferredприменяется функцияawait()`. Рассмотрим на примере:
import kotlinx.coroutines.*
suspend fun main() = coroutineScope{
val message: Deferred<String> = async{ getMessage()}
println("message: ${message.await()}")
println("Program has finished")
}
suspend fun getMessage() : String{
delay(500L) // имитация продолжительной работы
return "Hello"
}Поскольку функция getMessage() возвращает объект типа String, то метод await() в данном случае также будет возвращать строку, которую мы могли бы, например, присвоить переменной:
val text: String = message.await()Контекст корутины включает себя такой элемент как диспетчер корутины. Диспетчер корутины определяет какой поток или какие потоки будут использоваться для выполнения корутины.
Все построители корутины, в частности, функции launch и async в качестве необязательного параметра принимают объект типа CoroutineContext, который может использоваться для определения диспетчера создаваемой корутины.
-
Dispatchers.Default:применяется по умолчанию, если тип диспетчера не указан явным образом. Этот тип использует общий пул разделяемых фоновых потоков и подходит для вычислений, которые не работают с операциями ввода-вывода (операциями с файлами, базами данных, сетью) и которые требуют интенсивного потребления ресурсов центрального процессора. -
Dispatchers.IO:использует общий пул потоков, создаваемых по мере необходимости, и предназначен для выполнения операций ввода-вывода (например, операции с файлами или сетевыми запросами). -
Dispatchers.Main:применяется в графических приложениях, например, в приложениях Android или JavaFX. -
Dispatchers.Unconfined:корутина не закреплена четко за определенным потоком или пулом потоков. Она запускается в текущем потоке до первой приостановки. После возобновления работы корутина продолжает работу в одном из потоков, который сторого не фиксирован. Разработчики языка Kotlin в обычной ситуации не рекомендуют использовать данный тип. -
newSingleThreadContexиnewFixedThreadPoolContext:позволяют вручную задать поток/пул для выполнения корутины
И мы можем сами задать для корутины диспетчер, передав в функцию launch (а также async) соответствующее значение:
import kotlinx.coroutines.*
suspend fun main() = coroutineScope{
launch(Dispatchers.Default) { // явным образом определяем диспетчер Dispatcher.Default
println("Корутина выполняется на потоке: ${Thread.currentThread().name}")
}
println("Функция main выполняется на потоке: ${Thread.currentThread().name}")
}Для отмены выполнения корутины у объекта Job может применяться метод cancel()
import kotlinx.coroutines.*
suspend fun main() = coroutineScope{
val downloader: Job = launch{
println("Начинаем загрузку файлов")
for(i in 1..5){
println("Загружен файл $i")
delay(500L)
}
}
delay(800L) // установим задержку, чтобы несколько файлов загрузились
println("Надоело ждать, пока все файлы загрузятся. Прерву-ка я загрузку...")
downloader.cancel() // отменяем корутину
downloader.join() // ожидаем завершения корутины
println("Работа программы завершена")
}В данном случае определена корутина, которая имитирует загрузку файлов. В цикле пробегаемся от 1 до 5 и условно загружаем пять файлов.
Далее вызов метода downloader.cancel() сигнализирует корутине, что надо прервать выполнение. Затем с помощью метода join() ожидаем завершения корутина, которая прервана. В итоге получим консольный вывод наподобие следующего:
Начинаем загрузку файлов
Загружен файл 1
Загружен файл 2
Надоело ждать, пока все файлы загрузятся. Прерву-ка я загрузку...
Работа программы завершена
Также вместо двух методов cancel() иjoin() можно использовать один сборный метод cancelAndJoin()
Подобным образом можно отменять выполнение и корутин, создаваемых с помощью функции async(). В этом случае обычно вызов метода await() помещается в блок try
53. Что такое мемоизация (memoization) и как она применяется в функциональном программировании на Kotlin?
Мемоизация - это техника оптимизации, которая заключается в сохранении результатов выполнения функции для определенных аргументов и их повторном использовании при последующих вызовах функции с теми же аргументами. Это позволяет избежать повторных вычислений и ускоряет выполнение функции.
-
Для применения
мемоизациив функциональном программировании на Kotlin мы создаем функцию, которая принимает другую функцию в качестве параметра. Внутри этой функции мы создаем кэш, где будем сохранять результаты выполнения функции для каждого набора аргументов. -
Когда вызывается
мемоизированная функция, она проверяет наличие результата для заданных аргументов в кэше. Если результат уже есть, то он возвращается. Если результат отсутствует, то вызывается оригинальная функция для вычисления результата, который затем сохраняется в кэше для последующих вызовов. -
Пример
мемоизациифункции вычисления числа Фибоначчи:
fun <T, R> memoize(function: (T) -> R): (T) -> R {
val cache = mutableMapOf<T, R>()
return { input ->
cache.getOrPut(input) { function(input) }
}
}
val fibonacci: (Int) -> Long = { n ->
if (n < 2) n.toLong()
else fibonacci(n - 1) + fibonacci(n - 2)
}
val memoizedFibonacci = memoize(fibonacci)
fun main() {
println(memoizedFibonacci(10)) // Вычисляется и выводится 55
println(memoizedFibonacci(10)) // Возвращается из кэша 55, не происходит повторного вычисления
}-
В этом примере мы определяем функцию
fibonacci, которая рекурсивно вычисляет число Фибоначчи для заданного аргументаn. Однако, без мемоизации, эта функция будет выполнять повторные вычисления для одних и тех же аргументов, что приведет к значительному времени выполнения при больших значенияхn. -
Чтобы применить мемоизацию, мы создаем
memoizedFibonacciс помощью функцииmemoize, передавая ей функциюfibonacci. Затем мы вызываемmemoizedFibonacciдважды с аргументом 10. При первом вызове функция вычисляется и выводит результат 55. При втором вызове функция возвращает результат из кэша, и повторное вычисление не происходит. -
Благодаря мемоизации, мы можем существенно сократить время выполнения функции
fibonacci, так как результаты для каждого аргумента сохраняются и повторно используются.
generateSequence: Эта функция позволяет создавать бесконечные последовательности на основе лямбда-выражения. Она принимает начальное значение и лямбда-выражение, которое генерирует следующий элемент последовательности на основе предыдущего элемента.
fun main() {
val oddNumbers = generateSequence(1) { it + 2 } // `it` - это предыдущее значение
println(oddNumbers.take(5).toList()) // [1, 3, 5, 7, 9]
//println(oddNumbers.count()) // ошибка: последовательность бесконечна
}Для создания конечной последовательности передайте в generateSequence() такую функцию, которая после последнего нужного вам элемента вернёт null.
fun main() {
val oddNumbersLessThan10 = generateSequence(1) { if (it < 8) it + 2 else null }
println(oddNumbersLessThan10.count()) // 5
}sequence(), которая позволяет создавать элементы последовательности один за другим или кусками(chunks)произвольного размера.
Эта функция принимает лямбда-выражение, содержащее вызовы функций yield() и yieldAll().
Они возвращают элемент потребителю последовательности и приостанавливают выполнение sequence() до тех пор, пока потребитель не запросит следующий элемент. Функция yield() принимает в качестве аргумента один элемент; yieldAll() может принимать объект Iterable, Iterator или другую Sequence. Аргумент Sequence, переданный в yieldAll(), может быть бесконечным. Однако такой вызов должен быть последним, иначе все последующие вызовы никогда не будут выполнены.
fun main() {
val oddNumbers = sequence {
yield(1)
yieldAll(listOf(3, 5))
yieldAll(generateSequence(7) { it + 2 })
}
println(oddNumbers.take(5).toList()) // [1, 3, 5, 7, 9]
}Sequence: Это интерфейс, который определяет последовательность элементов. Вы можете реализовать этот интерфейс, чтобы создать свою собственную бесконечную последовательность.
class CustomSequence : Sequence<Int> {
override fun iterator(): Iterator<Int> {
return object : Iterator<Int> {
var current = 0
override fun hasNext(): Boolean = true
override fun next(): Int = current++
}
}
}
val customSequence = CustomSequence()
println(customSequence.take(5).toList()) // [0, 1, 2, 3, 4]55. Какие функции Kotlin позволяют применять операции разбиения (split) и соединения (join) к строкам?
split: Эта функция разделяет строку на подстроки, используя заданный разделитель. Она возвращает список строк. Пример:
val str = "Hello, World!"
val parts = str.split(", ")
println(parts) // [Hello, World!]splitToSequence: Эта функция аналогичнаsplit, но возвращает ленивую последовательность (Sequence) разделенных подстрок, что полезно при работе с большими строками или бесконечными последовательностями. Пример:
val str = "Hello, World!"
val partsSequence = str.splitToSequence(", ")
println(partsSequence.toList()) // [Hello, World!]joinToString: Эта функция соединяет элементы коллекции (или другие объекты) в строку, используя заданный разделитель и префикс/суффикс при необходимости. Пример:
val numbers = listOf("one", "two", "three", "four")
println(numbers) // [one, two, three, four]
println(numbers.joinToString()) // one, two, three, four
val listString = StringBuffer("The list of numbers: ")
numbers.joinTo(listString) println(listString) // The list of numbers: one, two, three, fourjoinTo: Эта функция аналогичнаjoinToString, но добавляет результат сразу к указанномуStringBuilderвместо создания новой строки. Пример:
val list = listOf("Hello", "World", "!")
val builder = StringBuilder()
list.joinTo(builder, separator = " ")
val joinedStr = builder.toString()
println(joinedStr) // Hello World !- Но также вы можете кастомизировать строковое представление коллекции, указав необходимые вам параметры при помощи специальных аргументов -
separator,prefix, иpostfix.
fun main() {
val numbers = listOf("one", "two", "three", "four")
println(numbers.joinToString( separator = " | ", prefix = "start: ", postfix = ": end" ))
// start: one | two | three | four: end
}- Если коллекция большая, то вы можете указать limit - количество элементов, которые будут включены в результат.
fun main() {
val numbers = (1..100).toList()
println(numbers.joinToString( limit = 10, truncated = "<...>") ) // 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, <...>
}compareTo: Это функция, которая определена для объектов, реализующих интерфейсComparable<T>. Она сравнивает текущий объект с другим объектом и возвращает целое число, указывающее на их относительный порядок. Пример:
val num1 = 10
val num2 = 5
val result = num1.compareTo(num2)
println(result) // 1compareBy: Это функция, которая позволяет создавать компараторы для сравнения объектов по заданным свойствам или критериям. Она принимает лямбда-выражение, которое определяет, как сравнивать объекты. Пример:
data class Person(val name: String, val age: Int)
val people = listOf(
Person("Alice", 25),
Person("Bob", 30),
Person("Charlie", 20)
)
val sortedPeople = people.sortedWith(compareBy { it.age })
println(sortedPeople) // [Charlie, Alice, Bob]sorted: Это функция расширения для коллекций, которая сортирует элементы коллекции в естественном порядке (используя их реализациюComparable<T>) или с помощью заданного компаратора. Пример:
val numbers = listOf(5, 2, 8, 1, 3)
val sortedNumbers = numbers.sorted()
println(sortedNumbers) // [1, 2, 3, 5, 8]sortedBy: Это функция расширения для коллекций, которая сортирует элементы коллекции на основе заданного критерия. Она принимает лямбда-выражение, которое определяет, по какому свойству или критерию сортировать объекты. Пример:
data class Person(val name: String, val age: Int)
val people = listOf(
Person("Alice", 25),
Person("Bob", 30),
Person("Charlie", 20)
)
val sortedPeople = people.sortedBy { it.age }
println(sortedPeople) // [Charlie, Alice, Bob]57. Что такое инвариантность (invariance) и ковариантность (covariance) типов в Kotlin и как они связаны с функциональным программированием?
Вариантность описывает, как обобщенные типы, типизированные классами из одной иерархии наследования, соотносятся друг с другом.
Инвариантность предполагает, что, если у нас есть классы Base и Derived, где Derived - производный класс от Base, то класс C<Base> не является ни базовым классом для С<Derived>, ни производным. (Пример Base - Any, Derived- String)
interface Messenger<T: Message>()
open class Message(val text: String)
class EmailMessage(text: String): Message(text)В данном случае мы не можем присвоить объект Messenger<EmailMessage> переменной типа Messenger<Message> и наоборот, они никак между собой не соотносятся, несмотря на то, что EmailMessage наследуется от Message:
fun changeMessengerToEmail(obj: Messenger<EmailMessage>){
val messenger: Messenger<Message> = obj // ! Ошибка
}
fun changeMessengerToDefault(obj: Messenger<Message>){
val messenger: Messenger<EmailMessage> = obj // ! Ошибка
}Мы можем присвоить переменным по умолчанию только объекты их типов.

Ковариантость предполагает, что, если у нас есть классы Base и Derived, где Base - базовый класс для Derived, то класс SomeClass<Base> является базовым классом для SomeClass<Derived>
Для определения обобщенного типа как ковариантного параметр обобщения определяется с ключевым словом out:
interface Messenger<out T: Message>
open class Message(val text: String)
class EmailMessage(text: String): Message(text)В данном случае интерфейс Messenger является ковариантным, так как его параметр определен со словом out: interface Messenger<out T>. И теперь переменной типа Messenger<Message> мы можем присвоить значение типа Messenger<EmailMessage>
fun changeMessengerToEmail(obj: Messenger<EmailMessage>){
val messenger: Messenger<Message> = obj
}Вот так получился класс, который может только отдавать значение, он условно называется Производитель.
// такой же пример с habr
class Box<out T : Animal>(val animal: T)
open class Animal()
class Cat : Animal()
fun main() {
val a: Animal = Cat()
val b: Box<Animal> = Box<Cat>(Cat()) //теперь можно
println(b.animal) //читать можно
}Зачем это может понадобиться? Скажем, у нас есть клетки с животными разных типов: Cat, Dog, Bird,… все они наследуются от Animal, и нам не важно кто они, мы просто хотим всех покормить — вызвать некую функцию feedMe() на классе Animal, например.
Еще раз отметим, что когда пишете свой класс «производитель», то параметр помеченный out, может находиться только на «отдающей» позиции:
class ABox<out T>(var animal: T // нельзя )
{
fun setT(new: T) // нельзя
{
animal = new
}
fun getT(): T = animal //можно
}
Контрвариантность предполагает в какой-то степени обратную ситуацию. Контрвариантность предполагает, что, если у нас есть классы Base и Derived, где Base - базовый класс для Derived, то объекту SomeClass<Derived> мы можем присвоить значение SomeClass<Base> (при ковариантности, наоборот, - объекту SomeClass<Base> можно присвоить значение SomeClass<Derived>)
Для определения обобщенного типа как контравариантного параметр обобщения определяется с ключевым словом in:
interface Messenger<in T: Message>
open class Message(val text: String)
class EmailMessage(text: String): Message(text)В данном случае интерфейс Messenger является контравариантным, так как его параметр определен со словом in: interface Messenger<in T>. И теперь переменной типа Messenger<EmailMessage> мы можем присвоить значение типа Messenger<Message>
fun changeMessengerToDefault(obj: Messenger<Message>){
val messenger: Messenger<EmailMessage> = obj
}// такой же пример с habr
class Processor<in T : Number>() {
fun process(a: T) {
//как то работаем с числами тут
}
}
fun main() {
val p: Processor<Int> = Processor<Number>()
p.process(1) //Int можно
p.process(1.2F) //float теперь нельзя
p.process(1.2) //double теперь нельзя
}Есть класс Processor, он может обрабатывать любые типы чисел, (умножать, складывать — не важно что), но объявив p как Processor мы сузили его возможности, теперь он может работать только с Int (и его потомками если бы они могли существовать)
В отличии от ковариантности, для которой безопасной является только операция чтения, для контрвариантности такой операцией является — запись. Вы можете передать некий Т в класс, но не вернуть его обратно наружу:
class Box<in T>(var element: T // нельзя)
{
fun set(new: T) { //можно
element = new
}
fun get(): T = element // нельзя
} Мы помечаем параметр T с помощью in. Так получается класс «потребитель». Свойство element должно быть приватным, а функцию get вообще придется убрать отсюда, оставив, возможность лишь принимать.
Пример: sortedWith
Ковариантность полезна, когда мы хотим работать с контейнерами, которые содержат подтипы, и обеспечивает безопасность типов при получении объектов из контейнера.
Инвариантность, ковариантность и контравариантность относятся к отношениям между типами в языках программирования, включая Kotlin.
Инвариантность(invariance): Инвариантность означает, что тип не разрешает прямое присваивание между ним и его подтипами или надтипами. Это означает, что тип и его подтипы или надтипы не являются взаимозаменяемыми в контексте присваивания значений. В языке Kotlin типы данных по умолчанию являются инвариантными.
class Animal
class Cat : Animal
class Dog : Animal
fun main() {
val animal: Animal = Cat() // Ошибка компиляции, несовместимые типы
}Ковариантность(covariance): Ковариантность позволяет использовать подтипы вместо типов в более общих контекстах. Если тип является ковариантным, то значение его подтипа может быть присвоено переменной с типом-надтипом. Ковариантность применяется в контекстах только для чтения.
interface Container<out T> {
fun getItem(): T
}
fun main() {
val catContainer: Container<Cat> = object : Container<Cat> {
override fun getItem(): Cat = Cat()
}
val animalContainer: Container<Animal> = catContainer // Ковариантность
val animal: Animal = animalContainer.getItem()
}Контравариантность(contravariance): Контравариантность позволяет использовать надтипы вместо типов в более специализированных контекстах. Если тип является контравариантным, то значение его надтипа может быть присвоено переменной с типом-подтипом. Контравариантность применяется в контекстах только для записи.
interface Comparator<in T> {
fun compare(item1: T, item2: T): Int
}
fun main() {
val animalComparator: Comparator<Animal> = object : Comparator<Animal> {
override fun compare(item1: Animal, item2: Animal): Int {
// Логика сравнения
return 0
}
}
val catComparator: Comparator<Cat> = animalComparator // Контравариантность
}Вывод:
- Инвариантность ограничивает присваивание значений между типами, не разрешая прямой замены типов