Created
March 14, 2018 03:59
-
-
Save KyoungHa-Park/118a4d105881fde95e20c33be9c5a37c to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| {"nbformat":4,"nbformat_minor":0,"metadata":{"colab":{"name":"Coursera Lecture-ML.ipynb","version":"0.3.2","views":{},"default_view":{},"provenance":[]}},"cells":[{"metadata":{"id":"1OcF1a9KTgVl","colab_type":"text"},"cell_type":"markdown","source":["<작성기준>\n","\n","+ 전체 목차는 Course ML 강의목록 기반르로 함\n","\n","+ Course ML 목차에 개념중심으로 정리하되, 개념간 흐름(연관성)에 유의하여 정리한다.\n","\n","+ 용어에 대해서는 다양한 출처가 있으므로, 출처를 별표기한다\n","\n","+ 1개념 = 1이미지 형식으로 정리함"]},{"metadata":{"id":"YSCcuqEtm99P","colab_type":"text"},"cell_type":"markdown","source":["<참고내용>\n","+ http://untitledtblog.tistory.com/43?category=667127\n","+ http://umbum.tistory.com/category/Machine%20Learning/Theory\n","+ "]},{"metadata":{"id":"rUHnJUHIfDbW","colab_type":"text"},"cell_type":"markdown","source":["#1.Linear Regression with One Variable"]},{"metadata":{"id":"f39xzOFEirwe","colab_type":"text"},"cell_type":"markdown","source":["##1.1.Model and Cost Function"]},{"metadata":{"id":"wYKJktWPirzC","colab_type":"text"},"cell_type":"markdown","source":["##1.2.Parameter Learning"]},{"metadata":{"id":"SGXhJ3A_ir3V","colab_type":"text"},"cell_type":"markdown","source":["##1.3.Linear Algebra Review"]},{"metadata":{"id":"hC1igj5kfDd4","colab_type":"text"},"cell_type":"markdown","source":["#2.Linear Regression with Multiple Variables"]},{"metadata":{"id":"lXIaNXy-fDgS","colab_type":"text"},"cell_type":"markdown","source":["##2.1Environment Setup Instructions\n"]},{"metadata":{"id":"unxg8ouifDiw","colab_type":"text"},"cell_type":"markdown","source":["##2.2.Multivariate Linear Regression\n"]},{"metadata":{"id":"bbLIJcUGgH9B","colab_type":"text"},"cell_type":"markdown","source":["##2.3.Computing Parameters Analytically"]},{"metadata":{"id":"NGyAia-NgH_b","colab_type":"text"},"cell_type":"markdown","source":["#3.Logistic Regression"]},{"metadata":{"id":"h1fo_joZgID7","colab_type":"text"},"cell_type":"markdown","source":["#4.Regularization"]},{"metadata":{"id":"hFGjZ9UhfDlE","colab_type":"text"},"cell_type":"markdown","source":["#5.Neural Networks: Representation"]},{"metadata":{"id":"HJ7caEwVfTZZ","colab_type":"text"},"cell_type":"markdown","source":["##5.1.Motivations"]},{"metadata":{"id":"ZINYk7ztkHyQ","colab_type":"text"},"cell_type":"markdown","source":["* 인공신경망은 **가중치 매개변수 값**의 설정을 입력으로부터 **자동으로 학습**하는 능력을 가진 모델을 말한다.\n","\n","* 좁은 의미에서는 **오차역전파법**을 이용한 **다층** 퍼셉트론 모델(=**다변량** 선형회귀 모형)을 가리키는 경우도 있다.\n"," \n"," (단, 이는 인공신경망에만 국한되지 않는다)\n","\n","* 다중 퍼셉트론은 인공신경망을 구현하는 알고리즘의 한 종류이다.\n","\n","* 다중 퍼셉트론(multi-layer perceptron) 외에, 합성곱 신경망(Convolution Neural Network), 순환적 신경망(Recurrent Neural Network)등이 있다.\n"]},{"metadata":{"id":"H4bbYdZSfTcx","colab_type":"text"},"cell_type":"markdown","source":["##5.2.Neural Networks\n"]},{"metadata":{"id":"b2f7kqL_Che_","colab_type":"text"},"cell_type":"markdown","source":["1. 답이 있는 ML 문제는 [분류]와 [회귀]로 나뉜다\n"," + 분류 : 데이터가 어느 클래스에 속하느냐에 관한 문제(=dummy 변수 설정)\n"," + 회귀 : 입력 데이터에서 (연속적인) 수치를 예측하는 문제.\n"," > \n","2. 목적이 \"분류\"나 \"회귀\"냐에 따라, 출력층에서 사용하는 활성화 함수가 달라진다.\n"," + [분류]에는 softmax 함수가 이용되며,\n"," + [회귀]에는 항함 함수를 사용한다.\n"]},{"metadata":{"id":"Z9MRdr4Lfa45","colab_type":"text"},"cell_type":"markdown","source":["##5.3.Applications"]},{"metadata":{"id":"mtruR2vXUqir","colab_type":"text"},"cell_type":"markdown","source":["+ \"분류\"에 대한 논의에 집중한다.\n","+ **Learning = Representation + Evaluation + Optimization**\n","+ **Avoid Oerfitting/Generalization is important**\n","+ Data alone is not enough\n","+ More data > cleverer algorithm\n","+ Intuition fails in higher dimensions/ Curse of dimensionality\n","+ Feature engineering is the key\n","+ Learn many models/ Ensemble learning\n","+ Theoretical guarantees are not what they seem \n","+ **Simplicity does not imply accuracy**\n","+ Representable does not imply learnable\n","\n","+ 주요 고려사항(ANN)\n"," + One-hot encording\n"," + Softamx\n"," + Cross-Entropy\n"," + Cost Function\n"," + Stochastic Gradient Descent\n","\n","+ 주요 고려사항(DNN)\n"," + One-hot encording\n"," + Softamx\n"," + Cross-Entropy\n"," + Cost Function\n"," + Stochastic Gradient Descent\n"," + **Gradient Vanishing**\n"," + **Batch normalization**\n"," + **Backpropagation**\n"," + **Regulization **\n","\n","(출처) : https://medium.com/@rupak.thakur/23-deep-learning-papers-to-get-you-started-part-1-308f80d7bba2"]},{"metadata":{"id":"1E2E45zPCmHv","colab_type":"text"},"cell_type":"markdown","source":["#6.Neural Networks: Learning"]},{"metadata":{"id":"vz13OoSaCq_v","colab_type":"text"},"cell_type":"markdown","source":["##6.1 Cost Function and Backpropagation"]},{"metadata":{"id":"k3N6ph5D1Zrl","colab_type":"text"},"cell_type":"markdown","source":["**손실 함수**\n","+ 학습을 통해 최적의 가중치 매개변수를 결정하기 위한 지표\n","+ 손실 함수의 결과값(오차)을 가장 작게 만드는 가중치 매개변수를 찾는 방식으로 동작하게 된다.\n","+ 손실 함수로는 보통 다음 두가지를 주요 사용한다\n"," + **평균제곱오차(Mean Squared Error : MSE)** \n"," \n"," : 회귀에서 손실함수로 사용된다\n"," + **교차 엔트로피 오차(Cross Entropy Error : CEE)** \n"," \n"," : 분류에서 소프트맥스 함수의 손실함수로 사용된다.\n"]},{"metadata":{"id":"gO_GzM4PZ_jV","colab_type":"text"},"cell_type":"markdown","source":["소프트맥스"]},{"metadata":{"id":"AlimEkM625Zk","colab_type":"text"},"cell_type":"markdown","source":["**미니배치**\n","\n","+ 학습하는 방법중 하나로, 데이터 일부만 추려서 학습하여 손실함수를 구하는 방법\n","+ 묶은 데이터 각각에 대해 손실함수를 구한 후 모두 더하고 데이터 개수로 나누어 정규화(=표준정규분포로 변환)함"]},{"metadata":{"id":"T7MqYDte4F1U","colab_type":"text"},"cell_type":"markdown","source":["매개변수 갱신(최적화) 기법\n"," \n","+ 확률적 경사 하강법(SGD ; Stochastic Gradient Descent)\n","+ 모멘텀(Momentum)\n","+ Nesrerov(NAG) : 모멘텀을 발전시킨 기법\n","+ AdaGrad : 학습률 감소를 적용했다\n","+ RMSProp : AdaGrad의 문재를 개선한 기법\n","+ **Adam : 학습의 갱신 강도를 적응적으로 조정한다**"]},{"metadata":{"id":"bOn_7k33CvzQ","colab_type":"text"},"cell_type":"markdown","source":["##6.2 Backpropagation in Practice"]},{"metadata":{"id":"3FLm-JjKCYZh","colab_type":"text"},"cell_type":"markdown","source":["Training a Neural Network\n","\n","1. Randomly initialize the weights\n","2. Implement forward propagation to get hΘ(x(i)) for any x(i)\n","3. Implement the cost function\n","4. Implement backpropagation to compute partial derivatives\n","5. Use gradient checking to confirm that your backpropagation works. Then disable gradient checking.\n","6. Use gradient descent or a built-in optimization function to minimize the cost function with the weights in theta."]},{"metadata":{"id":"0gt_kNmH3uKc","colab_type":"text"},"cell_type":"markdown","source":["**역전파(back propagation)**\n","+ 역전파 : 역방향으로 해당 함수의 국소적 미분을 곱해 나가는 것으로, 핵심은 국소적 계산과 연쇄법칙이다\n","+ 역전파(Backpropagation)는 최적화 방법론(ex.경사하강법 : SGD)과 함께 인공신경망 학습과정에서 많이 이용된다.\n","+ 다중 퍼셉트론에서는 은닉층(hidden layer)의 목적값을 결정할 수 없기 때문에 학습을 수행할 수 없다.\n"]},{"metadata":{"id":"x_yCf1L5pe1O","colab_type":"text"},"cell_type":"markdown","source":["신경망 학습과정\n","\n","0. 하이퍼 파라미터를 초기화 한다. 그리고 2~4 을 반복한다\n","\n","1. 미니배치 : 훈련 데이터 중 일부를 무작위로 뽑아 미니배치를 만든다\n","\n"," - 1에폭(epoch)d은 학습에서 데이터만큼 데이터를 뽑아냈을 때의 횟수에 해당한다.\n"," \n"," - 20,000개의 데이터에서 배치사이즈가 500이면, 40회 반복해야 20,000개의 데이터를 사용하게 된다. \n"," \n"," 이 경우, 1 epoch = 40회 이다.\n"," \n"," - epoch이 진행 될수록 훈련 데이터에 대한 정확도가 모두 높아지는데, 일정 횟수가 지나면 시험 데이터에 대한 정확도가 떨어지기 시작한다.(=휸련 데이터에 대한 정확도가 상승한다) 이 때가 오버피팅이 시작되는 시점이다.\n","\n","2. 기울기 산출 : 가중치 매개변수에 대한 손실함수의 gradient를 구한다.\n","\n","3. 매개변수 갱신 : 경사하강법을 사용해 가중치를 2에서 계산한 gradient 지표로 갱신한다.\n","\n"]},{"metadata":{"id":"JeJbtmD3EHXv","colab_type":"text"},"cell_type":"markdown","source":["#7.Advice for Applying Machine Learning"]},{"metadata":{"id":"Bg5cYTANEJGF","colab_type":"text"},"cell_type":"markdown","source":["##7.1 Evaluating a Learning Algorithm"]},{"metadata":{"id":"FdRiBR1f49QM","colab_type":"text"},"cell_type":"markdown","source":["초기 가중치 설정\n"]},{"metadata":{"id":"ldLUqmkY5B4V","colab_type":"text"},"cell_type":"markdown","source":["**기울기 소실(Gradient Vanishing)**\n","\n"," + 0에서 멀저질수록 기울기가 0으로 수렴하기 때문에, 활성화값이 0 또는 1에 치우쳐 분포하게 되면 기울기가 점점 작아지다가 사라지는 현상을 의미한다.\n"," + 이는 활성화 함수로 사용된 sigmoid 함수가 input을 작은 output range로 비선형적으로 우겨넣기 때문에 발생하는 문지이다.\n"," + tanh 함수도 마찬가지인데, S자 곡선의 끝 부분에서 더 심하게 발생한다. \n"," + 이러한 문제는 비선형 함수를 활성화 함수로 선택하면 해결할 수 있다.(=ReLU 함수가 활용된 배경이다.)"]},{"metadata":{"id":"HkxQQtdH5JSt","colab_type":"text"},"cell_type":"markdown","source":["**배치 정규화(Batch Normalization)**\n"," \n","+ 각 Affine layer를 통화한 미니배치 단위 Output을 **표준정규분포**로 정규화하는 작업이다.\n"," \n","+ 배치 정규화의 장점은\n"," + 초기값에 크게 의존하지 않는다.\n"," + Gradient Vanishing 및 Gradient Exploding을 방지한다\n"," + Overfittign을 억제한다"]},{"metadata":{"id":"sEOxC3xGqL1g","colab_type":"text"},"cell_type":"markdown","source":["**오버피팅(Overfitting)** : error를 최소화 하는 과정에서 발생하는 오류\n","+ 학습 과정에서 epoch이 진행 될 수록 훈련 데이터에 대한 정확도가 모두 높아지면서 발생하는 현상\n","+ Training error 축소에만 집중하면서, Test error를 감안하지 않은 상황\n","+ 훈련 데이터가 충분하지만, 매개 변수가 많은(=표현력이 높은) 모델인 경우 발생한다.(<-> Ocam's Razer) \n","+ 훈련 데이터가 적은 경우에도 발생한다\n"," > "]},{"metadata":{"id":"UP8Qsp8ctc5m","colab_type":"text"},"cell_type":"markdown","source":["**Regularization** : **오버피팅을 억제**하기 위한 기법\n","+ 정규화(normalization)과는 다른 개념이다. \n","+ **오버피팅을 억제** 이므로, **학습단계**에서 이용되는 기법들 중 하나임\n"," + sprasity (L1 Regularization)\n"," + 가중치가 클수록 페널티를 부과아혀 오버피팅을 억제하는 방법\n"," + 능형회귀 idea와 유사함\n"," + 손실함수 결과에 abs(lambda)*W를 더하는 방법\n"," + weight dacay(L2 Regularization)\n"," + 가중치가 클수록 페널티를 부과아혀 오버피팅을 억제하는 방법임은 L1과 유사\n"," + LASSO 회귀 idea와 유사함\n"," + 가울기에 lambda*W를 더하는 방법\n"," + L1과 L2를 통시에 이용할 수 있으나, L2만 이용하는 것이 효과적임\n"," > 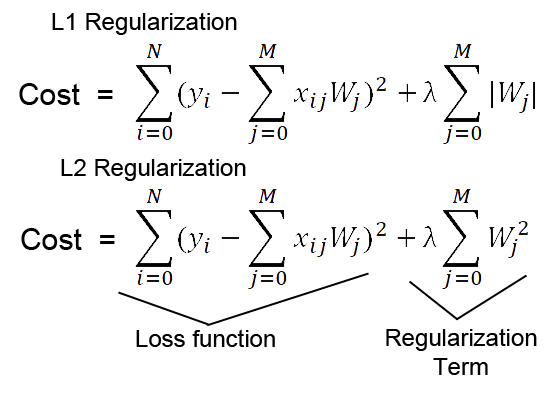\n"," \n"," 출처 : http://laid.delanover.com/difference-between-l1-and-l2-regularization-implementation-and-visualization-in-tensorflow/\n"," + dropout\n"," + 일부 layer를 제외하고 학습시키는 기법\n"," + 난수를 사용해서 일부 neuron을 0으로 만드는 방법\n"," \n"," 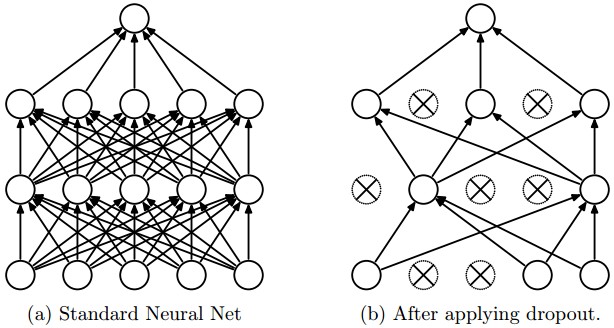"]},{"metadata":{"id":"JT7LoWElEJJG","colab_type":"text"},"cell_type":"markdown","source":["##7.2 Bias vs. Variance"]},{"metadata":{"id":"69hiZUIQEJMB","colab_type":"text"},"cell_type":"markdown","source":["#8.Support Vector Machines"]},{"metadata":{"id":"f1HX4ijDEXO4","colab_type":"text"},"cell_type":"markdown","source":["##8.1 Large Margin Classification\n"]},{"metadata":{"id":"-P_85ckeEXRO","colab_type":"text"},"cell_type":"markdown","source":["##8.2 Kernels\n"]},{"metadata":{"id":"qsEhAKfvEXUF","colab_type":"text"},"cell_type":"markdown","source":["##8.3 SVMs in Practice\n"]},{"metadata":{"id":"No1bw5Y7EXWX","colab_type":"text"},"cell_type":"markdown","source":["#9.Unsupervised Learning"]},{"metadata":{"id":"DFqTbuSeEgRl","colab_type":"text"},"cell_type":"markdown","source":["##9.1.Clustering"]},{"metadata":{"id":"ReFUzp7XEgOu","colab_type":"text"},"cell_type":"markdown","source":["#10.Dimensionality Reduction"]},{"metadata":{"id":"CuXAqjJBEgUH","colab_type":"text"},"cell_type":"markdown","source":["##10.1.Motivation"]},{"metadata":{"id":"m05YcgIHEgWh","colab_type":"text"},"cell_type":"markdown","source":["##10.2.Principal Component Analysis"]},{"metadata":{"id":"5NGAa43lhmNR","colab_type":"text"},"cell_type":"markdown","source":["##10.3.Applying PCA"]},{"metadata":{"id":"nK4hr9nThm9I","colab_type":"text"},"cell_type":"markdown","source":["#11.Anomaly Detection"]},{"metadata":{"id":"1gRenxEVhm_y","colab_type":"text"},"cell_type":"markdown","source":["##11.1.Density Estimation\n"]},{"metadata":{"id":"QPtT_uiVhnCF","colab_type":"text"},"cell_type":"markdown","source":["##11.2.Building an Anomaly Detection System\n"]},{"metadata":{"id":"hiLbL_g9hnEj","colab_type":"text"},"cell_type":"markdown","source":["##11.3.Multivariate Gaussian Distribution (Optional)"]},{"metadata":{"id":"9LwEMSWThnHA","colab_type":"text"},"cell_type":"markdown","source":["#12.Recommender Systems\n"]},{"metadata":{"id":"Od62q7jKhnJx","colab_type":"text"},"cell_type":"markdown","source":["##12.1.Predicting Movie Ratings"]},{"metadata":{"id":"1Do7-5uYh_-p","colab_type":"text"},"cell_type":"markdown","source":["##12.2.Collaborative Filtering\n"]},{"metadata":{"id":"dvJzF_jwiABB","colab_type":"text"},"cell_type":"markdown","source":["##12.3.Low Rank Matrix Factorization\n"]},{"metadata":{"id":"afT6FGhiiADc","colab_type":"text"},"cell_type":"markdown","source":["#13.Large Scale Machine Learning"]},{"metadata":{"id":"oDoOMxu_iAGA","colab_type":"text"},"cell_type":"markdown","source":["##13.1.Gradient Descent with Large Datasets\n"]},{"metadata":{"id":"EgUf9pk4iAIk","colab_type":"text"},"cell_type":"markdown","source":["##13.2.Advanced Topics"]},{"metadata":{"id":"ivH2pF9JiAK6","colab_type":"text"},"cell_type":"markdown","source":["#Application Example : Photo OCR"]},{"metadata":{"id":"yX625suAhnMj","colab_type":"text"},"cell_type":"markdown","source":[""]}]} |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment