团队名称:煮酒论英雄
By Dousir9, Wind-Gone , RTEnzyme
Repo: https://github.com/Dousir9/tidb_hackathon_2022
TiInverted 主要解决 TiDB 目前缺少对全文搜索(Full-Text Search)的支持问题,解决用户在检索文本时遇到的痛点。TiInverted 为 TiDB 新增一个功能,使得用户可以在基于文本的列(CHAR、VARCHAR、TEXT 等)上建立倒排索引,并适配MySQL的全文搜索功能的语法,从而实现在这一列上更高效、更复杂数据检索,此外还可以结合NLP的技术,允许用户设定模式,以在检索时获取相关性更高的搜索结果,实现数据库智能化(AI4DB)的宏观目标。
项目简要目标如下:项目简要目标如下:
-
为 TiDB 实现新功能:倒排索引(Inverted index) + NLP
-
设计 Benchmark 评测倒排索引的性能(与
like进行对比) -
简要的 Demo 展示倒排索引的效果:
- 更全面的搜索效果
- 更高的搜索相关性
- 更良好的用户体验
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,同时支持在线事务处理与在线分析处理,供水平可扩展性、强一致性和高可用性, 兼容 MySQL 5.7 协议和 MySQL 生态,是当下非常热门的数据库产品。倒排索引,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
传统的面向全文检索的数据库,如 Elasticsearch,solr 等,是基于全文搜索引擎构建出的分布式搜索平台,其主要目的主要是提供高效的、分布式的全文搜索。在传统数据库中,文本数据检索只能通过 like 来实现,但是这种方法存在诸多问题,因此 MySQL 从 8.0 版本开始,新增支持了倒排索引这一特性。
如果数据表规模很小还可以接受,但是一旦数据规模较大,那全表 Scan 就如同大海捞针一般,性能很差。
| ID | INTRODUCTION |
|---|---|
| 1001 | 苹果公司发布iPhone |
| 1002 | 牛顿因为苹果发现了地球引力 |
| 1003 | iPhone屏幕碎了 |
| 1004 | 我刚刚吃了苹果 |
| 1005 | 我在苹果商店维修屏幕 |
对于上表来说,假设要搜索 “苹果” 两字,搜索条件为:like %苹果%,那么 like 会对上表每一行数据去做匹配,查一下是否包含 “苹果”,可以查到ID为 1001、1002、1004、1005 的行,但是如果搜索条件改为 “苹果iPhone” :like %苹果iPhone%,在这个搜索条件下,就什么也搜不到了,得到的行数为 0,因为 like 只能首尾模糊匹配,无法把这词汇拆开再到数据库去搜索。
再比如,对于这段内容:“中国的历史十分悠久。”,如果采用 like %中国历史% 进行搜索,因为 “中国的历史” 与 “中国历史” 不匹配,就什么也搜不到,因为 like 无法实现分词 中国 OR 历史 进行搜索。
like 缺乏对搜索内容的近似拓展,搜索的相关性较差,假如我要用 like 搜索 “住宿”,就只能得到“住宿”的结果,但是在倒排索引中,可以启动加强相关性的同义词拓展功能(Synonym Expansion Mode),使得 “住宿” 可以通过预先设定好的同义词字典或者模型来匹配到 “酒店”、“公寓” 等等关键词上。
基于对以上传统方法不足之处的总结,以及在近年来数据库智能化浪潮的推动下,NLP技术臻于成熟,已有较多工程落地经验的参照,我们希望可以通过相关的技术手段为TiDB支持倒排索引这一特性,项目整体设计思路如下:
在TiDB中,索引以 Key-Value 的形式保存在 TiKV 中。TiDB 对每个表分配一个 TableID,每个索引都会分配一个 IndexID,每一行分配一个 RowID (如果表有整数型的 Primary Key ,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一。
对于 Unique Index 数据,会按照如下的规则编码成 Key-Value pair:
{
"Key": "tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue",
"Value": "rowID"
}而对于非 Unique Index,可能有多行的数据的 ColumnsValue 是一样的,如果采用上述的编码方式会出现冲突。所以对于非 Unique Index 采用以下的编码:
{
"Key": "tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID",
"Value": null
}为了适配 TiDB 的索引数据结构且不引起冲突,TiInverted 采用以下的编码格式:
{
"Key": "tablePrefix{tableID}_indexPrefixSep{indexID}_indexedWord_docID_posi",
"Value": null
}其中 indexedWord 是指倒排索引的词;docID 是指该词所在的一个文档的ID,通常是以 rowID 或 primaryKey 表示; posi 是指该词在文档中的位置。
修改 TiDB 中 Index Struct
// Index is the interface for index data on KV store.
type Index interface {
// Meta returns IndexInfo.
Meta() *model.IndexInfo
// Create supports insert into statement.
Create(ctx sessionctx.Context, txn kv.Transaction, indexedValues []types.Datum, h kv.Handle, handleRestoreData []types.Datum, opts ...CreateIdxOptFunc) (kv.Handle, error)
// Delete supports delete from statement.
Delete(sc *stmtctx.StatementContext, txn kv.Transaction, indexedValues []types.Datum, h kv.Handle) error
// Exist supports check index exists or not.
Exist(sc *stmtctx.StatementContext, txn kv.Transaction, indexedValues []types.Datum, h kv.Handle) (bool, kv.Handle, error)
// GenIndexKey generates an index key.
GenIndexKey(sc *stmtctx.StatementContext, indexedValues []types.Datum, h kv.Handle, buf []byte) (key []byte, distinct bool, err error)
// GenIndexValue generates an index value.
GenIndexValue(sc *stmtctx.StatementContext, distinct bool, indexedValues []types.Datum, h kv.Handle, restoredData []types.Datum) ([]byte, error)
// FetchValues fetched index column values in a row.
// Param columns is a reused buffer, if it is not nil, FetchValues will fill the index values in it,
// and return the buffer, if it is nil, FetchValues will allocate the buffer instead.
FetchValues(row []types.Datum, columns []types.Datum) ([]types.Datum, error)
}涉及到以下几个方面:
- 修改 DDL语句的 create index,增加对 FullText index 的支持
- 在构建倒排索引时,将 column value 添加到索引中
- Delete() -> Create():将索引中有关这一行的 key 删除,然后重新创建对这一行的索引。
- 后续优化方案:使得 Update 语句采用增量更新的机制,不需要完全针对这一行的的索引,可以在原有的索引基础上Create 或 Drop 某些 Word 的索引。
主要涉及到以下几个场景:
- drop index / table / column
- delete row
适配 MySQL 协议 FULLTEXT 索引进行改写:
CreateIndexStmt:
"CREATE" IndexKeyTypeOpt "INDEX" IfNotExists Identifier IndexTypeOpt "ON" TableName '(' IndexPartSpecificationList ')' IndexOptionList
{
...
}
IndexKeyTypeOpt:
{...}
| "UNIQUE"
{...}
| "SPATIAL"
{...}
| "FULLTEXT"
{...}根据 MySQL 协议,query 语法如下:
SELECT
*
FROM
t
WHERE
Match('content') AGAINST('上海市纽约大学')
LIMIT
5主要分为 Parser 规则的实现、语法树改写和同义词拓展功能的实现。
(1) Parser: 由于TiDB的parser.y中已对MySQL的全文搜索功能的语法进行适配,所以不需要再进行修改。
(2) 重写 AST 语法树:
因为涉及到分词,可以采用改写语法树的方法来处理。在遍历语法树阶段中,对于 MatchAgainstExpression 进行语法树的重写,首先对aganist的文本进行分词,再根据分词结果对语法树进行 rewrite,以下图为例:
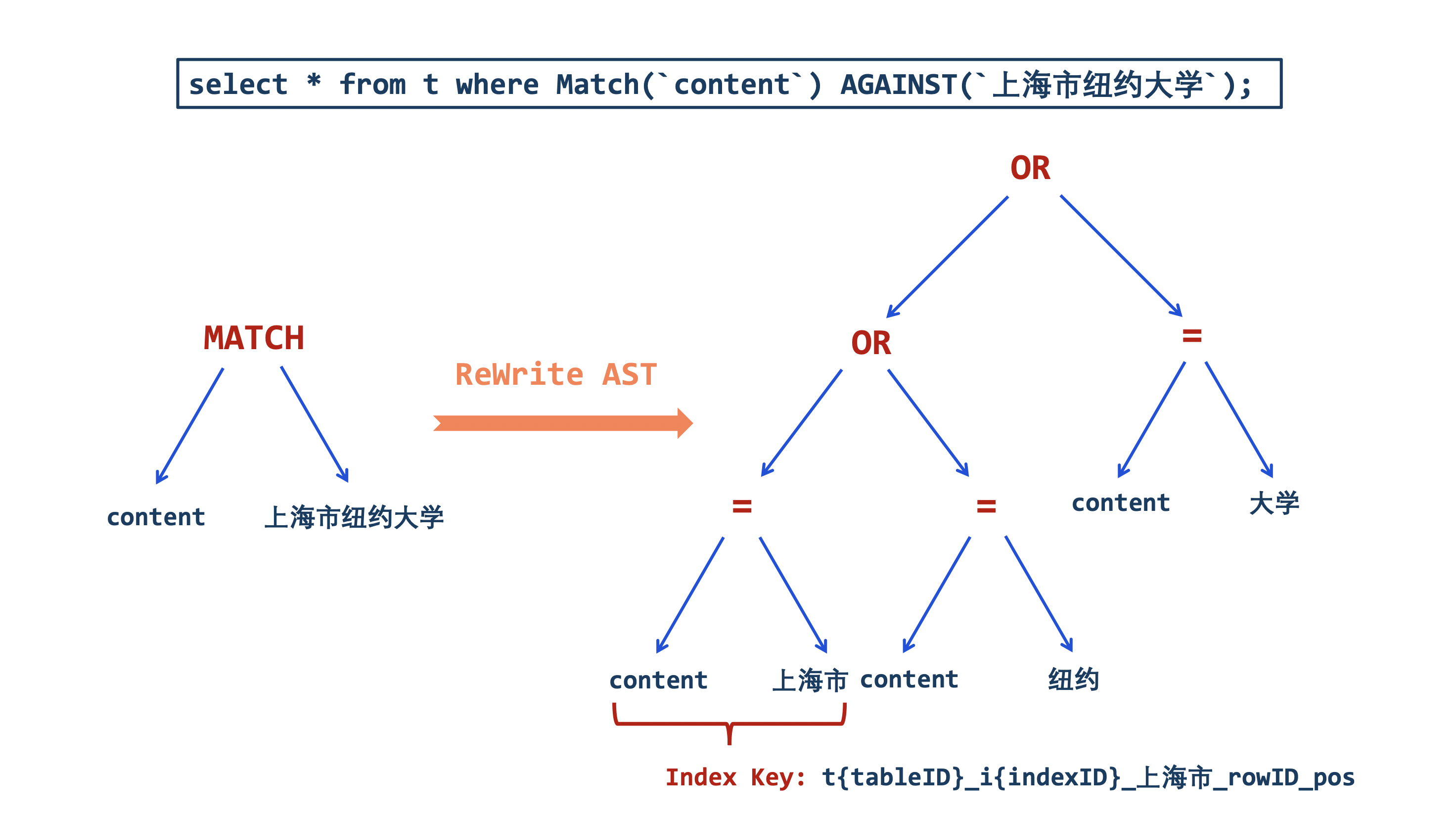
(3) 同义词拓展功能的实现(AI4DB): 传统的倒排索引的同义词拓展功能往往采用同义词词典,由提前预置的同义词词典或者用户自定义的同义词词典生成某些特定词的同义词。该方法虽然实现简单、效率高,但存在着预置的同义词有限、不灵活和无法自适应语境等问题。
TiInverted采用一种通过对词与词之间关系建模的方法,称为Word2Word,从而用AI模型优化倒排索引(AI4DB)。传统 FULLTEXT 索引与 AI4DB 比较:

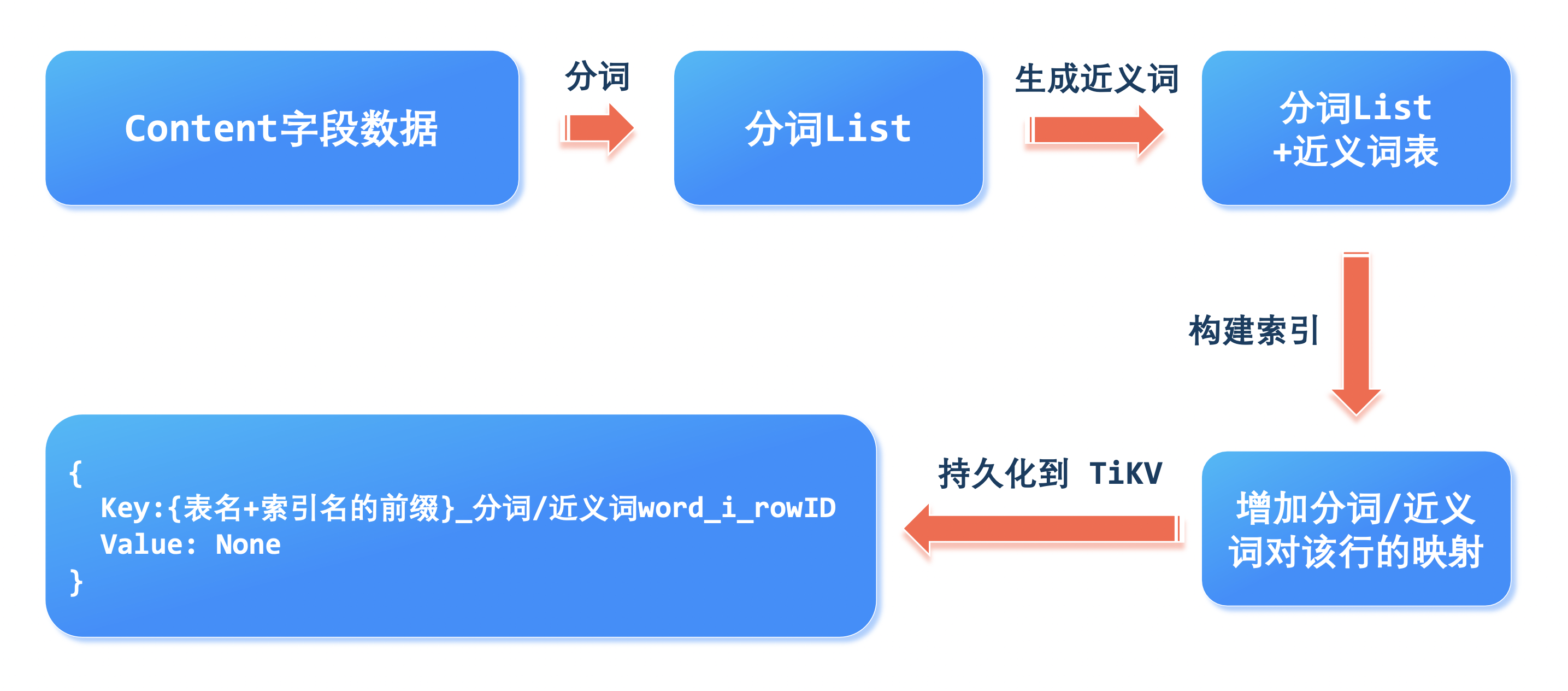
Word2Word的思路是,通过对大语料(wikipedia中文语料等)进行预训练,获得通用场景下词与词之间的统计关系。再根据用户索引字段的语料对词与词之间的关系进行fine-tune。最后通过词与词之间的关系生成指定词的同义词。该方法相比于Word2Vec或者基于Bert的同义词生成模型,具有低计算力消耗,时延低,低空间复杂度和更符合语境等优势。
在开启同义词拓展模式时,倒排索引的构建过程如下:
(4) TiInverted 的 Create / Update / Drop 实现逻辑:
修改TiDB 中 Index Struct 实现 TiInverted
评测 TiInverted 是否会带来更好的体验,主要目标如下:
- 设计多种评测负载,以验证检索速度是否获得提升
- 采用调研的方式分析检索结果是否更加人性化