👉 check the drlnd_py310 env setup notes
👉 check the p1 env setup notes
👉 course curriculum
👉 Colab notebooks
Window 11, VSCode, Minicoda, Powershell
👉 copy from the env where cuda and pytorch have been installed
🟢 conda create --name drlnd_p2 --clone drlnd (Python 3.6)
(base) PS D:\github\udacity-deep-reinforcement-learning\python> conda create --name drlnd_p2 --clone drlnd
Source: D:\Users\*\miniconda3\envs\drlnd
Destination: D:\Users\*\miniconda3\envs\drlnd_p2
Packages: 159
Files: 13970
- or check how to install cuda + pytorch in windows 11
conda install cuda --channel "nvidia/label/cuda-12.1.0" - or go to https://pytorch.org/, and select the right version to install
❌pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
🟢conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
pip install torchmeta
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidi
🟢 Follow these steps to install mujoco-py on Windows
- get mjpro150 win64
- get
mjkey.txt
🟢 Powershell $env:PATH += ";C:\Users\*\.mujoco\mjpro150\bin"
Powershell $env:path -split ";" to display path variables
🟢 download mujoco-py-1.50.1.68.tar.gz from https://pypi.org/project/mujoco-py/1.50.1.68/#files
pip install "cython<3"
pip install mujoco-py-1.50.1.68.tar.gz
python D:\github\udacity-deep-reinforcement-learning\python\mujoco-py\examples\body_interaction.py
- you might need this
pip install lockfileand some other packages. install them according to the error messages. - a worse case is that your python version is too high (maybe >=3.9?), you might need to install
mujoco_pymanually. - now you should be able to see this.
👉 install gym atari and lincense
https://stackoverflow.com/a/69602242
pip install -U gym
pip install -U gym[atari,accept-rom-license]
pip install bleach==1.5.0
pip install --upgrade numpy
pip install --upgrade tensorboard
👉 install OpenAI Baselines
pip install --upgrade pip setuptools wheel
pip install opencv-python==4.5.5.64
git clone https://github.com/openai/baselines.git
cd baselines
pip install -e .
- for python 3.11, you can
pip install opencv-python.
and iSuccessfully installed opencv-python-4.9.0.80.
👉 intall the rest packages for the deeprl folder.
pip install -r .\deeprl_files\requirements.txt
- requirements.txt
# torch
# torchvision
# torchmeta
# gym==0.15.7
# tensorflow==1.15.0
# opencv-python==4.0.0.21
atari-py
scikit-image==0.14.2
tqdm
pandas
pathlib
seaborn
# roboschool==1.0.34
dm-control2gym
tensorflow-io
- for python 3.11, losen the version requirement
scikit-image.
I gotscikit-image-0.22.0installed.
👉 test the env setup
- run notebooks
python -m ipykernel install --user --name=drlnd_p2
jupyter notebook D:\github\udacity-deep-reinforcement-learning\p2_continuous-control\Continuous_Control.ipynb
jupyter notebook D:\github\udacity-deep-reinforcement-learning\p2_continuous-control\Crawler.ipynb
🟢 python -m deeprl.component.envs
if __name__ == '__main__':
import time
## num_envs=5 will only create 3 env and cause error
## "results = _flatten_list(results)"
## in "baselines\baselines\common\vec_env\subproc_vec_env.py"
task = Task('Hopper-v2', num_envs=3, single_process=False)
state = task.reset()
## This might be helpful for custom env debugging
# env_dict = gym.envs.registration.registry.env_specs.copy()
# for item in env_dict.items():
# print(item)
start_time = time.time()
while True:
action = np.random.rand(task.action_space.shape[0])
next_state, reward, done, _ = task.step(action)
print(done)
if time.time()-start_time > 10: ## run about 10s
break
task.close()
🟢 run examples:
D:\github\udacity-deep-reinforcement-learning\python\deeprl_files\examples.py
if __name__ == '__main__':
mkdir('log')
mkdir('tf_log')
set_one_thread()
random_seed()
# -1 is CPU, an non-negative integer is the index of GPU
# select_device(-1)
select_device(0) ## GPU
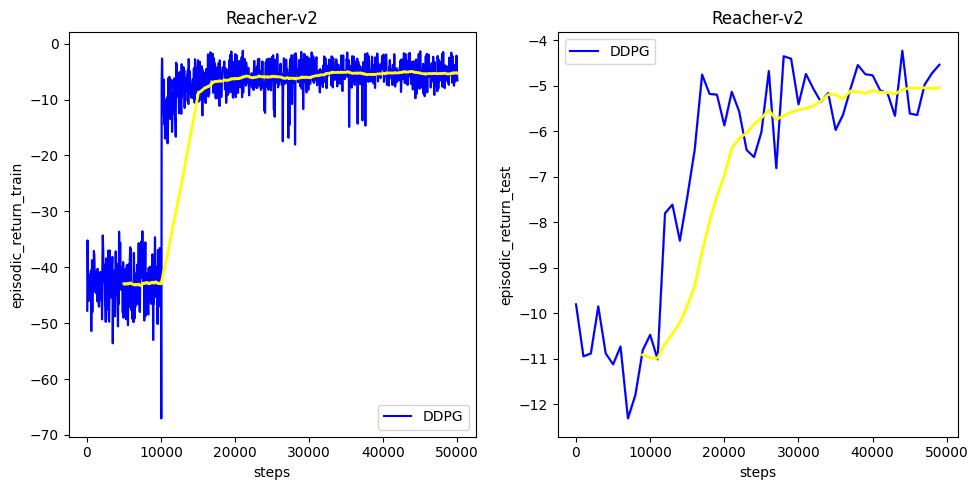
game = 'Reacher-v2'
# a2c_continuous(game=game)
# ppo_continuous(game=game)
ddpg_continuous(game=game)
- you should be able to see something like this in the video.
https://github.com/ShangtongZhang/DeepRL
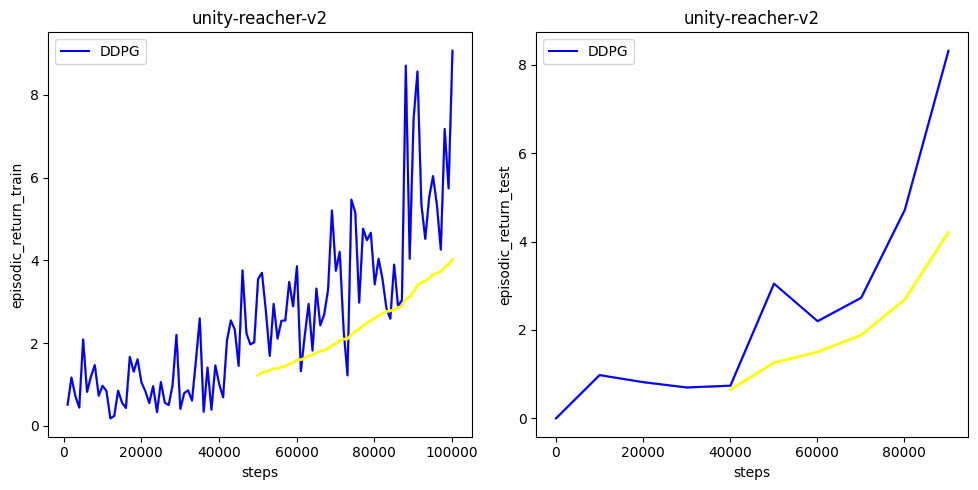
https://github.com/ChalamPVS/Unity-Reacher
🟢 copied python files from repo @ShangtongZhang/DeepRL to repo @Nov05/udacity-deep-reinforcement-learning under the './python' folder.
DeepRL/template_jobs.py
ddpg_continuous(game='Reacher-v2', run=0, env=env,
remark=ddpg_continuous.__name__)
DeepRL/examples.py
def ddpg_continuous(**kwargs):
config.task_fn = lambda: Task(config.game, env=env)
run_steps(DDPGAgent(config))
deep_rl/utils/config.py
class Config:
def __init__(self):
self.task_fn = None
DeepRL/deep_rl/utils/misc.py
def run_steps(agent):
config = agent.config
agent.step()
deep_rl/agent/DDPG_agent.py
class DDPGAgent(BaseAgent):
self.task = config.task_fn()
def step(self):
deep_rl/component/envs.py
def make_env(env_id, seed, rank, episode_life=True):
class Task:
def __init__(self,
name,
num_envs=1,
env=env,
if __name__ == '__main__':
task = Task('Hopper-v2', 5, single_process=False)
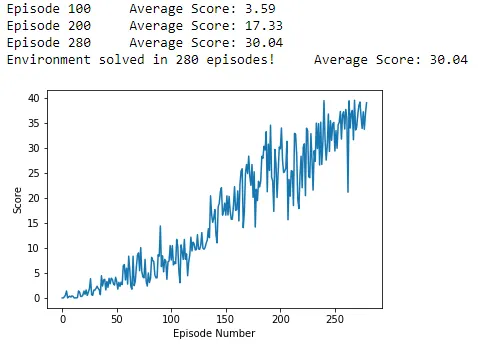

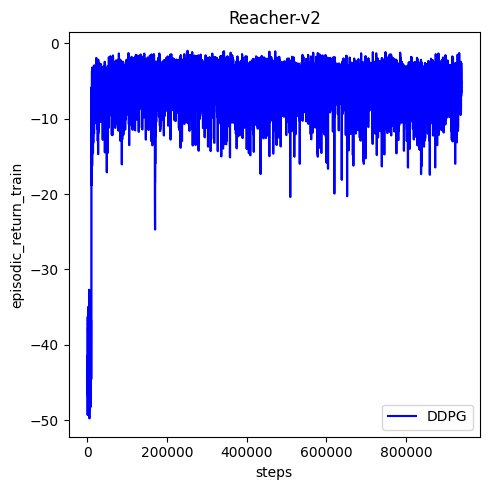
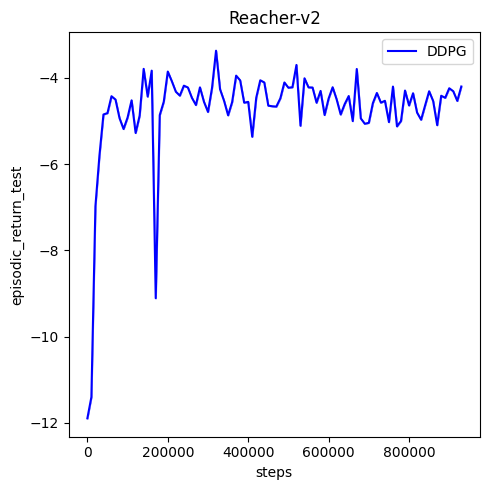
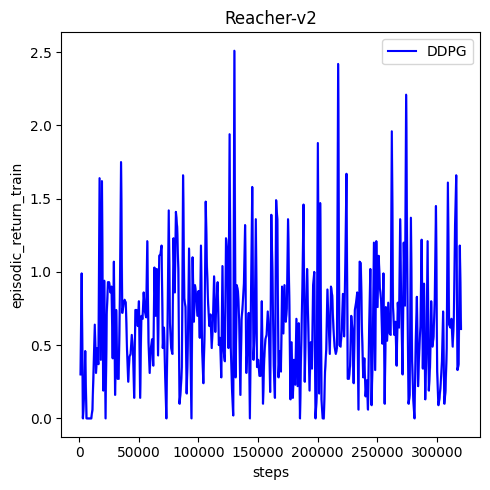

🟢⚠️ issue solved: conda env
drlnd_py310,tensorflow==2.16.1would cause the following errors. ✅ downgrade totensorflow==2.15.0solved the issue. colab is currently usingtensorflow==2.15.0as well.Baselinesexamplepython -m baselines.run --alg=ppo2 --env=PongNoFrameskip-v4 --save_path=~/models/PongNoFrameskip-v4_1M_ppo2 --log_path=~/logx = Input(...)
...
tf_fn(x) # Invalid.
class MyLayer(Layer):
def call(self, x):
return tf_fn(x)
x = MyLayer()(x)