Created
December 16, 2022 06:43
-
-
Save Jamesscn/62bf33550d7d2c5c4110328a35022538 to your computer and use it in GitHub Desktop.
Python Grapher
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #!/usr/bin/python3 | |
| import json, os, re | |
| from rich import print | |
| from typing import Tuple, Dict | |
| html_template = """ | |
| <html> | |
| <head> | |
| <script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script> | |
| <script type="text/javascript"> | |
| google.charts.load("current", {packages:["orgchart"]}); | |
| google.charts.setOnLoadCallback(drawChart); | |
| function drawChart() { | |
| var data = new google.visualization.DataTable(); | |
| data.addColumn("string", "Function"); | |
| data.addColumn("string", "Parent"); | |
| data.addColumn("string", "Tooltip"); | |
| data.addRows(%s); | |
| for(var i = 0; i < data.getNumberOfRows(); i++) { | |
| data.setRowProperty(i, "style", "width: 300px; -webkit-border-radius: 0px; background: rgb(255, 193, 107); border: 1px solid black; padding: 10px"); | |
| data.setRowProperty(i, "selectedStyle", "width: 300px; -webkit-border-radius: 0px; background: rgb(255, 220, 171); border: 2px solid black; padding: 10px"); | |
| } | |
| var chart = new google.visualization.OrgChart(document.getElementById("chart_div")); | |
| chart.draw(data, { | |
| "allowHtml": true, | |
| "allowCollapse": true | |
| }); | |
| } | |
| </script> | |
| </head> | |
| <body> | |
| <div id="chart_div"></div> | |
| </body> | |
| </html> | |
| """ | |
| graph_table = [] | |
| default_name = "" | |
| def get_entry_point() -> Tuple[str, str]: | |
| """Asks the user for the location of the file to start the analysis from. | |
| Returns: | |
| A tuple containing the file to begin the analysis and the name of the main function. | |
| """ | |
| print("Please enter the path to the file with the main function") | |
| print("> ", end = "") | |
| entry_point_path = input() | |
| print("Please enter the name of the main function") | |
| print("> ", end = "") | |
| main_func = input() | |
| entry_point = entry_point_path.split("/")[-1] | |
| directory = entry_point_path[:-len(entry_point)] | |
| if len(directory) > 0: | |
| os.chdir(directory) | |
| if entry_point.endswith(".py"): | |
| entry_point = entry_point[:-3] | |
| return entry_point, main_func | |
| def parse_docstring(docstring: str) -> Dict: | |
| """Reads in a docstring and returns a dictionary of the summary, arguments and return type. At the current moment | |
| it can only parse docstrings in the sphinx format. | |
| Arguments: | |
| docstring -- A string containing a docstring. | |
| Returns: | |
| A dictionary of information obtained from the docstring. | |
| """ | |
| docinfo = { | |
| "summary": "", | |
| "params": {}, | |
| "return": "" | |
| } | |
| summary = "" | |
| param_regex = r"(.*):param (.*):(.*)" | |
| return_regex = r"(.*):return:(.*)" | |
| reading_summary = True | |
| for line in docstring.splitlines(): | |
| param_match = re.match(param_regex, line) | |
| return_match = re.match(return_regex, line) | |
| if param_match != None: | |
| param_name = param_match.group(2).strip() | |
| param_desc = param_match.group(3).strip() | |
| docinfo["params"][param_name] = param_desc | |
| reading_summary = False | |
| if return_match != None: | |
| return_desc = return_match.group(2).strip() | |
| docinfo["return"] = return_desc | |
| reading_summary = False | |
| if reading_summary: | |
| line = line.replace('"""', '').strip() | |
| if len(line) > 0: | |
| summary += " " + line | |
| docinfo["summary"] = summary.strip() | |
| return docinfo | |
| def get_code_context(entry_point: str) -> Dict: | |
| """Obtains a dictionary called the context, with detailed information about the functions and classes and how they | |
| interact with each other between files. | |
| Arguments: | |
| entry_point -- The name of the file where the analysis will start. | |
| Returns: | |
| A dictionary context containing information about the classes, functions and imports of each code file. | |
| """ | |
| global default_name | |
| context = {} | |
| files_to_analyze = [entry_point] | |
| function_signature_regex = r"(\s*)def (\w+)\((.*)\)(.*)\:" | |
| function_call_regex = r"(\s*).*?([\w\.\_\-]+)\(" | |
| class_regex = r"(\s*)class (\w+)\:" | |
| import_regex = r"from (\w+) import (.*)" | |
| docstring_regex = r"\"\"\"" | |
| reading_docstring = False | |
| curr_docstring = "" | |
| while len(files_to_analyze) > 0: | |
| file_name = files_to_analyze.pop() + ".py" | |
| if file_name in context: | |
| continue | |
| if os.path.exists(file_name): | |
| context[file_name] = { | |
| "classes": [default_name], | |
| "functions": {}, | |
| "imports": {} | |
| } | |
| last_function = default_name | |
| last_function_indent = 0 | |
| last_class = default_name | |
| last_class_indent = 0 | |
| with open(file_name) as file: | |
| for line in file: | |
| unstripped = line | |
| line = line.rstrip() | |
| function_signature_match = re.match(function_signature_regex, line) | |
| function_call_match = re.findall(function_call_regex, line) | |
| class_match = re.match(class_regex, line) | |
| import_match = re.match(import_regex, line) | |
| docstring_match = re.search(docstring_regex, line) | |
| if reading_docstring: | |
| curr_docstring += unstripped | |
| if docstring_match == None: | |
| continue | |
| reading_docstring = False | |
| context[file_name]["functions"][last_function]["docstring"] = curr_docstring | |
| continue | |
| if function_signature_match != None: | |
| indentation = len(function_signature_match.group(1)) | |
| name = function_signature_match.group(2) | |
| parameters = function_signature_match.group(3).replace(" ", "") | |
| return_type = function_signature_match.group(4) | |
| parameter_list = [] | |
| if len(parameters) > 0: | |
| parameter_list = parameters.split(",") | |
| if "->" in return_type: | |
| return_type = return_type.split("->")[1].strip() | |
| curr_class = default_name | |
| if indentation > last_class_indent: | |
| curr_class = last_class | |
| context[file_name]["functions"][name] = { | |
| "name": name, | |
| "parameters": parameter_list, | |
| "return_type": return_type, | |
| "calls": [], | |
| "class": curr_class, | |
| "docstring": "" | |
| } | |
| last_function = name | |
| last_function_indent = indentation | |
| elif class_match != None: | |
| indentation = len(class_match.group(1)) | |
| name = class_match.group(2) | |
| if name not in context[file_name]["classes"]: | |
| context[file_name]["classes"].append(name) | |
| last_class = name | |
| last_class_indent = indentation | |
| elif import_match != None: | |
| library = import_match.group(1) | |
| items = import_match.group(2).replace(" ", "") | |
| item_list = items.split(",") | |
| if library not in context[file_name]["imports"]: | |
| context[file_name]["imports"][library] = [] | |
| for item in item_list: | |
| if item not in context[file_name]["imports"][library]: | |
| context[file_name]["imports"][library].append(item) | |
| elif docstring_match != None: | |
| curr_docstring = unstripped | |
| reading_docstring = True | |
| else: | |
| if len(function_call_match) > 0: | |
| indentation = len(function_call_match[0][0]) | |
| for function_call in function_call_match: | |
| name = function_call[1] | |
| curr_function = default_name | |
| if indentation > last_function_indent: | |
| curr_function = last_function | |
| if name not in context[file_name]["functions"][curr_function]["calls"]: | |
| context[file_name]["functions"][curr_function]["calls"].append(name) | |
| for other_file_name in context[file_name]["imports"]: | |
| files_to_analyze.append(other_file_name) | |
| for file_name in context: | |
| for function_name in context[file_name]["functions"]: | |
| docstring = context[file_name]["functions"][function_name]["docstring"] | |
| if len(docstring) > 0: | |
| docstring_dict = parse_docstring(docstring) | |
| else: | |
| docstring_dict = {} | |
| context[file_name]["functions"][function_name]["docstring"] = docstring_dict | |
| return context | |
| def add_function_to_graph(curr_file: str, curr_func: str, parent_file: str, parent_func: str, curr_func_dict: Dict) -> None: | |
| """Summarizes a function from a particular part of the final tree and stores that summary in an array which is sent to | |
| the Google charts DataTable object. | |
| Arguments: | |
| curr_file -- The name of the file the function is in. | |
| curr_func -- The name of the function. | |
| parent_file -- The name of the file the function is called in. | |
| parent_func -- The name of the function that is calling the current function. | |
| curr_func_dict -- A dictionary containing information about the current function. | |
| """ | |
| global graph_table, default_name | |
| description = "" | |
| if curr_func_dict != None: | |
| description += f"<p>File: {curr_file}</p>" | |
| description += f"<p><strong>{curr_func}()</strong></p>" | |
| curr_class = curr_func_dict["class"] | |
| docstring = curr_func_dict["docstring"] | |
| if "summary" in docstring: | |
| summary = docstring["summary"] | |
| description += f"<p>{summary}</p>" | |
| description += f"<br>" | |
| if curr_class != default_name: | |
| description += f"<p>Member of the class {curr_class}</p>" | |
| if len(curr_func_dict["parameters"]) > 0: | |
| doc_params = {} | |
| if "params" in docstring: | |
| doc_params = docstring["params"] | |
| description += f"<p><strong>Parameters: </strong></p><ul>" | |
| for parameter in curr_func_dict["parameters"]: | |
| name = parameter | |
| type = "unknown" | |
| param_summary = "" | |
| if ":" in parameter: | |
| name, type = parameter.split(":") | |
| if name in doc_params: | |
| param_summary = ": " + doc_params[name] | |
| description += f"<li><em>{name} of type {type}</em>{param_summary}</li>" | |
| description += "</ul>" | |
| return_type = curr_func_dict["return_type"] | |
| if return_type != "None": | |
| return_summary = "" | |
| if return_type == "": | |
| return_type = "unknown" | |
| if "return" in docstring: | |
| if len(docstring["return"]) > 0: | |
| return_summary = ": " + docstring["return"] | |
| description += f"<p><em>Returns a variable of type {return_type}</em>{return_summary}</p>" | |
| else: | |
| description += f"<p>External library: {curr_file[:-3]}</p>" | |
| description += f"<p>{curr_func}()</p>" | |
| graph_table.append([ | |
| { | |
| "v": curr_file + curr_func, | |
| "f": description | |
| }, | |
| parent_file + parent_func, | |
| "" | |
| ]) | |
| def get_function_tree(entry_point_file: str, main_func: str, context: Dict) -> Dict: | |
| """Obtains a tree like structure of all the function calls that are made. | |
| Arguments: | |
| entry_point_file -- The name of the file where the main function resides. | |
| main_func -- The name of the main function. | |
| context -- A dictionary containing context regarding the functions that are called in all the code files. | |
| Returns: | |
| A dictionary containing the tree of function calls. | |
| """ | |
| main_parent_dict = { | |
| "name": "", | |
| "children": {} | |
| } | |
| function_stack = [(entry_point_file, main_func, entry_point_file, main_parent_dict)] | |
| while len(function_stack) > 0: | |
| curr_file, curr_func, parent_file, parent_dict = function_stack.pop() | |
| parent_func = parent_dict["name"] | |
| if curr_file not in context: | |
| parent_dict["children"][curr_func] = {} | |
| add_function_to_graph(curr_file, curr_func, parent_file, parent_func, None) | |
| continue | |
| if curr_func in context[curr_file]["functions"]: | |
| curr_func_dict = context[curr_file]["functions"][curr_func] | |
| parent_dict["children"][curr_func] = curr_func_dict | |
| add_function_to_graph(curr_file, curr_func, parent_file, parent_func, curr_func_dict) | |
| else: | |
| #I am assuming there is one class per file | |
| class_name = curr_func | |
| if "__init__" in context[curr_file]["functions"]: | |
| curr_func = "__init__" | |
| curr_func_dict = context[curr_file]["functions"][curr_func] | |
| if not curr_func_dict["class"] == class_name: | |
| print("Error! Could not find function for class %s." % class_name) | |
| continue | |
| else: | |
| print("Error! Could not find function for class %s." % class_name) | |
| continue | |
| if "children" in curr_func_dict: | |
| continue | |
| curr_func_dict["children"] = {} | |
| for function_name in curr_func_dict["calls"]: | |
| if function_name in context[curr_file]["functions"]: | |
| function_stack.append((curr_file, function_name, curr_file, curr_func_dict)) | |
| else: | |
| for file_name in context[curr_file]["imports"]: | |
| if function_name in context[curr_file]["imports"][file_name]: | |
| function_stack.append((file_name + ".py", function_name, curr_file, curr_func_dict)) | |
| del curr_func_dict["calls"] | |
| func_tree = main_parent_dict["children"][main_func] | |
| return func_tree | |
| if __name__ == "__main__": | |
| """The main code obtains the context dictionary and uses it to construct the function tree, which is then used to | |
| create the variable graph_table. This variable is then inserted into the HTML template and is parsed by Google | |
| Charts as a DataTable structure, which will allow it to be visualized. | |
| After running this program one can find the analyzed graph of functions in the output.html file. | |
| """ | |
| entry_point, main_func = get_entry_point() | |
| context = get_code_context(entry_point) | |
| #the context json is quite cool! | |
| #print(json.dumps(context, indent = 4)) | |
| entry_point_file = entry_point + ".py" | |
| if main_func not in context[entry_point_file]["functions"]: | |
| print("Error! The function %s could not be found in %s" % (main_func, entry_point_file)) | |
| exit(1) | |
| func_tree = get_function_tree(entry_point_file, main_func, context) | |
| with open(entry_point + "-analysis.json", "w") as output_file: | |
| json.dump(func_tree, output_file, indent = 4) | |
| graph_table[0][1] = "" | |
| graph_table_string = json.dumps(graph_table) | |
| with open("output.html", "w") as output_file: | |
| output_file.write(html_template % graph_table_string) |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
This program scans code in Python and creates a graph of all the function calls between files with detailed information based on type hints and docstrings. The graph can be seen in the output.html file, and would like the following:
This is a preview of what the source code behind this graph looks like:
example1.py:
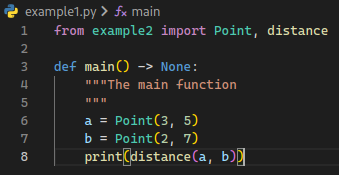
example2.py: