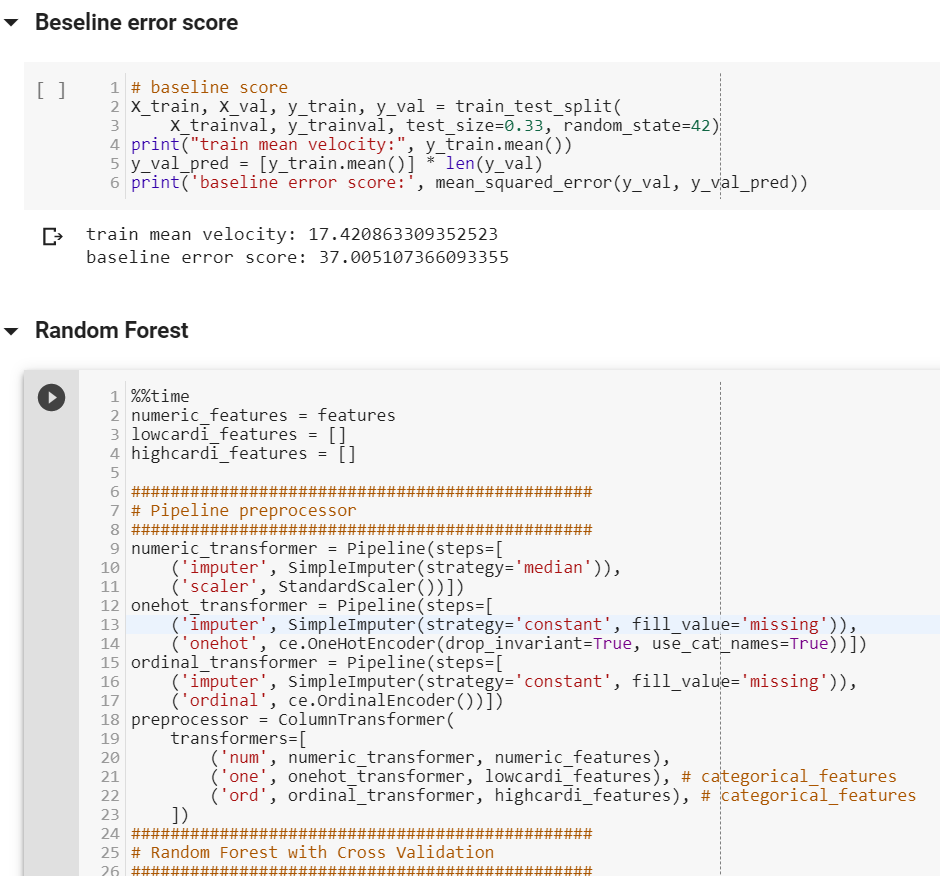
# baseline score
X_train, X_val, y_train, y_val = train_test_split(
X_trainval, y_trainval, test_size=0.33, random_state=42)
print("train mean velocity:", y_train.mean())
y_val_pred = [y_train.mean()] * len(y_val)
print('baseline error score:', mean_squared_error(y_val, y_val_pred))
%%time
numeric_features = features
lowcardi_features = []
highcardi_features = []
###############################################
# Pipeline preprocessor
###############################################
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
onehot_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', ce.OneHotEncoder(drop_invariant=True, use_cat_names=True))])
ordinal_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('ordinal', ce.OrdinalEncoder())])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('one', onehot_transformer, lowcardi_features), # categorical_features
('ord', ordinal_transformer, highcardi_features), # categorical_features
])
###############################################
# Random Forest with Cross Validation
###############################################
pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('rf', RandomForestRegressor(n_estimators=10,
max_depth=20,
random_state=5,
n_jobs=-1,
oob_score=True,)),
])
params = {
'rf__n_estimators': [10, 15, 20],
'rf__max_depth': [1, 2, 3, 5],
# 'rf__max_features': ['auto', 'sqrt', 'log2'],
# 'rf__criterion': ['mse', 'mae']
}
search = GridSearchCV(
pipeline,
params,
return_train_score=True,
cv=5)
search.fit(X_train[features], y_train)
print('Best hyperparameters', search.best_params_)
print('Cross-validation best score', search.best_score_)
y_val_pred = search.predict(X_val[features])
print('Random Forest error score:', mean_squared_error(y_val, y_val_pred))
###############################################
# eli5
###############################################
pipeline.fit(X_train[features], y_train)
permuter = PermutationImportance(pipeline['rf'],
scoring='neg_mean_squared_error',
cv='prefit',
n_iter=2,
random_state=5)
permuter.fit(pipeline['preprocessor'].transform(X_val[features]), y_val)
# Transformed features
tfs = pipeline['preprocessor'].named_transformers_
features_transformed = numeric_features
eli5.show_weights(permuter, top=None, feature_names=features_transformed)
Go to the repo
https://github.com/Nov05/playground-fireball