内存分配方式有三种:
1、从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
2、在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
3、从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由程序员决定,使用非常灵活,但如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,频繁地分配和释放不同大小的堆空间将会产生堆内碎块。
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。
当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放 掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理
From a correctness standpoint, you don’t need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language. The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function’s stack frame. However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack. In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap. However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.
准确地说,你并不需要知道。Golang 中的变量只要被引用就一直会存活,存储在堆上还是栈上由内部实现决定而和具体的语法没有关系。 知道变量的存储位置确实和效率编程有关系。如果可能,Golang 编译器会将函数的局部变量分配到函数栈帧(stack frame)上。然而,如果编译器不能确保变量在函数 return 之后不再被引用,编译器就会将变量分配到堆上。而且,如果一个局部变量非常大,那么它也应该被分配到堆上而不是栈上。 当前情况下,如果一个变量被取地址,那么它就有可能被分配到堆上。然而,还要对这些变量做逃逸分析,如果函数 return 之后,变量不再被引用,则将其分配到栈上。
简单来说就是原本应在栈上分配内存的对象,逃逸到了堆上进行分配。
如果能在栈上进行分配,那么只需要两个指令,入栈和出栈,GC压力也小了。所以相比之下,在栈上分配代价会小很多。
package main
func foo() *int {
var x int
return &x
}
func bar() int {
x := new(int)
*x = 1
return *x
}
func main() {
}查看逃逸情况:
➜ go_share git:(master) ✗ go run -gcflags '-m -l' escape.go
# command-line-arguments
./escape.go:5:9: &x escapes to heap
./escape.go:4:6: moved to heap: x
./escape.go:9:10: bar new(int) does not escapevar global *int
func f() {
var x int
x = 1
global = &x
}
func g() {
y := new(int)
*y = 1
}f函数里的x变量必须在堆上分配,因为它在函数退出后依然可以通过包一级的global变量找到,虽然它是在函数内部定义的;用Go语言的术语说,这个x局部变量从函数f中逃逸了。相反,当g函数返回时,变量*y将是不可达的,也就是说可以马上被回收的。因此,y并没有从函数g中逃逸,编译器可以选择在栈上分配y的存储空间(译注:也可以选择在堆上分配,然后由Go语言的GC回收这个变量的内存空间),虽然这里用的是new方式。其实在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。
Go语言的自动垃圾收集器对编写正确的代码是一个巨大的帮助,但也并不是说你完全不用考虑内存了。你虽然不需要显式地分配和释放内存,但是要编写高效的程序你依然需要了解变量的生命周期。例如,如果将指向短生命周期对象的指针保存到具有长生命周期的对象中,特别是保存到全局变量时,会阻止对短生命周期对象的垃圾回收(从而可能影响程序的性能)。
Go的内存分配器采用了跟tcmalloc库相同的实现,是一个带内存池的分配器,底层直接调用操作系统的mmap等函数。
不同点:局部缓存并不是分配给进程或者线程,而是分配给Processer处理器(这个还需要说一下go的goroutine实现)
1 它会向操作系统申请大块内存,自己管理这部分内存
2 它是一个池子,当上层释放内存时它不实际归还给操作系统,而是放回池子重复利用。
问题:内存碎片如何利用,提高效率?Go是一个支持goroutine这种多线程的语言,如何考虑在多线程下的稳定性和效率问题?
在避免内存碎片方面,大块内存直接按页为单位分配,小块内存会切成各种不同的固定大小的块,申请做任意字节内存时会向上取整到最接近的块,将整块分配给申请者以避免随意切割。
在多线程方面,很自然的做法就是每条线程都有自己的本地的内存,然后有一个全局的分配链,当某个线程中内存不足后就向全局分配链中申请内存。这样就避免了多线程同时访问共享变量时的加锁。
分配器的数据结构包括:
FixAlloc: 固定大小(128kB)的对象的空闲链分配器,被分配器用于管理存储
MHeap: 分配堆,按页的粒度进行管理(4kB)
MSpan: 一些由MHeap管理的页
MCentral: 对于给定尺寸类别的共享的free list
MCache: 用于小对象的每M一个的cache
通过next和prev,组成一个双向链表,mspan负责管理从startAddr开始的N个page的地址空间。是基本的内存分配单位。是一个管理内存的基本单位。
//保留重要成员变量
type mspan struct {
next *mspan // 链表中下个span
prev *mspan // 链表中上个span startAddr uintptr // 该mspan的起始地址
freeindex uintptr // 表示分配到第几个块
npages uintptr // 一个span中含有几页
sweepgen uint32 // GC相关
incache bool // 是否被mcache占用
spanclass spanClass // 0 ~ _NumSizeClasses之间的一个值,比如,为3,那么这个mspan被分割成32byte的块
}mspan的地址是一段连续的;start:基地址+(页号*页大小),可以有多页
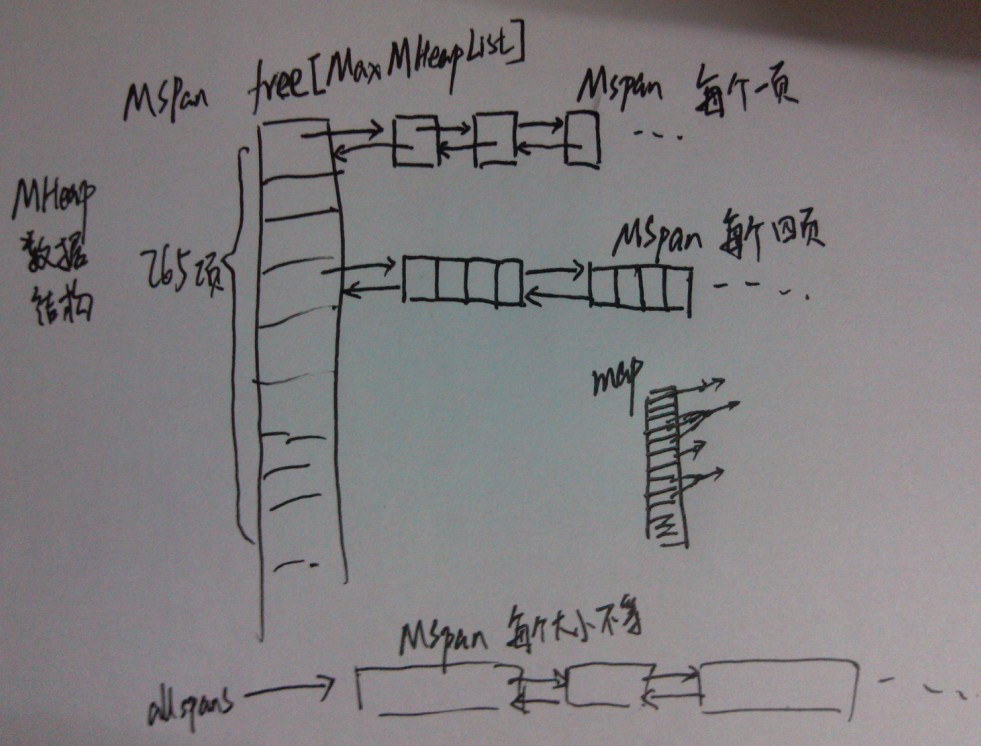
type mheap struct {
lock mutex // 是公有的,需要加锁
free [_MaxMHeapList]mSpanList // 未分配的spanlist,比如free[3]是由包含3个 page 的 mspan 组成的链表
freelarge mTreap // mspan组成的链表,每个mspan的 page 个数大于_MaxMHeapList
busy [_MaxMHeapList]mSpanList // busy lists of large spans of given length
busylarge mSpanList // busy lists of large spans length >= _MaxMHeapList
allspans []*mspan // 所有申请过的 mspan 都会记录在 allspans
spans []*mspan // 记录 arena 区域页号(page number)和 mspan 的映射关系
arena_start uintptr // arena是Golang中用于分配内存的连续虚拟地址区域,这是该区域开始的指针
arena_used uintptr // 已经使用的内存的指针
arena_alloc uintptr
arena_end uintptr
central [numSpanClasses]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte //避免伪共享(false sharing)问题
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // mcache分配器
}方便理解的mheap大图
mheap对mspan的组织管理核心
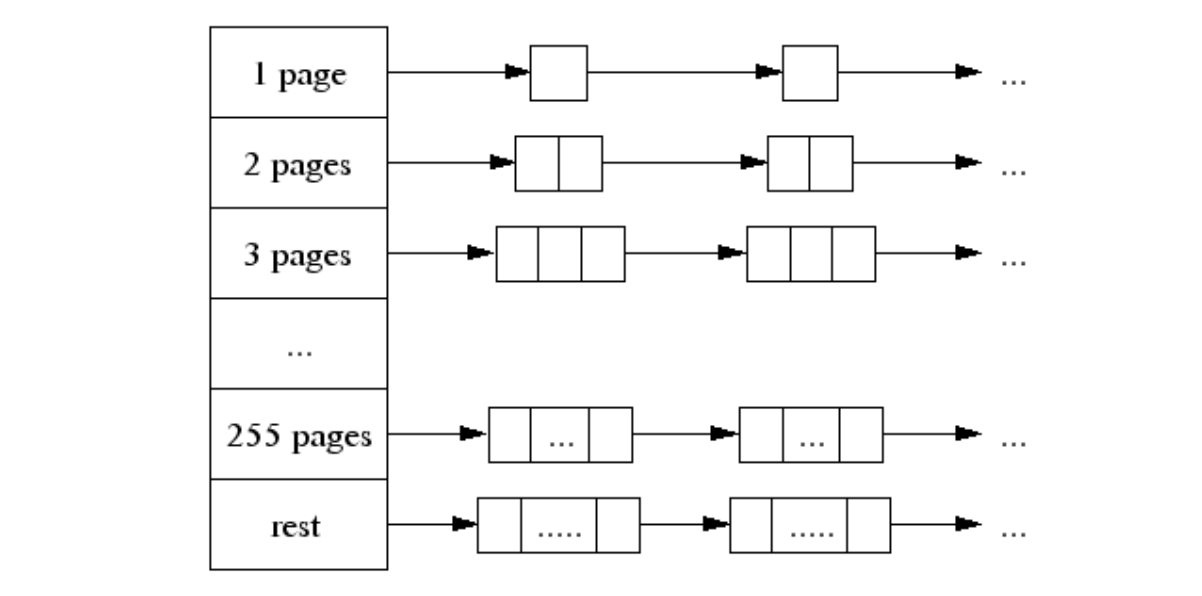
说明: 从free[i]出去的MSpan每个大小都i页 总共256个槽位,再大了之后,大小就不固定了,由large链起来。
tcmalloc使用span来管理内存分页,一个span可以包含几个连续分页。span的状态只有未分配、作为大对象分配、作为小对象分配
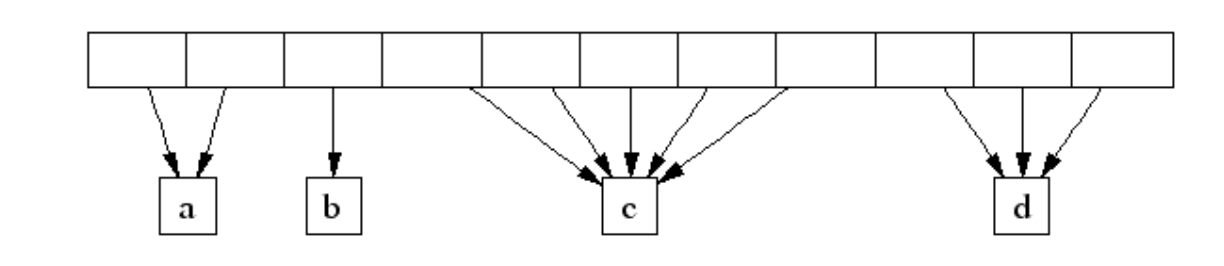
内存分配: 如果能从free[]的分配池中分配,则从其中分配。如果发生切割则将剩余部分放回free[]中。比如要分配2页大小的空间,从图上2号槽位开始寻找,直到4号槽位有可用的MSpan,则拿一个出来,切出两页,剩余的部分再放回2号槽位中。 否则从large链表中去分配,按BestFit算法去找一块可用空间。
垃圾回收: 回收一个MSpan时,首先会查找它相邻的页的址址,再通过map映射得到该页对应的MSpan,如果MSpan的state是未使用,则可以将两者进行合并。最后会将这页或者合并后的页归还到free[]分配池或者是large中。
// Per-thread (in Go, per-P) cache for small objects.
// No locking needed because it is per-thread (per-P).
type mcache struct {
// The following members are accessed on every malloc,
// so they are grouped here for better caching.
next_sample int32 // trigger heap sample after allocating this many bytes
local_scan uintptr // bytes of scannable heap allocated
// 小对象分配器,小于 16 byte 的小对象都会通过 tiny 来分配。
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
// The rest is not accessed on every malloc.
alloc [_NumSizeClasses]*mspan // spans to allocate from
stackcache [_NumStackOrders]stackfreelist
// Local allocator stats, flushed during GC.
local_nlookup uintptr // number of pointer lookups
local_largefree uintptr // bytes freed for large objects (>maxsmallsize)
local_nlargefree uintptr // number of frees for large objects (>maxsmallsize)
local_nsmallfree [_NumSizeClasses]uintptr // number of frees for small objects (<=maxsmallsize)
}分配小对象的时候直接从MCache中分配,就不用加锁了,这是Go能够在多线程环境中高效地进行内存分配的重要原因。MCache是用于小对象的分配
alloc [_NumSizeClasses]*mspan,这是一个大小为 67 的指针(指针指向 mspan )数组(_NumSizeClasses = 67),这是一个大小为 67 的指针(指针指向 mspan )数组(_NumSizeClasses = 67),每个数组元素用来包含特定大小的块。当要分配内存大小时,为 object 在 alloc 数组中选择合适的元素来分配。67 种块大小为 0,8 byte, 16 byte, … ,这个和 tcmalloc 稍有区别。
//file: sizeclasses.go
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}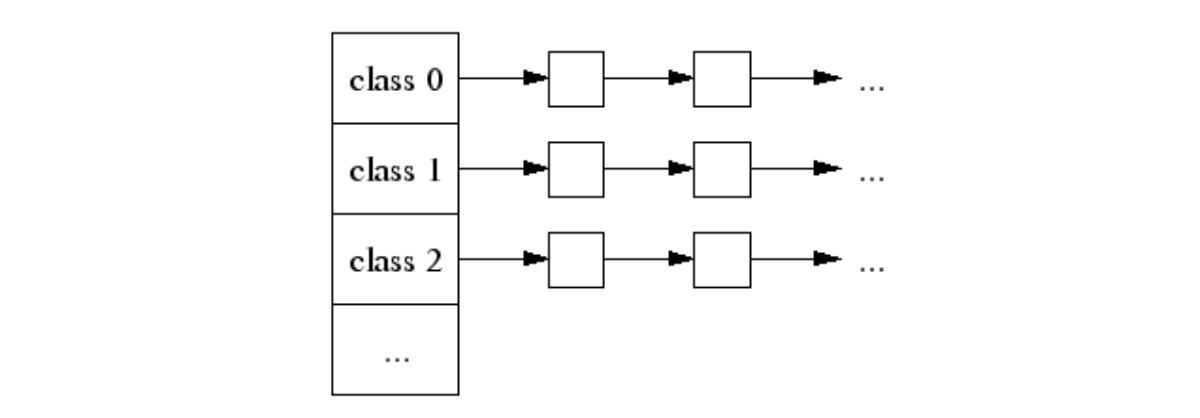
分配一个小对象(<32kB)的过程:
将小对象大小向上取整到一个对应的尺寸类别,查找相应的MCache的空闲链表。如果链表不空,直接从上面分配一个对象。这个过程可以不必加锁。 如果MCache自由链是空的,通过从MCentral自由链拿一些对象进行补充。 如果MCentral自由链是空的,则通过MHeap中拿一些页对MCentral进行补充,然后将这些内存截断成规定的大小。 如果MHeap是空的,或者没有足够大小的页了,从操作系统分配一组新的页(至少1MB)。分配一大批的页分摊了从操作系统分配的开销。
释放一个小对象也是类似的过程:
查找对象所属的尺寸类别,将它添加到MCache的自由链。 如果MCache自由链太长或者MCache内存大多了,则返还一些到MCentral自由链。 如果在某个范围的所有的对象都归还到MCentral链了,则将它们归还到页堆。
MCentral层次是作为MCache和MHeap的连接。对上,它从MHeap中申请MSpan;对下,它将MSpan划分成各种小尺寸对象,提供给MCache使用
struct MCentral
{
Lock;
int32 sizeclass;
MSpan nonempty;
MSpan empty;
int32 nfree;
};MCentral结构中,有一个nonempty的MSpan链和一个empty的MSpan链,分别表示还有空间的MSpan和装满了对象的.
分配: 直接从MCentral->nonempty->freelist分配。如果发现freelist空了,则说明这一块MSpan满了,将它移到MCentral->empty。
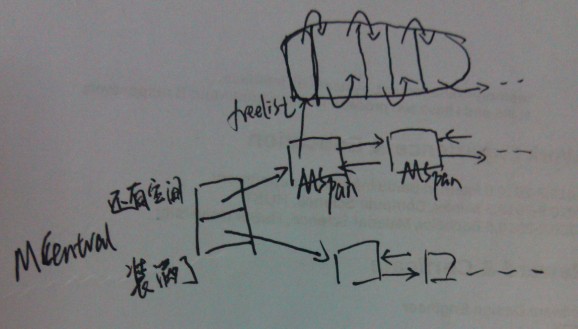
回收: 回收比分配复杂,因为涉及到合并。这里的合并是通过引用计数实现的。从MSpan中每划出一个对象,则引用计数加一,每回收一个对象,则引用计数减一。如果减完之后引用计数为零了,则说明这整块的MSpan已经没被使用了,可以将它归还给MHeap。