-
-
Save Minecraftian14/718ad6c5460fb3287509c32d6fef1bcd to your computer and use it in GitHub Desktop.
| from keras.datasets import mnist | |
| from CyDifferentTypesOfLayers import * | |
| class ConvolutionLayer(LayerChain): | |
| def __init__(this, s_in: DimsND, filter_size: int, lr: float): | |
| this.conv = ConvolutiveParametersLayer(s_in, lr, (filter_size, filter_size)); | |
| this.bias = AdditiveParametersLayer(this.conv.s_out, this.conv.s_out, lr); | |
| super().__init__([this.conv, this.bias], lr); | |
| this.f = this.conv.f; | |
| this.b = this.bias.b; | |
| def predict(this, a_in: ndarray) -> ndarray: | |
| a_out = super().predict(a_in); | |
| return a_out; | |
| def forward(this, a_in: ndarray) -> ndarray: | |
| a_out = super().forward(a_in); | |
| this.a_in = this.conv.a_in; | |
| return a_out; | |
| if __name__ == '__main__': | |
| train_X: ndarray; | |
| train_y: ndarray; | |
| test_X: ndarray; | |
| test_y: ndarray; | |
| (train_X, train_y), (test_X, test_y) = mnist.load_data(); | |
| train_X = normalizeData(train_X.astype(float)); | |
| test_X = normalizeData(test_X.astype(float)); | |
| train_y = one_hot_encode(train_y); | |
| test_y = one_hot_encode(test_y); | |
| print(train_X.shape[0], test_X.shape[0]); | |
| train_X = train_X[:1000, :, :]; | |
| train_y = train_y[:1000, :]; | |
| test_X = test_X[:1000, :, :]; | |
| test_y = test_y[:1000, :]; | |
| print(*np.sum(train_y, axis=0)) | |
| print(*np.sum(test_y, axis=0)) | |
| print(train_X.shape[0], test_X.shape[0]); | |
| n = train_X.shape[2]; | |
| c = train_y.shape[1]; | |
| lr = 0.00001; | |
| train_X = train_X.reshape(train_X.shape + (1,)); | |
| test_X = test_X.reshape(test_X.shape + (1,)); | |
| # train_X = get_windows_for_mini_batch(train_X, size_of_batches=600); | |
| # train_y = get_windows_for_mini_batch(train_y, size_of_batches=600); | |
| grabber = LayerGrabber(); | |
| def create_model(): | |
| layers = []; | |
| layers.append(InputLayer((n, n, 1))); | |
| layers.append(ConvolutionLayer((n, n, 1), 3, lr)); | |
| # layers.append(MaxPoolingLayer((n, n, 1), (2, 2), lr)); | |
| layers.append(ReluLayer((n, n, 1), (n, n), lr)); | |
| # layers.append(Flatten((n, n, 1), n * n, lr)); | |
| # layers.append(ConvolutiveParametersLayer(layers[-1], lr, (3, 3), 3, striding=(2, 2))); | |
| # layers.append(ReluLayer(layers[-1])); | |
| # layers.append(ConvolutiveParametersLayer(layers[-1], lr, (3, 3), 3, striding=(2, 2))); | |
| # layers.append(DeprecatedMaxPoolingLayer(layers[-1], (2, 2, 1))); | |
| # layers.append(AdditiveParametersLayer(layers[-1], lr)); | |
| # layers.append(ReluLayer(layers[-1])); | |
| # layers.append(AdditiveParametersLayer(layers[-1], lr)); | |
| # layers.append(ConvolutionLayer(layers[-1], 3, lr)); | |
| # layers.append(MaxPoolingLayer(layers[-1], (2, 2), lr)); | |
| # layers.append(ReluLayer(layers[-1], layers[-1], lr)); | |
| layers.append(Flatten(layers[-1])); | |
| # layers.append(SuperMultiplicativeParametersLayer(layers[-1], lr, 2)); | |
| layers.append(Perceptron(layers[-1], 2, lr)); | |
| layers.append(TanHLayer(layers[-1])); | |
| # layers.append(Perceptron(layers[-1], 128, lr)); | |
| # layers.append(TanHLayer(layers[-1])); | |
| # layers.append(grabber.grab(Perceptron(layers[-1], 32, lr))); | |
| # layers.append(TanHLayer(layers[-1])); | |
| # layers.append(Perceptron(layers[-1], 32, lr)); | |
| # layers.append(TanHLayer(layers[-1])); | |
| layers.append(Perceptron(layers[-1], 32, lr)); | |
| layers.append(TanHLayer(layers[-1])); | |
| # layers.append(BackDependenceLayer(grabber.layer)); | |
| # layers.append(ResidualNetworkLayer(grabber.layer)); | |
| layers.append(Perceptron(layers[-1], 10, lr)); | |
| layers.append(SigmoidLayer(layers[-1], layers[-1], lr)); | |
| # layers = list(map(lambda l: ClipLayer(l), layers)); | |
| return LayerChain(layers, lr); | |
| model = create_model(); | |
| for l in model.layers: | |
| print(l.__class__, l.s_out); | |
| loss = BCELoss(); | |
| observer_loss = SimpleLoss(); | |
| costRecorder = PlotTestDataToo(test_X, test_y, loss, observer_loss); | |
| trainer = Trainer([ | |
| costRecorder | |
| # , AutomaticDecayingLearningRate(costRecorder, 0.1) | |
| ]); | |
| def ims(m: Layer): | |
| i = np.random.randint(c); | |
| print('using', i); | |
| plt.imshow(m.un_predict(decode(c, i))[0]); | |
| plt.title(i); | |
| plt.show(); | |
| def imc(m: Layer): | |
| beef = []; | |
| while len(beef) != 10: | |
| print("Please enter 10 floats"); | |
| beef = [float(x) for x in input().split(' ')] | |
| plt.imshow(m.un_predict(np.array([beef]))[0]); | |
| plt.title(np.argmax(beef)); | |
| plt.show(); | |
| model = trainer.start_observatory(model, train_X, train_y, | |
| loss, observer_loss, create_model, | |
| bayes_error=0, max_iterations=10, | |
| custom_commands={ | |
| 'cm': lambda m: ConfusionMatrix(test_y, m.forward(test_X)).print_matrix(), | |
| 'cmt': lambda m: ConfusionMatrix(train_y, m.forward(train_X)).print_matrix(), | |
| 'im': lambda m: ims(m), | |
| 'imc': lambda m: imc(m) | |
| }); | |
| test_yp = model.forward(test_X); | |
| print(observer_loss.cost(test_y, test_yp)[0] * 100); | |
| m = ConfusionMatrix(test_y, test_yp); | |
| m.print_matrix(); |
Minecraftian14
commented
Jun 19, 2022
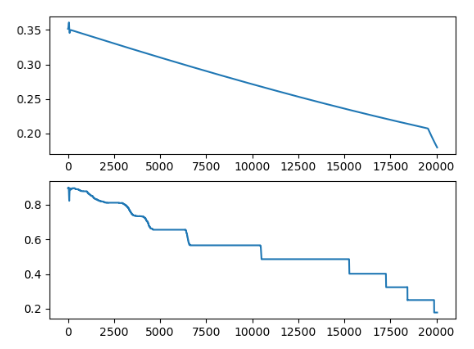
Trained on MNIST's first 5000 samples and tested against 2000 samples.
Model structure used is
5x5 Conv -> ReLU -> 3x3 Conv -> ReLU -> Perp[128] -> ReLU -> Perp[10] -> Sigmoid
and each layer had clipping on for the range [-2, 2].
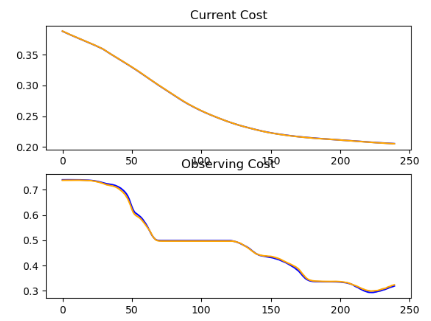

Last recorded Mean Squared Error = 0.1062083311211727
Almost 90% accuracy.
To load the parameters trained, download and rename the parameters file to parameters.npz, create a model with the above specs, start the observatory and use q command to load the parameters file.
https://drive.google.com/file/d/1-2Cd21TAt7QHZzWsGnsiGi4tWORdRXTj/view?usp=sharing
It just doesn't go below 0.1 👀
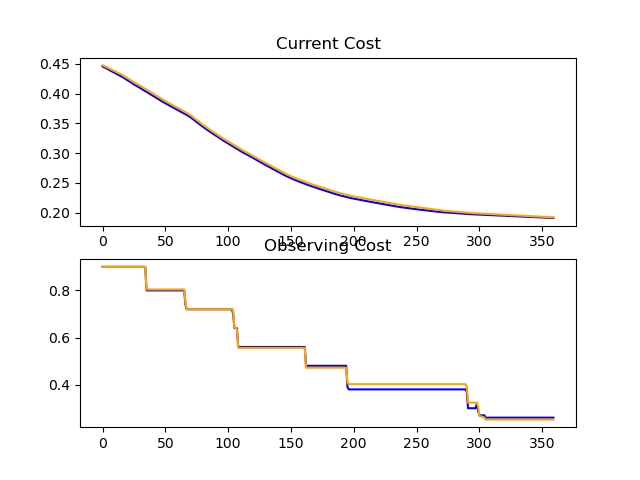
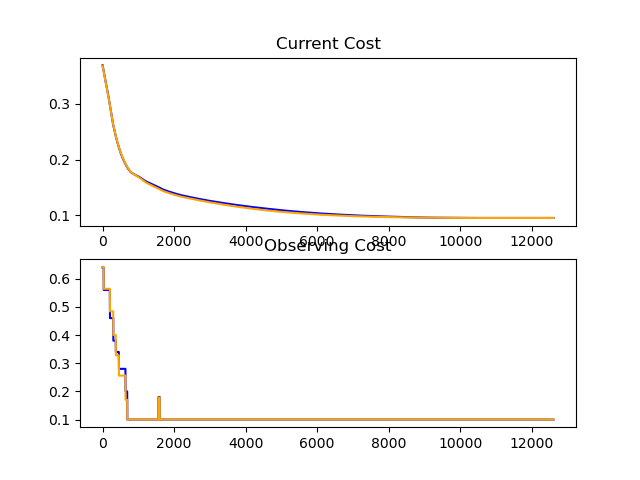
Tried with one ADAM optimized layer, but no luck against the 0.1 barrier...
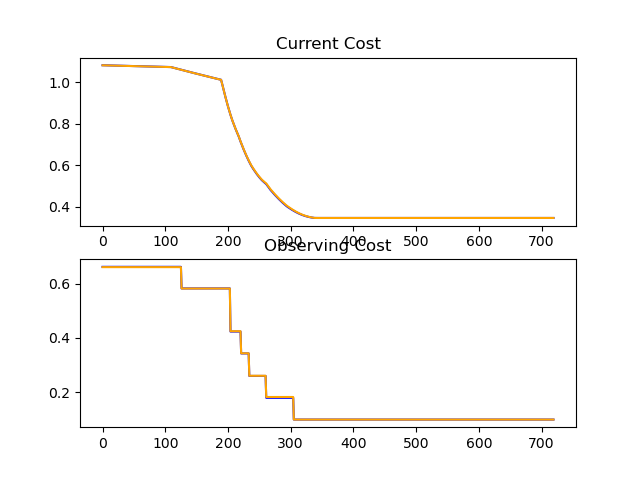
def create_model():
layers = [];
layers.append(ConvolutionLayer((n, n), 5, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(ConvolutionLayer(layers[-1].s_out, 3, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Flatten(layers[-1].s_out, int(np.prod(layers[-1].s_out)), lr));
layers.append(ADAMLayer(layers[-1].s_out, 128, lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(SigmoidLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers = list(map(lambda l: ClipLayer(l), layers));
return LayerChain(layers, lr);https://drive.google.com/file/d/1-6NZ979nVialVCyvU_HBRaApqaeqDD-c/view?usp=sharing
Tried using ResNets... I was implementing Residual Networks, but accidently made discovered a completely different algorithm xD.
The idea is simple, use the same layer in two separate places.
Last BCE Cost recorded: 0.35078454052733754
def create_model():
layers = [];
layers.append(ConvolutionLayer((n, n), 5, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(ConvolutionLayer(layers[-1].s_out, 3, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Flatten(layers[-1].s_out, int(np.prod(layers[-1].s_out)), lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(grabber.grab(Perceptron(layers[-1].s_out, 10, lr)));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(BackDependenceLayer(grabber.layer));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(SigmoidLayer(layers[-1].s_out, layers[-1].s_out, lr));
# layers = list(map(lambda l: ClipLayer(l), layers));
return LayerChain(layers, lr);https://drive.google.com/file/d/1-9gFCuZnsSzT8FGICPeuhkEV_tzyPqVP/view?usp=sharing
Finally implemented ResNet... But couldn't beat the 0.1 barrier 😢...

def create_model():
layers = [];
layers.append(ConvolutionLayer((n, n), 5, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(ConvolutionLayer(layers[-1].s_out, 3, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Flatten(layers[-1].s_out, int(np.prod(layers[-1].s_out)), lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(grabber.grab(Perceptron(layers[-1].s_out, 10, lr)));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
# layers.append(BackDependenceLayer(grabber.layer));
layers.append(ResidualNetworkLayer(grabber.layer));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(SigmoidLayer(layers[-1].s_out, layers[-1].s_out, lr));
# layers = list(map(lambda l: ClipLayer(l), layers));
return LayerChain(layers, lr);
https://drive.google.com/file/d/1-E1ulbtM27rCj7nFQNFxfWJgxMmVQ_ae/view?usp=sharing
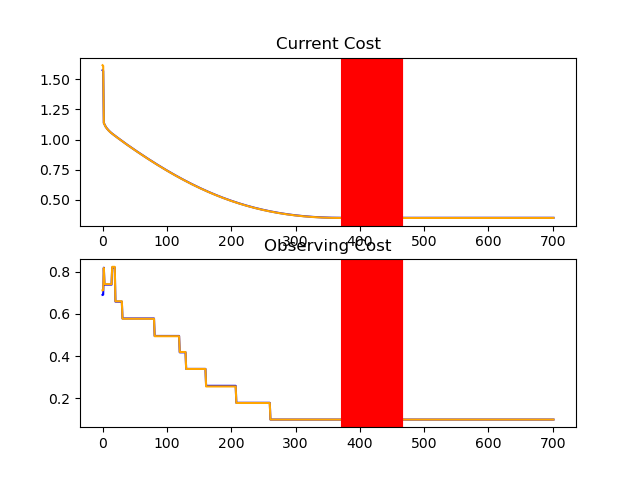
Finally I found a bug in my code, and hopefully it allows me to train further below that 0.1 mark.
def create_model():
layers = [];
layers.append(ConvolutionLayer((n, n), 5, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(ConvolutionLayer(layers[-1].s_out, 3, lr));
layers.append(MaxPoolingLayer(layers[-1].s_out, (2, 2), lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Flatten(layers[-1].s_out, int(np.prod(layers[-1].s_out)), lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(grabber.grab(Perceptron(layers[-1].s_out, 10, lr)));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(ReluLayer(layers[-1].s_out, layers[-1].s_out, lr));
# layers.append(BackDependenceLayer(grabber.layer));
layers.append(ResidualNetworkLayer(grabber.layer));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(SigmoidLayer(layers[-1].s_out, layers[-1].s_out, lr));
# layers = list(map(lambda l: ClipLayer(l), layers));
return LayerChain(layers, lr);
https://drive.google.com/file/d/1-FDzIgYIr6PrYAdNw6bLLTZ0r8aC3epM/view?usp=sharing
The 0.1 barrier 👀...
I hope the model will finally go below it...
Edit: No it failed...
Tried a lot of things, only fc layers, only conv layers, normalization, mini-batch, and fixed a few bugs.
(About the confusion matrix, yes that currently is buggy, I'll fix it later)
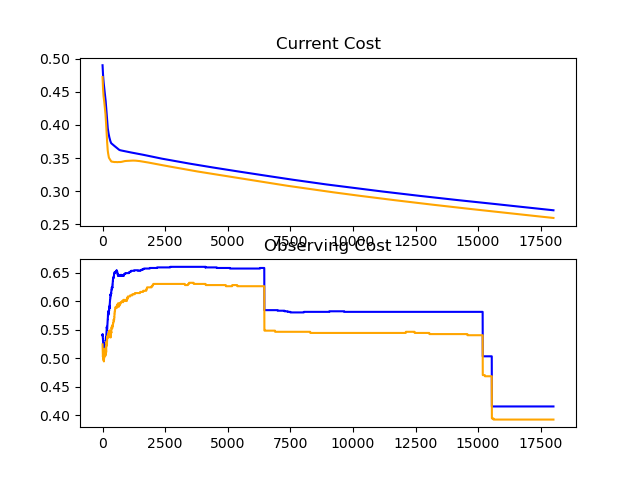
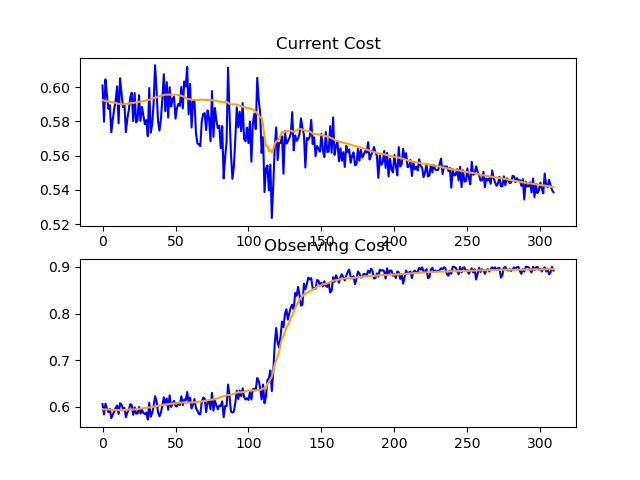
Interesting results from mini-batch:
- The usual bumpiness of Mini-Batch

- The nice (an unexpected) fractal along the curve
- The final training result
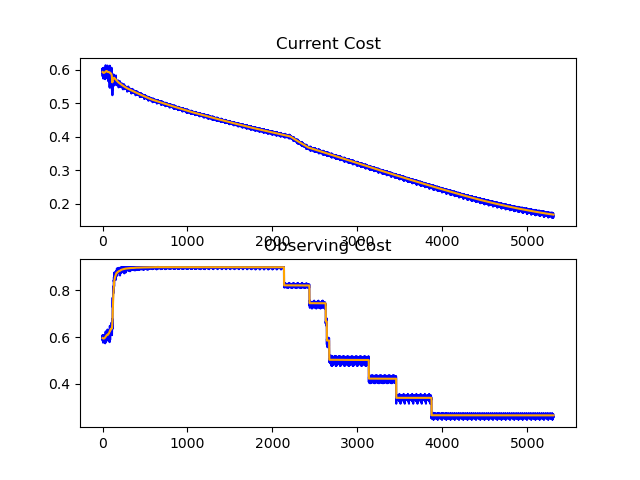
Finally broke through the 0.1 barrier!!!!!!!!!!
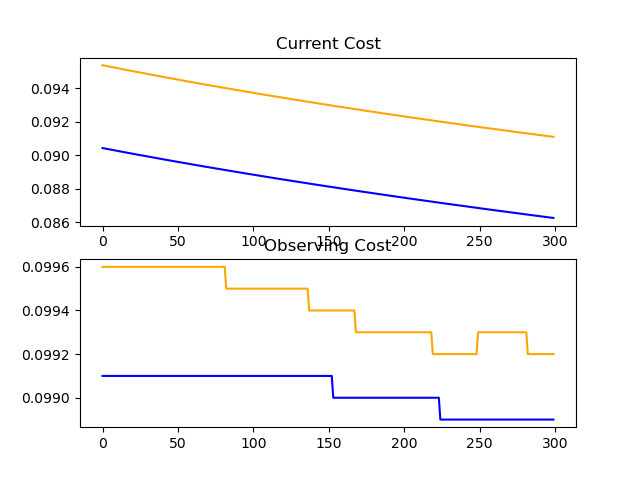
Reached 65.8% accuracy with a network starting with one conv (filter size 5x5) layer...
Conv>Perp[128]>Relu>Perp[32]>Relu>Perp[32]>Relu>Perp[32]>Relu>Perp[10]>Sigmoid
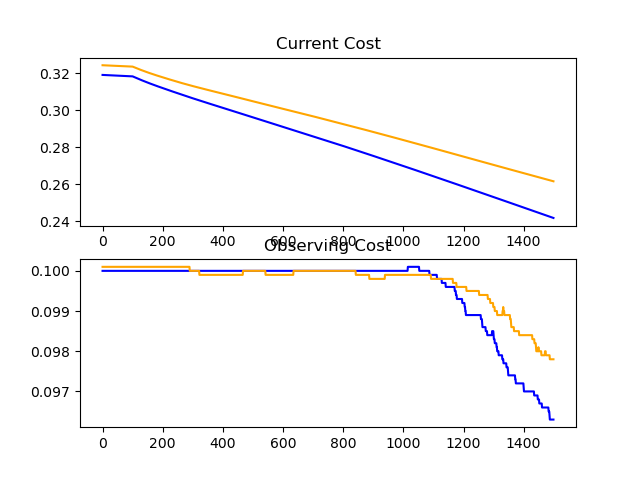
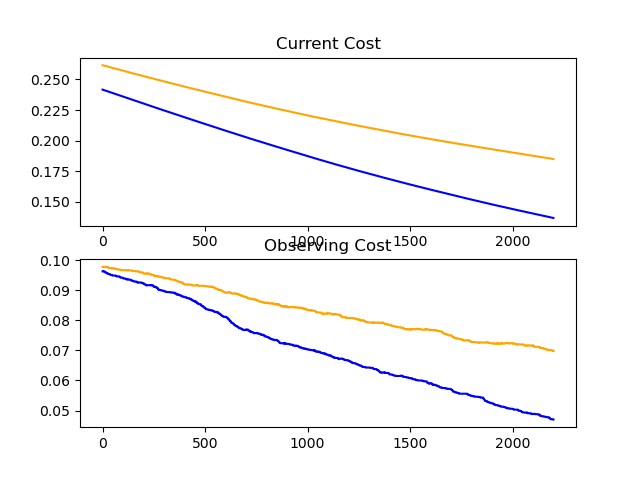
Unfortunately, I was able to reach ~80% accuracy in much much less time without the conv layer...
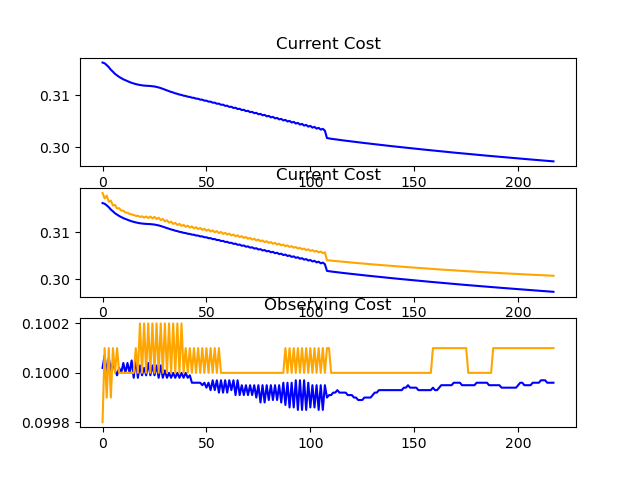
A few crazy graphs 🤔... What does that even mean?
This was such a sharp fall!

Why are there these strange spikes?

Quite a bouncy ride 👀
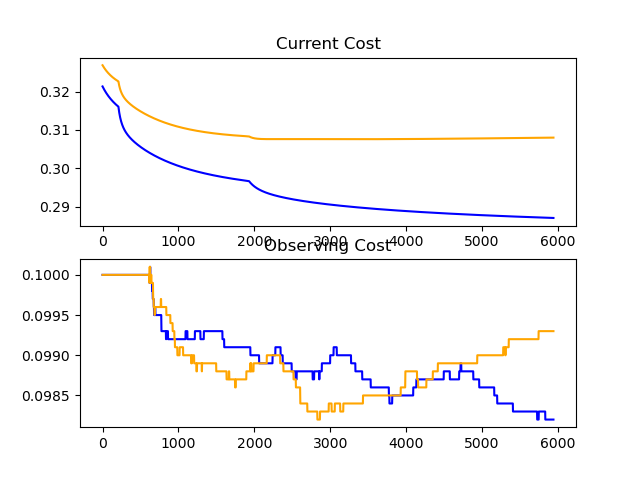
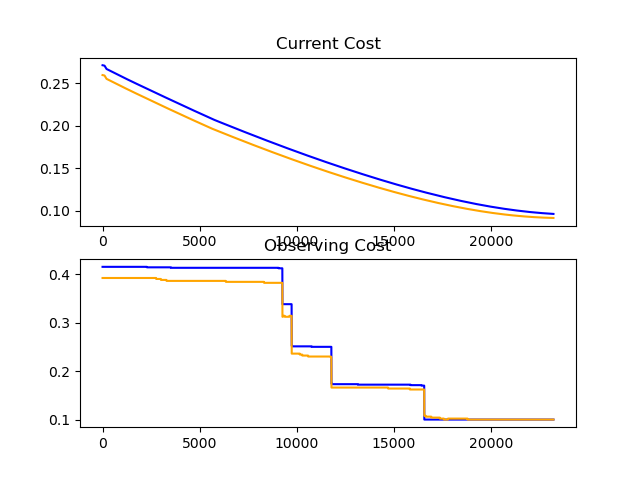
Finally got my CNN working right, with 92% Accuracy... Let's try pushing it to it's limits!
def create_model():
layers = [];
layers.append(ConvolutiveParametersLayer((n, n, 1), lr, (3, 3), 3, striding=(2, 2)));
layers.append(Flatten(layers[-1].s_out, int(np.prod(layers[-1].s_out)), lr));
layers.append(Perceptron(layers[-1].s_out, 2, lr));
layers.append(TanHLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 128, lr));
layers.append(TanHLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(grabber.grab(Perceptron(layers[-1].s_out, 32, lr)));
layers.append(TanHLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 32, lr));
layers.append(TanHLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 32, lr));
layers.append(TanHLayer(layers[-1].s_out, layers[-1].s_out, lr));
layers.append(Perceptron(layers[-1].s_out, 10, lr));
layers.append(SigmoidLayer(layers[-1].s_out, layers[-1].s_out, lr));
return LayerChain(layers, lr);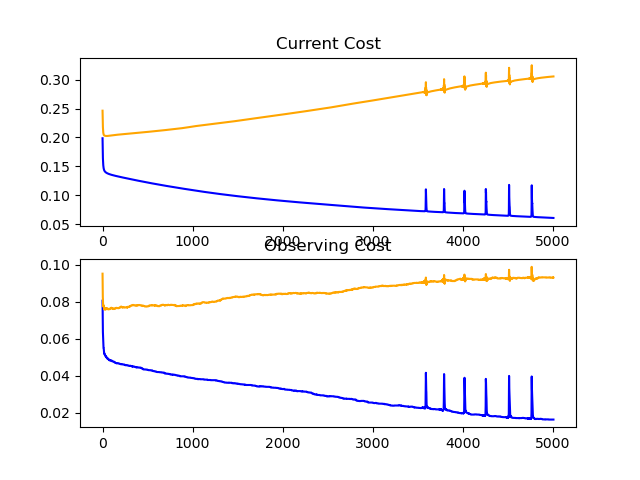
Accuracy = 92.2
Predicted 0 1 2 3 4 5 6 7 8 9
Actual
0 97 0 0 0 0 0 0 0 0 0
1 0 115 1 0 0 0 0 0 0 0
2 9 0 70 0 0 10 0 0 8 2
3 1 1 1 88 0 0 0 1 1 0
4 0 0 0 0 105 0 0 0 0 0
5 0 0 4 1 1 74 0 0 12 0
6 1 1 0 0 1 0 91 0 0 0
7 0 0 0 0 1 0 0 113 0 3
8 0 0 0 1 0 12 0 0 74 0
9 2 0 1 0 0 0 0 0 2 95
95% Accuracy... Well.

https://drive.google.com/file/d/1-J_boyxEEuQusntH_Xfc2bbA03ogVuTO/view?usp=sharing
Results of Training on MNIST-Fashion
(10k train samples and 1k test samples)
My Gist's model
MaxPool((2,2)) > Conv((5,5),3) > ReLU > FC(128) > TanH > FC(32) >
TanH > FC(32) > TanH > FC(32) > TanH > FC(10) > Sigmoid
Train Set Accuracy = 87.22%
Test Set Accuracy = 82.40%
https://drive.google.com/file/d/1-TJGgfLoub1-ZJ8K0KdCuepc_wXSi1uz/view?usp=sharing
VGG in Tensorflow
Conv((3,3),32) > ReLU > Conv((3,3),32) > ReLU > MaxPool((2,2)) >
Conv((3,3),32) > ReLU > Conv((3,3),32) > ReLU > MaxPool((2,2)) >
Conv((3,3),32) > ReLU > Conv((3,3),32) > ReLU > MaxPool((2,2)) >
FC(128) > ReLU > FC(10) > Softmax
Train Set Accuracy = ~85%
Test Set Accuracy = 83%