- For this toy game, two
Deep Q-networkmethods are tried out. Since the observations (states) are simple (not in pixels), convolutional layers are not in use. And the evaluation results confirm that linear layers are sufficient for solving the problem.- Double DQN, with 3 linear layers (hidden dims: 256*64, later tried with 64*64)
- Dueling DQN, with 2 linear layers + 2 split linear layers (hidden dims: 64*64)
▪️ The Dueling DQN architecture is displayed as below.
| Dueling Architecture | The green module |
|---|---|
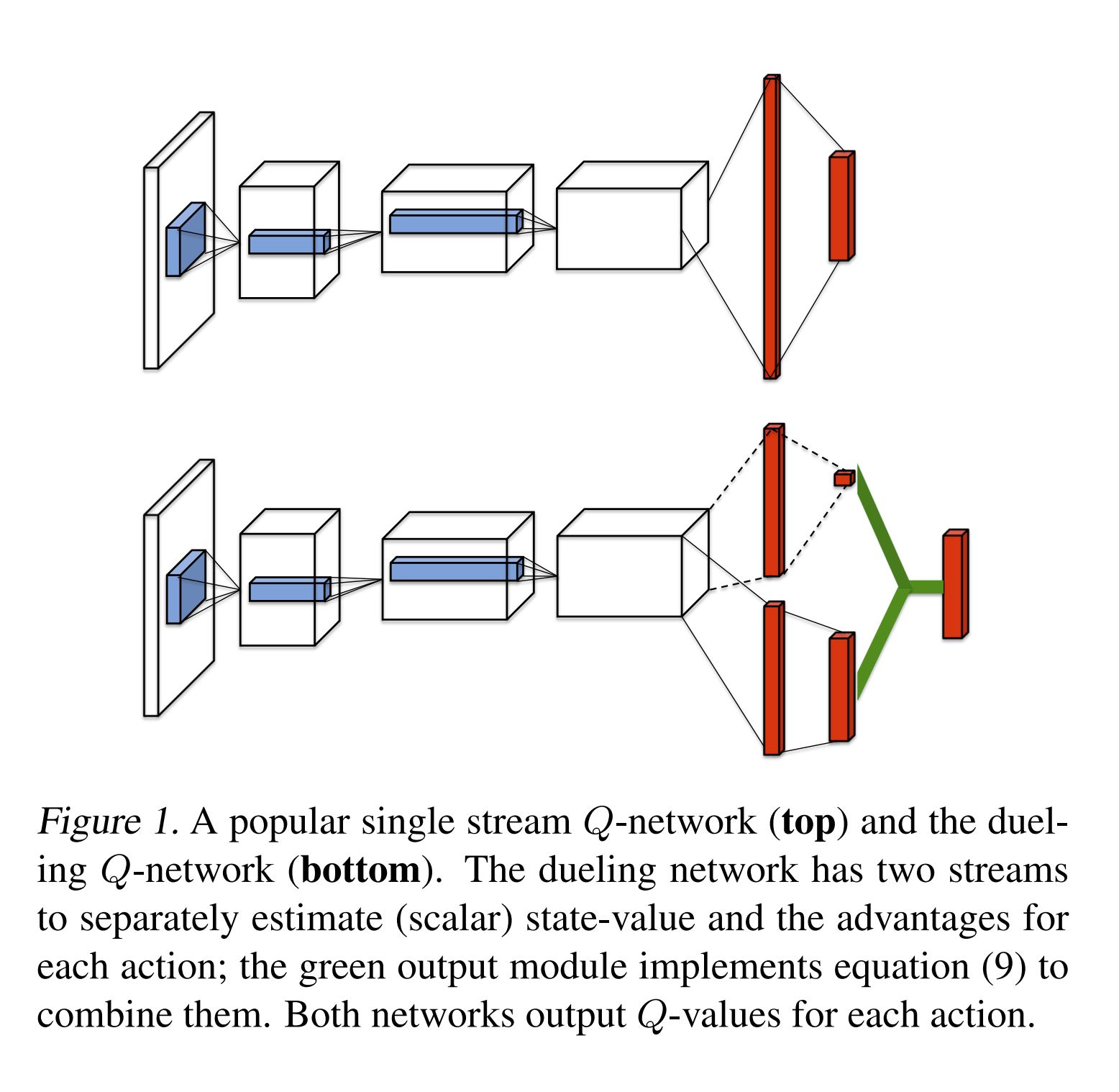
|
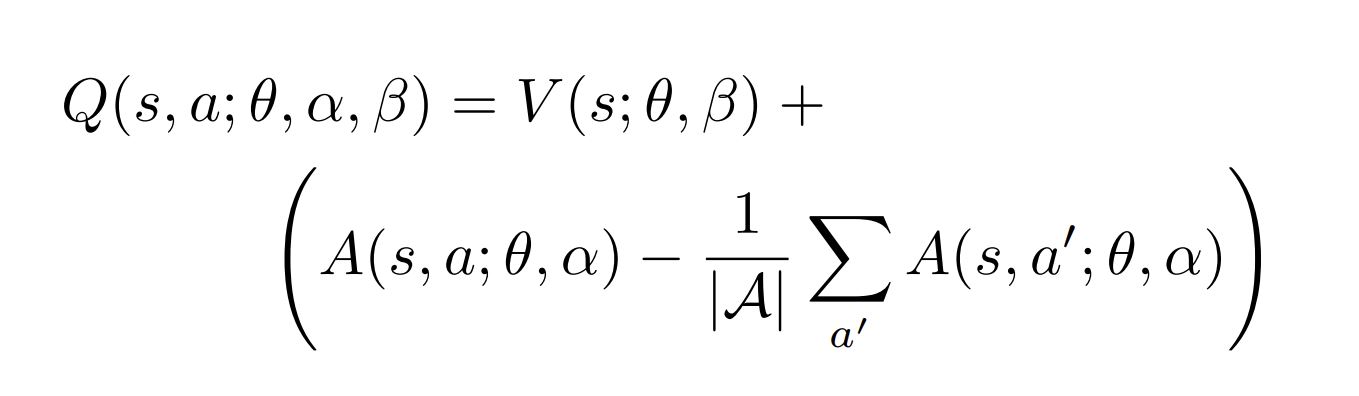
|
▪️ Since both the advantage and the value stream propagate gradients to the last convolutional layer in the backward pass, we rescale the combined gradient entering the last convolutional layer by 1/√2. This simple heuristic mildly increases stability.
self.layer1 = nn.Linear(state_size, 64)
self.layer2 = nn.Linear(64, 64)
self.layer3_adv = nn.Linear(in_features=64, out_features=action_size) ## advantage
self.layer3_val = nn.Linear(in_features=64, out_features=1) ## state value
def forward(self, state):
x = F.relu(self.layer1(state))
x = F.relu(self.layer2(x))
adv, val = self.layer3_adv(x), self.layer3_val(x)
return (val + adv - adv.mean(1).unsqueeze(1).expand(x.size(0), action_size)) / (2**0.5)▪️ In addition, we clip the gradients to have their norm less than or equal to 10. This clipping is not standard practice in deep RL, but common in recurrent network training (Bengio et al., 2013).
## clip the gradients
nn.utils.clip_grad_norm_(self.qnetwork_local.parameters(), 10.)
nn.utils.clip_grad_norm_(self.qnetwork_target.parameters(), 10.) - The following picture shows the train and eval scores (rewards) for both architectures. Since it is a toy project, trained models are not formally evaluated. We can roughly see that Dueling DQN slightly performs better with an average score of 17 vs. Double DQN 13 in 10 episodes.

- Project artifacts:
- All the notebooks (trained in Google Colab, evaluated on local machine)
- The project folder
p1_navigation(which contains checkpointsdqn_checkpoint_2000.pthanddueling_dqn_checkpoint_2000.pth) - Video recording (which demonstrates how trained models are run on the local machine)