This project took place over the summer of 2023 as part of the Google Summer of Code, working closely with DBpedia. For some background, DBpedia is a community-driven project that extracts structured information from Wikipedia and makes it available as an Open Knowledge Graph (OKG), for use in various applications and research.
The main goal of this project was to explore DBpedia’s potential to enrich the data provided to Recommender Systems (RS) on different standard datasets. The first step of the project was to implement a data integration pipeline to enrich the MovieLens and LastFM datasets.
Also, a framework was implemented for running reproducible experiments with only the model implementation and a simple .yaml configuration file. Through the framework, this project allows practitioners to easily evaluate and compare their proposed RS algorithms with existing approaches, enabling future benchmarks on enriched and non-enriched datasets.
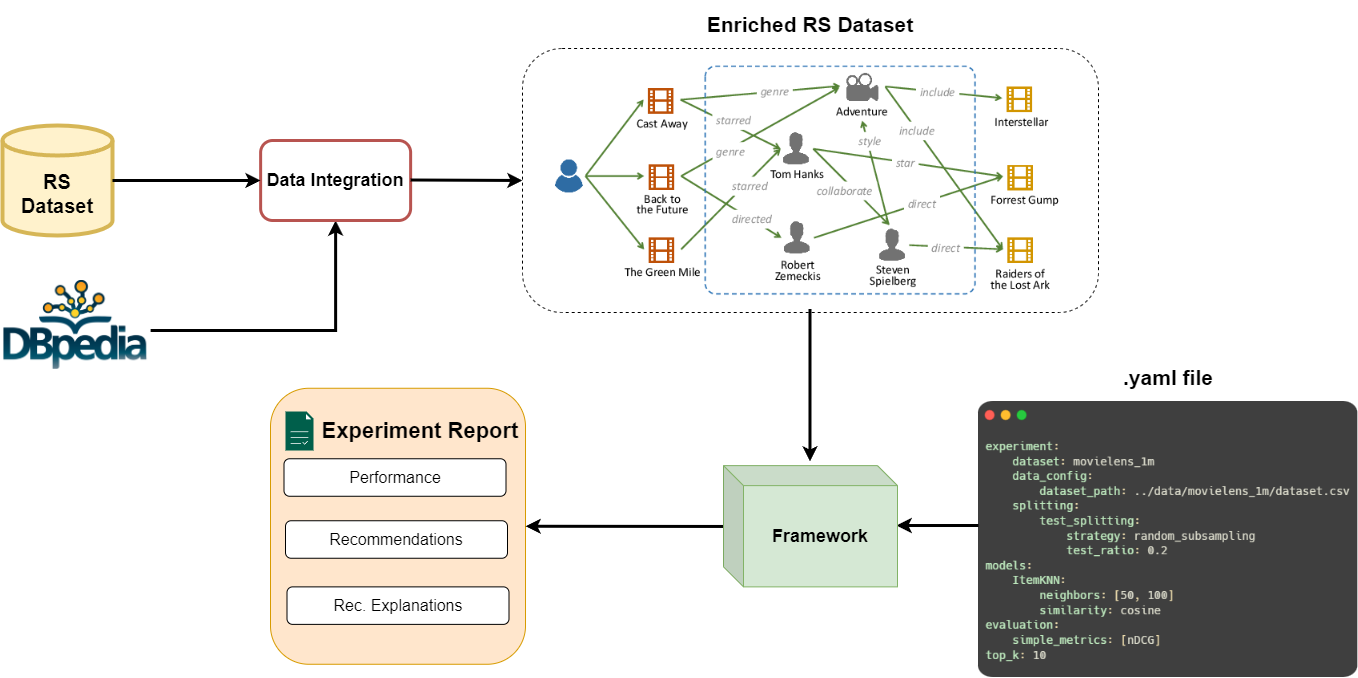
My main contributions were the implementation of the Data Integration and Framework modules. I implemented the backbone for both, with some supported datasets and methods, to allow the configuration of a simple experiment pipeline.
Currently, the supported datasets for Data Integration are:
| Dataset | #items matched | #items |
|---|---|---|
| MovieLens-100k | 1462 | 1681 |
| MovieLens-1M | 3356 | 3883 |
| LastFM-hetrec-2011 | 11815 | 17632 |
Each Framework submodule currently supports:
- Pre-processing Methods:
- Binarize ratings.
- Filtering by k-core
- Splitting Methods
- Random by Ratio
- Timestamp by Ratio
- Fixed Timestamp
- K-Fold
- Recommender System Models:
- deepwalk_based: Node embedding based model (Node2Vec) + cosine similarity.
- Evaluation Metrics
- MAP@k
- nDCG@k
Although I did complete all of the goals set for this project proposal, there is a lot of room for improvement. Currently, we have the backbone for running simple benchmarks, but we need to add more datasets and methods on both, Data Integration and Framework modules, for running more complete ones.
With this in mind, this project was also designed to support further contributions, whether adding new supported datasets, new baseline models, new evaluation metrics, or bug fixing.
I plan to continue contributing to this project, by adding new datasets, RS models, and metrics. I and my mentor also plan to publish a benchmarking paper using this resource as a way to share with the RS and open-source communities that this project is available for running reproducible experiments.
I also plan to contribute to different projects at DBpedia in the future.
Participating in the Google Summer of Code 2023 program, and dedicating my efforts to the "Knowledge Graph aware Recommendation System with DBpedia" project, has been an enriching experience. I'm grateful for the opportunity to contribute to DBpedia and Recommender System communities.
I also would like to thank the guidance of my mentors Paulo do Carmo and Edgard Marx, and for always helping me throughout this program. I have gained a lot of knowledge while working with them and the open-source community. I'm looking forward to contributing more with you in the near future.
Thanks for your support ❤️