Last active
March 31, 2021 07:12
-
-
Save Odomontois/6baa522040180ea51b2a01afb26ed4eb to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "data": { | |
| "userRecentTopics": [ | |
| { | |
| "id": 1134197, | |
| "title": "[Python] 4 lines solution, explained", | |
| "commentCount": 4, | |
| "post": { | |
| "creationDate": 1617104975, | |
| "voteCount": 22, | |
| "topicTitle": "[Python] 4 lines solution, explained", | |
| "content": "There is solution, if we use similar idea of Problems **300** (Longest Increading subsequence), because we want to find the longest increasing sub-sequence. Check my solution https://leetcode.com/problems/longest-increasing-subsequence/discuss/667975/Python-3-Lines-dp-with-binary-search-explained\\n\\nActually we can done exactly the same as in 300,\\nbut when we sort we put envelopes with equal first elements [6,8], [6,7] it this opposite order\\nin this way we make sure that or longest increasing subsequence works like it is and we put into our dp table the second elements. For example if we have envelopes [1,3],[3,5],[6,8],[6,7],[8,4],[9,5], we work with [3,5,8,7,4,5] and look for longest increasing sequence here.\\n\\n```python\\nclass Solution:\\n def maxEnvelopes(self, envelopes):\\n nums = sorted(envelopes, key = lambda x: [x[0], -x[1]]) \\n dp = [10**10] * (len(nums) + 1)\\n for elem in nums: dp[bisect_left(dp, elem[1])] = elem[1] \\n return dp.index(10**10)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1132516, | |
| "title": "[Python] recursive dfs, explained", | |
| "commentCount": 4, | |
| "post": { | |
| "creationDate": 1617007737, | |
| "voteCount": 18, | |
| "topicTitle": "[Python] recursive dfs, explained", | |
| "content": "For me it was not medium problem, more like hard. First of all it is asked in problem statement to find the minimum number of flips, however in fact we do not have choice: I think everything is determenistic here. The first thing you need to think about when you see tree, it is dfs or bfs. Let us choose recursive dfs, it is usally easier to code and understand.\\n\\n1. `self.ans` is our list with flipped nodes.\\n2. `self.ind` is where exaclty at our `voyage` array we are now. This is tricky part! If you do not use something similar, you still can solve problem, but it will be more like `O(n^2)` complexity.\\n\\n`dfs(node)` function will work recursively as usual.\\n1. Check if we go outside our tree or we out of elements in `voyage`, in this case we just go back.\\n2. Also, we **expect**, that value of current node we are in now is equal to element we are currently in `voyage`: if it is not the case, no flipping can save this situation. So, if we see that this condition does not hold, we add `None` to the answer and return. In the end we going to check if we have `None` in answer or not.\\n3. Define `dr = 1`: direction of traversal (means `left -> right` and `-1` means `right -> left`), also increase `self.ind` by one.\\n4. Check if we need to do flip: we need if `node.left.val` is not equal to `voyage[self.ind]`: in this case what is expected to be next node in traversal is not equal to the next node in voyages. We add node to answer and change direction. Note, that in the opposite case we **can not** flip this node, that is everything is determenistic.\\n5. Traverse children in right direction and run `dfs(child)`.\\n6. In the end, run `dfs(root)` and check if we have `None` inside, if we have it means that at one moment of time we have impossible option and we need to return `[-1]`. In opposite case we return `self.ans`.\\n\\n**Complexity**: What we did here is just traversed our tree, using dfs, so time complexity is `O(n)`, where `n` is number of nodes in tree. Space complexity is potentially `O(n)` as well.\\n\\n```\\nclass Solution:\\n def flipMatchVoyage(self, root, voyage):\\n self.ans, self.ind = [], 0\\n \\n def dfs(node):\\n if not node or self.ind == len(voyage): return\\n if node.val != voyage[self.ind]: \\n self.ans.append(None)\\n return\\n dr, self.ind = 1, self.ind + 1\\n \\n if node.left and node.left.val != voyage[self.ind]:\\n self.ans.append(node.val)\\n dr = -1\\n \\n for child in [node.left, node.right][::dr]:\\n dfs(child)\\n \\n dfs(root)\\n return [-1] if None in self.ans else self.ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1131046, | |
| "title": "[Python] Linear solution, using Counters, explained", | |
| "commentCount": 15, | |
| "post": { | |
| "creationDate": 1616921063, | |
| "voteCount": 58, | |
| "topicTitle": "[Python] Linear solution, using Counters, explained", | |
| "content": "Actually what is asked in this problem is to solve linear system of equations: imagine that we have `f0, ... f9` frequencies of words `zero, ... nine`, then we need to solve `10` equations with `10` variables. We can look at this at slightly different angle:\\n1. Let us look at word `zero`: we meet symbol `z` only in this word, so total number of times we have `z` in string is number of times we have word `zero` inside. So, what we do: we keep global counter `cnt` and subtract all frequencies, corresponding to letters `z`, `e`, `r`, `o`.\\n2. Look at word `two`, we have symbol `w` only in this word, remove all words `two`.\\n3. Look at word `four`, we have symbol `u` only in this word, remove all words `four`.\\n4. Look at word `six`, we have symbol `x` only in this word, remove all words `six`.\\n5. Look at word `eight`, we have symbol `g` only in this word, remove all words `eight`.\\n6. Look at word `one`, we have symbol `o` only in this word if we look at words we still have, remove all words `one`.\\n7. Look at word `three`, we have symbol `t` only in this word if we look at words we still have, remove all words `three`.\\n8. Look at word `five`, we have symbol `f` only in this word if we look at words we still have, remove all words `five`.\\n9. Look at word `seven`, we have symbol `s` only in this word if we look at words we still have, remove all words `seven`.\\n10. Look at word `nine`, we have symbol `n` only in this word if we look at words we still have, remove all words `nine`.\\n\\n**Complexity**: time complexity is just `O(n)`, where `n` is length of `s`, because first we create counter and then we iterate over `10` digits and update `cnt` in `O(1)` time. Space complexity is `O(n)` as well to format our answer.\\n\\n```\\nclass Solution:\\n def originalDigits(self, s):\\n cnt = Counter(s)\\n Digits = [\"zero\",\"two\",\"four\",\"six\",\"eight\",\"one\",\"three\",\"five\",\"seven\",\"nine\"]\\n Corresp = [0,2,4,6,8,1,3,5,7,9]\\n Counters = [Counter(digit) for digit in Digits]\\n Found = [0]*10\\n for it, C in enumerate(Counters):\\n k = min(cnt[x]//C[x] for x in C)\\n for i in C.keys(): C[i] *= k\\n cnt -= C\\n Found[Corresp[it]] = k\\n \\n return \"\".join([str(i)*Found[i] for i in range(10)]) \\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1130510, | |
| "title": "[Python] Short solution, using split, explained", | |
| "commentCount": 4, | |
| "post": { | |
| "creationDate": 1616904107, | |
| "voteCount": 16, | |
| "topicTitle": "[Python] Short solution, using split, explained", | |
| "content": "Nothing very special about this problem, we need to traverse our string and deal with data inside brackets. Let us do it in the following way:\\n\\n1. Create `d`: dictionary of knowledge\\n2. Split `s` into parts, using `(`. Imagine, that `s = (name)is(age)yearsold`, then splitted list will be `[\\'\\', \\'name)is\\', \\'age)yearsold\\']`. It will look like this: first part will not have closing bracket, and each next part will have closing bracket.\\n3. So, we add `t[0]` to final solution and then for each next part we againg use split, now by \")\" and check if we have first part in `d` or not: and either add `?` to answer or corresponding value. Also we add second part `b`, which goes after brackets.\\n\\n**Complexity**: time complexity is `O(m + n)`, where `m` is the length of `s` and `n` is the total length of all the words in `knowledge`: we created dictionary once and then we do one split with `O(n)` and then for each part we do another split and total length of all parts is `O(n)`. Space complexity is also `O(m+n)`.\\n\\n```\\nclass Solution:\\n def evaluate(self, s, knowledge):\\n d = {k:v for k, v in knowledge}\\n t = s.split(\"(\")\\n ans = t[0]\\n for i in range(1, len(t)):\\n a, b = t[i].split(\")\")\\n ans += d.get(a, \"?\") + b\\n return ans\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1130495, | |
| "title": "[Python] O(log n) math solution, explained", | |
| "commentCount": 32, | |
| "post": { | |
| "creationDate": 1616904049, | |
| "voteCount": 113, | |
| "topicTitle": "[Python] O(log n) math solution, explained", | |
| "content": "In fact, this problem is very similar to problem **343. Integer Break** https://leetcode.com/problems/integer-break/, let me explain why:\\n\\nImagine, that we have number `m = p1^a1*p2^a2*...*pk^ak`, this is standard representation of number, where `p1, ..., pk` are some prime numbers and `a1, ..., ak` some integer powers. Then total number of **nice** divisors can be calculated by `a1*...*ak`: just using combinatorics rules: first one can be choosen by `a1` options, second by `a2` and so on. Also, we are given, that `a1 + ... + ak <= n`, where by `n` here I defined `primeFactors` for simplicity. So, the problem now looks like:\\n\\nGiven `a1 + ... + ak <= n` find maximum `a1 * ... ak`.\\n\\nLet us prove, that it is always better when we make numbers equal to `2` or `3`. Indeed, if we have bigger, we can split it to two parts: like `4 -> 2*2`, `5 -> 2*3`, `6 -> 3*3` and so on. Moreover, if we have `2, 2, 2`, it is always better to replace it to `3, 3`. So in the end: optimal configuration has only `2` and `3` and number of `2` is not more than two. Let us just check all `3` cases: `n` gives reminders `0, 1, 2` when divided by `3` and evaluate answer.\\n\\n**Complexity**: time complexity is `O(log n)`, because function `pow` with given modulo `M` will use expontiation trick with doubling of exponent. Space complexity is `O(1)`.\\n\\n\\n```\\nclass Solution:\\n def maxNiceDivisors(self, n):\\n M = 10**9 + 7\\n if n <= 3: return n\\n if n % 3 == 0: return pow(3, n//3, M)\\n if n % 3 == 1: return (pow(3, (n-4)//3, M) * 4) % M\\n return (2*pow(3, n//3, M)) % M\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1129416, | |
| "title": "[Python] Expand around center, explained", | |
| "commentCount": 4, | |
| "post": { | |
| "creationDate": 1616835957, | |
| "voteCount": 13, | |
| "topicTitle": "[Python] Expand around center, explained", | |
| "content": "Each palindrome has center: this is either some symbol or place between symbols. Let us for more simplicity define center by pair or elements `i, j`. If center is symbol, then it will be `(i, i)`; if center is between symbols it will be `(i, i+1)`. All we need to do now is to expand around each of the possible centers and iterrupt when we meet different symbols. In the end return sum of number of found palindromes.\\n\\n**Complexity**: time complexity is `O(n^2)`, because we have `2n-1` possible centers and we can expand upto `O(n)` length. Space complexity is `O(n)`.\\n\\n**Remark** Yes, I am aware, that there exists `O(n)` Manacher algorithm, but it is much more difficult to code and explain how it works. If for some reason you will need it on competition you can quickly google it and use.\\n\\n```\\nclass Solution:\\n def countSubstrings(self, s):\\n def helper(i, j):\\n while i >= 0 and j < len(s) and s[i] == s[j]:\\n i, j = i - 1, j + 1\\n return (j-i)//2\\n \\n return sum(helper(k,k) + helper(k,k+1) for k in range(len(s)))\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1128187, | |
| "title": "[Python] Simple counter solution, explained", | |
| "commentCount": 13, | |
| "post": { | |
| "creationDate": 1616753904, | |
| "voteCount": 19, | |
| "topicTitle": "[Python] Simple counter solution, explained", | |
| "content": "The idea here is to use counters: we need to find elements from `A`, for which each string from `B` have less or equal frequencies for each symbol. Let us create `cnt`: counter, with maximal values for each letter, that is if we have `B = [abb, bcc]`, then we have `cnt = {a:1, b:2 ,c:2}`. In python it can be written using `|` symbol. \\n\\nSecond step is for each string `a` from `A` calcuate counter and check that it is bigger for each element than `cnt`. Again in python it can be don in very short way, using `not cnt - Counter(a)`.\\n\\n**Complexity**: time complexity is `O(m + n)`, where `m` is total length of words in `A` and `m` is total length of words in `n`. Space complexity is `O(m)`, because potentially answe can consist all strings from `A`.\\n\\n```\\nclass Solution:\\n def wordSubsets(self, A, B):\\n cnt = Counter()\\n for b in B:\\n cnt |= Counter(b)\\n \\n return [a for a in A if not cnt - Counter(a)]\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1126782, | |
| "title": "[Python] simple bfs, explained", | |
| "commentCount": 1, | |
| "post": { | |
| "creationDate": 1616666145, | |
| "voteCount": 18, | |
| "topicTitle": "[Python] simple bfs, explained", | |
| "content": "Let us reverse logic in this problem. Instead of looking for places from which one or another ocean can be reached, we will start from ocean and move in **increasing** way, not decreasing. So, we do the following\\n1. Start from `pacific` ocean: all nodes with one of coordinates equal to `0`, and perform `bfs` from all these cells: we put them into queue and then as usual popleft element and add its neigbours if we can: that is we did not visit it yet, and such that new value is more or equal to the old one. In the end my function return all visited cells.\\n2. Start from `atlantic` ocean and do exactly the same logic.\\n3. Finally, intersect two sets we get on previous two steps and return it (even though it is set, not list, leetcode allows to do it)\\n\\n**Complexity**: time and space complexity is `O(mn)`: we perform bfs twice and then did intersection of sets.\\n\\n```\\nclass Solution:\\n def pacificAtlantic(self, M):\\n if not M or not M[0]: return []\\n \\n m, n = len(M[0]), len(M)\\n def bfs(starts):\\n queue = deque(starts)\\n visited = set(starts)\\n while queue:\\n x, y = queue.popleft()\\n for dx, dy in [(x, y+1), (x, y-1), (x-1, y), (x+1, y)]:\\n if 0 <= dx < n and 0 <= dy < m and (dx, dy) not in visited and M[dx][dy] >= M[x][y]:\\n queue.append((dx, dy))\\n visited.add((dx, dy))\\n \\n return visited\\n \\n pacific = [(0, i) for i in range(m)] + [(i, 0) for i in range(1,n)]\\n atlantic = [(n-1, i) for i in range(m)] + [(i, m-1) for i in range(n-1)]\\n \\n return bfs(pacific) & bfs(atlantic)\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1125779, | |
| "title": "Dynamic programming on subsets with examples, explained", | |
| "commentCount": 11, | |
| "post": { | |
| "creationDate": 1616607492, | |
| "voteCount": 136, | |
| "topicTitle": "Dynamic programming on subsets with examples, explained", | |
| "content": "This is very useful technique, which uses both idea of bitmasks and dymamic programming. What is bitmask? It is specific way to represent data, where `1` means that element is taken and `0` that it is not taken. For example if `nums = [1,2,8,9,10]`, than bitmask `01011` represents set `{2, 9, 10}`. Of course we can use sets as well, but bitmask make it very fast and efficient.\\n\\n\\nThere is a bunch of leetcode problems (usually they are hard, but sometimes medium as well). Imagine the following problem as examples: given `2n` points on the plane we need to construct `n` segments, using all `2n` points, such that sum of length of these segments is minimal. The idea is to keep **bitmask** of already used nodes: for example `00011101` mask means that we use nodes number `0, 2, 3, 4`. Now the question is how to go from one mask to another: we can do it in `6` ways here: `11011101, 10111101, 10011111, 01111101, 01011111, 00111111`. In general we will have `2^n` masks and `O(n^2)` ways to go from one mask to another. Now, when you get the idea of how it works let us consider several problems from leetcode, where this idea can be applied:\\n\\n\\n\\n\\n### Problem 698: Partition to K Equal Sum Subsets\\nhttps://leetcode.com/problems/partition-to-k-equal-sum-subsets/\\n\\nDenote by `dp[mask]` possibility to put numbers with mask `mask` into our subsets. In more detais: we return `-1` if this partition is not possible and we return `t >= 0`, if it is possible, where `t` is reminder when we divide sum of all used numbers so far by `basket`: value, of how many we need to put in each group. Then to check if we can do it, we need to check the last number we put and check `n` possible options, where `n` is number of nums. Overall time complexity is `(2^n * n)` and space complexity is `O(2^n)`.\\n\\n```\\nclass Solution:\\n def canPartitionKSubsets(self, nums, k):\\n N = len(nums)\\n nums.sort(reverse = True)\\n\\n basket, rem = divmod(sum(nums), k)\\n if rem or nums[0] > basket: return False\\n\\n dp = [-1] * (1<<N) \\n dp[0] = 0\\n for mask in range(1<<N):\\n for j in range(N):\\n neib = dp[mask ^ (1<<j)]\\n if mask & (1<<j) and neib >= 0 and neib + nums[j] <= basket:\\n dp[mask] = (neib + nums[j]) % basket\\n break\\n\\n return dp[-1] == 0\\n```\\n\\n\\n### Problem 473 Matchsticks to Square \\nhttps://leetcode.com/problems/matchsticks-to-square/\\n\\nSpecial case of **Problem 698 Partition to K Equal Sum Subsets**, but here we need to partition into `4` equal sums (we say, put them into buckets). So actually we can reuse exactly the same code we did in **Problem 698**, but here I do it in different way, using `@lru_cache(None)`, which is used for memoisation. Time complexity is `O(2^n*n)`, space complexity is `O(2^n)`.\\n\\n```\\nclass Solution:\\n def makesquare(self, nums):\\n N = len(nums)\\n nums.sort(reverse = True)\\n if N == 0: return False\\n \\n basket, rem = divmod(sum(nums), 4)\\n if rem or nums[0] > basket: return False\\n \\n @lru_cache(None)\\n def dfs(BitMask):\\n if BitMask == 0: return 0\\n for j in range(N):\\n if BitMask & (1<<j):\\n neib = dfs(BitMask ^ (1<<j))\\n if neib >= 0 and neib + nums[j] <= basket:\\n return (neib + nums[j]) % basket\\n return -1\\n \\n return dfs((1<<N) - 1) == 0\\n```\\n\\n### 526. Beautiful Arrangement\\n\\nhttps://leetcode.com/problems/beautiful-arrangement/\\n\\n\\nLet us use dynamic programming with bitmasks. The idea is to use function `dfs(bm, pl)`, where:\\n1. `bm` is binary mask for visited numbers.\\n2. `pl` is current place we want to fill. Idea is to start from the end, and fill places in opposite direction, because for big numbers we potentially have less candidates. (if we start form `pl = 0` and go in increasing direction, then it is also will work fine, like `120ms` vs `60ms`)\\n\\nNow, let us discuss how `dfs(bm, pl)` will work:\\n1. If we reached place `0` and procces was not interrupted so far, it means that we find beautiful arrangement.\\n2. For each number `1, 2, ..., N` we try to put this number on place `pl`: and we need to check two conditions: first, that this place is still empty, using bitmask and secondly that one of the two properties for beutiful arrangement holds. In this case we add `dfs(bm^1<<i, pl - 1)` to final answer.\\n3. Finally, we run `dfs(0, N)`: from the last place and with empty bit-mask.\\n\\n**Complexity**: First of all, notice that we have `2^N` possible options for `bm`, `N` possible options for `pl`. But in all we have only `2^N` states: `pl` is uniquely defined by number of nonzero bits in `bm`. Also we have `N` possible moves from one state to another, so time complexity is `O(N*2^N)`. Space complexity is `O(2^N)`.\\n\\n```\\nclass Solution:\\n def countArrangement(self, N):\\n @lru_cache(None)\\n def dfs(bm, pl):\\n if pl == 0: return 1\\n \\n S = 0\\n for i in range(N):\\n if not bm&1<<i and ((i+1)%pl == 0 or pl%(i+1) == 0):\\n S += dfs(bm^1<<i, pl - 1)\\n return S\\n \\n return dfs(0, N)\\n```\\n\\n\\n### Problem 847 Shortest Path Visiting All Nodes\\nhttps://leetcode.com/problems/shortest-path-visiting-all-nodes/\\n\\nLet us first find distances between all pairs of nodes, using either bfs or better Floyd-Warshall algorithm with `O(n^3)` complexity. (do not be afraid of this algorithm, in fact it is just usual dp, but it is not the point of interest here, we want to focus on dp on subsets.\\n\\n\\nThen our problem is equivalent to Traveling Salesman Problem (TSP): we need to find path with smallest weight, visiting all nodes. Here we have `2^n * n` possible **states**, where state consists of two elements:\\n1. `mask`: binary mask with length `n` with already visited nodes.\\n2. `last`: last visited node.\\n\\nNote, that it is wary similar to previous approach we used, but now we need to include last visited node in our state.\\n\\nThere will be `O(n)` possible transitions for each state: for example to the state `(10011101, 7)` we will have possible steps from `(00011101, 0), (00011101, 2), (00011101, 3), (00011101, 4)`. Finally, time complexity is `O(2^n*n^2)` and space complexity is `O(2^n*n)`.\\n\\n```\\nclass Solution:\\n def shortestPathLength(self, graph):\\n n = len(graph)\\n W = [[float(\"inf\")] * n for _ in range(n)]\\n #for i in range(n): W[i][i] = 0\\n for i in range(n):\\n for j in graph[i]:\\n W[i][j] = 1\\n \\n for i,j,k in product(range(n), repeat = 3):\\n W[i][j] = min(W[i][j], W[i][k] + W[k][j])\\n \\n dp = [[float(\"inf\")] * n for _ in range(1<<n)]\\n for i in range(n): dp[1<<i][i] = 0\\n \\n for mask in range(1<<n):\\n n_z_bits = [j for j in range(n) if mask&(1<<j)]\\n \\n for j, k in permutations(n_z_bits, 2):\\n cand = dp[mask ^ (1<<j)][k] + W[k][j]\\n dp[mask][j] = min(dp[mask][j], cand)\\n\\n return min(dp[-1])\\n```\\n\\n\\n### Problem 943 Find the Shortest Superstring\\nhttps://leetcode.com/problems/find-the-shortest-superstring/\\n\\nThis is actually Travelling salesman problem (TSP) problem: if we look at our strings as nodes, then we can evaluate distance between one string and another, for example for `abcde` and `cdefghij` distance is `5`, because we need to use 5 more symbols `fghij` to continue first string to get the second. Note, that this is not symmetric, so our graph is oriented. Our state will be `(bitmask, last)` as in problem **847**.\\n\\n\\nComplexity is `O(n^2 * 2^n)`, because every state is bitmask + last visited node. In each `dp[i][j]` we will keep length of built string + built string itself.\\n\\n```\\nclass Solution:\\n def CreateConnections(self, A, N):\\n Connections = [[\"\"] * N for _ in range(N)]\\n for i, j in permutations(range(N), 2):\\n Connections[i][j] = A[j]\\n for k in range(min(len(A[i]), len(A[j]))):\\n if A[i][-k:] == A[j][:k]:\\n Connections[i][j] = A[j][k:]\\n return Connections\\n\\n def shortestSuperstring(self, A):\\n N = len(A)\\n Connections = self.CreateConnections(A, N)\\n dp = [[(float(\"inf\"), \"\")] * N for _ in range(1<<N)]\\n for i in range(N): dp[1<<i][i] = (len(A[i]), A[i])\\n \\n for i in range(1<<N):\\n n_z_bits = [len(bin(i))-p-1 for p,c in enumerate(bin(i)) if c==\"1\"]\\n \\n for j, k in permutations(n_z_bits, 2):\\n cand = dp[i ^ (1<<j)][k][1] + Connections[k][j]\\n dp[i][j] = min(dp[i][j], (len(cand), cand))\\n\\n return min(dp[-1])[1] \\n```\\n\\n### Problem 1434 Number of Ways to Wear Different Hats to Each Other\\nhttps://leetcode.com/problems/number-of-ways-to-wear-different-hats-to-each-other/\\n\\nHere our state is `dp[mask][hat_id]`, where `mask` is bitmask for used people and `hat_id` is number of hats we processed so far. Number of states is `O(2^n*m)`, where `n` is number of people and `m` is number of people. So, time complexity is `O(2^n*n*m)`.\\n\\n```\\nclass Solution:\\n def numberWays(self, hats):\\n n, M, N_hats = len(hats), 10**9 + 7, 41\\n\\n hats_persons = defaultdict(set) \\n for person_id, person in enumerate(hats):\\n hats_persons[person_id] = set(person)\\n\\n dp = [[0] * N_hats for _ in range(1<<n)] \\n dp[0][0] = 1\\n\\n for mask in range(0, 1<<n):\\n for hat_id in range(N_hats):\\n for person in range(n):\\n neib = mask ^ 1<<(person)\\n if neib != mask and hat_id in hats_persons[person]: \\n dp[mask][hat_id] += dp[neib][hat_id-1]\\n\\n dp[mask][hat_id] = (dp[mask][hat_id] + dp[mask][hat_id-1]) % M\\n\\n return int(dp[-1][-1] % M)\\n```\\n\\n### Problem 1494 Parallel Courses II\\nhttps://leetcode.com/problems/parallel-courses-ii/\\n\\n\\nLet us denote by `dp[i][j]` tuple with: \\n1. minumum number of days we need to finish\\n2. number of non-zero bits for binary mask of the last semester\\n3. binary mask of the last semester\\n\\nall courses denoted by binary mask `i` and such that the last course we take is `j`. For example for `dp[13][3]`, `i=13` is represented as `1101`, and it means that we take courses number `0`, `2`, `3` and the last one we take is number `3`. (instead of starting with `1`, let us subtract `1` from all courses and start from `0`).\\n\\nLet us also introduce `bm_dep[i]`: this will be binary mask for all courses we need to take, before we can take course number `i`. For example `bm_dep[3] = 6 = 110` means, that we need to take courses `1` and `2` before we can take course number `3`.\\n\\nNow, let us iterate over all `i in range(1<<n)`. Let us evaluate `n_z_bit`, this will be an array with all places with non-zero bits. For example for `i=13=1101`, `n_z_bit = [0,2,3]`.\\n\\nWhat we need to do next, we:\\n1. First check that we really can take new course number `j`, using `bm_dep[j] & i == bm_dep[j]`.\\n2. Now, we want to update `dp[i][j]`, using `dp[i^(1<<j)][t]`, for example if we want to find answer for `(1,3,4,5)` courses with `3` being the last course, it means that we need to look into `(1,4,5)` courses, where we add course `3`.\\n3. We check how many courses we already take in last semester, using `bits < k`, and also make sure, that we can add new course to last semester. Now we have two candidates: `(cand, bits + 1, mask + (1<<j))` and `dp[i][j]` and we need to choose the best one. In other case, we need to take new semester: so `cands` will be equalt to `cands + 1`, `bits` will be equal to `1` and binary mask for last semester is `1<<j`.\\n\\n**Complexity** is `O(n^2*2^n)`, because we iterate all bitmasks and then we iterate over all pairs of non-zero bit, and we heve `O(n^2)` of them. Memory is `O(2^n * n)`.\\nI think it can be simplified to `O(n*2^n)/O(2^n)` complexity, but I am not sure yet.\\n\\n```\\nclass Solution:\\n def minNumberOfSemesters(self, n, dependencies, k):\\n dp = [[(100, 0, 0)] * n for _ in range(1<<n)]\\n \\n bm_dep = [0]*(n)\\n for i,j in dependencies:\\n bm_dep[j-1]^=(1<<(i-1))\\n\\n for i in range(n):\\n if bm_dep[i] == 0: dp[1<<i][i] = (1, 1, 1<<i)\\n \\n for i in range(1<<n):\\n n_z_bits = [len(bin(i))-p-1 for p,c in enumerate(bin(i)) if c==\"1\"]\\n \\n for t, j in permutations(n_z_bits, 2):\\n if bm_dep[j] & i == bm_dep[j]:\\n cand, bits, mask = dp[i^(1<<j)][t]\\n if bm_dep[j] & mask == 0 and bits < k:\\n dp[i][j] = min(dp[i][j], (cand, bits + 1, mask + (1<<j)))\\n else:\\n dp[i][j] = min(dp[i][j], (cand+1, 1, 1<<j))\\n \\n return min([i for i, j, k in dp[-1]])\\n```\\n\\n### Problem 1655 Distribute Repeating Integers\\n\\nhttps://leetcode.com/problems/distribute-repeating-integers/\\n\\nLet us precalculate sums of all subsets first for speed. Let us define our state as `dfs(i, mask)`, where `i` is index not of customer, but `Counter(nums)`:\\n\\nImagine we have `Counter(nums) = 10, 5` and `quantities = 5,7,3`, then we first try to distribute `10`: on different bitmasks: `000, 001, 010, 011, 100, 101, 110, 111`, here we can choose `000, 001, 010, 001, 101, 011`: `000` coressponds to emty, `010` to `7`, `101` to `5 + 3` and so on).\\n\\nFor each state and mask we need to iterate over all submasks and we can do it efficiently in the way it is shown in code. It can be proven, that time complexity of this code is `O(m*3^m)`, space complexity is `O(m*2^m)`.\\n\\n```\\nclass Solution:\\n def canDistribute(self, a, customers):\\n m = len(customers)\\n a = sorted(Counter(a).values())[-m:]\\n n = len(a)\\n \\n mask_sum = [0]*(1<<m)\\n for mask, i in product(range(1<<m), range(m)):\\n if (1 << i) & mask:\\n mask_sum[mask] += customers[i]\\n \\n \\n @lru_cache(None)\\n def dfs(i, mask):\\n if mask == 0: return True\\n if i == n: return False\\n \\n submask = mask\\n while submask:\\n if mask_sum[submask] <= a[i] and dfs(i+1, mask ^ submask):\\n return True\\n submask = (submask-1) & mask\\n return dfs(i+1, mask)\\n \\n return dfs(0, (1<<m) - 1)\\n```\\n\\n### Problem 1659 Maximize Grid Happiness \\n\\nhttps://leetcode.com/problems/maximize-grid-happiness/\\n\\nLet us us dynamic programming with the following states: \\n\\n1. `index`: number of cell in our grid, going from `0` to `mn-1`: from top left corner, line by line.\\n2. `row` is the next row filled with elements `0`, `1` (for introvert) or `2` (for extravert): see on my diagramm.\\n3. `I` is number of interverts we have left.\\n4. `E` is number of extraverts we have left.\\n\\n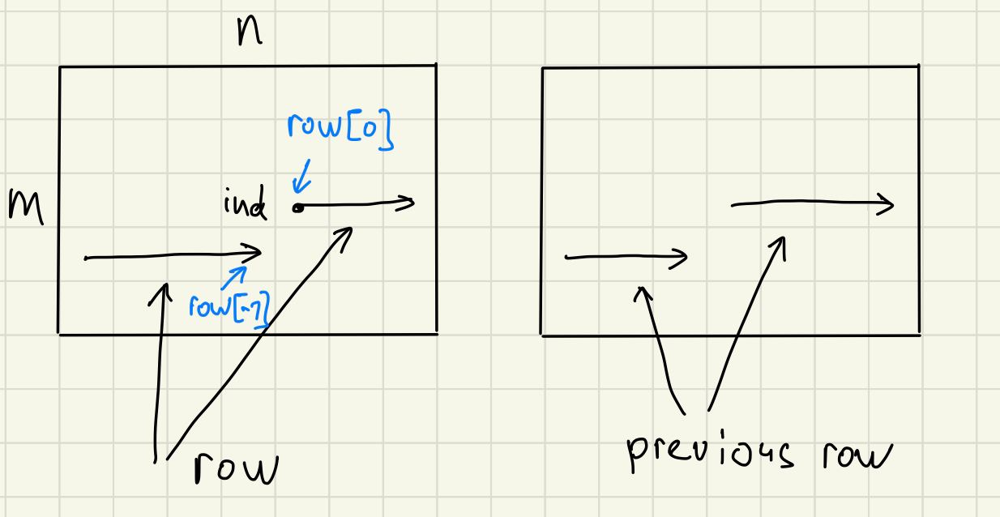\\n\\n\\nNow, let us fill out table element by element, using `dp` function:\\n\\n1. First of all, if we reached `index == -1`, we return 0, it is our border case.\\n2. Compute `R` and `C` coordinates of our cell.\\n3. Define `neibs`: it is parameters for our recursion: fist element is what we put into this element: `0`, `1` or `2`, second and third elements are new coordinates and last one is gain.\\n4. Now, we have `3` possible cases we need to cover: new cell is filled with `0`, `1` or `2` and for each of these cases we need to calculate `ans`:\\na) this is `dp` for our previous row, shifted by one\\nb) gain we need to add when we add new intravert / extravert / empty\\nc) check right neighbor (if we have any) and add `fine`: for example if we have 2 introverts, both of them are not happy, so we need to add `-30-30`, if we have one introvert and one extravert, it is `20-30` and if it is two extraverts it is `20+20`.\\nd) do the same for down neigbor if we have any (**see illustration for help**)\\n\\nFinally, we just return `dp(m*n-1, tuple([0]*n), I, E)`\\n\\n**Complexity**: time complexity is `O(m*n*I*E*3^n)`, because: `index` goes from `0` to `mn-1`, `row` has `n` elements, each of them equal to `0`, `1` or `2`.\\n\\n```\\nclass Solution:\\n def getMaxGridHappiness(self, m, n, I, E):\\n InG, ExG, InL, ExL = 120, 40, -30, 20\\n fine = [[0, 0, 0], [0, 2*InL, InL+ExL], [0, InL+ExL, 2*ExL]]\\n \\n @lru_cache(None)\\n def dp(index, row, I, E):\\n if index == -1: return 0\\n\\n R, C, ans = index//n, index%n, []\\n neibs = [(1, I-1, E, InG), (2, I, E-1, ExG), (0, I, E, 0)] \\n \\n for val, dx, dy, gain in neibs:\\n tmp = 0\\n if dx >= 0 and dy >= 0:\\n tmp = dp(index-1, (val,) + row[:-1], dx, dy) + gain\\n if C < n-1: tmp += fine[val][row[0]] #right neighbor\\n if R < m-1: tmp += fine[val][row[-1]] #down neighbor\\n ans.append(tmp)\\n\\n return max(ans)\\n \\n if m < n: m, n = n, m\\n \\n return dp(m*n-1, tuple([0]*n), I, E)\\n```\\n\\n### Problem 1681. Minimum Incompatibility\\n\\nhttps://leetcode.com/problems/minimum-incompatibility/\\n\\nWe need to keep state in the form: `bitmask, last`, where:\\n1. `bitmask` is bitmask for all numbers already taken.\\n2. `last` is index of last taken number.\\n\\nHow are we going to form our groups: sort our numbers first and imagine we have numbers `[1,1,2,3,3,4]`: and `k = 3`. Then we need to create first group of `2` elements, for example it can be elements with indexes `1,2`, and we have current bitmask `011000`, then we need to form another group of `2` elements, for example it can be elements with indexes `0,5`, so we have bitmask `111001` now. Finally we put last two elements in last group. We can interpret it as TSP problem: we choose path `1->2->0->5->3->4`. Note, that in each group we only choose increasing indexes, whereas between groups than can decrease (but can increase also).\\n\\nNow, what we have in our algorithm:\\n1. We iterate over all possible `mask`\\n2. Calculate places, where we have `1` in this mask.\\n3. Now, we can have two cases: first, if `len(n_z_bits)%(n//k) == 1`: it means, that it is time to start new group, so we can choose any index we want, not neccecerily bigger than previous, so we choose `permutations` here: there will be exactly `t(t-1)/2` pairs and for each of them we update `dp[mask][l]`.\\n4. In other case, it means, that we need to continue to build our group, so next index should be bigger than previous and we choose `combinations` here. Also we check that new number is not equal to last one we have and again update `dp[mask][l]`.\\n5. Finally, we return minimum from `dp[-1]`.\\n\\n**Complexity**: time complexity is `O(n*n*2^n)` as TSP have: we have `2^n` bitmasks and we have `O(n^2)` time to process each mask. In python it is working not very fast, I can say it is barely accepted, so, I think there should be `O(n*2^n)` solution as well, if you know such solution (desirebly with explanations), please let me know!\\n\\n```\\nclass Solution:\\n def minimumIncompatibility(self, nums, k):\\n n = len(nums)\\n if k == n: return 0\\n dp = [[float(\"inf\")] * n for _ in range(1<<n)] \\n nums.sort()\\n for i in range(n): dp[1<<i][i] = 0\\n\\n for mask in range(1<<n):\\n n_z_bits = [j for j in range(n) if mask&(1<<j)]\\n if len(n_z_bits)%(n//k) == 1:\\n for j, l in permutations(n_z_bits, 2):\\n dp[mask][l] = min(dp[mask][l], dp[mask^(1<<l)][j])\\n else:\\n for j, l in combinations(n_z_bits, 2):\\n if nums[j] != nums[l]:\\n dp[mask][j] = min(dp[mask][j], dp[mask^(1<<j)][l] + nums[l] - nums[j])\\n \\n return min(dp[-1]) if min(dp[-1]) != float(\"inf\") else -1\\n```\\n\\n\\n### Problem 854 K-Similar Strings\\nhttps://leetcode.com/problems/k-similar-strings/\\n\\nNote similarity of this problem with Problem `Q765 Couples Holding Hands`, but here we have more `6` different symbols. Let us look at this problem as to graph: for example if we have `A = abcde` and `B = bcaed`, then we need to find `2` loops: `a -> b -> c -> a` and `d -> e -> d`. In general we need to find minimum number of loops in directed graph on `m = 6` nodes, where we can have multiple edges and we have `n` edges. However it is still difficult problem and it is not obvious how to handle it.\\n\\n\\nLet us assign number to each letter: `a:1, b:32, c:32^2, d:32^3, e:32^4, f:32^5`. Now, we evaluate difference between corresponding elements of two strings, so for example for given example we have `[-31, -992, 1023, -1015808, 1015808]`. Now, finding loop is equivalent to group of elements which has `0` when we sum them! Why? Because if some sum is equal to zero, it means, that numbers in both sets are equal: we choose `32 > 20`, length of our string): indeed, imagine, that we have set of numbers with sum $0$, it means:\\n\\n`alpha_0 * 1 + alpha_1 * 32 + ... + alpha_5 * 32^5 = beta_0 * 1 + beta * 32 + ... + beta * 32^5,`\\n\\nwhere `alpha_0, ... alpha_5` is corresponding number of `a, b, c, d, e, f`, similar for betas. From here we have\\n\\n`gamma_0 * 1 + gamma_1 * 32 + ... + gamma_5 * 32^5 = 0, `\\n\\nwhere `gamma_i = alpha_i - beta_i` lies in `[-20, 20]`. If we consider biggest `gamma_i` which is not equal to `0`, then sum of all other terms is smaller than this term, so it means that all `gamma_i` equal to zero, that is we have the same set of letters.\\n\\nActually, this is almost equivalent to Problem **Q698 Partition to K Equal Sum Subsets** we already discussed. Time complexity is `O(2^n * n)` and space complexity is `O(2^n)`.\\n\\nTo be accepted on Leetcode, we need to make couple of optimizations: first of all, if two symbols on the same place are equal, we just remove them. Also if we have loop of length `2` we also remove it: here I use trick, where we intersect count for `nums` and list with all opposite numbers from `nums`. Then for each element we repeat it as much times as needed and delete from our list.\\n\\n```\\nclass Solution:\\n def kSimilarity(self, A, B):\\n nums = [((1<<ord(i)*5) - (1<<ord(j)*5))>>(97*5) for i,j in zip(A,B) if i!=j] \\n\\n Cnt = Counter(nums) & Counter(-n for n in nums)\\n pairs = list(chain(*([i]*j for i, j in Cnt.items())))\\n for num in pairs: nums.remove(num)\\n \\n n = len(nums)\\n \\n dp = [(-1,0)] * (1<<n)\\n dp[0] = (0, 0)\\n\\n for mask in range(1<<n):\\n for j in range(n):\\n if mask & (1<<j):\\n steps, summ = dp[mask ^ (1<<j)]\\n dp[mask] = max(dp[mask], (steps + (summ==0), summ + nums[j]))\\n\\n return n - dp[-1][0] + len(pairs)//2\\n```\\n\\n### Problem 1799 Maximize Score After N Operations\\n\\nhttps://leetcode.com/problems/maximize-score-after-n-operations/\\n\\n Let us define by `dp(bitmask)` the answer for subproblem, where we can use only numbers with `1` bits, for example if `nums = [1,2,3,4,5,6]` and `bitmask = 010111`, we can use numbers `2, 4, 5, 6`.\\n\\nHow we can calculate `dp(bitmask)`? We need to look at all pairs of not used yet numbers and take `dp` of the resulting mask. Then choose maximum among all possible candidates.\\n\\n**Complexity**: time complexity is `O(2^(2n)*n^2)`, because we have `2^(2n)` different bitmasks and for each masks and for each of them we have `O(n^2)` transitions to other bitmasks. Also I precalculated all gcds, which will give you complexity `O(n^2*log M)`, where `M` is the biggest number in `nums`. Space complexity is `O(2^(2n))`.\\n\\n```\\nclass Solution:\\n def maxScore(self, nums):\\n n = len(nums)\\n gcds = {(j, k): gcd(nums[j], nums[k]) for j, k in combinations(range(n), 2)}\\n\\n @lru_cache(None)\\n def dfs(bitmask):\\n if bitmask == 0: return 0\\n \\n cand = 0\\n n_z_bits = [j for j in range(n) if bitmask&(1<<j)]\\n for j, k in combinations(n_z_bits, 2):\\n q = bitmask^(1<<j)^(1<<k)\\n cand = max(cand, dfs(q) + (n+2 - len(n_z_bits))//2*gcds[j, k])\\n return cand\\n\\n return dfs((1<<n) - 1)\\n```\\n\\nIf you know more problems where you can use dp on subsets, please let me know in comments, I will add it (probably some of the premium problems are, but I do not have access to them, also I did not solve all problems on leetcode, so I probably missed some of the problems)\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1125119, | |
| "title": "[Python] Greedy solution, Two Pointers, explained", | |
| "commentCount": 6, | |
| "post": { | |
| "creationDate": 1616574256, | |
| "voteCount": 40, | |
| "topicTitle": "[Python] Greedy solution, Two Pointers, explained", | |
| "content": "The idea here is to sort `A` and `B` lists first and start with the biggest number from `B` and check if we can beat it with biggest number from `A`. If we can, do it and increase `beg` pointer. If no, than we need to choose the smallest number we have and we move `end` pointer. One difficulty here is that we need to keep order of data somehow, so we add indexes to `B` list. Then we create `ans` list and change corresponding element of it.\\n\\nTime complexity is `O(n log n)` to perform sorts and space complexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def advantageCount(self, A, B):\\n n = len(A)\\n B = sorted([(num, i) for i, num in enumerate(B)])[::-1]\\n A = sorted(A)[::-1]\\n ans = [-1]*n\\n \\n beg, end = 0, n - 1\\n \\n for num, ind in B:\\n if A[beg] > num:\\n ans[ind] = A[beg]\\n beg += 1\\n else:\\n ans[ind] = A[end]\\n end -= 1\\n \\n return ans\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1123498, | |
| "title": "[Python] Combinatorics solution, explained", | |
| "commentCount": 4, | |
| "post": { | |
| "creationDate": 1616489774, | |
| "voteCount": 19, | |
| "topicTitle": "[Python] Combinatorics solution, explained", | |
| "content": "Let us calculate `Counter(arr)`, that is how what is frequency of each number and then check `3` cases:\\n1. All numbers `i < j < k` ar different: then we can check all possible permutations for numbers `i` and `j` and then check that for `k = target - i - j` we have `i < j < k`.\\n2. For numbers `i, j, k` we have `i = j != k`. Then we have `c[i]*(c[i]-1)*c[target - 2*i]//2` number of options. Why? Because we need to choose `i` element twice, this is number of combinations with `2` elements from `c[i]` elements. Note, that I did not specify which of three indexes here is smaller and which is bigger, so here we cover all cases where exactly `2` indexes are equal.\\n3. For numers `i, j, k` we have `i = j = k`. Here answer is `c[i]*(c[i]-1)*(c[i]-2)//6`: number of combinations with `3` elements from `c[i]` elements.\\n\\n**Complexity**: time complexity is `O(n^2)`, where `n` is length of `arr`, because on first iteration we did `O(n^2)` and on second and third we did `O(n)`. Space complexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def threeSumMulti(self, arr, target):\\n c = Counter(arr)\\n ans, M = 0, 10**9 + 7\\n for i, j in permutations(c, 2):\\n if i < j < target - i - j:\\n ans += c[i]*c[j]*c[target - i - j]\\n\\n for i in c:\\n if 3*i != target:\\n ans += c[i]*(c[i]-1)*c[target - 2*i]//2\\n else:\\n ans += c[i]*(c[i]-1)*(c[i]-2)//6\\n \\n return ans % M\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1121864, | |
| "title": "[Python] Use 3 dictionaries, explained", | |
| "commentCount": 15, | |
| "post": { | |
| "creationDate": 1616403191, | |
| "voteCount": 29, | |
| "topicTitle": "[Python] Use 3 dictionaries, explained", | |
| "content": "Not very difficult problem, you just need to be careful and use idea of masks here. For example for word `heLLO` I define mask like this `h*ll*`, that is put all letters to lower case and replace all vowels to `*`. Why it is good idea to do it? Because if two words have the same mask, it means, that one of them is correction of another. We need to check `3` cases:\\n\\n1. If `query` word in original `wordlist`, we just return this word.\\n2. If `query.lower()` word in `d1`: dictionary for words without corrections, which is correspondence between word and its lower case, for example `heLlO: hello`. If we found `query` in this dictionary, by problem statement we need to return the first such match in the wordlist: that is why when we define `d1`, we from the end and rewrite matches if we have more than one.\\n3. Finally, if `mask(query)` in dictionary `d2`, we return `d2[mask(query)]`. Note, that we defined `d2` also from the end.\\n\\n**Complexity**: it is `O(M + N)`, where `M` is total length of words in `wordlist` and `M` is total length of words in `queries`, because we process each word from `wordlist` no more than `3` times and each word from query `1` time.\\n\\n```\\nclass Solution:\\n def spellchecker(self, wordlist, queries):\\n def mask(w):\\n return \"\".join(\\'*\\' if c in \\'aeiou\\' else c for c in w.lower())\\n \\n d0 = set(wordlist)\\n d1 = {w.lower(): w for w in wordlist[::-1]}\\n d2 = {mask(w): w for w in wordlist[::-1]}\\n \\n def solve(query):\\n if query in d0: return query\\n if query.lower() in d1: return d1[query.lower()]\\n if mask(query) in d2: return d2[mask(query)]\\n return \"\"\\n \\n return [solve(q) for q in queries]\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1120130, | |
| "title": "[Python] Find anagram, explained", | |
| "commentCount": 1, | |
| "post": { | |
| "creationDate": 1616314956, | |
| "voteCount": 7, | |
| "topicTitle": "[Python] Find anagram, explained", | |
| "content": "This is in fact question about anagrams: given string we need to find if we have another string from list of powers of too, which is anagram of original string. Let us iterate through all powers of two and check if count of this number is equal to count of given number `N`. \\n\\n**Complexity**: time complexity will be `O(log^2 N)`: we check `O(log N)` numbers, each of them have `O(log N)` digits at most. In fact it can be improved to `O(log^2N)`, because there can be at most `4` numbers with given number of digits, but here it just not worth it. Space complexity is `O(log N)`.\\n\\n```\\nclass Solution:\\n def reorderedPowerOf2(self, N):\\n cnt = Counter(str(N))\\n return any(cnt == Counter(str(1<<i)) for i in range(30))\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1118747, | |
| "title": "[Python] Short dp on subsets, explained.", | |
| "commentCount": 4, | |
| "post": { | |
| "creationDate": 1616256043, | |
| "voteCount": 21, | |
| "topicTitle": "[Python] Short dp on subsets, explained.", | |
| "content": "When you see constraints of this problem you should think about dynaimc programming on subsets. Let us define by `dp(bitmask)` the answer for subproblem, where we can use only numbers with `1` bits, for example if `nums = [1,2,3,4,5,6]` and `bitmask = 010111`, we can use numbers `2, 4, 5, 6`.\\n\\nHow we can calculate `dp(bitmask)`? We need to look at all pairs of not used yet numbers and take `dp` of the resulting mask. Then choose maximum among all possible candidates.\\n\\n**Complexity**: time complexity is `O(2^(2n)*n^2)`, because we have `2^(2n)` different bitmasks and for each masks and for each of them we have `O(n^2)` transitions to other bitmasks. Also I precalculated all gcds, which will give you complexity `O(n^2*log M)`, where `M` is the biggest number in `nums`. Space complexity is `O(2^(2n))`.\\n\\n```\\nclass Solution:\\n def maxScore(self, nums):\\n n = len(nums)\\n gcds = {(j, k): gcd(nums[j], nums[k]) for j, k in combinations(range(n), 2)}\\n\\n @lru_cache(None)\\n def dfs(bitmask):\\n if bitmask == 0: return 0\\n \\n cand = 0\\n n_z_bits = [j for j in range(n) if bitmask&(1<<j)]\\n for j, k in combinations(n_z_bits, 2):\\n q = bitmask^(1<<j)^(1<<k)\\n cand = max(cand, dfs(q) + (n+2 - len(n_z_bits))//2*gcds[j, k])\\n return cand\\n\\n return dfs((1<<n) - 1)\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1118415, | |
| "title": "[Python] Dictionary + Counters solution, explained", | |
| "commentCount": 7, | |
| "post": { | |
| "creationDate": 1616234765, | |
| "voteCount": 23, | |
| "topicTitle": "[Python] Dictionary + Counters solution, explained", | |
| "content": "The main difficulty of this problem is very long statement, and probably you will spend more time understanding what is asked that to code it. So, what we have here. We have several persons, defined by `id`, which Check In at some `station` and some `time` and then Check Out from some other station at another time. We need to calculate times this person spend to go from one station to another and then calculate average time for all persons. Let us keep 3 pieces of information:\\n\\n1. `self.ids` is dictionary, where for each person(id) we will keep pair `(station, time)` if the last action this person did is check In and empty if it was check OUt\\n2. `self.pairs` is counter, where for each pair of stations we keep total time spend between two stations.\\n3. `self.freqs` is counter, where for each pair of stations we keep how many trips we have between these two stations.\\n\\nNow, let us discuss, what our functions will do:\\n1. `checkIn(self, id, stationName, t)`: we just put pair `(stationName, t)` into `self.ids[id]`.\\n2. `checkOut(self, id, stationName, t)`. Here we look at person `id`, extract information about his last station visited (pop it from `self.ids[id]` and update `self.pairs`, `self.freqs` for these pairs of stations.\\n3. `getAverageTime(self, startStation, endStation)`: here we just look at dictionaries `self.pairs` and `self.freqs` and directly return result.\\n\\n**Complexity**: time compexlty is `O(1)` for all `3` operations. Space complexity potentially is `O(Q)`, where `Q` is toatl number of queries.\\n\\n```\\nclass UndergroundSystem:\\n def __init__(self):\\n self.ids = {}\\n self.pairs = Counter()\\n self.freqs = Counter()\\n \\n def checkIn(self, id, stationName, t):\\n self.ids[id] = (stationName, t)\\n\\n def checkOut(self, id, stationName, t):\\n Name2, t2 = self.ids.pop(id)\\n self.pairs[(Name2, stationName)] += t-t2\\n self.freqs[(Name2, stationName)] += 1\\n \\n def getAverageTime(self, startStation, endStation):\\n return self.pairs[startStation, endStation]/self.freqs[startStation, endStation]\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1116703, | |
| "title": "[Python] Simple dfs + oneliner, explained", | |
| "commentCount": 4, | |
| "post": { | |
| "creationDate": 1616139324, | |
| "voteCount": 20, | |
| "topicTitle": "[Python] Simple dfs + oneliner, explained", | |
| "content": "The main idea you need to understand to solve this problem that it is a graph problem. We have list of rooms - nodes and for each room you have list of keys, this is edges which go from this node. Problem is asking if you can traverse all graph, starting from node `0`. As usual, there are different ways to do it:\\n1. iterative `dfs` with stack\\n2. recursive `dfs` without explicit stack (however we have implicit stack)\\n3. `bfs`, using queue.\\n\\nWhenever I can I choose recursive `dfs`, because it is the easiest to code: we keep set of visited nodes, and for `dfs(room)` we try to visit all new rooms which we can open with keys, which we did not visit yet, run then to visited set and run `dfs` recursively. In the end we check that length of visited set is equal to length of total number of rooms.\\n\\n**Complexity**: time complexity is `O(N+E)`, where `N` is number of rooms ans `E` is total number of keys. Space complexity is `O(N)` - size of `visited` and size of implicit stack as well.\\n\\n```\\nclass Solution:\\n def canVisitAllRooms(self, rooms):\\n visited = set([0])\\n \\n def dfs(room):\\n for neib in rooms[room]:\\n if neib not in visited:\\n visited.add(neib)\\n dfs(neib)\\n \\n dfs(0)\\n return len(visited) == len(rooms) \\n```\\n\\n### Oneliner, just for fun:\\nIdea is to construct adjacency matrix and then use matrix exponent to understand if we can reach nodes or not.\\n```\\nfrom scipy.sparse.linalg import expm\\n\\nclass Solution:\\n def canVisitAllRooms(self, rooms):\\n return 0 not in expm([[j in r + [i] for j in range(len(rooms))] for i,r in enumerate(rooms)])[0]\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1115235, | |
| "title": "[Python] 5 lines dp with O(n), explained", | |
| "commentCount": 5, | |
| "post": { | |
| "creationDate": 1616056462, | |
| "voteCount": 10, | |
| "topicTitle": "[Python] 5 lines dp with O(n), explained", | |
| "content": "Define by `dp(i, 1)` the biggest length of wiggle subsequense, which ends with element `nums[i]` and has and increasing status, and `dp(i, -1)` is the biggest length of wiggle subsequence, which ends with element `nums[i]` and has decreasing status.\\n\\nHow we can calculate `dp(i, 1)`, looking at previous element `nums[i-1]`:\\n1. if `nums[i-1] < nums[i]`, then it means that we need to look at `dp(i - 1, -1) + 1`: look at the biggest subsequence ending in `i-1`, which have decreasing status and add `1`, because we can continue it by one element.\\n2. if `nums[i-1] >= nums[i]`, then we can not continue subsequence with decreasing status, all we can do is to look at `dp(i-1, 1)`.\\n3. Very similar logic is used to calculate `dp(i, -1)`. Here I write both cases in very compact way in one line. \\n\\nNote also that here we can say we use greedy approach: it is always enough to take previous element `nums[i-1]` to continue to build our subsequence, the logic is the following: actually what matters are **local extremums** in our array. Imagine, that we have part of array like this `100, 1, 2, 5, 10, 13, 20, 1`. What can we say about part `1, 2, 5, 10, 13, 20`? We can take only `2` elements, and the best case will be to take `1` and `20`.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(n)` as well, which potentially can be reduced to `O(1)`.\\n\\n```\\nclass Solution:\\n def wiggleMaxLength(self, nums):\\n @lru_cache(None)\\n def dp(i, s):\\n if i == 0: return 1\\n return dp(i-1, -s) + 1 if (nums[i] - nums[i-1])*s < 0 else dp(i-1, s)\\n \\n return max(dp(len(nums)-1, -1), dp(len(nums)-1, 1))\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1113679, | |
| "title": "[Python] Polar coordinates, explained with diagrams and math", | |
| "commentCount": 20, | |
| "post": { | |
| "creationDate": 1615970974, | |
| "voteCount": 79, | |
| "topicTitle": "[Python] Polar coordinates, explained with diagrams and math", | |
| "content": "Imagine first special case for this problem: we have circle with radius equal to `1` and coordinates of center is `(0, 0)`. Let us use polar coordinates:\\n`x = R * cos(theta)`\\n`y = R * sin(theta)`.\\n\\n<img src=\"https://assets.leetcode.com/users/images/0a8d83b0-69fb-4ee7-866b-91fce8ddfb2f_1615969976.4114075.png\" alt=\"closed_paren\" title=\"Closed Parenthesis\" width=\"250\" height=\"250\"/>\\n\\n\\n\\nHere `R` is distance between our point (call it `A`) and the origin (call it `O`). `theta` is angle between `OA` and axis `OX`.\\nWhy it is good idea to go to polar coordinates here? Because in polar coordiantes unity circle can be written as:\\n`R <= 1`\\n`0 <= theta <= 2*pi`.\\n\\nNow we need to answer two qustions: how to generate `R` and how to generate `theta`.\\n\\n1. About `theta` it is quite obvious: we do it uniformly.\\n2. About `R` it is not obvious: if we do it uniformly, there will be more points closer if we generate it in uniform way. Look at this intuition: let us fix `R = 1` and generate `10` points, then fix `R = 0.5` and generate `10` more points. What you can see? Distance between points on the big circle is in average `2` times bigger, than between `2` points on smaller circle. It actually means, that for small circle you need to generate only `5` points, not `10`, and by this logic if you have `x` points for circle with `R = 1`, you need `x*R` points for smaller radius. \\n\\n<img src=\"https://assets.leetcode.com/users/images/d8f828cb-bf5a-40dc-9da9-cddf6656b2ac_1615970011.1811876.png\" alt=\"closed_paren\" title=\"Closed Parenthesis\" width=\"200\" height=\"200\"/>\\n\\n\\nThis was intuition, now let go into mathematics: what does uniform distribution means, that if we choose small element inside our circle, than probability to get inside this element should be proportional to area of this element. Let us define `F(R)` cumulative distribution function (cdf) for radius. Then by definition probability to get between `R` and `R + dR` is equal to `F(R + dR) - F(R) = f(R)*dR`, where `f(R)` is probability density function (pdf), so probability to get into this small region is `f(R)* dR * dTheta`. From other point of view, area of this region can be calclated as `[(R+dR)^2 - R^2]*dTheta = 2*R*dR*dTheta`. From here we get, that `f(R) = c*R` for some constant `c` (because we say it is proportional, not equal). Now, `F\\'(R) = f(R)`, so `F(R) = c*R^2` (here `c` is another conatant). Now the question is how you generate data such that cumulative function is proportional to `R^2`. The answer is **Inverse transform sampling** (check wikipedia), where idea is given uniform distribution generate data from any distribution `F(R)`: we need to generate `R` from uniform distrubution and than apply inverse function, that is we have `sqrt(uniform(0,1))` in the end.\\n\\n<img src=\"https://assets.leetcode.com/users/images/ed0b4ca6-695b-4006-9985-968a1fc76279_1615969804.150301.png\" alt=\"closed_paren\" title=\"Closed Parenthesis\" width=\"250\" height=\"250\"/>\\n\\n**Complexity**: time and space complexity is just `O(1)`.\\n\\n```\\nclass Solution:\\n def __init__(self, radius, x_center, y_center):\\n self.r, self.x, self.y = radius, x_center, y_center\\n\\n def randPoint(self):\\n theta = uniform(0,2*pi)\\n R = self.r*sqrt(uniform(0,1))\\n return [self.x + R*cos(theta), self.y + R*sin(theta)]\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1112112, | |
| "title": "[Python] Another dp solution, explained", | |
| "commentCount": 1, | |
| "post": { | |
| "creationDate": 1615883055, | |
| "voteCount": 13, | |
| "topicTitle": "[Python] Another dp solution, explained", | |
| "content": "Let us define `diff[i] = B[i+1] - B[i]`. Then we need to find maximum gain for several continuous subarrays, where we pay fee for each subarray. Let us consider it on example:\\n`[1, 3, 5, 4, 8, 7, 4]`, then differences will be `[2, 2, -1, 4, -1, -3]`. For example we can take two subarrays `[2, 2]` and `[4]`, it means we make two trancastions and we need to pay `2` fees. In original array it means we buy at price `1`, then sell at price `5`. Then buy at price `4` and sell at price `8`.\\n\\nUse dynamic programming, where `dp[i]` is maximum gain at `i`-th moment of time if we use `diff[i]` and `sp[i]` be maximum among `dp[0], ..., dp[i]`, that is running maximum, that is `sp[i]` is the gain we can get, using first `i` times.\\nThen we can have `2` options:\\n\\n1. We continue last subarray, so we get `diff[i] + dp[i-1]`.\\n2. We start new subarray, so we get `diff[i] + sp[i-2] - fee`: here we take `sp[i-2]`, because we need to skip one element, so subarrays are separated.\\n\\nLet us look at our example with differences `[2, 2, -1, 4, -1, -3]`:\\n\\n1.`dp[0]` is the maximum gain we can get using ony first difference, we can have `2` and we need to pay fee, so we have `1`.\\n2.`dp[1]` is maxumum gain we can get using `[2, 2]`. We can continue previous transaction, so we will gain `3`. Or we can try to start new transaction. However it is not possible, because we need to have a gap here.\\n3.`dp[2]` is maximum gain we can get using `[2, 2, -1]`. Note, that by definition of `dp[i]` we need to use last element here, so again we have two choices: if we continue first transaction, we have `3-1 = 2` gain. Or we start new transaction, and then we need to make gap and previous transaction will be for element `i-2` or smaller. Exaclty for this we use `sp`: running maximum of `dp`. In our case `sp[0] = 1`, so total gain if we start new transaction is `sp[0] - fee + -1 = -1`.\\n4.`dp[3]` is maximum gain we can get using `[2, 2, -1, 4]`. Again, we can have two choices: continue last transaction, in this case we have `dp[2] + 4 = 6`. If we start new transaction, we have `sp[1] - fee + 4 = 6` as well. So in this case does not matter, what option we choose and it makes sence: fee is equal to decrease of price.\\n5.`dp[4]` is maximum gain we can get using `[2, 2, -1, 4, -1]`. Again, we have choice between `dp[3] + -1 = 5` and `sp[2] - fee + -1 = 4`.\\n6.`dp[5]` is maximum gain we can get using `[2, 2, -1, 4, -1, -3]`. We have either `dp[4] + -3 = 2` or `sp[3] - fee + -3 = 2`.\\n\\nFinally, we have arrays like this:\\n\\n`dp = [1, 3, 2, 6, 5, 2, -inf]`\\n`sp = [1, 3, 3, 6, 6, 6, 0]`\\n\\n**Complexity**: time and space complexity is `O(n)`, where space complexity can be reduced to `O(1)`, because we use only `2` elements to the back.\\n\\n```\\nclass Solution:\\n def maxProfit(self, B, fee):\\n if len(B) == 1: return 0\\n n = len(B)\\n \\n dp, sp = [-float(inf)]*n, [0]*n\\n\\n for i in range(n-1):\\n dp[i] = B[i+1] - B[i] + max(dp[i-1], sp[i-2] - fee)\\n sp[i] = max(sp[i-1], dp[i])\\n \\n return sp[-2] \\n```\\n\\nOther buy and sell stock problems with my explanations:\\n\\n**121: Best Time to Buy and Sell Stock**\\nhttps://leetcode.com/problems/best-time-to-buy-and-sell-stock/discuss/851941/Python-O(n)-dynamic-programming-solution-explained\\n\\n**123. Best Time to Buy and Sell Stock III**\\nhttps://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/discuss/794633/Python-O(n)-solution-with-optimization-explained\\n\\n**188. Best Time to Buy and Sell Stock IV**\\nhttps://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv/discuss/900151/Python-O(nk)-dynamic-programming-explained\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| }, | |
| { | |
| "id": 1110529, | |
| "title": "[Python] Use two dictionaries, explained", | |
| "commentCount": 7, | |
| "post": { | |
| "creationDate": 1615797520, | |
| "voteCount": 24, | |
| "topicTitle": "[Python] Use two dictionaries, explained", | |
| "content": "The idea of this problem is the following: let us keep `2` dictinoaries:\\n1. `self.long_short` to keep links between original long address and encoded short address.\\n2. `self.short_long` to keep the opposit connections.\\n\\nWhy we need to keep both dictionaries? Because we want to do fast encoding and decoding.\\n\\n1.`encode(self, longUrl)` will work like this: let us try to generate random `code`, say with `6` symbols, which consists of letters. If this code was not used for some other long link, we are happy: we put connections to our direct and inverse dictionaries. If it happen, that this code was used for some other long link, we are not happy, and we generate one more code and so on.\\n2.`decode(self, shortUrl)` is pretty straightforward: we just look at our `selfl.short_long` dictionary.\\n\\n**Complexity**: time complexity of one encoding and decoding is `O(n + m)`, where `n` is length of original string and `m` is length of encoded strigng, if we assume that probability of collision is small enough. So, what is probability of collision: we have `26^6` approx `N = 3*10^8` different options, and if we use **Birthday problem**, than if you have `T = 1000` different strings to encode we will have `(1-1/N)*(1-2/N)*...(1-(T-1)/N)` probability to not have a collision, which is very close to `1`. In fact, we need to choose `T`, such that `T^2 << N`, and in this case probability can be approximated as `exp(T^2/2*N)`, which in our case equal to `exp(-1/300)` approx `(1 - 1/300)`.\\n\\n```\\nclass Codec:\\n def __init__(self):\\n self.long_short = {}\\n self.short_long = {}\\n self.alphabet = \"abcdefghijklmnopqrstuvwzyz\"\\n\\n def encode(self, longUrl):\\n while longUrl not in self.long_short:\\n code = \"\".join(choices(self.alphabet, k=6))\\n if code not in self.short_long:\\n self.short_long[code] = longUrl\\n self.long_short[longUrl] = code\\n return \\'http://tinyurl.com/\\' + self.long_short[longUrl]\\n\\n def decode(self, shortUrl):\\n return self.short_long[shortUrl[-6:]]\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please **Upvote!**", | |
| "__typename": "PostNode" | |
| }, | |
| "__typename": "TopicNode" | |
| } | |
| ] | |
| } | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment