Created
March 27, 2022 15:28
-
-
Save ChrisRackauckas/c60b3bd42f25ad54ad6bb8f6cb241baa to your computer and use it in GitHub Desktop.
Automatic Differentiation Done Quick: Forward and Reverse Mode Differentiable Programming
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| <!DOCTYPE html> | |
| <HTML lang = "en"> | |
| <HEAD> | |
| <meta charset="UTF-8"/> | |
| <meta name="viewport" content="width=device-width, initial-scale=1.0, user-scalable=yes"> | |
| <title>Forward and Reverse Automatic Differentiation In A Nutshell</title> | |
| <script type="text/x-mathjax-config"> | |
| MathJax.Hub.Config({ | |
| tex2jax: {inlineMath: [['$','$'], ['\\(','\\)']]}, | |
| TeX: { equationNumbers: { autoNumber: "AMS" } } | |
| }); | |
| </script> | |
| <script type="text/javascript" async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.1/MathJax.js?config=TeX-AMS-MML_HTMLorMML"> | |
| </script> | |
| <style> | |
| pre.hljl { | |
| border: 1px solid #ccc; | |
| margin: 5px; | |
| padding: 5px; | |
| overflow-x: auto; | |
| color: rgb(68,68,68); background-color: rgb(251,251,251); } | |
| pre.hljl > span.hljl-t { } | |
| pre.hljl > span.hljl-w { } | |
| pre.hljl > span.hljl-e { } | |
| pre.hljl > span.hljl-eB { } | |
| pre.hljl > span.hljl-o { } | |
| pre.hljl > span.hljl-k { color: rgb(148,91,176); font-weight: bold; } | |
| pre.hljl > span.hljl-kc { color: rgb(59,151,46); font-style: italic; } | |
| pre.hljl > span.hljl-kd { color: rgb(214,102,97); font-style: italic; } | |
| pre.hljl > span.hljl-kn { color: rgb(148,91,176); font-weight: bold; } | |
| pre.hljl > span.hljl-kp { color: rgb(148,91,176); font-weight: bold; } | |
| pre.hljl > span.hljl-kr { color: rgb(148,91,176); font-weight: bold; } | |
| pre.hljl > span.hljl-kt { color: rgb(148,91,176); font-weight: bold; } | |
| pre.hljl > span.hljl-n { } | |
| pre.hljl > span.hljl-na { } | |
| pre.hljl > span.hljl-nb { } | |
| pre.hljl > span.hljl-nbp { } | |
| pre.hljl > span.hljl-nc { } | |
| pre.hljl > span.hljl-ncB { } | |
| pre.hljl > span.hljl-nd { color: rgb(214,102,97); } | |
| pre.hljl > span.hljl-ne { } | |
| pre.hljl > span.hljl-neB { } | |
| pre.hljl > span.hljl-nf { color: rgb(66,102,213); } | |
| pre.hljl > span.hljl-nfm { color: rgb(66,102,213); } | |
| pre.hljl > span.hljl-np { } | |
| pre.hljl > span.hljl-nl { } | |
| pre.hljl > span.hljl-nn { } | |
| pre.hljl > span.hljl-no { } | |
| pre.hljl > span.hljl-nt { } | |
| pre.hljl > span.hljl-nv { } | |
| pre.hljl > span.hljl-nvc { } | |
| pre.hljl > span.hljl-nvg { } | |
| pre.hljl > span.hljl-nvi { } | |
| pre.hljl > span.hljl-nvm { } | |
| pre.hljl > span.hljl-l { } | |
| pre.hljl > span.hljl-ld { color: rgb(148,91,176); font-style: italic; } | |
| pre.hljl > span.hljl-s { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-sa { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-sb { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-sc { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-sd { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-sdB { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-sdC { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-se { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-sh { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-si { } | |
| pre.hljl > span.hljl-so { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-sr { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-ss { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-ssB { color: rgb(201,61,57); } | |
| pre.hljl > span.hljl-nB { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-nbB { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-nfB { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-nh { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-ni { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-nil { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-noB { color: rgb(59,151,46); } | |
| pre.hljl > span.hljl-oB { color: rgb(102,102,102); font-weight: bold; } | |
| pre.hljl > span.hljl-ow { color: rgb(102,102,102); font-weight: bold; } | |
| pre.hljl > span.hljl-p { } | |
| pre.hljl > span.hljl-c { color: rgb(153,153,119); font-style: italic; } | |
| pre.hljl > span.hljl-ch { color: rgb(153,153,119); font-style: italic; } | |
| pre.hljl > span.hljl-cm { color: rgb(153,153,119); font-style: italic; } | |
| pre.hljl > span.hljl-cp { color: rgb(153,153,119); font-style: italic; } | |
| pre.hljl > span.hljl-cpB { color: rgb(153,153,119); font-style: italic; } | |
| pre.hljl > span.hljl-cs { color: rgb(153,153,119); font-style: italic; } | |
| pre.hljl > span.hljl-csB { color: rgb(153,153,119); font-style: italic; } | |
| pre.hljl > span.hljl-g { } | |
| pre.hljl > span.hljl-gd { } | |
| pre.hljl > span.hljl-ge { } | |
| pre.hljl > span.hljl-geB { } | |
| pre.hljl > span.hljl-gh { } | |
| pre.hljl > span.hljl-gi { } | |
| pre.hljl > span.hljl-go { } | |
| pre.hljl > span.hljl-gp { } | |
| pre.hljl > span.hljl-gs { } | |
| pre.hljl > span.hljl-gsB { } | |
| pre.hljl > span.hljl-gt { } | |
| </style> | |
| <style type="text/css"> | |
| @font-face { | |
| font-style: normal; | |
| font-weight: 300; | |
| } | |
| @font-face { | |
| font-style: normal; | |
| font-weight: 400; | |
| } | |
| @font-face { | |
| font-style: normal; | |
| font-weight: 600; | |
| } | |
| html { | |
| font-family: sans-serif; /* 1 */ | |
| -ms-text-size-adjust: 100%; /* 2 */ | |
| -webkit-text-size-adjust: 100%; /* 2 */ | |
| } | |
| body { | |
| margin: 0; | |
| } | |
| article, | |
| aside, | |
| details, | |
| figcaption, | |
| figure, | |
| footer, | |
| header, | |
| hgroup, | |
| main, | |
| menu, | |
| nav, | |
| section, | |
| summary { | |
| display: block; | |
| } | |
| audio, | |
| canvas, | |
| progress, | |
| video { | |
| display: inline-block; /* 1 */ | |
| vertical-align: baseline; /* 2 */ | |
| } | |
| audio:not([controls]) { | |
| display: none; | |
| height: 0; | |
| } | |
| [hidden], | |
| template { | |
| display: none; | |
| } | |
| a:active, | |
| a:hover { | |
| outline: 0; | |
| } | |
| abbr[title] { | |
| border-bottom: 1px dotted; | |
| } | |
| b, | |
| strong { | |
| font-weight: bold; | |
| } | |
| dfn { | |
| font-style: italic; | |
| } | |
| h1 { | |
| font-size: 2em; | |
| margin: 0.67em 0; | |
| } | |
| mark { | |
| background: #ff0; | |
| color: #000; | |
| } | |
| small { | |
| font-size: 80%; | |
| } | |
| sub, | |
| sup { | |
| font-size: 75%; | |
| line-height: 0; | |
| position: relative; | |
| vertical-align: baseline; | |
| } | |
| sup { | |
| top: -0.5em; | |
| } | |
| sub { | |
| bottom: -0.25em; | |
| } | |
| img { | |
| border: 0; | |
| } | |
| svg:not(:root) { | |
| overflow: hidden; | |
| } | |
| figure { | |
| margin: 1em 40px; | |
| } | |
| hr { | |
| -moz-box-sizing: content-box; | |
| box-sizing: content-box; | |
| height: 0; | |
| } | |
| pre { | |
| overflow: auto; | |
| } | |
| code, | |
| kbd, | |
| pre, | |
| samp { | |
| font-family: monospace, monospace; | |
| font-size: 1em; | |
| } | |
| button, | |
| input, | |
| optgroup, | |
| select, | |
| textarea { | |
| color: inherit; /* 1 */ | |
| font: inherit; /* 2 */ | |
| margin: 0; /* 3 */ | |
| } | |
| button { | |
| overflow: visible; | |
| } | |
| button, | |
| select { | |
| text-transform: none; | |
| } | |
| button, | |
| html input[type="button"], /* 1 */ | |
| input[type="reset"], | |
| input[type="submit"] { | |
| -webkit-appearance: button; /* 2 */ | |
| cursor: pointer; /* 3 */ | |
| } | |
| button[disabled], | |
| html input[disabled] { | |
| cursor: default; | |
| } | |
| button::-moz-focus-inner, | |
| input::-moz-focus-inner { | |
| border: 0; | |
| padding: 0; | |
| } | |
| input { | |
| line-height: normal; | |
| } | |
| input[type="checkbox"], | |
| input[type="radio"] { | |
| box-sizing: border-box; /* 1 */ | |
| padding: 0; /* 2 */ | |
| } | |
| input[type="number"]::-webkit-inner-spin-button, | |
| input[type="number"]::-webkit-outer-spin-button { | |
| height: auto; | |
| } | |
| input[type="search"] { | |
| -webkit-appearance: textfield; /* 1 */ | |
| -moz-box-sizing: content-box; | |
| -webkit-box-sizing: content-box; /* 2 */ | |
| box-sizing: content-box; | |
| } | |
| input[type="search"]::-webkit-search-cancel-button, | |
| input[type="search"]::-webkit-search-decoration { | |
| -webkit-appearance: none; | |
| } | |
| fieldset { | |
| border: 1px solid #c0c0c0; | |
| margin: 0 2px; | |
| padding: 0.35em 0.625em 0.75em; | |
| } | |
| legend { | |
| border: 0; /* 1 */ | |
| padding: 0; /* 2 */ | |
| } | |
| textarea { | |
| overflow: auto; | |
| } | |
| optgroup { | |
| font-weight: bold; | |
| } | |
| table { | |
| font-family: monospace, monospace; | |
| font-size : 0.8em; | |
| border-collapse: collapse; | |
| border-spacing: 0; | |
| } | |
| td, | |
| th { | |
| padding: 0; | |
| } | |
| thead th { | |
| border-bottom: 1px solid black; | |
| background-color: white; | |
| } | |
| tr:nth-child(odd){ | |
| background-color: rgb(248,248,248); | |
| } | |
| /* | |
| * Skeleton V2.0.4 | |
| * Copyright 2014, Dave Gamache | |
| * www.getskeleton.com | |
| * Free to use under the MIT license. | |
| * http://www.opensource.org/licenses/mit-license.php | |
| * 12/29/2014 | |
| */ | |
| .container { | |
| position: relative; | |
| width: 100%; | |
| max-width: 960px; | |
| margin: 0 auto; | |
| padding: 0 20px; | |
| box-sizing: border-box; } | |
| .column, | |
| .columns { | |
| width: 100%; | |
| float: left; | |
| box-sizing: border-box; } | |
| @media (min-width: 400px) { | |
| .container { | |
| width: 85%; | |
| padding: 0; } | |
| } | |
| @media (min-width: 550px) { | |
| .container { | |
| width: 80%; } | |
| .column, | |
| .columns { | |
| margin-left: 4%; } | |
| .column:first-child, | |
| .columns:first-child { | |
| margin-left: 0; } | |
| .one.column, | |
| .one.columns { width: 4.66666666667%; } | |
| .two.columns { width: 13.3333333333%; } | |
| .three.columns { width: 22%; } | |
| .four.columns { width: 30.6666666667%; } | |
| .five.columns { width: 39.3333333333%; } | |
| .six.columns { width: 48%; } | |
| .seven.columns { width: 56.6666666667%; } | |
| .eight.columns { width: 65.3333333333%; } | |
| .nine.columns { width: 74.0%; } | |
| .ten.columns { width: 82.6666666667%; } | |
| .eleven.columns { width: 91.3333333333%; } | |
| .twelve.columns { width: 100%; margin-left: 0; } | |
| .one-third.column { width: 30.6666666667%; } | |
| .two-thirds.column { width: 65.3333333333%; } | |
| .one-half.column { width: 48%; } | |
| /* Offsets */ | |
| .offset-by-one.column, | |
| .offset-by-one.columns { margin-left: 8.66666666667%; } | |
| .offset-by-two.column, | |
| .offset-by-two.columns { margin-left: 17.3333333333%; } | |
| .offset-by-three.column, | |
| .offset-by-three.columns { margin-left: 26%; } | |
| .offset-by-four.column, | |
| .offset-by-four.columns { margin-left: 34.6666666667%; } | |
| .offset-by-five.column, | |
| .offset-by-five.columns { margin-left: 43.3333333333%; } | |
| .offset-by-six.column, | |
| .offset-by-six.columns { margin-left: 52%; } | |
| .offset-by-seven.column, | |
| .offset-by-seven.columns { margin-left: 60.6666666667%; } | |
| .offset-by-eight.column, | |
| .offset-by-eight.columns { margin-left: 69.3333333333%; } | |
| .offset-by-nine.column, | |
| .offset-by-nine.columns { margin-left: 78.0%; } | |
| .offset-by-ten.column, | |
| .offset-by-ten.columns { margin-left: 86.6666666667%; } | |
| .offset-by-eleven.column, | |
| .offset-by-eleven.columns { margin-left: 95.3333333333%; } | |
| .offset-by-one-third.column, | |
| .offset-by-one-third.columns { margin-left: 34.6666666667%; } | |
| .offset-by-two-thirds.column, | |
| .offset-by-two-thirds.columns { margin-left: 69.3333333333%; } | |
| .offset-by-one-half.column, | |
| .offset-by-one-half.columns { margin-left: 52%; } | |
| } | |
| html { | |
| font-size: 62.5%; } | |
| body { | |
| font-size: 1.5em; /* currently ems cause chrome bug misinterpreting rems on body element */ | |
| line-height: 1.6; | |
| font-weight: 400; | |
| font-family: "Raleway", "HelveticaNeue", "Helvetica Neue", Helvetica, Arial, sans-serif; | |
| color: #222; } | |
| h1, h2, h3, h4, h5, h6 { | |
| margin-top: 0; | |
| margin-bottom: 2rem; | |
| font-weight: 300; } | |
| h1 { font-size: 3.6rem; line-height: 1.2; letter-spacing: -.1rem;} | |
| h2 { font-size: 3.4rem; line-height: 1.25; letter-spacing: -.1rem; } | |
| h3 { font-size: 3.2rem; line-height: 1.3; letter-spacing: -.1rem; } | |
| h4 { font-size: 2.8rem; line-height: 1.35; letter-spacing: -.08rem; } | |
| h5 { font-size: 2.4rem; line-height: 1.5; letter-spacing: -.05rem; } | |
| h6 { font-size: 1.5rem; line-height: 1.6; letter-spacing: 0; } | |
| p { | |
| margin-top: 0; } | |
| a { | |
| color: #1EAEDB; } | |
| a:hover { | |
| color: #0FA0CE; } | |
| .button, | |
| button, | |
| input[type="submit"], | |
| input[type="reset"], | |
| input[type="button"] { | |
| display: inline-block; | |
| height: 38px; | |
| padding: 0 30px; | |
| color: #555; | |
| text-align: center; | |
| font-size: 11px; | |
| font-weight: 600; | |
| line-height: 38px; | |
| letter-spacing: .1rem; | |
| text-transform: uppercase; | |
| text-decoration: none; | |
| white-space: nowrap; | |
| background-color: transparent; | |
| border-radius: 4px; | |
| border: 1px solid #bbb; | |
| cursor: pointer; | |
| box-sizing: border-box; } | |
| .button:hover, | |
| button:hover, | |
| input[type="submit"]:hover, | |
| input[type="reset"]:hover, | |
| input[type="button"]:hover, | |
| .button:focus, | |
| button:focus, | |
| input[type="submit"]:focus, | |
| input[type="reset"]:focus, | |
| input[type="button"]:focus { | |
| color: #333; | |
| border-color: #888; | |
| outline: 0; } | |
| .button.button-primary, | |
| button.button-primary, | |
| input[type="submit"].button-primary, | |
| input[type="reset"].button-primary, | |
| input[type="button"].button-primary { | |
| color: #FFF; | |
| background-color: #33C3F0; | |
| border-color: #33C3F0; } | |
| .button.button-primary:hover, | |
| button.button-primary:hover, | |
| input[type="submit"].button-primary:hover, | |
| input[type="reset"].button-primary:hover, | |
| input[type="button"].button-primary:hover, | |
| .button.button-primary:focus, | |
| button.button-primary:focus, | |
| input[type="submit"].button-primary:focus, | |
| input[type="reset"].button-primary:focus, | |
| input[type="button"].button-primary:focus { | |
| color: #FFF; | |
| background-color: #1EAEDB; | |
| border-color: #1EAEDB; } | |
| input[type="email"], | |
| input[type="number"], | |
| input[type="search"], | |
| input[type="text"], | |
| input[type="tel"], | |
| input[type="url"], | |
| input[type="password"], | |
| textarea, | |
| select { | |
| height: 38px; | |
| padding: 6px 10px; /* The 6px vertically centers text on FF, ignored by Webkit */ | |
| background-color: #fff; | |
| border: 1px solid #D1D1D1; | |
| border-radius: 4px; | |
| box-shadow: none; | |
| box-sizing: border-box; } | |
| /* Removes awkward default styles on some inputs for iOS */ | |
| input[type="email"], | |
| input[type="number"], | |
| input[type="search"], | |
| input[type="text"], | |
| input[type="tel"], | |
| input[type="url"], | |
| input[type="password"], | |
| textarea { | |
| -webkit-appearance: none; | |
| -moz-appearance: none; | |
| appearance: none; } | |
| textarea { | |
| min-height: 65px; | |
| padding-top: 6px; | |
| padding-bottom: 6px; } | |
| input[type="email"]:focus, | |
| input[type="number"]:focus, | |
| input[type="search"]:focus, | |
| input[type="text"]:focus, | |
| input[type="tel"]:focus, | |
| input[type="url"]:focus, | |
| input[type="password"]:focus, | |
| textarea:focus, | |
| select:focus { | |
| border: 1px solid #33C3F0; | |
| outline: 0; } | |
| label, | |
| legend { | |
| display: block; | |
| margin-bottom: .5rem; | |
| font-weight: 600; } | |
| fieldset { | |
| padding: 0; | |
| border-width: 0; } | |
| input[type="checkbox"], | |
| input[type="radio"] { | |
| display: inline; } | |
| label > .label-body { | |
| display: inline-block; | |
| margin-left: .5rem; | |
| font-weight: normal; } | |
| ul { | |
| list-style: circle; } | |
| ol { | |
| list-style: decimal; } | |
| ul ul, | |
| ul ol, | |
| ol ol, | |
| ol ul { | |
| margin: 1.5rem 0 1.5rem 3rem; | |
| font-size: 90%; } | |
| li > p {margin : 0;} | |
| th, | |
| td { | |
| padding: 12px 15px; | |
| text-align: left; | |
| border-bottom: 1px solid #E1E1E1; } | |
| th:first-child, | |
| td:first-child { | |
| padding-left: 0; } | |
| th:last-child, | |
| td:last-child { | |
| padding-right: 0; } | |
| button, | |
| .button { | |
| margin-bottom: 1rem; } | |
| input, | |
| textarea, | |
| select, | |
| fieldset { | |
| margin-bottom: 1.5rem; } | |
| pre, | |
| blockquote, | |
| dl, | |
| figure, | |
| table, | |
| p, | |
| ul, | |
| ol, | |
| form { | |
| margin-bottom: 1.0rem; } | |
| .u-full-width { | |
| width: 100%; | |
| box-sizing: border-box; } | |
| .u-max-full-width { | |
| max-width: 100%; | |
| box-sizing: border-box; } | |
| .u-pull-right { | |
| float: right; } | |
| .u-pull-left { | |
| float: left; } | |
| hr { | |
| margin-top: 3rem; | |
| margin-bottom: 3.5rem; | |
| border-width: 0; | |
| border-top: 1px solid #E1E1E1; } | |
| .container:after, | |
| .row:after, | |
| .u-cf { | |
| content: ""; | |
| display: table; | |
| clear: both; } | |
| pre { | |
| display: block; | |
| padding: 9.5px; | |
| margin: 0 0 10px; | |
| font-size: 13px; | |
| line-height: 1.42857143; | |
| word-break: break-all; | |
| word-wrap: break-word; | |
| border: 1px solid #ccc; | |
| border-radius: 4px; | |
| } | |
| pre.hljl { | |
| margin: 0 0 10px; | |
| display: block; | |
| background: #f5f5f5; | |
| border-radius: 4px; | |
| padding : 5px; | |
| } | |
| pre.output { | |
| background: #ffffff; | |
| } | |
| pre.code { | |
| background: #ffffff; | |
| } | |
| pre.julia-error { | |
| color : red | |
| } | |
| code, | |
| kbd, | |
| pre, | |
| samp { | |
| font-family: Menlo, Monaco, Consolas, "Courier New", monospace; | |
| font-size: 0.9em; | |
| } | |
| @media (min-width: 400px) {} | |
| @media (min-width: 550px) {} | |
| @media (min-width: 750px) {} | |
| @media (min-width: 1000px) {} | |
| @media (min-width: 1200px) {} | |
| h1.title {margin-top : 20px} | |
| img {max-width : 100%} | |
| div.title {text-align: center;} | |
| </style> | |
| </HEAD> | |
| <BODY> | |
| <div class ="container"> | |
| <div class = "row"> | |
| <div class = "col-md-12 twelve columns"> | |
| <div class="title"> | |
| <h1 class="title">Forward and Reverse Automatic Differentiation In A Nutshell</h1> | |
| <h5>Chris Rackauckas</h5> | |
| <h5>January 21st, 2022</h5> | |
| </div> | |
| <h1>Machine Epsilon and Roundoff Error</h1> | |
| <p>Floating point arithmetic is relatively scaled, which means that the precision that you get from calculations is relative to the size of the floating point numbers. Generally, you have 16 digits of accuracy in (64-bit) floating point operations. To measure this, we define <em>machine epsilon</em> as the value by which <code>1 + E = 1</code>. For floating point numbers, this is:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>eps</span><span class='hljl-p'>(</span><span class='hljl-n'>Float64</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| 2.220446049250313e-16 | |
| </pre> | |
| <p>However, since it's relative, this value changes as we change our reference value:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-nf'>eps</span><span class='hljl-p'>(</span><span class='hljl-nfB'>1.0</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-nf'>eps</span><span class='hljl-p'>(</span><span class='hljl-nfB'>0.1</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-nf'>eps</span><span class='hljl-p'>(</span><span class='hljl-nfB'>0.01</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| eps(1.0) = 2.220446049250313e-16 | |
| eps(0.1) = 1.3877787807814457e-17 | |
| eps(0.01) = 1.734723475976807e-18 | |
| 1.734723475976807e-18 | |
| </pre> | |
| <p>Thus issues with <em>roundoff error</em> come when one subtracts out the higher digits. For example, <span class="math">$(x + \epsilon) - x$</span> should just be <span class="math">$\epsilon$</span> if there was no roundoff error, but if <span class="math">$\epsilon$</span> is small then this kicks in. If <span class="math">$x = 1$</span> and <span class="math">$\epsilon$</span> is of size around <span class="math">$10^{-10}$</span>, then <span class="math">$x+ \epsilon$</span> is correct for 10 digits, dropping off the smallest 6 due to error in the addition to <span class="math">$1$</span>. But when you subtract off <span class="math">$x$</span>, you don't get those digits back, and thus you only have 6 digits of <span class="math">$\epsilon$</span> correct.</p> | |
| <p>Let's see this in action:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>ϵ</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nfB'>1e-10</span><span class='hljl-nf'>rand</span><span class='hljl-p'>()</span><span class='hljl-t'> | |
| </span><span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-n'>ϵ</span><span class='hljl-t'> | |
| </span><span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-ni'>1</span><span class='hljl-oB'>+</span><span class='hljl-n'>ϵ</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>ϵ2</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-ni'>1</span><span class='hljl-oB'>+</span><span class='hljl-n'>ϵ</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>-</span><span class='hljl-t'> </span><span class='hljl-ni'>1</span><span class='hljl-t'> | |
| </span><span class='hljl-p'>(</span><span class='hljl-n'>ϵ</span><span class='hljl-t'> </span><span class='hljl-oB'>-</span><span class='hljl-t'> </span><span class='hljl-n'>ϵ2</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| ϵ = 9.236209819962081e-11 | |
| 1 + ϵ = 1.0000000000923621 | |
| -1.975420506320867e-17 | |
| </pre> | |
| <p>See how <span class="math">$\epsilon$</span> is only rebuilt at accuracy around <span class="math">$10^{-16}$</span> and thus we only keep around 6 digits of accuracy when it's generated at the size of around <span class="math">$10^{-10}$</span>!</p> | |
| <h2>Finite Differencing and Numerical Stability</h2> | |
| <p>To start understanding how to compute derivatives on a computer, we start with <em>finite differencing</em>. For finite differencing, recall that the definition of the derivative is:</p> | |
| <p class="math">\[ | |
| f'(x) = \lim_{\epsilon \rightarrow 0} \frac{f(x+\epsilon)-f(x)}{\epsilon} | |
| \]</p> | |
| <p>Finite differencing directly follows from this definition by choosing a small <span class="math">$\epsilon$</span>. However, choosing a good <span class="math">$\epsilon$</span> is very difficult. If <span class="math">$\epsilon$</span> is too large than there is error since this definition is asymtopic. However, if <span class="math">$\epsilon$</span> is too small, you receive roundoff error. To understand why you would get roundoff error, recall that floating point error is relative, and can essentially store 16 digits of accuracy. So let's say we choose <span class="math">$\epsilon = 10^{-6}$</span>. Then <span class="math">$f(x+\epsilon) - f(x)$</span> is roughly the same in the first 6 digits, meaning that after the subtraction there is only 10 digits of accuracy, and then dividing by <span class="math">$10^{-6}$</span> simply brings those 10 digits back up to the correct relative size.</p> | |
| <p><img src="https://www.researchgate.net/profile/Jongrae_Kim/publication/267216155/figure/fig1/AS:651888458493955@1532433728729/Finite-Difference-Error-Versus-Step-Size.png" alt="" /></p> | |
| <p>This means that we want to choose <span class="math">$\epsilon$</span> small enough that the <span class="math">$\mathcal{O}(\epsilon^2)$</span> error of the truncation is balanced by the <span class="math">$O(1/\epsilon)$</span> roundoff error. Under some minor assumptions, one can argue that the average best point is <span class="math">$\sqrt(E)$</span>, where E is machine epsilon</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-nf'>eps</span><span class='hljl-p'>(</span><span class='hljl-n'>Float64</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-nf'>sqrt</span><span class='hljl-p'>(</span><span class='hljl-nf'>eps</span><span class='hljl-p'>(</span><span class='hljl-n'>Float64</span><span class='hljl-p'>))</span> | |
| </pre> | |
| <pre class="output"> | |
| eps(Float64) = 2.220446049250313e-16 | |
| sqrt(eps(Float64)) = 1.4901161193847656e-8 | |
| 1.4901161193847656e-8 | |
| </pre> | |
| <p>This means we should not expect better than 8 digits of accuracy, even when things are good with finite differencing.</p> | |
| <p><img src="http://degenerateconic.com/wp-content/uploads/2014/11/complex_step1.png" alt="" /></p> | |
| <p>The centered difference formula is a little bit better, but this picture suggests something much better...</p> | |
| <h2>Differencing in a Different Dimension: Complex Step Differentiation</h2> | |
| <p>The problem with finite differencing is that we are mixing our really small number with the really large number, and so when we do the subtract we lose accuracy. Instead, we want to keep the small perturbation completely separate.</p> | |
| <p>To see how to do this, assume that <span class="math">$x \in \mathbb{R}$</span> and assume that <span class="math">$f$</span> is complex analytic. You want to calculate a real derivative, but your function just happens to also be complex analytic when extended to the complex plane. Thus it has a Taylor series, and let's see what happens when we expand out this Taylor series purely in the complex direction:</p> | |
| <p class="math">\[ | |
| f(x+ih) = f(x) + f'(x)ih + \mathcal{O}(h^2) | |
| \]</p> | |
| <p>which we can re-arrange as:</p> | |
| <p class="math">\[ | |
| if'(x) = \frac{f(x+ih) - f(x)}{h} + \mathcal{O}(h) | |
| \]</p> | |
| <p>Since <span class="math">$x$</span> is real and <span class="math">$f$</span> is real-valued on the reals, <span class="math">$if'$</span> is purely imaginary. So let's take the imaginary parts of both sides:</p> | |
| <p class="math">\[ | |
| f'(x) = \frac{Im(f(x+ih))}{h} + \mathcal{O}(h) | |
| \]</p> | |
| <p>since <span class="math">$Im(f(x)) = 0$</span> (since it's real valued!). Thus with a sufficiently small choice of <span class="math">$h$</span>, this is the <em>complex step differentiation</em> formula for calculating the derivative.</p> | |
| <p>But to understand the computational advantage, recal that <span class="math">$x$</span> is pure real, and thus <span class="math">$x+ih$</span> is an imaginary number where <strong>the <span class="math">$h$</span> never directly interacts with <span class="math">$x$</span></strong> since a complex number is a two dimensional number where you keep the two pieces separate. Thus there is no numerical cancellation by using a small value of <span class="math">$h$</span>, and thus, due to the relative precision of floating point numbers, both the real and imaginary parts will be computed to (approximately) 16 digits of accuracy for any choice of <span class="math">$h$</span>.</p> | |
| <h2>Derivatives as nilpotent sensitivities</h2> | |
| <p>The derivative measures the <strong>sensitivity</strong> of a function, i.e. how much the function output changes when the input changes by a small amount <span class="math">$\epsilon$</span>:</p> | |
| <p class="math">\[ | |
| f(a + \epsilon) = f(a) + f'(a) \epsilon + o(\epsilon). | |
| \]</p> | |
| <p>In the following we will ignore higher-order terms; formally we set <span class="math">$\epsilon^2 = 0$</span>. This form of analysis can be made rigorous through a form of non-standard analysis called <em>Smooth Infinitesimal Analysis</em> [1], though note that nilpotent infinitesimal requires <em>constructive logic</em>, and thus proof by contradiction is not allowed in this logic due to a lack of the <em>law of the excluded middle</em>.</p> | |
| <p>A function <span class="math">$f$</span> will be represented by its value <span class="math">$f(a)$</span> and derivative <span class="math">$f'(a)$</span>, encoded as the coefficients of a degree-1 (Taylor) polynomial in <span class="math">$\epsilon$</span>:</p> | |
| <p class="math">\[ | |
| f \rightsquigarrow f(a) + \epsilon f'(a) | |
| \]</p> | |
| <p>Conversely, if we have such an expansion in <span class="math">$\epsilon$</span> for a given function <span class="math">$f$</span>, then we can identify the coefficient of <span class="math">$\epsilon$</span> as the derivative of <span class="math">$f$</span>.</p> | |
| <h2>Dual numbers</h2> | |
| <p>Thus, to extend the idea of complex step differentiation beyond complex analytic functions, we define a new number type, the <em>dual number</em>. A dual number is a multidimensional number where the sensitivity of the function is propagated along the dual portion.</p> | |
| <p>Here we will now start to use <span class="math">$\epsilon$</span> as a dimensional signifier, like <span class="math">$i$</span>, <span class="math">$j$</span>, or <span class="math">$k$</span> for quaternion numbers. In order for this to work out, we need to derive an appropriate algebra for our numbers. To do this, we will look at Taylor series to make our algebra reconstruct differentiation.</p> | |
| <p>Note that the chain rule has been explicitly encoded in the derivative part.</p> | |
| <p class="math">\[ | |
| f(a + \epsilon) = f(a) + \epsilon f'(a) | |
| \]</p> | |
| <p>to first order. If we have two functions</p> | |
| <p class="math">\[ | |
| f \rightsquigarrow f(a) + \epsilon f'(a) | |
| \]</p> | |
| <p class="math">\[ | |
| g \rightsquigarrow g(a) + \epsilon g'(a) | |
| \]</p> | |
| <p>then we can manipulate these Taylor expansions to calculate combinations of these functions as follows. Using the nilpotent algebra, we have that:</p> | |
| <p class="math">\[ | |
| (f + g) = [f(a) + g(a)] + \epsilon[f'(a) + g'(a)] | |
| \]</p> | |
| <p class="math">\[ | |
| (f \cdot g) = [f(a) \cdot g(a)] + \epsilon[f(a) \cdot g'(a) + g(a) \cdot f'(a) ] | |
| \]</p> | |
| <p>From these we can <em>infer</em> the derivatives by taking the component of <span class="math">$\epsilon$</span>. These also tell us the way to implement these in the computer.</p> | |
| <h2>Computer representation</h2> | |
| <p>Setup (not necessary from the REPL):</p> | |
| <pre class='hljl'> | |
| <span class='hljl-k'>using</span><span class='hljl-t'> </span><span class='hljl-n'>InteractiveUtils</span><span class='hljl-t'> </span><span class='hljl-cs'># only needed when using Weave</span> | |
| </pre> | |
| <p>Each function requires two pieces of information and some particular "behavior", so we store these in a <code>struct</code>. It's common to call this a "dual number":</p> | |
| <pre class='hljl'> | |
| <span class='hljl-k'>struct</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>{</span><span class='hljl-n'>T</span><span class='hljl-p'>}</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>val</span><span class='hljl-oB'>::</span><span class='hljl-n'>T</span><span class='hljl-t'> </span><span class='hljl-cs'># value</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>der</span><span class='hljl-oB'>::</span><span class='hljl-n'>T</span><span class='hljl-t'> </span><span class='hljl-cs'># derivative</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span> | |
| </pre> | |
| <p>Each <code>Dual</code> object represents a function. We define arithmetic operations to mirror performing those operations on the corresponding functions.</p> | |
| <p>We must first import the operations from <code>Base</code>:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>Base</span><span class='hljl-oB'>.:+</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:+</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-oB'>::</span><span class='hljl-n'>Number</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:+</span><span class='hljl-p'>(</span><span class='hljl-n'>α</span><span class='hljl-oB'>::</span><span class='hljl-n'>Number</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-t'> | |
| </span><span class='hljl-cm'>#= | |
| You can also write: | |
| import Base: + | |
| f::Dual + g::Dual = Dual(f.val + g.val, f.der + g.der) | |
| =#</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:-</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>-</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-t'> </span><span class='hljl-oB'>-</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-cs'># Product Rule</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:*</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-oB'>*</span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-oB'>*</span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-oB'>*</span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:*</span><span class='hljl-p'>(</span><span class='hljl-n'>α</span><span class='hljl-oB'>::</span><span class='hljl-n'>Number</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:*</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-oB'>::</span><span class='hljl-n'>Number</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-t'> | |
| </span><span class='hljl-cs'># Quotient Rule</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:/</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-oB'>/</span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-oB'>*</span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>-</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-oB'>*</span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-p'>)</span><span class='hljl-oB'>/</span><span class='hljl-p'>(</span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-oB'>^</span><span class='hljl-ni'>2</span><span class='hljl-p'>))</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:/</span><span class='hljl-p'>(</span><span class='hljl-n'>α</span><span class='hljl-oB'>::</span><span class='hljl-n'>Number</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>α</span><span class='hljl-oB'>/</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-oB'>-</span><span class='hljl-n'>α</span><span class='hljl-oB'>*</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-oB'>/</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-oB'>^</span><span class='hljl-ni'>2</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:/</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>α</span><span class='hljl-oB'>::</span><span class='hljl-n'>Number</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-nf'>inv</span><span class='hljl-p'>(</span><span class='hljl-n'>α</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-cs'># Dual(f.val/α, f.der * (1/α))</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.:^</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>n</span><span class='hljl-oB'>::</span><span class='hljl-n'>Integer</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>Base</span><span class='hljl-oB'>.</span><span class='hljl-nf'>power_by_squaring</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>n</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-cs'># use repeated squaring for integer powers</span> | |
| </pre> | |
| <p>We can now define <code>Dual</code>s and manipulate them:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>f</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-ni'>3</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-ni'>4</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>g</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-ni'>5</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-ni'>6</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>f</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>g</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Int64}(8, 10) | |
| </pre> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>f</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>g</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Int64}(15, 38) | |
| </pre> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>f</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-n'>g</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Int64}(30, 76) | |
| </pre> | |
| <h2>Defining Higher Order Primitives</h2> | |
| <p>We can also define functions of <code>Dual</code> objects, using the chain rule. To speed up our derivative function, we can directly hardcode the derivative of known functions which we call <em>primitives</em>. If <code>f</code> is a <code>Dual</code> representing the function <span class="math">$f$</span>, then <code>exp(f)</code> should be a <code>Dual</code> representing the function <span class="math">$\exp \circ f$</span>, i.e. with value <span class="math">$\exp(f(a))$</span> and derivative <span class="math">$(\exp \circ f)'(a) = \exp(f(a)) \, f'(a)$</span>:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-k'>import</span><span class='hljl-t'> </span><span class='hljl-n'>Base</span><span class='hljl-oB'>:</span><span class='hljl-t'> </span><span class='hljl-n'>exp</span> | |
| </pre> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>exp</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-n'>Dual</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-nf'>exp</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>),</span><span class='hljl-t'> </span><span class='hljl-nf'>exp</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| exp (generic function with 36 methods) | |
| </pre> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>f</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Int64}(3, 4) | |
| </pre> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>exp</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Float64}(20.085536923187668, 80.3421476927506 | |
| 7) | |
| </pre> | |
| <h1>Differentiating arbitrary functions</h1> | |
| <p>For functions where we don't have a rule, we can recursively do dual number arithmetic within the function until we hit primitives where we know the derivative, and then use the chain rule to propagate the information back up. Under this algebra, we can represent <span class="math">$a + \epsilon$</span> as <code>Dual(a, 1)</code>. Thus, applying <code>f</code> to <code>Dual(a, 1)</code> should give <code>Dual(f(a), f'(a))</code>. This is thus a 2-dimensional number for calculating the derivative without floating point error, <strong>using the compiler to transform our equations into dual number arithmetic</strong>. To to differentiate an arbitrary function, we define a generic function and then change the algebra.</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>h</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-oB'>^</span><span class='hljl-ni'>2</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-ni'>2</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>a</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-ni'>3</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>xx</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>a</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-ni'>1</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Int64}(3, 1) | |
| </pre> | |
| <p>Now we simply evaluate the function <code>h</code> at the <code>Dual</code> number <code>xx</code>:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>h</span><span class='hljl-p'>(</span><span class='hljl-n'>xx</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Int64}(11, 6) | |
| </pre> | |
| <p>The first component of the resulting <code>Dual</code> is the value <span class="math">$h(a)$</span>, and the second component is the derivative, <span class="math">$h'(a)$</span>!</p> | |
| <p>We can codify this into a function as follows:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>derivative</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>f</span><span class='hljl-p'>(</span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nf'>one</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>)))</span><span class='hljl-oB'>.</span><span class='hljl-n'>der</span> | |
| </pre> | |
| <pre class="output"> | |
| derivative (generic function with 1 method) | |
| </pre> | |
| <p>Here, <code>one</code> is the function that gives the value <span class="math">$1$</span> with the same type as that of <code>x</code>.</p> | |
| <p>Finally we can now calculate derivatives such as</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>derivative</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>-></span><span class='hljl-t'> </span><span class='hljl-ni'>3</span><span class='hljl-n'>x</span><span class='hljl-oB'>^</span><span class='hljl-ni'>5</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-ni'>2</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-ni'>2</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| 240 | |
| </pre> | |
| <p>As a bigger example, we can take a pure Julia <code>sqrt</code> function and differentiate it by changing the internal algebra:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-k'>function</span><span class='hljl-t'> </span><span class='hljl-nf'>newtons</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>a</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>for</span><span class='hljl-t'> </span><span class='hljl-n'>i</span><span class='hljl-t'> </span><span class='hljl-kp'>in</span><span class='hljl-t'> </span><span class='hljl-ni'>1</span><span class='hljl-oB'>:</span><span class='hljl-ni'>300</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>a</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nfB'>0.5</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-n'>a</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-oB'>/</span><span class='hljl-n'>a</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>a</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span><span class='hljl-t'> | |
| </span><span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-nf'>newtons</span><span class='hljl-p'>(</span><span class='hljl-nfB'>2.0</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-nd'>@show</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-nf'>newtons</span><span class='hljl-p'>(</span><span class='hljl-nfB'>2.0</span><span class='hljl-oB'>+</span><span class='hljl-nf'>sqrt</span><span class='hljl-p'>(</span><span class='hljl-nf'>eps</span><span class='hljl-p'>()))</span><span class='hljl-t'> </span><span class='hljl-oB'>-</span><span class='hljl-t'> </span><span class='hljl-nf'>newtons</span><span class='hljl-p'>(</span><span class='hljl-nfB'>2.0</span><span class='hljl-p'>))</span><span class='hljl-oB'>/</span><span class='hljl-t'> </span><span class='hljl-nf'>sqrt</span><span class='hljl-p'>(</span><span class='hljl-nf'>eps</span><span class='hljl-p'>())</span><span class='hljl-t'> | |
| </span><span class='hljl-nf'>newtons</span><span class='hljl-p'>(</span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-nfB'>2.0</span><span class='hljl-p'>,</span><span class='hljl-nfB'>1.0</span><span class='hljl-p'>))</span> | |
| </pre> | |
| <pre class="output"> | |
| newtons(2.0) = 1.414213562373095 | |
| (newtons(2.0 + sqrt(eps())) - newtons(2.0)) / sqrt(eps()) = 0.3535533994436 | |
| 264 | |
| Main.##WeaveSandBox#1023.Dual{Float64}(1.414213562373095, 0.353553390593273 | |
| 73) | |
| </pre> | |
| <h2>Higher dimensions</h2> | |
| <p>How can we extend this to higher dimensional functions? For example, we wish to differentiate the following function <span class="math">$f: \mathbb{R}^2 \to \mathbb{R}$</span>:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>ff</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-oB'>^</span><span class='hljl-ni'>2</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-oB'>*</span><span class='hljl-n'>y</span> | |
| </pre> | |
| <pre class="output"> | |
| ff (generic function with 1 method) | |
| </pre> | |
| <p>Recall that the <strong>partial derivative</strong> <span class="math">$\partial f/\partial x$</span> is defined by fixing <span class="math">$y$</span> and differentiating the resulting function of <span class="math">$x$</span>:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>a</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>b</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nfB'>3.0</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nfB'>4.0</span><span class='hljl-t'> | |
| </span><span class='hljl-nf'>ff_1</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>ff</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>b</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-cs'># single-variable function</span> | |
| </pre> | |
| <pre class="output"> | |
| ff_1 (generic function with 1 method) | |
| </pre> | |
| <p>Since we now have a single-variable function, we can differentiate it:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>derivative</span><span class='hljl-p'>(</span><span class='hljl-n'>ff_1</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>a</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| 10.0 | |
| </pre> | |
| <p>Under the hood this is doing</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>ff</span><span class='hljl-p'>(</span><span class='hljl-nf'>Dual</span><span class='hljl-p'>(</span><span class='hljl-n'>a</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nf'>one</span><span class='hljl-p'>(</span><span class='hljl-n'>a</span><span class='hljl-p'>)),</span><span class='hljl-t'> </span><span class='hljl-n'>b</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.Dual{Float64}(21.0, 10.0) | |
| </pre> | |
| <p>Similarly, we can differentiate with respect to <span class="math">$y$</span> by doing</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>ff_2</span><span class='hljl-p'>(</span><span class='hljl-n'>y</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>ff</span><span class='hljl-p'>(</span><span class='hljl-n'>a</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-cs'># single-variable function</span><span class='hljl-t'> | |
| </span><span class='hljl-nf'>derivative</span><span class='hljl-p'>(</span><span class='hljl-n'>ff_2</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>b</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| 3.0 | |
| </pre> | |
| <p>Note that we must do <strong>two separate calculations</strong> to get the two partial derivatives; in general, calculating the gradient <span class="math">$\nabla$</span> of a function <span class="math">$f:\mathbb{R}^n \to \mathbb{R}$</span> requires <span class="math">$n$</span> separate calculations.</p> | |
| <h2>Implementation of higher-dimensional forward-mode AD</h2> | |
| <p>We can implement derivatives of functions <span class="math">$f: \mathbb{R}^n \to \mathbb{R}$</span> by adding several independent partial derivative components to our dual numbers.</p> | |
| <p>We can think of these as <span class="math">$\epsilon$</span> perturbations in different directions, which satisfy <span class="math">$\epsilon_i^2 = \epsilon_i \epsilon_j = 0$</span>, and we will call <span class="math">$\epsilon$</span> the vector of all perturbations. Then we have</p> | |
| <p class="math">\[ | |
| f(a + \epsilon) = f(a) + \nabla f(a) \cdot \epsilon + \mathcal{O}(\epsilon^2), | |
| \]</p> | |
| <p>where <span class="math">$a \in \mathbb{R}^n$</span> and <span class="math">$\nabla f(a)$</span> is the <strong>gradient</strong> of <span class="math">$f$</span> at <span class="math">$a$</span>, i.e. the vector of partial derivatives in each direction. <span class="math">$\nabla f(a) \cdot \epsilon$</span> is the <strong>directional derivative</strong> of <span class="math">$f$</span> in the direction <span class="math">$\epsilon$</span>.</p> | |
| <p>We now proceed similarly to the univariate case:</p> | |
| <p class="math">\[ | |
| (f + g)(a + \epsilon) = [f(a) + g(a)] + [\nabla f(a) + \nabla g(a)] \cdot \epsilon | |
| \]</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| (f \cdot g)(a + \epsilon) &= [f(a) + \nabla f(a) \cdot \epsilon ] \, [g(a) + \nabla g(a) \cdot \epsilon ] \\ | |
| &= f(a) g(a) + [f(a) \nabla g(a) + g(a) \nabla f(a)] \cdot \epsilon. | |
| \end{align} | |
| \]</p> | |
| <p>We will use the <code>StaticArrays.jl</code> package for efficient small vectors:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-k'>using</span><span class='hljl-t'> </span><span class='hljl-n'>StaticArrays</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>struct</span><span class='hljl-t'> </span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>}</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>val</span><span class='hljl-oB'>::</span><span class='hljl-n'>T</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>derivs</span><span class='hljl-oB'>::</span><span class='hljl-nf'>SVector</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>}</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>import</span><span class='hljl-t'> </span><span class='hljl-n'>Base</span><span class='hljl-oB'>:</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>function</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>},</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>::</span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>})</span><span class='hljl-t'> </span><span class='hljl-n'>where</span><span class='hljl-t'> </span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>}</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>return</span><span class='hljl-t'> </span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>}(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>derivs</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>derivs</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>function</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>::</span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>},</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>::</span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>})</span><span class='hljl-t'> </span><span class='hljl-n'>where</span><span class='hljl-t'> </span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>}</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>return</span><span class='hljl-t'> </span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>{</span><span class='hljl-n'>N</span><span class='hljl-p'>,</span><span class='hljl-n'>T</span><span class='hljl-p'>}(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>.*</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>derivs</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>g</span><span class='hljl-oB'>.</span><span class='hljl-n'>val</span><span class='hljl-t'> </span><span class='hljl-oB'>.*</span><span class='hljl-t'> </span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>derivs</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span> | |
| </pre> | |
| <pre class="output"> | |
| * (generic function with 694 methods) | |
| </pre> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>gg</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-oB'>*</span><span class='hljl-n'>x</span><span class='hljl-oB'>*</span><span class='hljl-n'>y</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-t'> | |
| </span><span class='hljl-p'>(</span><span class='hljl-n'>a</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>b</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-nfB'>1.0</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nfB'>2.0</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>xx</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>(</span><span class='hljl-n'>a</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nf'>SVector</span><span class='hljl-p'>(</span><span class='hljl-nfB'>1.0</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nfB'>0.0</span><span class='hljl-p'>))</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>yy</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>MultiDual</span><span class='hljl-p'>(</span><span class='hljl-n'>b</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nf'>SVector</span><span class='hljl-p'>(</span><span class='hljl-nfB'>0.0</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-nfB'>1.0</span><span class='hljl-p'>))</span><span class='hljl-t'> | |
| </span><span class='hljl-nf'>gg</span><span class='hljl-p'>(</span><span class='hljl-n'>xx</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>yy</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| Main.##WeaveSandBox#1023.MultiDual{2, Float64}(5.0, [5.0, 2.0]) | |
| </pre> | |
| <p>We can calculate the Jacobian of a function <span class="math">$\mathbb{R}^n \to \mathbb{R}^m$</span> by applying this to each component function:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-nf'>ff</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-nf'>SVector</span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-oB'>*</span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-oB'>*</span><span class='hljl-n'>y</span><span class='hljl-t'> </span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-nf'>ff</span><span class='hljl-p'>(</span><span class='hljl-n'>xx</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>yy</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| 2-element SVector{2, Main.##WeaveSandBox#1023.MultiDual{2, Float64}} with i | |
| ndices SOneTo(2): | |
| Main.##WeaveSandBox#1023.MultiDual{2, Float64}(5.0, [2.0, 4.0]) | |
| Main.##WeaveSandBox#1023.MultiDual{2, Float64}(3.0, [1.0, 1.0]) | |
| </pre> | |
| <p>It would be possible (and better for performance in many cases) to store all of the partials in a matrix instead.</p> | |
| <p>Forward-mode AD is implemented in a clean and efficient way in the <code>ForwardDiff.jl</code> package:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-k'>using</span><span class='hljl-t'> </span><span class='hljl-n'>ForwardDiff</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>StaticArrays</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>ForwardDiff</span><span class='hljl-oB'>.</span><span class='hljl-nf'>gradient</span><span class='hljl-p'>(</span><span class='hljl-t'> </span><span class='hljl-n'>xx</span><span class='hljl-t'> </span><span class='hljl-oB'>-></span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-t'> </span><span class='hljl-p'>(</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>xx</span><span class='hljl-p'>;</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-oB'>^</span><span class='hljl-ni'>2</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>y</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-oB'>*</span><span class='hljl-n'>y</span><span class='hljl-t'> </span><span class='hljl-p'>),</span><span class='hljl-t'> </span><span class='hljl-p'>[</span><span class='hljl-ni'>1</span><span class='hljl-p'>,</span><span class='hljl-t'> </span><span class='hljl-ni'>2</span><span class='hljl-p'>])</span> | |
| </pre> | |
| <pre class="output"> | |
| 2-element Vector{Int64}: | |
| 6 | |
| 2 | |
| </pre> | |
| <h2>Directional derivative and gradient of functions <span class="math">$f: \mathbb{R}^n \to \mathbb{R}$</span></h2> | |
| <p>For a function <span class="math">$f: \mathbb{R}^n \to \mathbb{R}$</span> the basic operation is the <strong>directional derivative</strong>:</p> | |
| <p class="math">\[ | |
| \lim_{\epsilon \to 0} \frac{f(\mathbf{x} + \epsilon \mathbf{v}) - f(\mathbf{x})}{\epsilon} = | |
| [\nabla f(\mathbf{x})] \cdot \mathbf{v}, | |
| \]</p> | |
| <p>where <span class="math">$\epsilon$</span> is still a single dimension and <span class="math">$\nabla f(\mathbf{x})$</span> is the direction in which we calculate.</p> | |
| <p>We can directly do this using the same simple <code>Dual</code> numbers as above, using the <em>same</em> <span class="math">$\epsilon$</span>, e.g.</p> | |
| <p class="math">\[ | |
| f(x, y) = x^2 \sin(y) | |
| \]</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| f(x_0 + a\epsilon, y_0 + b\epsilon) &= (x_0 + a\epsilon)^2 \sin(y_0 + b\epsilon) \\ | |
| &= x_0^2 \sin(y_0) + \epsilon[2ax_0 \sin(y_0) + x_0^2 b \cos(y_0)] + o(\epsilon) | |
| \end{align} | |
| \]</p> | |
| <p>so we have indeed calculated <span class="math">$\nabla f(x_0, y_0) \cdot \mathbf{v},$</span> where <span class="math">$\mathbf{v} = (a, b)$</span> are the components that we put into the derivative component of the <code>Dual</code> numbers.</p> | |
| <p>If we wish to calculate the directional derivative in another direction, we could repeat the calculation with a different <span class="math">$\mathbf{v}$</span>. A better solution is to use another independent epsilon <span class="math">$\epsilon$</span>, expanding <span class="math">$x = x_0 + a_1 \epsilon_1 + a_2 \epsilon_2$</span> and putting <span class="math">$\epsilon_1 \epsilon_2 = 0$</span>.</p> | |
| <p>In particular, if we wish to calculate the gradient itself, <span class="math">$\nabla f(x_0, y_0)$</span>, we need to calculate both partial derivatives, which corresponds to two directional derivatives, in the directions <span class="math">$(1, 0)$</span> and <span class="math">$(0, 1)$</span>, respectively.</p> | |
| <h2>Forward-Mode AD as jvp</h2> | |
| <p>Note that another representation of the directional derivative is <span class="math">$f'(x)v$</span>, where <span class="math">$f'(x)$</span> is the Jacobian or total derivative of <span class="math">$f$</span> at <span class="math">$x$</span>. To see the equivalence of this to a directional derivative, first let's see an example:</p> | |
| <p class="math">\[ | |
| \left[\begin{array}{ccc} | |
| \frac{\partial f_{1}}{\partial x_{1}} & \frac{\partial f_{1}}{\partial x_{2}} & \frac{\partial f_{1}}{\partial x_{3}}\\ | |
| \frac{\partial f_{2}}{\partial x_{1}} & \frac{\partial f_{2}}{\partial x_{2}} & \frac{\partial f_{2}}{\partial x_{3}}\\ | |
| \frac{\partial f_{3}}{\partial x_{1}} & \frac{\partial f_{3}}{\partial x_{2}} & \frac{\partial f_{3}}{\partial x_{3}}\\ | |
| \frac{\partial f_{4}}{\partial x_{1}} & \frac{\partial f_{4}}{\partial x_{2}} & \frac{\partial f_{4}}{\partial x_{3}}\\ | |
| \frac{\partial f_{5}}{\partial x_{1}} & \frac{\partial f_{5}}{\partial x_{2}} & \frac{\partial f_{5}}{\partial x_{3}} | |
| \end{array}\right]\left[\begin{array}{c} | |
| v_{1}\\ | |
| v_{2}\\ | |
| v_{3} | |
| \end{array}\right]=\left[\begin{array}{c} | |
| \frac{\partial f_{1}}{\partial x_{1}}v_{1}+\frac{\partial f_{1}}{\partial x_{2}}v_{2}+\frac{\partial f_{1}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{2}}{\partial x_{1}}v_{1}+\frac{\partial f_{2}}{\partial x_{2}}v_{2}+\frac{\partial f_{2}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{3}}{\partial x_{1}}v_{1}+\frac{\partial f_{3}}{\partial x_{2}}v_{2}+\frac{\partial f_{3}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{4}}{\partial x_{1}}v_{1}+\frac{\partial f_{4}}{\partial x_{2}}v_{2}+\frac{\partial f_{4}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{5}}{\partial x_{1}}v_{1}+\frac{\partial f_{5}}{\partial x_{2}}v_{2}+\frac{\partial f_{5}}{\partial x_{3}}v_{3} | |
| \end{array}\right]=\left[\begin{array}{c} | |
| \nabla f_{1}(x)\cdot v\\ | |
| \nabla f_{2}(x)\cdot v\\ | |
| \nabla f_{3}(x)\cdot v\\ | |
| \nabla f_{4}(x)\cdot v\\ | |
| \nabla f_{5}(x)\cdot v | |
| \end{array}\right] | |
| \]</p> | |
| <p>Or more formally, let's write it out in the standard basis:</p> | |
| <p class="math">\[ | |
| w_i = \sum_{j}^{m} J_{ij} v_{j} | |
| \]</p> | |
| <p>Now write out what <span class="math">$J$</span> means and we see that:</p> | |
| <p class="math">\[ | |
| w_i = \sum_j^{m} \frac{df_i}{dx_j} v_j = \nabla f_i(x) \cdot v | |
| \]</p> | |
| <p><strong>The primitive action of forward-mode AD is f'(x)v!</strong></p> | |
| <p>This is also known as a <em>Jacobian-vector product</em>, or <em>jvp</em> for short.</p> | |
| <p>We can thus represent vector calculus with multidimensional dual numbers as follows. Let <span class="math">$d =[x,y]$</span>, the vector of dual numbers. We can instead represent this as:</p> | |
| <p class="math">\[ | |
| d = d_0 + v_1 \epsilon_1 + v_2 \epsilon_2 | |
| \]</p> | |
| <p>where <span class="math">$d_0$</span> is the <em>primal</em> vector <span class="math">$[x_0,y_0]$</span> and the <span class="math">$v_i$</span> are the vectors for the <em>dual</em> directions. If you work out this algebra, then note that a single application of <span class="math">$f$</span> to a multidimensional dual number calculates:</p> | |
| <p class="math">\[ | |
| f(d) = f(d_0) + f'(d_0)v_1 \epsilon_1 + f'(d_0)v_2 \epsilon_2 | |
| \]</p> | |
| <p>i.e. it calculates the result of <span class="math">$f(x,y)$</span> and two separate directional derivatives. Note that because the information about <span class="math">$f(d_0)$</span> is shared between the calculations, this is more efficient than doing multiple applications of <span class="math">$f$</span>. And of course, this is then generalized to <span class="math">$m$</span> many directional derivatives at once by:</p> | |
| <p class="math">\[ | |
| d = d_0 + v_1 \epsilon_1 + v_2 \epsilon_2 + \ldots + v_m \epsilon_m | |
| \]</p> | |
| <h2>Jacobian</h2> | |
| <p>For a function <span class="math">$f: \mathbb{R}^n \to \mathbb{R}^m$</span>, we reduce (conceptually, although not necessarily in code) to its component functions <span class="math">$f_i: \mathbb{R}^n \to \mathbb{R}$</span>, where <span class="math">$f(x) = (f_1(x), f_2(x), \ldots, f_m(x))$</span>.</p> | |
| <p>Then</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| f(x + \epsilon v) &= (f_1(x + \epsilon v), \ldots, f_m(x + \epsilon v)) \\ | |
| &= (f_1(x) + \epsilon[\nabla f_1(x) \cdot v], \dots, f_m(x) + \epsilon[\nabla f_m(x) \cdot v] \\ | |
| &= f(x) + [f'(x) \cdot v] \epsilon, | |
| \end{align} | |
| \]</p> | |
| <p>To calculate the complete Jacobian, we calculate these directional derivatives in the <span class="math">$n$</span> different directions of the basis vectors, i.e. if</p> | |
| <p class="math">\[ | |
| d = d_0 + e_1 \epsilon_1 + \ldots + e_n \epsilon_n | |
| \]</p> | |
| <p>for <span class="math">$e_i$</span> the <span class="math">$i$</span>th basis vector, then</p> | |
| <p class="math">\[ | |
| f(d) = f(d_0) + Je_1 \epsilon_1 + \ldots + Je_n \epsilon_n | |
| \]</p> | |
| <p>computes all columns of the Jacobian simultaniously.</p> | |
| <h2>Forward-Mode Automatic Differentiation for Gradients</h2> | |
| <p>Let's recall the forward-mode method for computing gradients. For an arbitrary nonlinear function <span class="math">$f$</span> with scalar output, we can compute derivatives by putting a dual number in. For example, with</p> | |
| <p class="math">\[ | |
| d = d_0 + v_1 \epsilon_1 + \ldots + v_m \epsilon_m | |
| \]</p> | |
| <p>we have that</p> | |
| <p class="math">\[ | |
| f(d) = f(d_0) + f'(d_0)v_1 \epsilon_1 + \ldots + f'(d_0)v_m \epsilon_m | |
| \]</p> | |
| <p>where <span class="math">$f'(d_0)v_i$</span> is the direction derivative in the direction of <span class="math">$v_i$</span>. To compute the gradient with respond to the input, we thus need to make <span class="math">$v_i = e_i$</span>.</p> | |
| <p>However, in this case we now do not want to compute the derivative with respect to the input! Instead, now we have <span class="math">$f(x;p)$</span> and want to compute the derivatives with respect to <span class="math">$p$</span>. This simply means that we want to take derivatives in the directions of the parameters. To do this, let:</p> | |
| <p class="math">\[ | |
| x = x_0 + 0 \epsilon_1 + \ldots + 0 \epsilon_k | |
| \]</p> | |
| <p class="math">\[ | |
| P = p + e_1 \epsilon_1 + \ldots + e_k \epsilon_k | |
| \]</p> | |
| <p>where there are <span class="math">$k$</span> parameters. We then have that</p> | |
| <p class="math">\[ | |
| f(x;P) = f(x;p) + \frac{df}{dp_1} \epsilon_1 + \ldots + \frac{df}{dp_k} \epsilon_k | |
| \]</p> | |
| <p>as the output, and thus a <span class="math">$k+1$</span>-dimensional number computes the gradient of the function with respect to <span class="math">$k$</span> parameters.</p> | |
| <p>Can we do better?</p> | |
| <h1>Reverse-Mode Automatic Differentiation</h1> | |
| <p>The fast method for computing gradients goes under many times. The <em>adjoint technique</em>, <em>backpropogation</em>, and <em>reverse-mode automatic differentiation</em> are in some sense all equivalent phrases given to this method from different disciplines. To understand this technique, first let's understand programs <span class="math">$f$</span> as a composition of <span class="math">$L$</span> functions:</p> | |
| <p class="math">\[ | |
| f = f^L \circ f^{L-1} \circ \ldots \circ f^1 | |
| \]</p> | |
| <p>This should be intuitive because a program is just breaking down the steps of a calculation, like:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-ni'>5</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-ni'>2</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>y</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-ni'>3</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>z</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>^</span><span class='hljl-t'> </span><span class='hljl-n'>y</span> | |
| </pre> | |
| <pre class="output"> | |
| 558545864083284007 | |
| </pre> | |
| <p>could have simply been written as:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-p'>(</span><span class='hljl-ni'>5</span><span class='hljl-oB'>+</span><span class='hljl-ni'>2</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>^</span><span class='hljl-t'> </span><span class='hljl-p'>((</span><span class='hljl-ni'>5</span><span class='hljl-oB'>+</span><span class='hljl-ni'>2</span><span class='hljl-p'>)</span><span class='hljl-oB'>*</span><span class='hljl-ni'>3</span><span class='hljl-p'>)</span> | |
| </pre> | |
| <pre class="output"> | |
| 558545864083284007 | |
| </pre> | |
| <p>Composing the assignment statements together gives the mathematical form of the function as a composition of the intermediate calculations. Now if <span class="math">$f$</span> is</p> | |
| <p class="math">\[ | |
| f = f^L \circ f^{L-1} \circ \ldots \circ f^1 | |
| \]</p> | |
| <p>then the Jacobian matrix satisfies:</p> | |
| <p class="math">\[ | |
| J = J_L J_{L-1} \ldots J_1 | |
| \]</p> | |
| <p>This fact is just another way of writing the chain rule:</p> | |
| <p class="math">\[ | |
| (g(f(x)))' = g'(f(x))*f'(x) = J_2 * J_1 | |
| \]</p> | |
| <p>Forward-mode automatic differentiation worked by propogating forward the actions of the Jacobians at every step of the program:</p> | |
| <p class="math">\[ | |
| Jv = J_L (J_{L-1} (\ldots (J_1 v) \ldots )) | |
| \]</p> | |
| <p>effectively calculating the Jacobian of the program by multiplying by the Jacobians from left to right at each step of the way. This means doing primitive <span class="math">$Jv$</span> calculations on each underlying problem, and pushing that calculation through. When the primitive of a function was unknown, one would dig into how that function was defined, recursively, until primitive derivative definitions were known and used to define the dual part. Thus primitives defined how deep into a calculation one would look for an analytical solution to <span class="math">$J_i v$</span>, and then the automatic differentiation engine would simply chain together these Jacobian-vector products.</p> | |
| <p>Forward-mode accumulation was good because <span class="math">$Jv$</span> directly calculated the directional derivative, which is also seen as the columns of the Jacobian (in a chosen basis). However, the key to understanding reverse-mode automatic differentiation is to see that <strong>gradients are the rows of the Jacobian</strong>. Let's see this in an example:</p> | |
| <p class="math">\[ | |
| \left[\begin{array}{ccccc} | |
| 0 & 1 & 0 & 0 & 0\end{array}\right]\left[\begin{array}{ccc} | |
| \frac{\partial f_{1}}{\partial x_{1}} & \frac{\partial f_{1}}{\partial x_{2}} & \frac{\partial f_{1}}{\partial x_{3}}\\ | |
| \frac{\partial f_{2}}{\partial x_{1}} & \frac{\partial f_{2}}{\partial x_{2}} & \frac{\partial f_{2}}{\partial x_{3}}\\ | |
| \frac{\partial f_{3}}{\partial x_{1}} & \frac{\partial f_{3}}{\partial x_{2}} & \frac{\partial f_{3}}{\partial x_{3}}\\ | |
| \frac{\partial f_{4}}{\partial x_{1}} & \frac{\partial f_{4}}{\partial x_{2}} & \frac{\partial f_{4}}{\partial x_{3}}\\ | |
| \frac{\partial f_{5}}{\partial x_{1}} & \frac{\partial f_{5}}{\partial x_{2}} & \frac{\partial f_{5}}{\partial x_{3}} | |
| \end{array}\right]=\left[\begin{array}{ccc} | |
| \frac{\partial f_{2}}{\partial x_{1}} & \frac{\partial f_{2}}{\partial x_{2}} & \frac{\partial f_{2}}{\partial x_{3}}\end{array}\right]=\nabla f_{2}(x) | |
| \]</p> | |
| <p>Notice that multiplying by a row vector <code>[0 1 0 0 0]</code> pulls out the second row of the Jacobian, which pulls out the gradient of the second component of the multi-output function. If <code>f(x)</code> is a function that returned a scalar, <code>[1] * J</code> would give <span class="math">$\nabla f(x)$</span>. Thus if we want to calculate gradients fast, we need to do automatic differentiation in a way that computes one row at a time, not one column at a time, and for scalar outputs then the gradient can be calculated in O(1) time instead of O(n)!</p> | |
| <p>However, this matrix calculus understanding of reverse-mode automatic differentiation directly describes how it gets its name. We can thus think of this as a different direction for the Jacobian accumulation. Let's see what happens when we left apply a row vector to the Jacobian, but recurse down to the component <span class="math">$J_i$</span> pieces of a composed function:</p> | |
| <p class="math">\[ | |
| v^T J = (\ldots ((v^T J_L) J_{L-1}) \ldots ) J_1 | |
| \]</p> | |
| <p>Multiplying on the right does <span class="math">$J_1 v$</span> first, while multiplying on the left requires doing <span class="math">$v^T J_L$</span> first. This means <strong>in order to do this calcaultion, the derivative must be computed in reverse starting from the end</strong>, giving rise to the name reverse-mode AD. We must chain together vector-Jacobian product, or <strong>vjp</strong> calculations from the last step of the calculation to the previous all the way back to the start.</p> | |
| <h2>Quick note on notation</h2> | |
| <p>Some people write reverse-mode AD as the <span class="math">$J^T v$</span> action, but you can also see this implies reverse accumulation by the properties of the transpose since</p> | |
| <p class="math">\[ | |
| J^T v = (J_L J_{L-1} \ldots J_1)^T v = (J_1^T J_{2}^T \ldots J_L^T )v | |
| \]</p> | |
| <p>the transpose reverses the order of multiplication.</p> | |
| <p>Okay, now let's figure out how to do the calculation in this style.</p> | |
| <h2>Reverse-Mode of a Neural Network</h2> | |
| <p>Let's do reverse-mode automatic differentiation fo the following function:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| z &= W_1 x + b_1\\ | |
| h &= \sigma(z)\\ | |
| y &= W_2 h + b_2\\ | |
| \mathcal{L} &= \frac{1}{2} \Vert y-t \Vert^2 \end{align} | |
| \]</p> | |
| <p>where we call <span class="math">$f(x) = L$</span>. To simplify our notation, let's write for <span class="math">$y = f(x)$</span> the simplification:</p> | |
| <p class="math">\[ | |
| \overline{x} = [\frac{\partial f}{\partial x}]^T v | |
| \]</p> | |
| <p>The reason is because we want to encode the successive "<span class="math">$J'v$</span> of last time" expressions. To calculate <span class="math">$f'(x)^T v$</span> we decompose it into steps <span class="math">$(J_1^T J_{2}^T \ldots J_L^T )v$</span>, or:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{L} &= v\\ | |
| \overline{y} &= [\frac{\partial (\frac{1}{2} \Vert y-t \Vert^2)}{\partial y}]^T \overline{L} = (y-t)^T v\\ | |
| \overline{h} &= [\frac{\partial (W_2 h + b_2)}{\partial h}]^T \overline{y} = W_2^T \overline{y}\\ | |
| \overline{z} &= [\frac{\partial \sigma(z)}{\partial z}]^T \overline{h} = \sigma^\prime(z)^T \overline{h}\\ | |
| \overline{x} &= [\frac{\partial W_1 x + b_1}{\partial x}]^T \overline{z} = W_1^T \overline{z}\\ | |
| \end{align} | |
| \]</p> | |
| <p>(note that since <span class="math">$L$</span> is a scalar, <span class="math">$v$</span> is a scalar here so we don't really need to transpose, that's more to show form). Or, in order to calculate <span class="math">$f'(x)^T v$</span>, we do this by calculating:</p> | |
| <p class="math">\[ | |
| J^T v = (W_1^T \sigma^\prime(z)^T W_2^T (y-t)^T) v | |
| \]</p> | |
| <p>and if <span class="math">$v=1$</span> then we receive the gradient of the neural network with respect to <span class="math">$x$</span>.</p> | |
| <h2>Primitives of Reverse Mode</h2> | |
| <p>For forward-mode AD, we saw that we could define primitives in order to accelerate the calculation. For example, knowing that</p> | |
| <p class="math">\[ | |
| exp(x+\epsilon) = exp(x) + exp(x)\epsilon | |
| \]</p> | |
| <p>allows the program to skip autodifferentiating through the code for <code>exp</code>. This was simple with forward-mode since we could represent the operation on a Dual number. What's the equivalent for reverse-mode AD? The answer is the <em>pullback</em> function. If <span class="math">$y = [y_1,y_2,\ldots] = f(x_1,x_2, \ldots)$</span>, then <span class="math">$[\overline{x_1},\overline{x_2},\ldots]=\mathcal{B}_f^x(\overline{y})$</span> is the pullback of <span class="math">$f$</span> at the point <span class="math">$x$</span>, defined for a scalar loss function <span class="math">$L(y)$</span> as:</p> | |
| <p class="math">\[ | |
| \overline{x_i} = \frac{\partial L}{\partial x} = \sum_i \frac{\partial L}{\partial y_i} \frac{\partial y_i}{\partial x_i} | |
| \]</p> | |
| <p>Using the notation from earlier, <span class="math">$\overline{y} = \frac{\partial L}{\partial y}$</span> is the derivative of the some intermediate w.r.t. the cost function, and thus</p> | |
| <p class="math">\[ | |
| \overline{x_i} = \sum_i \overline{y_i} \frac{\partial y_i}{\partial x_i} = \mathcal{B}_f^x(\overline{y}) | |
| \]</p> | |
| <p>Note that <span class="math">$\mathcal{B}_f^x(\overline{y})$</span> is a function of <span class="math">$x$</span> because the reverse pass that is use embeds values from the forward pass, and the values from the forward pass to use are those calculated during the evaluation of <span class="math">$f(x)$</span>.</p> | |
| <p>By the chain rule, if we don't have a primitive defined for <span class="math">$y_i(x)$</span>, we can compute that by <span class="math">$\mathcal{B}_{y_i}(\overline{y})$</span>, and recursively apply this process until we hit rules that we know. The rules to start with are the scalar derivative rules with follow quite simply, and the multivariate rules which we derived above. For example, if <span class="math">$y=f(x)=Ax$</span>, then</p> | |
| <p class="math">\[ | |
| \mathcal{B}_{f}^x(\overline{y}) = \overline{y}^T A | |
| \]</p> | |
| <p>which is simply saying that the Jacobian of <span class="math">$f$</span> at <span class="math">$x$</span> is <span class="math">$A$</span>, and so the vjp is to multiply the vector transpose by <span class="math">$A$</span>.</p> | |
| <p>Likewise, for element-wise operations, the Jacobian is diagonal, and thus the vjp is multiplying once again by a diagonal matrix against the derivative, deriving the same pullback as we had for backpropogation in a neural network. This then is a quicker encoding and derivation of backpropogation.</p> | |
| <h2>Example of a Reverse-Mode AD Primitive</h2> | |
| <p>Let's write down the reverse-mode primitive for <span class="math">$y = \sigma(Wx + b)$</span>. Doing as we showed before, we break down the steps of the computation and write the <span class="math">$J'v$</span> one step at a time until we get back to the start:</p> | |
| <pre class='hljl'> | |
| <span class='hljl-k'>using</span><span class='hljl-t'> </span><span class='hljl-n'>ChainRules</span><span class='hljl-t'> | |
| </span><span class='hljl-nf'>nndense</span><span class='hljl-p'>(</span><span class='hljl-n'>W</span><span class='hljl-p'>,</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-n'>b</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>σ</span><span class='hljl-oB'>.</span><span class='hljl-p'>(</span><span class='hljl-n'>W</span><span class='hljl-oB'>*</span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>+</span><span class='hljl-t'> </span><span class='hljl-n'>b</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>function</span><span class='hljl-t'> </span><span class='hljl-n'>ChainRules</span><span class='hljl-oB'>.</span><span class='hljl-nf'>rrule</span><span class='hljl-p'>(</span><span class='hljl-oB'>::</span><span class='hljl-nf'>typeof</span><span class='hljl-p'>(</span><span class='hljl-n'>nndense</span><span class='hljl-p'>),</span><span class='hljl-t'> </span><span class='hljl-n'>W</span><span class='hljl-p'>,</span><span class='hljl-n'>x</span><span class='hljl-p'>,</span><span class='hljl-n'>b</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>r</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>W</span><span class='hljl-oB'>*</span><span class='hljl-n'>x</span><span class='hljl-t'> </span><span class='hljl-oB'>.+</span><span class='hljl-t'> </span><span class='hljl-n'>b</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>y</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>σ</span><span class='hljl-oB'>.</span><span class='hljl-p'>(</span><span class='hljl-n'>r</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>function</span><span class='hljl-t'> </span><span class='hljl-nf'>adjoint</span><span class='hljl-p'>(</span><span class='hljl-n'>v</span><span class='hljl-p'>)</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>zbar</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>ForwardDiff</span><span class='hljl-oB'>.</span><span class='hljl-n'>derivative</span><span class='hljl-oB'>.</span><span class='hljl-p'>(</span><span class='hljl-n'>f</span><span class='hljl-oB'>.</span><span class='hljl-n'>σ</span><span class='hljl-p'>,</span><span class='hljl-n'>r</span><span class='hljl-p'>)</span><span class='hljl-t'> </span><span class='hljl-oB'>.*</span><span class='hljl-t'> </span><span class='hljl-n'>v</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>xbar</span><span class='hljl-t'> </span><span class='hljl-oB'>=</span><span class='hljl-t'> </span><span class='hljl-n'>W</span><span class='hljl-oB'>'</span><span class='hljl-t'> </span><span class='hljl-oB'>*</span><span class='hljl-t'> </span><span class='hljl-n'>zbar</span><span class='hljl-t'> | |
| </span><span class='hljl-nf'>NoTangent</span><span class='hljl-p'>(),</span><span class='hljl-nf'>NotImplemented</span><span class='hljl-p'>(),</span><span class='hljl-n'>xbar</span><span class='hljl-p'>,</span><span class='hljl-nf'>NotImplemented</span><span class='hljl-p'>()</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span><span class='hljl-t'> | |
| </span><span class='hljl-n'>y</span><span class='hljl-p'>,</span><span class='hljl-n'>adjoint</span><span class='hljl-t'> | |
| </span><span class='hljl-k'>end</span> | |
| </pre> | |
| <p>The homework will be to figure out how to calculate <code>Wbar</code> and <code>bbar</code>!</p> | |
| <h2>Forward Mode vs Reverse Mode Efficiency</h2> | |
| <p>Notice that a pullback of a single scalar gives the gradient of a function, while the <em>pushforward</em> using forward-mode of a dual gives a directional derivative. Forward mode computes columns of a Jacobian, while reverse mode computes gradients (rows of a Jacobian). Therefore, the relative efficiency of the two approaches is based on the size of the Jacobian. If <span class="math">$f:\mathbb{R}^n \rightarrow \mathbb{R}^m$</span>, then the Jacobian is of size <span class="math">$m \times n$</span>. If <span class="math">$m$</span> is much smaller than <span class="math">$n$</span>, then computing by each row will be faster, and thus use reverse mode. In the case of a gradient, <span class="math">$m=1$</span> while <span class="math">$n$</span> can be large, leading to this phonomena. Likewise, if <span class="math">$n$</span> is much smaller than <span class="math">$m$</span>, then computing by each column will be faster. We will see shortly the reverse mode AD has a high overhead with respect to forward mode, and thus if the values are relatively equal (or <span class="math">$n$</span> and <span class="math">$m$</span> are small), forward mode is more efficient.</p> | |
| <p>However, since optimization needs gradients, reverse-mode definitely has a place in the standard toolchain which is why backpropagation is so central to machine learning. <strong>But this does not mean that reverse-mode AD is "faster", in fact for square matrices it's usually slower!</strong>.</p> | |
| <h1>Extra: Reverse-Mode Automatic Differentiation on Computation Graphs</h1> | |
| <p>Most lecture notes will show reverse-mode automatic differentiation on computation graphs as the core way to do the calculation because they want to avoid matrix calculus. The following walks through that approach to show how it's a very tedious way to derive the same results.</p> | |
| <h2>Adjoints and Reverse-Mode AD through Computation Graphs</h2> | |
| <p>Let's look at the multivariate chain rule on a <em>computation graph</em>. Recall that for <span class="math">$f(x(t),y(t))$</span> that we have:</p> | |
| <p class="math">\[ | |
| \frac{df}{dt} = \frac{df}{dx}\frac{dx}{dt} + \frac{df}{dy}\frac{dy}{dt} | |
| \]</p> | |
| <p>We can visualize our direct dependences as the computation graph:</p> | |
| <p><img src="https://user-images.githubusercontent.com/1814174/66461367-e3162380-ea46-11e9-8e80-09b32e138269.PNG" alt="" /></p> | |
| <p>i.e. <span class="math">$t$</span> directly determines <span class="math">$x$</span> and <span class="math">$y$</span> which then determines <span class="math">$f$</span>. To calculate Assume you've already evaluated <span class="math">$f(t)$</span>. If this has been done, then you've already had to calculate <span class="math">$x$</span> and <span class="math">$y$</span>. Thus given the function <span class="math">$f$</span>, we can now calculate <span class="math">$\frac{df}{dx}$</span> and <span class="math">$\frac{df}{dy}$</span>, and then calculate <span class="math">$\frac{dx}{dt}$</span> and <span class="math">$\frac{dy}{dt}$</span>.</p> | |
| <p>Now let's put another layer in the computation. Let's make <span class="math">$f(x(v(t),w(t)),y(v(t),w(t))$</span>. We can write out the full expression for the derivative. Notice that even with this additional layer, the statement we wrote above still holds:</p> | |
| <p class="math">\[ | |
| \frac{df}{dt} = \frac{df}{dx}\frac{dx}{dt} + \frac{df}{dy}\frac{dy}{dt} | |
| \]</p> | |
| <p>So given an evaluation of <span class="math">$f$</span>, we can (still) directly calculate <span class="math">$\frac{df}{dx}$</span> and <span class="math">$\frac{df}{dy}$</span>. But now, to calculate <span class="math">$\frac{dx}{dt}$</span> and <span class="math">$\frac{dy}{dt}$</span>, we do the next step of the chain rule:</p> | |
| <p class="math">\[ | |
| \frac{dx}{dt} = \frac{dx}{dv}\frac{dv}{dt} + \frac{dx}{dw}\frac{dw}{dt} | |
| \]</p> | |
| <p>and similar for <span class="math">$y$</span>. So plug it all in, and you see that our equations will grow wild if we actually try to plug it in! But it's clear that, to calculate <span class="math">$\frac{df}{dt}$</span>, we can first calculate <span class="math">$\frac{df}{dx}$</span>, and then multiply that to <span class="math">$\frac{dx}{dt}$</span>. If we had more layers, we could calculate the <em>sensitivity</em> (the derivative) of the output to the last layer, then and then the sensitivity to the second layer back is the sensitivity of the last layer multiplied to that, and the third layer back has the sensitivity of the second layer multiplied to it!</p> | |
| <h2>Logistic Regression Example</h2> | |
| <p>To better see this structure, let's write out a simple example. Let our <em>forward pass</em> through our function be:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| z &= wx + b\\ | |
| y &= \sigma(z)\\ | |
| \mathcal{L} &= \frac{1}{2}(y-t)^2\\ | |
| \mathcal{R} &= \frac{1}{2}w^2\\ | |
| \mathcal{L}_{reg} &= \mathcal{L} + \lambda \mathcal{R}\end{align} | |
| \]</p> | |
| <p><img src="https://user-images.githubusercontent.com/1814174/66462825-e2cb5780-ea49-11e9-9804-240037fb6b56.PNG" alt="" /></p> | |
| <p>The formulation of the program here is called a <em>Wengert list, tape, or graph</em>. In this, <span class="math">$x$</span> and <span class="math">$t$</span> are inputs, <span class="math">$b$</span> and <span class="math">$W$</span> are parameters, <span class="math">$z$</span>, <span class="math">$y$</span>, <span class="math">$\mathcal{L}$</span>, and <span class="math">$\mathcal{R}$</span> are intermediates, and <span class="math">$\mathcal{L}_{reg}$</span> is our output.</p> | |
| <p>This is a simple univariate logistic regression model. To do logistic regression, we wish to find the parameters <span class="math">$w$</span> and <span class="math">$b$</span> which minimize the distance of <span class="math">$\mathcal{L}_{reg}$</span> from a desired output, which is done by computing derivatives.</p> | |
| <p>Let's calculate the derivatives with respect to each quantity in reverse order. If our program is <span class="math">$f(x) = \mathcal{L}_{reg}$</span>, then we have that</p> | |
| <p class="math">\[ | |
| \frac{df}{\mathcal{L}_{reg}} = 1 | |
| \]</p> | |
| <p>as the derivatives of the last layer. To computerize our notation, let's write</p> | |
| <p class="math">\[ | |
| \overline{\mathcal{L}_{reg}} = \frac{df}{\mathcal{L}_{reg}} | |
| \]</p> | |
| <p>for our computed values. For the derivatives of the second to last layer, we have that:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{\mathcal{R}} &= \frac{df}{\mathcal{L}_{reg}} \frac{d\mathcal{L}_{reg}}{\mathcal{R}}\\ | |
| &= \overline{\mathcal{L}_{reg}} \lambda \end{align} | |
| \]</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{\mathcal{L}} &= \frac{df}{\mathcal{L}_{reg}} \frac{d\mathcal{L}_{reg}}{\mathcal{L}}\\ | |
| &= \overline{\mathcal{L}_{reg}} \end{align} | |
| \]</p> | |
| <p>This was our observation from before that the derivative of the second layer is the partial derivative of the current values times the sensitivity of the final layer. And then we keep multiplying, so now for our next layer we have that:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{y} &= \overline{\mathcal{L}} \frac{d\mathcal{L}}{dy}\\ | |
| &= \overline{\mathcal{L}} (y-t) \end{align} | |
| \]</p> | |
| <p>And notice that the chain rule holds since <span class="math">$\overline{\mathcal{L}}$</span> implicitly already has the multiplication by <span class="math">$\overline{\mathcal{L}_{reg}}$</span> inside of it. Then the next layer is:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \frac{df}{z} &= \overline{y} \frac{dy}{dz}\\ | |
| &= \overline{y} \sigma^\prime(z) \end{align} | |
| \]</p> | |
| <p>Then the next layer. Notice that here, by the chain rule on <span class="math">$w$</span> we have that:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{w} &= \overline{z} \frac{\partial z}{\partial w} + \overline{\mathcal{R}} \frac{d \mathcal{R}}{dw}\\ | |
| &= \overline{z} x + \overline{\mathcal{R}} w\end{align} | |
| \]</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{b} &= \overline{z} \frac{\partial z}{\partial b}\\ | |
| &= \overline{z} \end{align} | |
| \]</p> | |
| <p>This completely calculates all derivatives. In conclusion, the rule is:</p> | |
| <ul> | |
| <li><p>You sum terms from each outward arrow</p> | |
| </li> | |
| <li><p>Each arrow has the derivative term of the end times the partial of the current term.</p> | |
| </li> | |
| <li><p>Recurse backwards to build simple linear combination expressions.</p> | |
| </li> | |
| </ul> | |
| <h3>Quick note</h3> | |
| <p>We started this derivation with</p> | |
| <p class="math">\[ | |
| \frac{df}{\mathcal{L}_{reg}} = 1 | |
| \]</p> | |
| <p>and we then get out <span class="math">$\nabla f(x)$</span>, but from our discussion before this is simply <code>[1]' J</code>. Thus while we have a (flaky) justification for making this value <code>1</code>, it's really just the choice of <span class="math">$v$</span>! Thus doing</p> | |
| <p class="math">\[ | |
| \frac{df}{\mathcal{L}_{reg}} = v | |
| \]</p> | |
| <p>will make this process compute <span class="math">$v^T J$</span> for this <span class="math">$f$</span>.</p> | |
| <h2>Backpropogation of a Neural Network</h2> | |
| <p>Now let's look at backpropgation of a deep neural network. Before getting to it in the linear algebraic sense, let's write everything in terms of scalars. This means we can write a simple neural network as:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| z_i &= \sum_j W_{ij}^1 x_j + b_i^1\\ | |
| h_i &= \sigma(z_i)\\ | |
| y_i &= \sum_j W_{ij}^2 h_j + b_i^2\\ | |
| \mathcal{L} &= \frac{1}{2} \sum_k \left(y_k - t_k \right)^2 \end{align} | |
| \]</p> | |
| <p>where I have chosen the L2 loss function. This is visualized by the computational graph:</p> | |
| <p><img src="https://user-images.githubusercontent.com/1814174/66464817-ad286d80-ea4d-11e9-9a4c-f7bcf1b34475.PNG" alt="" /></p> | |
| <p>Then we can do the same process as before to get:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{\mathcal{L}} &= 1\\ | |
| \overline{y_i} &= \overline{\mathcal{L}} (y_i - t_i)\\ | |
| \overline{w_{ij}^2} &= \overline{y_i} h_j\\ | |
| \overline{b_i^2} &= \overline{y_i}\\ | |
| \overline{h_i} &= \sum_k (\overline{y_k}w_{ki}^2)\\ | |
| \overline{z_i} &= \overline{h_i}\sigma^\prime(z_i)\\ | |
| \overline{w_{ij}^1} &= \overline{z_i} x_j\\ | |
| \overline{b_i^1} &= \overline{z_i}\end{align} | |
| \]</p> | |
| <p>just by examining the computation graph. Now let's write this in linear algebraic form.</p> | |
| <p><img src="https://user-images.githubusercontent.com/1814174/66465741-69366800-ea4f-11e9-9c20-07806214008b.PNG" alt="" /></p> | |
| <p>The forward pass for this simple neural network was:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| z &= W_1 x + b_1\\ | |
| h &= \sigma(z)\\ | |
| y &= W_2 h + b_2\\ | |
| \mathcal{L} = \frac{1}{2} \Vert y-t \Vert^2 \end{align} | |
| \]</p> | |
| <p>If we carefully decode our scalar expression, we see that we get the following:</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{\mathcal{L}} &= 1\\ | |
| \overline{y} &= \overline{\mathcal{L}}(y-t)\\ | |
| \overline{W_2} &= \overline{y}h^{T}\\ | |
| \overline{b_2} &= \overline{y}\\ | |
| \overline{h} &= W_2^T \overline{y}\\ | |
| \overline{z} &= \overline{h} .* \sigma^\prime(z)\\ | |
| \overline{W_1} &= \overline{z} x^T\\ | |
| \overline{b_1} &= \overline{z} \end{align} | |
| \]</p> | |
| <p>We can thus decode the rules as:</p> | |
| <ul> | |
| <li><p>Multiplying by the matrix going forwards means multiplying by the transpose going backwards. A term on the left stays on the left, and a term on the right stays on the right.</p> | |
| </li> | |
| <li><p>Element-wise operations give element-wise multiplication</p> | |
| </li> | |
| </ul> | |
| <p>Notice that the summation is then easily encoded into this rule by the transpose operation.</p> | |
| <p>We can write it in the general DNN form of:</p> | |
| <p class="math">\[ | |
| r_i = W_i v_{i} + b_i | |
| \]</p> | |
| <p class="math">\[ | |
| v_{i+1} = \sigma_i.(r_i) | |
| \]</p> | |
| <p class="math">\[ | |
| v_1 = x | |
| \]</p> | |
| <p class="math">\[ | |
| \mathcal{L} = \frac{1}{2} \Vert v_{n} - t \Vert | |
| \]</p> | |
| <p class="math">\[ | |
| \begin{align} | |
| \overline{\mathcal{L}} &= 1\\ | |
| \overline{v_n} &= \overline{\mathcal{L}}(y-t)\\ | |
| \overline{r_i} &= \overline{v_i} .* \sigma_i^\prime (r_i)\\ | |
| \overline{W_i} &= \overline{v_i}r_{i-1}^{T}\\ | |
| \overline{b_i} &= \overline{v_i}\\ | |
| \overline{v_{i-1}} &= W_{i}^{T} \overline{v_i} \end{align} | |
| \]</p> | |
| <h2>References</h2> | |
| <ul> | |
| <li><p>John L. Bell, <em>An Invitation to Smooth Infinitesimal Analysis</em>, http://publish.uwo.ca/~jbell/invitation%20to%20SIA.pdf</p> | |
| </li> | |
| <li><p>Bell, John L. <em>A Primer of Infinitesimal Analysis</em></p> | |
| </li> | |
| <li><p>Nocedal & Wright, <em>Numerical Optimization</em>, Chapter 8</p> | |
| </li> | |
| <li><p>Griewank & Walther, <em>Evaluating Derivatives</em></p> | |
| </li> | |
| </ul> | |
| <HR/> | |
| <div class="footer"> | |
| <p> | |
| Published from <a href="automatic_differentiation_done_quick.jmd">automatic_differentiation_done_quick.jmd</a> | |
| using <a href="http://github.com/JunoLab/Weave.jl">Weave.jl</a> v0.10.10 on 2022-01-21. | |
| </p> | |
| </div> | |
| </div> | |
| </div> | |
| </div> | |
| </BODY> | |
| </HTML> |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| --- | |
| title: Forward and Reverse Automatic Differentiation In A Nutshell | |
| author: Chris Rackauckas | |
| date: January 21st, 2022 | |
| --- | |
| # Machine Epsilon and Roundoff Error | |
| Floating point arithmetic is relatively scaled, which means that the precision | |
| that you get from calculations is relative to the size of the floating point | |
| numbers. Generally, you have 16 digits of accuracy in (64-bit) floating | |
| point operations. To measure this, we define *machine epsilon* as the value | |
| by which `1 + E = 1`. For floating point numbers, this is: | |
| ```julia | |
| eps(Float64) | |
| ``` | |
| However, since it's relative, this value changes as we change our reference value: | |
| ```julia | |
| @show eps(1.0) | |
| @show eps(0.1) | |
| @show eps(0.01) | |
| ``` | |
| Thus issues with *roundoff error* come when one subtracts out the higher digits. | |
| For example, $(x + \epsilon) - x$ should just be $\epsilon$ if there was no | |
| roundoff error, but if $\epsilon$ is small then this kicks in. If $x = 1$ | |
| and $\epsilon$ is of size around $10^{-10}$, then $x+ \epsilon$ is correct for | |
| 10 digits, dropping off the smallest 6 due to error in the addition to $1$. | |
| But when you subtract off $x$, you don't get those digits back, and thus you | |
| only have 6 digits of $\epsilon$ correct. | |
| Let's see this in action: | |
| ```julia | |
| ϵ = 1e-10rand() | |
| @show ϵ | |
| @show (1+ϵ) | |
| ϵ2 = (1+ϵ) - 1 | |
| (ϵ - ϵ2) | |
| ``` | |
| See how $\epsilon$ is only rebuilt at accuracy around $10^{-16}$ and thus we only | |
| keep around 6 digits of accuracy when it's generated at the size of around $10^{-10}$! | |
| ## Finite Differencing and Numerical Stability | |
| To start understanding how to compute derivatives on a computer, we start with | |
| *finite differencing*. For finite differencing, recall that the definition of | |
| the derivative is: | |
| $$f'(x) = \lim_{\epsilon \rightarrow 0} \frac{f(x+\epsilon)-f(x)}{\epsilon}$$ | |
| Finite differencing directly follows from this definition by choosing a small | |
| $\epsilon$. However, choosing a good $\epsilon$ is very difficult. If $\epsilon$ | |
| is too large than there is error since this definition is asymtopic. However, | |
| if $\epsilon$ is too small, you receive roundoff error. To understand why | |
| you would get roundoff error, recall that floating point error is relative, | |
| and can essentially store 16 digits of accuracy. So let's say we choose | |
| $\epsilon = 10^{-6}$. Then $f(x+\epsilon) - f(x)$ is roughly the same in the | |
| first 6 digits, meaning that after the subtraction there is only 10 digits of | |
| accuracy, and then dividing by $10^{-6}$ simply brings those 10 digits back up | |
| to the correct relative size. | |
|  | |
| This means that we want to choose $\epsilon$ small enough that the | |
| $\mathcal{O}(\epsilon^2)$ error of the truncation is balanced by the $O(1/\epsilon)$ | |
| roundoff error. Under some minor assumptions, one can argue that the average | |
| best point is $\sqrt(E)$, where E is machine epsilon | |
| ```julia | |
| @show eps(Float64) | |
| @show sqrt(eps(Float64)) | |
| ``` | |
| This means we should not expect better than 8 digits of accuracy, even when | |
| things are good with finite differencing. | |
|  | |
| The centered difference formula is a little bit better, but this picture | |
| suggests something much better... | |
| ## Differencing in a Different Dimension: Complex Step Differentiation | |
| The problem with finite differencing is that we are mixing our really small | |
| number with the really large number, and so when we do the subtract we lose | |
| accuracy. Instead, we want to keep the small perturbation completely separate. | |
| To see how to do this, assume that $x \in \mathbb{R}$ and assume that $f$ is | |
| complex analytic. You want to calculate a real derivative, but your function | |
| just happens to also be complex analytic when extended to the complex plane. | |
| Thus it has a Taylor series, and let's see what happens when we expand out this | |
| Taylor series purely in the complex direction: | |
| $$f(x+ih) = f(x) + f'(x)ih + \mathcal{O}(h^2)$$ | |
| which we can re-arrange as: | |
| $$if'(x) = \frac{f(x+ih) - f(x)}{h} + \mathcal{O}(h)$$ | |
| Since $x$ is real and $f$ is real-valued on the reals, $if'$ is purely imaginary. | |
| So let's take the imaginary parts of both sides: | |
| $$f'(x) = \frac{Im(f(x+ih))}{h} + \mathcal{O}(h)$$ | |
| since $Im(f(x)) = 0$ (since it's real valued!). Thus with a sufficiently small | |
| choice of $h$, this is the *complex step differentiation* formula for calculating | |
| the derivative. | |
| But to understand the computational advantage, recal that $x$ is pure real, and | |
| thus $x+ih$ is an imaginary number where **the $h$ never directly interacts with | |
| $x$** since a complex number is a two dimensional number where you keep the two | |
| pieces separate. Thus there is no numerical cancellation by using a small value | |
| of $h$, and thus, due to the relative precision of floating point numbers, both | |
| the real and imaginary parts will be computed to (approximately) 16 digits of | |
| accuracy for any choice of $h$. | |
| ## Derivatives as nilpotent sensitivities | |
| The derivative measures the **sensitivity** of a function, i.e. how much the | |
| function output changes when the input changes by a small amount $\epsilon$: | |
| $$f(a + \epsilon) = f(a) + f'(a) \epsilon + o(\epsilon).$$ | |
| In the following we will ignore higher-order terms; formally we set | |
| $\epsilon^2 = 0$. This form of analysis can be made rigorous through a form | |
| of non-standard analysis called *Smooth Infinitesimal Analysis* [1], though | |
| note that nilpotent infinitesimal requires *constructive logic*, and thus proof | |
| by contradiction is not allowed in this logic due to a lack of the *law of the | |
| excluded middle*. | |
| A function $f$ will be represented by its value $f(a)$ and derivative $f'(a)$, | |
| encoded as the coefficients of a degree-1 (Taylor) polynomial in $\epsilon$: | |
| $$f \rightsquigarrow f(a) + \epsilon f'(a)$$ | |
| Conversely, if we have such an expansion in $\epsilon$ for a given function $f$, | |
| then we can identify the coefficient of $\epsilon$ as the derivative of $f$. | |
| ## Dual numbers | |
| Thus, to extend the idea of complex step differentiation beyond complex analytic | |
| functions, we define a new number type, the *dual number*. A dual number is a | |
| multidimensional number where the sensitivity of the function is propagated | |
| along the dual portion. | |
| Here we will now start to use $\epsilon$ as a dimensional signifier, like $i$, | |
| $j$, or $k$ for quaternion numbers. In order for this to work out, we need | |
| to derive an appropriate algebra for our numbers. To do this, we will look | |
| at Taylor series to make our algebra reconstruct differentiation. | |
| Note that the chain rule has been explicitly encoded in the derivative part. | |
| $$f(a + \epsilon) = f(a) + \epsilon f'(a)$$ | |
| to first order. If we have two functions | |
| $$f \rightsquigarrow f(a) + \epsilon f'(a)$$ | |
| $$g \rightsquigarrow g(a) + \epsilon g'(a)$$ | |
| then we can manipulate these Taylor expansions to calculate combinations of | |
| these functions as follows. Using the nilpotent algebra, we have that: | |
| $$(f + g) = [f(a) + g(a)] + \epsilon[f'(a) + g'(a)]$$ | |
| $$(f \cdot g) = [f(a) \cdot g(a)] + \epsilon[f(a) \cdot g'(a) + g(a) \cdot f'(a) ]$$ | |
| From these we can *infer* the derivatives by taking the component of $\epsilon$. | |
| These also tell us the way to implement these in the computer. | |
| ## Computer representation | |
| Setup (not necessary from the REPL): | |
| ```julia | |
| using InteractiveUtils # only needed when using Weave | |
| ``` | |
| Each function requires two pieces of information and some particular "behavior", | |
| so we store these in a `struct`. It's common to call this a "dual number": | |
| ```julia | |
| struct Dual{T} | |
| val::T # value | |
| der::T # derivative | |
| end | |
| ``` | |
| Each `Dual` object represents a function. We define arithmetic operations to | |
| mirror performing those operations on the corresponding functions. | |
| We must first import the operations from `Base`: | |
| ```julia | |
| Base.:+(f::Dual, g::Dual) = Dual(f.val + g.val, f.der + g.der) | |
| Base.:+(f::Dual, α::Number) = Dual(f.val + α, f.der) | |
| Base.:+(α::Number, f::Dual) = f + α | |
| #= | |
| You can also write: | |
| import Base: + | |
| f::Dual + g::Dual = Dual(f.val + g.val, f.der + g.der) | |
| =# | |
| Base.:-(f::Dual, g::Dual) = Dual(f.val - g.val, f.der - g.der) | |
| # Product Rule | |
| Base.:*(f::Dual, g::Dual) = Dual(f.val*g.val, f.der*g.val + f.val*g.der) | |
| Base.:*(α::Number, f::Dual) = Dual(f.val * α, f.der * α) | |
| Base.:*(f::Dual, α::Number) = α * f | |
| # Quotient Rule | |
| Base.:/(f::Dual, g::Dual) = Dual(f.val/g.val, (f.der*g.val - f.val*g.der)/(g.val^2)) | |
| Base.:/(α::Number, f::Dual) = Dual(α/f.val, -α*f.der/f.val^2) | |
| Base.:/(f::Dual, α::Number) = f * inv(α) # Dual(f.val/α, f.der * (1/α)) | |
| Base.:^(f::Dual, n::Integer) = Base.power_by_squaring(f, n) # use repeated squaring for integer powers | |
| ``` | |
| We can now define `Dual`s and manipulate them: | |
| ```julia | |
| f = Dual(3, 4) | |
| g = Dual(5, 6) | |
| f + g | |
| ``` | |
| ```julia | |
| f * g | |
| ``` | |
| ```julia | |
| f * (g + g) | |
| ``` | |
| ## Defining Higher Order Primitives | |
| We can also define functions of `Dual` objects, using the chain rule. | |
| To speed up our derivative function, we can directly hardcode the derivative | |
| of known functions which we call *primitives*. If `f` is | |
| a `Dual` representing the function $f$, then `exp(f)` should be a `Dual` | |
| representing the function $\exp \circ f$, i.e. with value $\exp(f(a))$ and | |
| derivative $(\exp \circ f)'(a) = \exp(f(a)) \, f'(a)$: | |
| ```julia | |
| import Base: exp | |
| ``` | |
| ```julia | |
| exp(f::Dual) = Dual(exp(f.val), exp(f.val) * f.der) | |
| ``` | |
| ```julia | |
| f | |
| ``` | |
| ```julia | |
| exp(f) | |
| ``` | |
| # Differentiating arbitrary functions | |
| For functions where we don't have a rule, we can recursively do dual number | |
| arithmetic within the function until we hit primitives where we know the derivative, | |
| and then use the chain rule to propagate the information back up. | |
| Under this algebra, we can represent $a + \epsilon$ as `Dual(a, 1)`. | |
| Thus, applying `f` to `Dual(a, 1)` should give `Dual(f(a), f'(a))`. This is thus | |
| a 2-dimensional number for calculating the derivative without floating point | |
| error, **using the compiler to transform our equations into dual number arithmetic**. | |
| To to differentiate an arbitrary function, we define a generic function and then | |
| change the algebra. | |
| ```julia | |
| h(x) = x^2 + 2 | |
| a = 3 | |
| xx = Dual(a, 1) | |
| ``` | |
| Now we simply evaluate the function `h` at the `Dual` number `xx`: | |
| ```julia | |
| h(xx) | |
| ``` | |
| The first component of the resulting `Dual` is the value $h(a)$, and the | |
| second component is the derivative, $h'(a)$! | |
| We can codify this into a function as follows: | |
| ```julia | |
| derivative(f, x) = f(Dual(x, one(x))).der | |
| ``` | |
| Here, `one` is the function that gives the value $1$ with the same type as | |
| that of `x`. | |
| Finally we can now calculate derivatives such as | |
| ```julia | |
| derivative(x -> 3x^5 + 2, 2) | |
| ``` | |
| As a bigger example, we can take a pure Julia `sqrt` function and differentiate | |
| it by changing the internal algebra: | |
| ```julia | |
| function newtons(x) | |
| a = x | |
| for i in 1:300 | |
| a = 0.5 * (a + x/a) | |
| end | |
| a | |
| end | |
| @show newtons(2.0) | |
| @show (newtons(2.0+sqrt(eps())) - newtons(2.0))/ sqrt(eps()) | |
| newtons(Dual(2.0,1.0)) | |
| ``` | |
| ## Higher dimensions | |
| How can we extend this to higher dimensional functions? For example, we wish | |
| to differentiate the following function $f: \mathbb{R}^2 \to \mathbb{R}$: | |
| ```julia | |
| ff(x, y) = x^2 + x*y | |
| ``` | |
| Recall that the **partial derivative** $\partial f/\partial x$ is defined by | |
| fixing $y$ and differentiating the resulting function of $x$: | |
| ```julia | |
| a, b = 3.0, 4.0 | |
| ff_1(x) = ff(x, b) # single-variable function | |
| ``` | |
| Since we now have a single-variable function, we can differentiate it: | |
| ```julia | |
| derivative(ff_1, a) | |
| ``` | |
| Under the hood this is doing | |
| ```julia | |
| ff(Dual(a, one(a)), b) | |
| ``` | |
| Similarly, we can differentiate with respect to $y$ by doing | |
| ```julia | |
| ff_2(y) = ff(a, y) # single-variable function | |
| derivative(ff_2, b) | |
| ``` | |
| Note that we must do **two separate calculations** to get the two partial | |
| derivatives; in general, calculating the gradient $\nabla$ of a function | |
| $f:\mathbb{R}^n \to \mathbb{R}$ requires $n$ separate calculations. | |
| ## Implementation of higher-dimensional forward-mode AD | |
| We can implement derivatives of functions $f: \mathbb{R}^n \to \mathbb{R}$ | |
| by adding several independent partial derivative components to our dual numbers. | |
| We can think of these as $\epsilon$ perturbations in different directions, | |
| which satisfy $\epsilon_i^2 = \epsilon_i \epsilon_j = 0$, and | |
| we will call $\epsilon$ the vector of all perturbations. Then we have | |
| $$f(a + \epsilon) = f(a) + \nabla f(a) \cdot \epsilon + \mathcal{O}(\epsilon^2),$$ | |
| where $a \in \mathbb{R}^n$ and $\nabla f(a)$ is the **gradient** of $f$ at $a$, | |
| i.e. the vector of partial derivatives in each direction. | |
| $\nabla f(a) \cdot \epsilon$ is the **directional derivative** of $f$ in the | |
| direction $\epsilon$. | |
| We now proceed similarly to the univariate case: | |
| $$(f + g)(a + \epsilon) = [f(a) + g(a)] + [\nabla f(a) + \nabla g(a)] \cdot \epsilon$$ | |
| $$\begin{align} | |
| (f \cdot g)(a + \epsilon) &= [f(a) + \nabla f(a) \cdot \epsilon ] \, [g(a) + \nabla g(a) \cdot \epsilon ] \\ | |
| &= f(a) g(a) + [f(a) \nabla g(a) + g(a) \nabla f(a)] \cdot \epsilon. | |
| \end{align}$$ | |
| We will use the `StaticArrays.jl` package for efficient small vectors: | |
| ```julia | |
| using StaticArrays | |
| struct MultiDual{N,T} | |
| val::T | |
| derivs::SVector{N,T} | |
| end | |
| import Base: +, * | |
| function +(f::MultiDual{N,T}, g::MultiDual{N,T}) where {N,T} | |
| return MultiDual{N,T}(f.val + g.val, f.derivs + g.derivs) | |
| end | |
| function *(f::MultiDual{N,T}, g::MultiDual{N,T}) where {N,T} | |
| return MultiDual{N,T}(f.val * g.val, f.val .* g.derivs + g.val .* f.derivs) | |
| end | |
| ``` | |
| ```julia | |
| gg(x, y) = x*x*y + x + y | |
| (a, b) = (1.0, 2.0) | |
| xx = MultiDual(a, SVector(1.0, 0.0)) | |
| yy = MultiDual(b, SVector(0.0, 1.0)) | |
| gg(xx, yy) | |
| ``` | |
| We can calculate the Jacobian of a function $\mathbb{R}^n \to \mathbb{R}^m$ | |
| by applying this to each component function: | |
| ```julia | |
| ff(x, y) = SVector(x*x + y*y , x + y) | |
| ff(xx, yy) | |
| ``` | |
| It would be possible (and better for performance in many cases) to | |
| store all of the partials in a matrix instead. | |
| Forward-mode AD is implemented in a clean and efficient way in the | |
| `ForwardDiff.jl` package: | |
| ```julia | |
| using ForwardDiff, StaticArrays | |
| ForwardDiff.gradient( xx -> ( (x, y) = xx; x^2 * y + x*y ), [1, 2]) | |
| ``` | |
| ## Directional derivative and gradient of functions $f: \mathbb{R}^n \to \mathbb{R}$ | |
| For a function $f: \mathbb{R}^n \to \mathbb{R}$ the basic operation is the | |
| **directional derivative**: | |
| $$\lim_{\epsilon \to 0} \frac{f(\mathbf{x} + \epsilon \mathbf{v}) - f(\mathbf{x})}{\epsilon} = | |
| [\nabla f(\mathbf{x})] \cdot \mathbf{v},$$ | |
| where $\epsilon$ is still a single dimension and $\nabla f(\mathbf{x})$ is the | |
| direction in which we calculate. | |
| We can directly do this using the same simple `Dual` numbers as above, | |
| using the *same* $\epsilon$, e.g. | |
| $$f(x, y) = x^2 \sin(y)$$ | |
| $$\begin{align} | |
| f(x_0 + a\epsilon, y_0 + b\epsilon) &= (x_0 + a\epsilon)^2 \sin(y_0 + b\epsilon) \\ | |
| &= x_0^2 \sin(y_0) + \epsilon[2ax_0 \sin(y_0) + x_0^2 b \cos(y_0)] + o(\epsilon) | |
| \end{align}$$ | |
| so we have indeed calculated $\nabla f(x_0, y_0) \cdot \mathbf{v},$ where | |
| $\mathbf{v} = (a, b)$ are the components that we put into the derivative | |
| component of the `Dual` numbers. | |
| If we wish to calculate the directional derivative in another direction, we | |
| could repeat the calculation with a different $\mathbf{v}$. A better solution | |
| is to use another independent epsilon $\epsilon$, expanding | |
| $$x = x_0 + a_1 \epsilon_1 + a_2 \epsilon_2$$ and putting | |
| $\epsilon_1 \epsilon_2 = 0$. | |
| In particular, if we wish to calculate the gradient itself, | |
| $\nabla f(x_0, y_0)$, we need to calculate both partial derivatives, which | |
| corresponds to two directional derivatives, in the directions | |
| $(1, 0)$ and $(0, 1)$, respectively. | |
| ## Forward-Mode AD as jvp | |
| Note that another representation of the directional derivative is $f'(x)v$, | |
| where $f'(x)$ is the Jacobian or total derivative of $f$ at $x$. To see the | |
| equivalence of this to a directional derivative, first let's see an example: | |
| $$\left[\begin{array}{ccc} | |
| \frac{\partial f_{1}}{\partial x_{1}} & \frac{\partial f_{1}}{\partial x_{2}} & \frac{\partial f_{1}}{\partial x_{3}}\\ | |
| \frac{\partial f_{2}}{\partial x_{1}} & \frac{\partial f_{2}}{\partial x_{2}} & \frac{\partial f_{2}}{\partial x_{3}}\\ | |
| \frac{\partial f_{3}}{\partial x_{1}} & \frac{\partial f_{3}}{\partial x_{2}} & \frac{\partial f_{3}}{\partial x_{3}}\\ | |
| \frac{\partial f_{4}}{\partial x_{1}} & \frac{\partial f_{4}}{\partial x_{2}} & \frac{\partial f_{4}}{\partial x_{3}}\\ | |
| \frac{\partial f_{5}}{\partial x_{1}} & \frac{\partial f_{5}}{\partial x_{2}} & \frac{\partial f_{5}}{\partial x_{3}} | |
| \end{array}\right]\left[\begin{array}{c} | |
| v_{1}\\ | |
| v_{2}\\ | |
| v_{3} | |
| \end{array}\right]=\left[\begin{array}{c} | |
| \frac{\partial f_{1}}{\partial x_{1}}v_{1}+\frac{\partial f_{1}}{\partial x_{2}}v_{2}+\frac{\partial f_{1}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{2}}{\partial x_{1}}v_{1}+\frac{\partial f_{2}}{\partial x_{2}}v_{2}+\frac{\partial f_{2}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{3}}{\partial x_{1}}v_{1}+\frac{\partial f_{3}}{\partial x_{2}}v_{2}+\frac{\partial f_{3}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{4}}{\partial x_{1}}v_{1}+\frac{\partial f_{4}}{\partial x_{2}}v_{2}+\frac{\partial f_{4}}{\partial x_{3}}v_{3}\\ | |
| \frac{\partial f_{5}}{\partial x_{1}}v_{1}+\frac{\partial f_{5}}{\partial x_{2}}v_{2}+\frac{\partial f_{5}}{\partial x_{3}}v_{3} | |
| \end{array}\right]=\left[\begin{array}{c} | |
| \nabla f_{1}(x)\cdot v\\ | |
| \nabla f_{2}(x)\cdot v\\ | |
| \nabla f_{3}(x)\cdot v\\ | |
| \nabla f_{4}(x)\cdot v\\ | |
| \nabla f_{5}(x)\cdot v | |
| \end{array}\right]$$ | |
| Or more formally, let's write it out in the standard basis: | |
| $$w_i = \sum_{j}^{m} J_{ij} v_{j}$$ | |
| Now write out what $J$ means and we see that: | |
| $$w_i = \sum_j^{m} \frac{df_i}{dx_j} v_j = \nabla f_i(x) \cdot v$$ | |
| **The primitive action of forward-mode AD is $f'(x)v!** | |
| This is also known as a *Jacobian-vector product*, or *jvp* for short. | |
| We can thus represent vector calculus with multidimensional dual numbers as | |
| follows. Let $d =[x,y]$, the vector of dual numbers. We can instead represent | |
| this as: | |
| $$d = d_0 + v_1 \epsilon_1 + v_2 \epsilon_2$$ | |
| where $d_0$ is the *primal* vector $[x_0,y_0]$ and the $v_i$ are the vectors | |
| for the *dual* directions. If you work out this algebra, then note that a | |
| single application of $f$ to a multidimensional dual number calculates: | |
| $$f(d) = f(d_0) + f'(d_0)v_1 \epsilon_1 + f'(d_0)v_2 \epsilon_2$$ | |
| i.e. it calculates the result of $f(x,y)$ and two separate directional derivatives. | |
| Note that because the information about $f(d_0)$ is shared between the calculations, | |
| this is more efficient than doing multiple applications of $f$. And of course, | |
| this is then generalized to $m$ many directional derivatives at once by: | |
| $$d = d_0 + v_1 \epsilon_1 + v_2 \epsilon_2 + \ldots + v_m \epsilon_m$$ | |
| ## Jacobian | |
| For a function $f: \mathbb{R}^n \to \mathbb{R}^m$, we reduce (conceptually, | |
| although not necessarily in code) to its component functions | |
| $f_i: \mathbb{R}^n \to \mathbb{R}$, where $f(x) = (f_1(x), f_2(x), \ldots, f_m(x))$. | |
| Then | |
| $$\begin{align} | |
| f(x + \epsilon v) &= (f_1(x + \epsilon v), \ldots, f_m(x + \epsilon v)) \\ | |
| &= (f_1(x) + \epsilon[\nabla f_1(x) \cdot v], \dots, f_m(x) + \epsilon[\nabla f_m(x) \cdot v] \\ | |
| &= f(x) + [f'(x) \cdot v] \epsilon, | |
| \end{align}$$ | |
| To calculate the complete Jacobian, we calculate these directional derivatives | |
| in the $n$ different directions of the basis vectors, i.e. if | |
| $d = d_0 + e_1 \epsilon_1 + \ldots + e_n \epsilon_n$ | |
| for $e_i$ the $i$th basis vector, then | |
| $f(d) = f(d_0) + Je_1 \epsilon_1 + \ldots + Je_n \epsilon_n$ | |
| computes all columns of the Jacobian simultaniously. | |
| ## Forward-Mode Automatic Differentiation for Gradients | |
| Let's recall the forward-mode method for computing gradients. For an arbitrary | |
| nonlinear function $f$ with scalar output, we can compute derivatives by | |
| putting a dual number in. For example, with | |
| $$d = d_0 + v_1 \epsilon_1 + \ldots + v_m \epsilon_m$$ | |
| we have that | |
| $$f(d) = f(d_0) + f'(d_0)v_1 \epsilon_1 + \ldots + f'(d_0)v_m \epsilon_m$$ | |
| where $f'(d_0)v_i$ is the direction derivative in the direction of $v_i$. To | |
| compute the gradient with respond to the input, we thus need to make $v_i = e_i$. | |
| However, in this case we now do not want to compute the derivative with respect | |
| to the input! Instead, now we have $f(x;p)$ and want to compute the derivatives | |
| with respect to $p$. This simply means that we want to take derivatives in the | |
| directions of the parameters. To do this, let: | |
| $$x = x_0 + 0 \epsilon_1 + \ldots + 0 \epsilon_k$$ | |
| $$P = p + e_1 \epsilon_1 + \ldots + e_k \epsilon_k$$ | |
| where there are $k$ parameters. We then have that | |
| $$f(x;P) = f(x;p) + \frac{df}{dp_1} \epsilon_1 + \ldots + \frac{df}{dp_k} \epsilon_k$$ | |
| as the output, and thus a $k+1$-dimensional number computes the gradient of | |
| the function with respect to $k$ parameters. | |
| Can we do better? | |
| # Reverse-Mode Automatic Differentiation | |
| The fast method for computing gradients goes under many times. The *adjoint | |
| technique*, *backpropogation*, and *reverse-mode automatic differentiation* | |
| are in some sense all equivalent phrases given to this method from different | |
| disciplines. To understand this technique, first let's understand programs $f$ | |
| as a composition of $L$ functions: | |
| $$f = f^L \circ f^{L-1} \circ \ldots \circ f^1$$ | |
| This should be intuitive because a program is just breaking down the steps | |
| of a calculation, like: | |
| ```julia | |
| x = 5 + 2 | |
| y = x * 3 | |
| z = x ^ y | |
| ``` | |
| could have simply been written as: | |
| ```julia | |
| (5+2) ^ ((5+2)*3) | |
| ``` | |
| Composing the assignment statements together gives the mathematical form of the | |
| function as a composition of the intermediate calculations. Now if $f$ is | |
| $$f = f^L \circ f^{L-1} \circ \ldots \circ f^1$$ | |
| then the Jacobian matrix satisfies: | |
| $$J = J_L J_{L-1} \ldots J_1$$ | |
| This fact is just another way of writing the chain rule: | |
| $$(g(f(x)))' = g'(f(x))*f'(x) = J_2 * J_1$$ | |
| Forward-mode automatic differentiation worked by propogating forward the actions | |
| of the Jacobians at every step of the program: | |
| $$Jv = J_L (J_{L-1} (\ldots (J_1 v) \ldots ))$$ | |
| effectively calculating the Jacobian of the program by multiplying by the | |
| Jacobians from left to right at each step of the way. This means doing primitive | |
| $Jv$ calculations on each underlying problem, and pushing that calculation | |
| through. When the primitive of a function was unknown, one would dig into how | |
| that function was defined, recursively, until primitive derivative definitions | |
| were known and used to define the dual part. Thus primitives defined how deep | |
| into a calculation one would look for an analytical solution to $J_i v$, and then | |
| the automatic differentiation engine would simply chain together these Jacobian-vector | |
| products. | |
| Forward-mode accumulation was good because $Jv$ directly calculated the | |
| directional derivative, which is also seen as the columns of the Jacobian (in a | |
| chosen basis). However, the key to understanding reverse-mode automatic differentiation | |
| is to see that **gradients are the rows of the Jacobian**. Let's see this in an | |
| example: | |
| $$\left[\begin{array}{ccccc} | |
| 0 & 1 & 0 & 0 & 0\end{array}\right]\left[\begin{array}{ccc} | |
| \frac{\partial f_{1}}{\partial x_{1}} & \frac{\partial f_{1}}{\partial x_{2}} & \frac{\partial f_{1}}{\partial x_{3}}\\ | |
| \frac{\partial f_{2}}{\partial x_{1}} & \frac{\partial f_{2}}{\partial x_{2}} & \frac{\partial f_{2}}{\partial x_{3}}\\ | |
| \frac{\partial f_{3}}{\partial x_{1}} & \frac{\partial f_{3}}{\partial x_{2}} & \frac{\partial f_{3}}{\partial x_{3}}\\ | |
| \frac{\partial f_{4}}{\partial x_{1}} & \frac{\partial f_{4}}{\partial x_{2}} & \frac{\partial f_{4}}{\partial x_{3}}\\ | |
| \frac{\partial f_{5}}{\partial x_{1}} & \frac{\partial f_{5}}{\partial x_{2}} & \frac{\partial f_{5}}{\partial x_{3}} | |
| \end{array}\right]=\left[\begin{array}{ccc} | |
| \frac{\partial f_{2}}{\partial x_{1}} & \frac{\partial f_{2}}{\partial x_{2}} & \frac{\partial f_{2}}{\partial x_{3}}\end{array}\right]=\nabla f_{2}(x)$$ | |
| Notice that multiplying by a row vector `[0 1 0 0 0]` pulls out the second row | |
| of the Jacobian, which pulls out the gradient of the second component of the | |
| multi-output function. If `f(x)` is a function that returned a scalar, `[1] * J` | |
| would give $\nabla f(x)$. Thus if we want to calculate gradients fast, we need | |
| to do automatic differentiation in a way that computes one row at a time, not | |
| one column at a time, and for scalar outputs then the gradient can be calculated | |
| in O(1) time instead of O(n)! | |
| However, this matrix calculus understanding of reverse-mode automatic differentiation | |
| directly describes how it gets its name. We can thus think of this as a different | |
| direction for the Jacobian accumulation. Let's see what happens when we left | |
| apply a row vector to the Jacobian, but recurse down to the component $J_i$ | |
| pieces of a composed function: | |
| $$v^T J = (\ldots ((v^T J_L) J_{L-1}) \ldots ) J_1$$ | |
| Multiplying on the right does $J_1 v$ first, while multiplying on the left | |
| requires doing $v^T J_L$ first. This means **in order to do this calcaultion, | |
| the derivative must be computed in reverse starting from the end**, giving | |
| rise to the name reverse-mode AD. We must chain together vector-Jacobian product, | |
| or **vjp** calculations from the last step of the calculation to the previous | |
| all the way back to the start. | |
| ## Quick note on notation | |
| Some people write reverse-mode AD as the $J^T v$ action, but you can also see this | |
| implies reverse accumulation by the properties of the transpose since | |
| $$J^T v = (J_L J_{L-1} \ldots J_1)^T v = (J_1^T J_{2}^T \ldots J_L^T )v$$ | |
| the transpose reverses the order of multiplication. | |
| Okay, now let's figure out how to do the calculation in this style. | |
| ## Reverse-Mode of a Neural Network | |
| Let's do reverse-mode automatic differentiation fo the following function: | |
| $$\begin{align} | |
| z &= W_1 x + b_1\\ | |
| h &= \sigma(z)\\ | |
| y &= W_2 h + b_2\\ | |
| \mathcal{L} &= \frac{1}{2} \Vert y-t \Vert^2 \end{align}$$ | |
| where we call $f(x) = L$. To simplify our notation, let's write for $y = f(x)$ | |
| the simplification: | |
| $$\overline{x} = [\frac{\partial f}{\partial x}]^T v$$ | |
| The reason is because we want to encode the successive "$J'v$ of last time" | |
| expressions. To calculate $f'(x)^T v$ we decompose it into steps | |
| $(J_1^T J_{2}^T \ldots J_L^T )v$, or: | |
| $$\begin{align} | |
| \overline{L} &= v\\ | |
| \overline{y} &= [\frac{\partial (\frac{1}{2} \Vert y-t \Vert^2)}{\partial y}]^T \overline{L} = (y-t)^T v\\ | |
| \overline{h} &= [\frac{\partial (W_2 h + b_2)}{\partial h}]^T \overline{y} = W_2^T \overline{y}\\ | |
| \overline{z} &= [\frac{\partial \sigma(z)}{\partial z}]^T \overline{h} = \sigma^\prime(z)^T \overline{h}\\ | |
| \overline{x} &= [\frac{\partial W_1 x + b_1}{\partial x}]^T \overline{z} = W_1^T \overline{z}\\ | |
| \end{align}$$ | |
| (note that since $L$ is a scalar, $v$ is a scalar here so we don't really need | |
| to transpose, that's more to show form). Or, in order to calculate $f'(x)^T v$, | |
| we do this by calculating: | |
| $$J^T v = (W_1^T \sigma^\prime(z)^T W_2^T (y-t)^T) v$$ | |
| and if $v=1$ then we receive the gradient of the neural network with respect | |
| to $x$. | |
| ## Primitives of Reverse Mode | |
| For forward-mode AD, we saw that we could define primitives in order to accelerate | |
| the calculation. For example, knowing that | |
| $$exp(x+\epsilon) = exp(x) + exp(x)\epsilon$$ | |
| allows the program to skip autodifferentiating through the code for `exp`. This | |
| was simple with forward-mode since we could represent the operation on a Dual | |
| number. What's the equivalent for reverse-mode AD? The answer is the *pullback* | |
| function. If $y = [y_1,y_2,\ldots] = f(x_1,x_2, \ldots)$, then | |
| $[\overline{x_1},\overline{x_2},\ldots]=\mathcal{B}_f^x(\overline{y})$ is the | |
| pullback of $f$ at the point $x$, defined for a scalar loss function $L(y)$ as: | |
| $$\overline{x_i} = \frac{\partial L}{\partial x} = \sum_i \frac{\partial L}{\partial y_i} \frac{\partial y_i}{\partial x_i}$$ | |
| Using the notation from earlier, $\overline{y} = \frac{\partial L}{\partial y}$ is the derivative | |
| of the some intermediate w.r.t. the cost function, and thus | |
| $$\overline{x_i} = \sum_i \overline{y_i} \frac{\partial y_i}{\partial x_i} = \mathcal{B}_f^x(\overline{y})$$ | |
| Note that $\mathcal{B}_f^x(\overline{y})$ is a function of $x$ because the | |
| reverse pass that is use embeds values from the forward pass, and the values | |
| from the forward pass to use are those calculated during the evaluation of | |
| $f(x)$. | |
| By the chain rule, if we don't have a primitive defined | |
| for $y_i(x)$, we can compute that by $\mathcal{B}_{y_i}(\overline{y})$, and | |
| recursively apply this process until we hit rules that we know. The rules to | |
| start with are the scalar derivative rules with follow quite simply, and the | |
| multivariate rules which we derived above. For example, if $y=f(x)=Ax$, then | |
| $$\mathcal{B}_{f}^x(\overline{y}) = \overline{y}^T A$$ | |
| which is simply saying that the Jacobian of $f$ at $x$ is $A$, and so the vjp | |
| is to multiply the vector transpose by $A$. | |
| Likewise, for element-wise operations, the Jacobian is diagonal, and thus the | |
| vjp is multiplying once again by a diagonal matrix against the derivative, | |
| deriving the same pullback as we had for backpropogation in a neural network. | |
| This then is a quicker encoding and derivation of backpropogation. | |
| ## Example of a Reverse-Mode AD Primitive | |
| Let's write down the reverse-mode primitive for $y = \sigma(Wx + b)$. Doing as | |
| we showed before, we break down the steps of the computation and write the | |
| $J'v$ one step at a time until we get back to the start: | |
| ```julia | |
| using ChainRules | |
| nndense(W,x,b) = σ.(W*x + b) | |
| function ChainRules.rrule(::typeof(nndense), W,x,b) | |
| r = W*x .+ b | |
| y = σ.(r) | |
| function adjoint(v) | |
| zbar = ForwardDiff.derivative.(f.σ,r) .* v | |
| xbar = W' * zbar | |
| NoTangent(),NotImplemented(),xbar,NotImplemented() | |
| end | |
| y,adjoint | |
| end | |
| ``` | |
| The homework will be to figure out how to calculate `Wbar` and `bbar`! | |
| ## Forward Mode vs Reverse Mode Efficiency | |
| Notice that a pullback of a single scalar gives the gradient of a function, | |
| while the *pushforward* using forward-mode of a dual gives a directional | |
| derivative. Forward mode computes columns of a Jacobian, while reverse mode | |
| computes gradients (rows of a Jacobian). Therefore, the relative efficiency | |
| of the two approaches is based on the size of the Jacobian. If | |
| $f:\mathbb{R}^n \rightarrow \mathbb{R}^m$, then the Jacobian is of size $$m \times n$$. | |
| If $m$ is much smaller than $n$, then computing by each row will be faster, and | |
| thus use reverse mode. In the case of a gradient, $m=1$ while $n$ can be large, | |
| leading to this phonomena. Likewise, if $n$ is much smaller than $m$, then | |
| computing by each column will be faster. We will see shortly the reverse mode | |
| AD has a high overhead with respect to forward mode, and thus if the values | |
| are relatively equal (or $n$ and $m$ are small), forward mode is more efficient. | |
| However, since optimization needs gradients, reverse-mode definitely has a | |
| place in the standard toolchain which is why backpropagation is so central to | |
| machine learning. **But this does not mean that reverse-mode AD is "faster", in | |
| fact for square matrices it's usually slower!**. | |
| # Extra: Reverse-Mode Automatic Differentiation on Computation Graphs | |
| Most lecture notes will show reverse-mode automatic differentiation on | |
| computation graphs as the core way to do the calculation because they want | |
| to avoid matrix calculus. The following walks through that approach to show | |
| how it's a very tedious way to derive the same results. | |
| ## Adjoints and Reverse-Mode AD through Computation Graphs | |
| Let's look at the multivariate chain rule on a *computation graph*. Recall that | |
| for $f(x(t),y(t))$ that we have: | |
| $$\frac{df}{dt} = \frac{df}{dx}\frac{dx}{dt} + \frac{df}{dy}\frac{dy}{dt}$$ | |
| We can visualize our direct dependences as the computation graph: | |
| 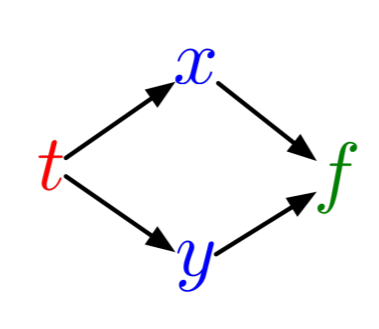 | |
| i.e. $t$ directly determines $x$ and $y$ which then determines $f$. To calculate | |
| Assume you've already evaluated $f(t)$. If this has been done, then you've | |
| already had to calculate $x$ and $y$. Thus given the function $f$, we can now | |
| calculate $\frac{df}{dx}$ and $\frac{df}{dy}$, and then calculate $\frac{dx}{dt}$ | |
| and $\frac{dy}{dt}$. | |
| Now let's put another layer in the computation. Let's make | |
| $f(x(v(t),w(t)),y(v(t),w(t))$. We can write out the full expression for the | |
| derivative. Notice that even with this additional layer, the | |
| statement we wrote above still holds: | |
| $$\frac{df}{dt} = \frac{df}{dx}\frac{dx}{dt} + \frac{df}{dy}\frac{dy}{dt}$$ | |
| So given an evaluation of $f$, we can (still) directly calculate $\frac{df}{dx}$ | |
| and $\frac{df}{dy}$. But now, to calculate $\frac{dx}{dt}$ and $\frac{dy}{dt}$, | |
| we do the next step of the chain rule: | |
| $$\frac{dx}{dt} = \frac{dx}{dv}\frac{dv}{dt} + \frac{dx}{dw}\frac{dw}{dt}$$ | |
| and similar for $y$. So plug it all in, and you see that our equations will grow | |
| wild if we actually try to plug it in! But it's clear that, to calculate | |
| $$\frac{df}{dt}$$, we can first calculate $\frac{df}{dx}$, and then multiply | |
| that to $\frac{dx}{dt}$. If we had more layers, we could calculate the | |
| *sensitivity* (the derivative) of the output to the last layer, then and then | |
| the sensitivity to the second layer back is the sensitivity of the last layer | |
| multiplied to that, and the third layer back has the sensitivity of the second | |
| layer multiplied to it! | |
| ## Logistic Regression Example | |
| To better see this structure, let's write out a simple example. Let our | |
| *forward pass* through our function be: | |
| $$\begin{align} | |
| z &= wx + b\\ | |
| y &= \sigma(z)\\ | |
| \mathcal{L} &= \frac{1}{2}(y-t)^2\\ | |
| \mathcal{R} &= \frac{1}{2}w^2\\ | |
| \mathcal{L}_{reg} &= \mathcal{L} + \lambda \mathcal{R}\end{align}$$ | |
| 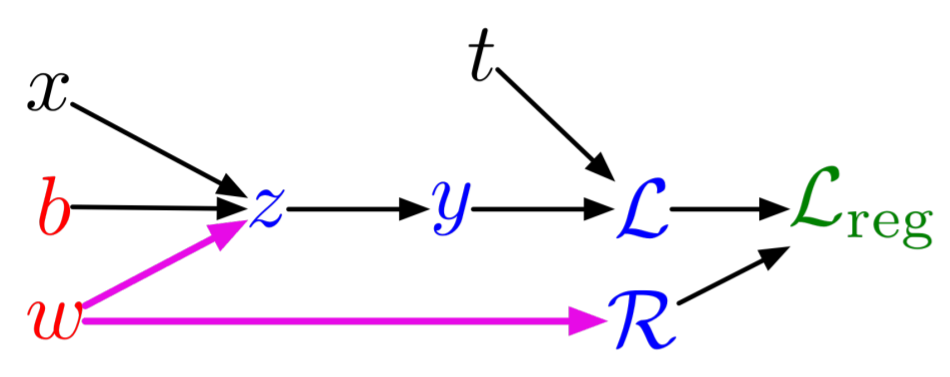 | |
| The formulation of the program here is called a *Wengert list, tape, or graph*. | |
| In this, $x$ and $t$ are inputs, $b$ and $W$ are parameters, $z$, $y$, $\mathcal{L}$, | |
| and $\mathcal{R}$ are intermediates, and $\mathcal{L}_{reg}$ is our output. | |
| This is a simple univariate logistic regression model. To do logistic regression, | |
| we wish to find the parameters $w$ and $b$ which minimize the distance of | |
| $\mathcal{L}_{reg}$ from a desired output, which is done by computing derivatives. | |
| Let's calculate the derivatives with respect to each quantity in reverse order. | |
| If our program is $f(x) = \mathcal{L}_{reg}$, then we have that | |
| $$\frac{df}{\mathcal{L}_{reg}} = 1$$ | |
| as the derivatives of the last layer. To computerize our notation, let's write | |
| $$\overline{\mathcal{L}_{reg}} = \frac{df}{\mathcal{L}_{reg}}$$ | |
| for our computed values. For the derivatives of the second to last layer, we have that: | |
| $$\begin{align} | |
| \overline{\mathcal{R}} &= \frac{df}{\mathcal{L}_{reg}} \frac{d\mathcal{L}_{reg}}{\mathcal{R}}\\ | |
| &= \overline{\mathcal{L}_{reg}} \lambda \end{align}$$ | |
| $$\begin{align} | |
| \overline{\mathcal{L}} &= \frac{df}{\mathcal{L}_{reg}} \frac{d\mathcal{L}_{reg}}{\mathcal{L}}\\ | |
| &= \overline{\mathcal{L}_{reg}} \end{align}$$ | |
| This was our observation from before that the derivative of the second layer is | |
| the partial derivative of the current values times the sensitivity of the final | |
| layer. And then we keep multiplying, so now for our next layer we have that: | |
| $$\begin{align} | |
| \overline{y} &= \overline{\mathcal{L}} \frac{d\mathcal{L}}{dy}\\ | |
| &= \overline{\mathcal{L}} (y-t) \end{align}$$ | |
| And notice that the chain rule holds since $\overline{\mathcal{L}}$ implicitly | |
| already has the multiplication by $\overline{\mathcal{L}_{reg}}$ inside of it. | |
| Then the next layer is: | |
| $$\begin{align} | |
| \frac{df}{z} &= \overline{y} \frac{dy}{dz}\\ | |
| &= \overline{y} \sigma^\prime(z) \end{align}$$ | |
| Then the next layer. Notice that here, by the chain rule on $w$ we have that: | |
| $$\begin{align} | |
| \overline{w} &= \overline{z} \frac{\partial z}{\partial w} + \overline{\mathcal{R}} \frac{d \mathcal{R}}{dw}\\ | |
| &= \overline{z} x + \overline{\mathcal{R}} w\end{align}$$ | |
| $$\begin{align} | |
| \overline{b} &= \overline{z} \frac{\partial z}{\partial b}\\ | |
| &= \overline{z} \end{align}$$ | |
| This completely calculates all derivatives. In conclusion, the rule is: | |
| - You sum terms from each outward arrow | |
| - Each arrow has the derivative term of the end times the partial of the | |
| current term. | |
| - Recurse backwards to build simple linear combination expressions. | |
| ### Quick note | |
| We started this derivation with | |
| $$\frac{df}{\mathcal{L}_{reg}} = 1$$ | |
| and we then get out $\nabla f(x)$, but from our discussion before this is simply | |
| `[1]' J`. Thus while we have a (flaky) justification for making this value `1`, | |
| it's really just the choice of $v$! Thus doing | |
| $$\frac{df}{\mathcal{L}_{reg}} = v$$ | |
| will make this process compute $v^T J$ for this $f$. | |
| ## Backpropogation of a Neural Network | |
| Now let's look at backpropgation of a deep neural network. Before getting to it | |
| in the linear algebraic sense, let's write everything in terms of scalars. This | |
| means we can write a simple neural network as: | |
| $$\begin{align} | |
| z_i &= \sum_j W_{ij}^1 x_j + b_i^1\\ | |
| h_i &= \sigma(z_i)\\ | |
| y_i &= \sum_j W_{ij}^2 h_j + b_i^2\\ | |
| \mathcal{L} &= \frac{1}{2} \sum_k \left(y_k - t_k \right)^2 \end{align}$$ | |
| where I have chosen the L2 loss function. This is visualized by the computational | |
| graph: | |
| 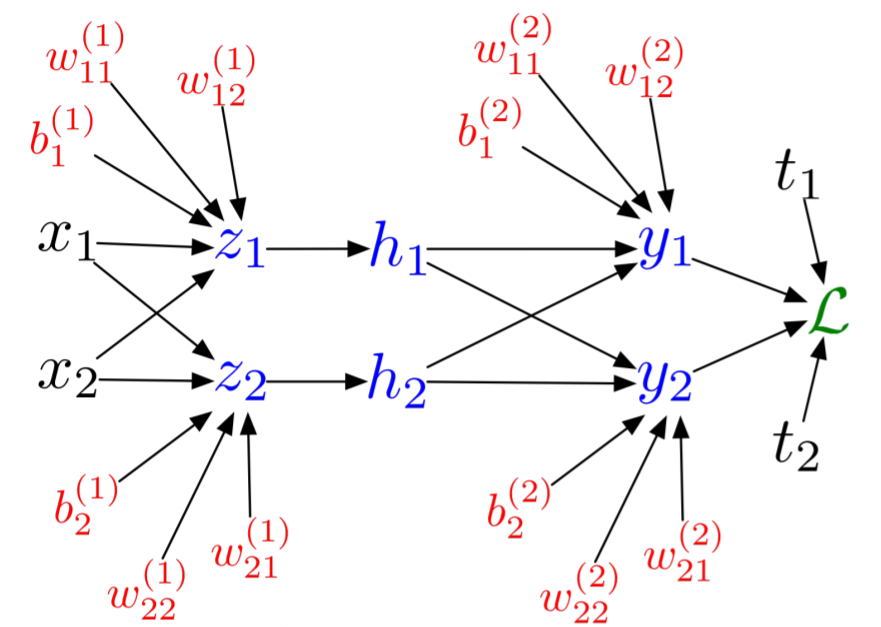 | |
| Then we can do the same process as before to get: | |
| $$\begin{align} | |
| \overline{\mathcal{L}} &= 1\\ | |
| \overline{y_i} &= \overline{\mathcal{L}} (y_i - t_i)\\ | |
| \overline{w_{ij}^2} &= \overline{y_i} h_j\\ | |
| \overline{b_i^2} &= \overline{y_i}\\ | |
| \overline{h_i} &= \sum_k (\overline{y_k}w_{ki}^2)\\ | |
| \overline{z_i} &= \overline{h_i}\sigma^\prime(z_i)\\ | |
| \overline{w_{ij}^1} &= \overline{z_i} x_j\\ | |
| \overline{b_i^1} &= \overline{z_i}\end{align}$$ | |
| just by examining the computation graph. Now let's write this in linear algebraic | |
| form. | |
| 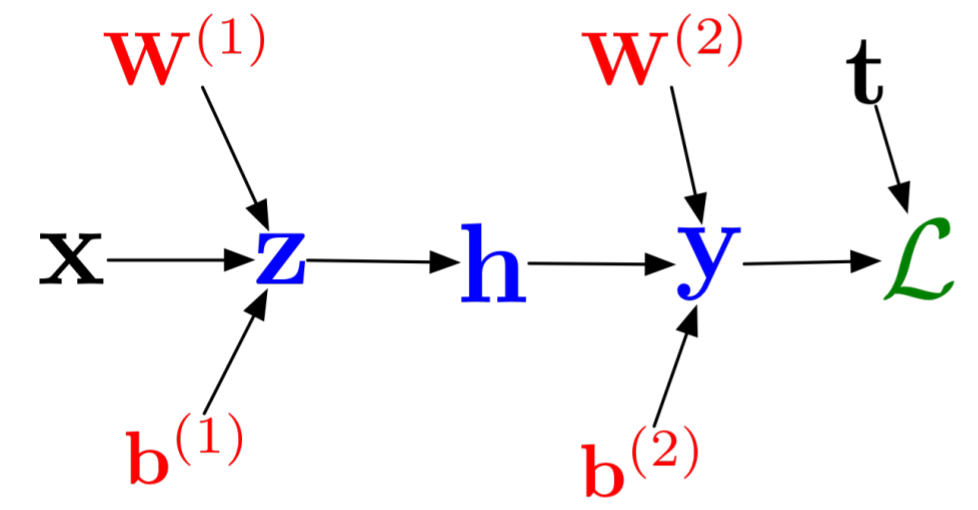 | |
| The forward pass for this simple neural network was: | |
| $$\begin{align} | |
| z &= W_1 x + b_1\\ | |
| h &= \sigma(z)\\ | |
| y &= W_2 h + b_2\\ | |
| \mathcal{L} = \frac{1}{2} \Vert y-t \Vert^2 \end{align}$$ | |
| If we carefully decode our scalar expression, we see that we get the following: | |
| $$\begin{align} | |
| \overline{\mathcal{L}} &= 1\\ | |
| \overline{y} &= \overline{\mathcal{L}}(y-t)\\ | |
| \overline{W_2} &= \overline{y}h^{T}\\ | |
| \overline{b_2} &= \overline{y}\\ | |
| \overline{h} &= W_2^T \overline{y}\\ | |
| \overline{z} &= \overline{h} .* \sigma^\prime(z)\\ | |
| \overline{W_1} &= \overline{z} x^T\\ | |
| \overline{b_1} &= \overline{z} \end{align}$$ | |
| We can thus decode the rules as: | |
| - Multiplying by the matrix going forwards means multiplying by the transpose | |
| going backwards. A term on the left stays on the left, and a term on the right | |
| stays on the right. | |
| - Element-wise operations give element-wise multiplication | |
| Notice that the summation is then easily encoded into this rule by the transpose | |
| operation. | |
| We can write it in the general DNN form of: | |
| $$r_i = W_i v_{i} + b_i$$ | |
| $$v_{i+1} = \sigma_i.(r_i)$$ | |
| $$v_1 = x$$ | |
| $$\mathcal{L} = \frac{1}{2} \Vert v_{n} - t \Vert$$ | |
| $$\begin{align} | |
| \overline{\mathcal{L}} &= 1\\ | |
| \overline{v_n} &= \overline{\mathcal{L}}(y-t)\\ | |
| \overline{r_i} &= \overline{v_i} .* \sigma_i^\prime (r_i)\\ | |
| \overline{W_i} &= \overline{v_i}r_{i-1}^{T}\\ | |
| \overline{b_i} &= \overline{v_i}\\ | |
| \overline{v_{i-1}} &= W_{i}^{T} \overline{v_i} \end{align}$$ | |
| ## References | |
| - John L. Bell, *An Invitation to Smooth Infinitesimal Analysis*, | |
| http://publish.uwo.ca/~jbell/invitation%20to%20SIA.pdf | |
| - Bell, John L. *A Primer of Infinitesimal Analysis* | |
| - Nocedal & Wright, *Numerical Optimization*, Chapter 8 | |
| - Griewank & Walther, *Evaluating Derivatives* |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment