Grinnell College employs the transcription workflow described here when preparing oral histories for ingest into Digital Grinnell. This workflow includes a commercially available software tool called InqScribe and at Grinnell transcribers also frequently use a VEC USB Footpedal to help control playback of audio to be transcribed.
An 11.5 minute long is available to reinforce the concepts presented below.
The video moves very quickly, compressing a 2-hour transcription session down into 11.5 minutes. You may find it necessary to slow the playback down, or rewind and repeat portions of the video, using the controls available in your browser.
A typical transcription session generally involves the following steps...
OHScribe creates a new cue every time it encounters a timecode, so every timecode should be followed immediately by a newline, speaker name and pipe character. For areas of the recording that are dense with speaker changes, no timecode is needed to transition to the next speaker, i.e. the transcriber can represent a change in speaker by entering a newline, the speaker name and pipe character to start the next speaker's dialogue. This will result in a cue that has mutliple speakers.
InqScribe allows a transcriber to define and use Snippets, short bits of frequently-repeated text, with associated triggers or keyboard Shortcuts that make it easy to quickly add key elements to a transcript. The following are samples of Snippets and their corresponding Triggers/Shortcuts used in conjunction with our workflow.
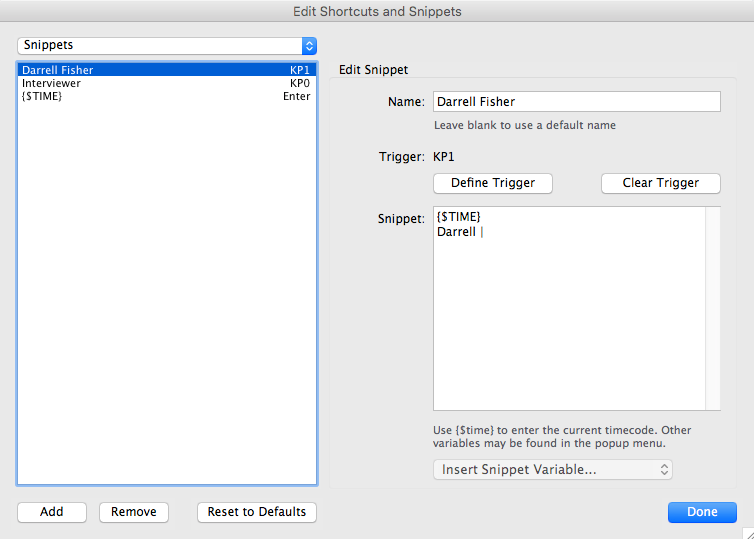
The above image is an example of a Snippet we refer to as a 'Speaker Timecode'. When triggered, this snippet will insert:
- A timecode, the
${TIME}variable portion of the snippet, and - A name identifying the speaker providing the transcribed text that will follow.
In this example the speaker's name is 'Darrell' and that name is followed by a REQUIRED space and a pipe character, the vertical bar, in the portion that reads Darrell | . There is a space after the pipe character so as to allow the thranscriber to simply press the triger and then immediately start to type the dialogue into InqScribe. OHScribe does not currently correctly parse a pipe character from other text unless it is surrounded by spaces on either side.
If a speaker has a double first name, the name will need to be hyphentated because OHScribe will only identify one word/name, separated from others by spaces, as the trigger name for the speaker. The first name in the <speaker> FirstName LastName </speaker> tag MUST match the name that follows after the timecode.
Note also that in this example our Speaker Timecode snippet is named Darrell Fisher and it is assigned to trigger KP1 which has a corresponding keyboard shortcut. The name of the timecode snippet is not important, and can be left vague/general, as with the Interviewer example.
Any additional speakers can be represented in the same way by selecting 'Add' and then filling in the correct information similarly to the example above.
Each time a new speaker is introduced, there must be <speaker> FirstName LastName </speaker> line added between the timecode and the FirstName | . Each speaker should only have one instance of speaker tags in the InqScribe file.
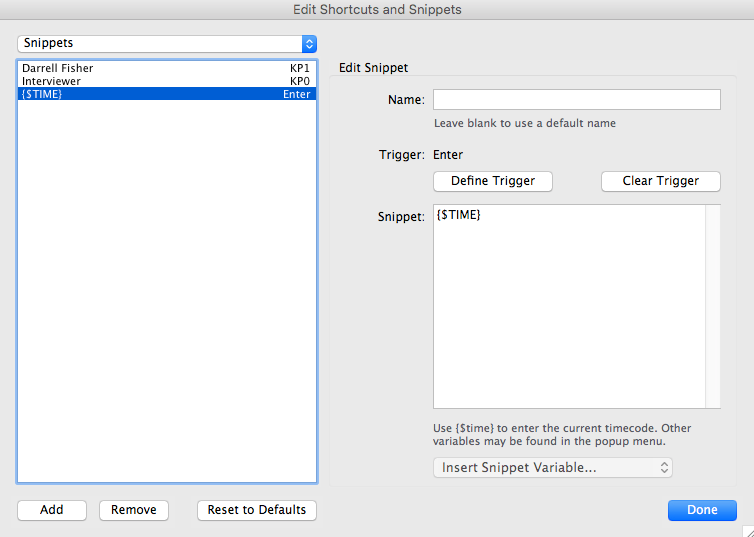
The second image, immediately above, is an example of a Snippet we refer to as a 'Raw Timecode'. When triggered, this snippet will insert:
- A timecode, the value of the
${TIME}variable referenced in the snippet, and nothing else.
Note that a Raw Timecode has no associated speaker name as it's intended to be used when the speaker name is unknown, or when there isn't time during transcription to pause for identification of the next speaker.
This example Raw Timecode snippet is named {$TIME} and it is assigned to the Enter trigger which generally corresponds to the Enter or Return key on the keyboard.
Once the transcription and timecodes are in place, save the InqScribe file and export it to an XML file by selecting File -> Export -> XML.