
| Student | Niklas Muennighoff |
|---|---|
| Github | @Muennighoff |
| Organisation | DeepPavlov |
| Project | A new architecture for DeepPavlov's Conversational AI Stack |
| Pull Request | Final PR |
| Issues | Open a DeepPavlov Issue and link @Muennighoff |
| Other | Reach out at n.muennighoff@gmail.com |
The goal of this project was to improve the architecture of Goal-Oriented Chatbots in the DeepPavlov framework for AI smart assistants. To do so, we decided to implement a new model inspired by the latest State of the Art in Goal-Oriented bots, especially TripPy.
The code for the new model has been pulled into the DeepPavlov repository here.
See here for a simple tutorial creating a toy chatbot.
See here for another simple tutorial leveraging the RASA format.
See here for an advanced tutorial deploying a chatbot to Telegram in 30 minutes.
On a high-level, the model is about 50% faster than the previous model due to a migration from TensorFlow 1 to PyTorch & excels at interpreting outliers (unusual texts) due to a BERT-backbone. For example, the model would predict correctly that “Alright, that’s it” is the end of the conversation, even though it has only seen “Goodbye” or “Thanks” as conversation ending sentences during fine-tuning.
Details follow:

The above sketch is the full architecture that has been implemented. The process starts with a user uttering some text “Utterance”. This is then fed together with the dialogues history (empty at the beginning) and some definitions (Slot names refers to variables the model aims to fill, such as “Time”, “Foodtype”). These inputs are fed into a TripPy-like pipeline. In the “Input preprocessing” the inputs are tokenized and prepared for the BERT model. This is where the core of the model sits and the entire dialogue is fed through a multi-layer transformer model. The hidden states of the transformer are then used via multiple heads to produce different predictions. A “Hydranet” as folks at Tesla might call it.
One part of the predictions serves the purpose of action prediction. From a pre-defined list of possible actions the model predicts which it wants to take. An action may be as simple as “Goodbye”.
The other part serves the filling of the dialogue state. This is where the model keeps track of its knowledge about the users desires. If the user said “I want Japanese food”, the model may save something like “food: japanese” with an associated probability in its dialogue state tracker.
Together these two parts are used to produce a system response. The model allows the user to provide an SQLite database or an external API-Call mechanism, as shown in this tutorial. If such is provided and the predicted action is one that needs to retrieve data, a call to the database/api will be made. (E.g. an action like “Restaurant XYZ serves Japanese food.” - The model needs to retrieve a restaurant name that serves japanese food) The response is generated via a rule-based mechanism in the Natural Language Generation component and sent back to the user.
The architecture can also be used without any slot names if all the data can be defined in the actions of the model. For example, a bot that recommends people whether to play outside or stay inside based on how they feel may just need two actions (e.g. “Go play outside!” and “Stay inside!”) which it predicts based on user inputs, such as “It’s dark outside and I feel tired”. To train such a bot, one needs a dataset with ideally at least 5 dialogues for each of the bots actions. See for example the RASA tutorial.
To train a bot with slots and an api call, one needs a more advanced dataset with labels of the slots in the input. See the advanced tutorial for creating such a dataset.
Below a bot deployed to Telegram querying the Google Maps API while chatting:
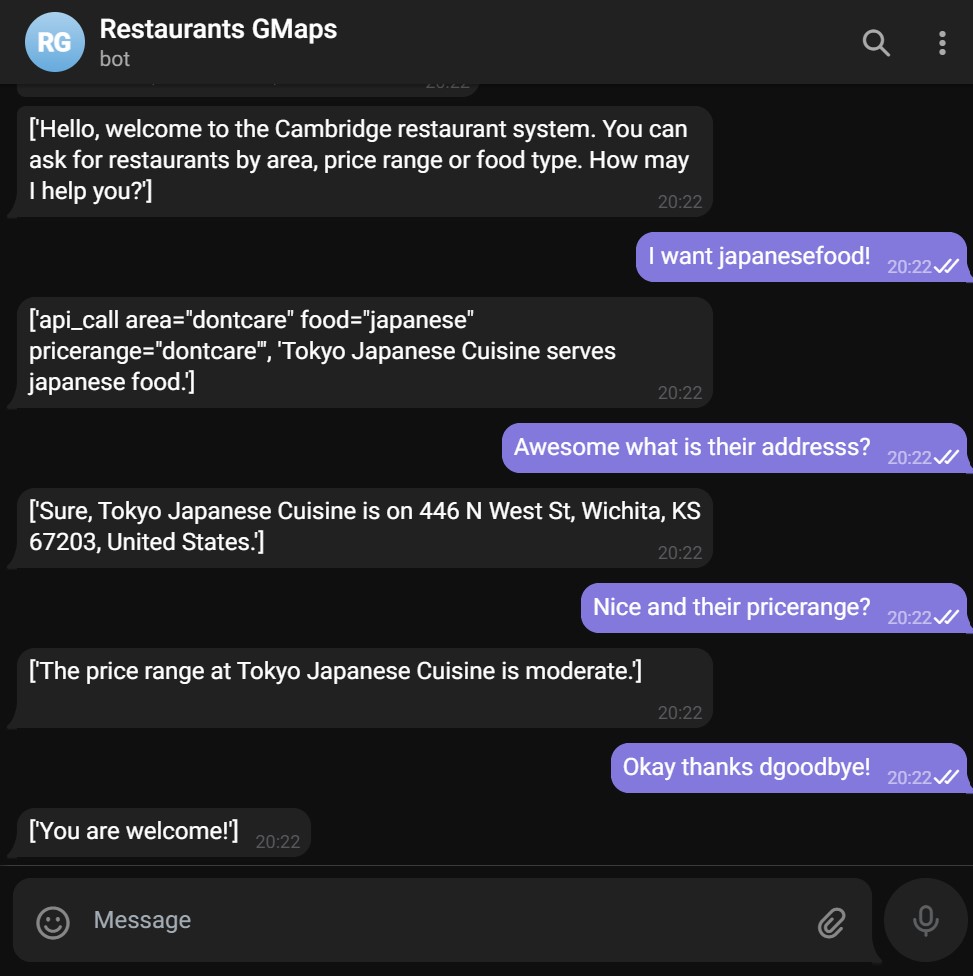
I think the most promising improvement would be to swap the copy mechanism for a generative mechanism. The current implementation copies its slot values (what the user wants) from its own previous text or the users text. This prevents it from catching the slot value “French food “ from very convoluted sentences, like “I want to eat the food from the country with the Eiffel Tower”. However, you can’t just drop-in a purely generative model like GPT-3 due to its unpredictability - The probabilities for it giving the exact answers you want are too unlikely. A certain amount of unpredictability is acceptable, just as you cannot be sure a customer service representative won’t start insulting you, but it needs to be orders of magnitude better than GPT-3.
Switching to a generative mechanism, while retaining high predictability will be a key challenge to embed conversational AI into more business settings.